近期三个问题的复盘
A postmortem of three recent issues
Anthropic 披露 8 月至 9 月初 Claude 质量下降由三个基础设施 bug 导致:Sonnet 4 context window 错路由、TPU 输出损坏、XLA:TPU approximate top-k 编译问题。影响覆盖 Claude API、Bedrock、Vertex AI 部分请求,修复于 9 月 2 日至 18 日陆续部署,并改进 evaluations、生产监测和调试 tooling。
8 月至 9 月初,三个基础设施 bug 间歇性地降低了 Claude 的响应质量。我们现在已经解决了这些问题,并希望说明发生了什么。
8 月初,一些用户开始报告 Claude 的响应质量下降。这些最初的报告很难与用户反馈中的正常波动区分开来。到 8 月下旬,这类报告的频率和持续性不断上升,促使我们启动调查,并最终发现了三个独立的基础设施 bug。
直白地说:我们从不会因为需求量、一天中的时间或服务器负载而降低模型质量。用户报告的问题仅由基础设施 bug 导致。
我们知道,用户期望 Claude 提供稳定一致的质量;我们也一直以极高标准确保基础设施变更不会影响模型输出。在这些最近的事件中,我们没有达到这一标准。下面的事后复盘会解释哪里出了问题,为什么检测和解决花费的时间比我们希望的更长,以及我们将做出哪些改变来防止未来发生类似事件。
我们通常不会分享如此详细的基础设施技术细节,但这些问题的范围和复杂性值得给出更完整的解释。
我们如何大规模提供 Claude 服务
我们通过自有 API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 向数百万用户提供 Claude。我们将 Claude 部署在多个硬件平台上,即 AWS Trainium、NVIDIA GPU 和 Google TPU。这种方式提供了服务全球用户所需的容量和地理分布。
每个硬件平台都有不同特性,并需要特定优化。尽管存在这些差异,我们对模型实现有严格的等价标准。我们的目标是,无论由哪个平台处理请求,用户都应获得相同质量的响应。这种复杂性意味着,任何基础设施变更都需要在所有平台和配置上进行仔细验证。
事件时间线
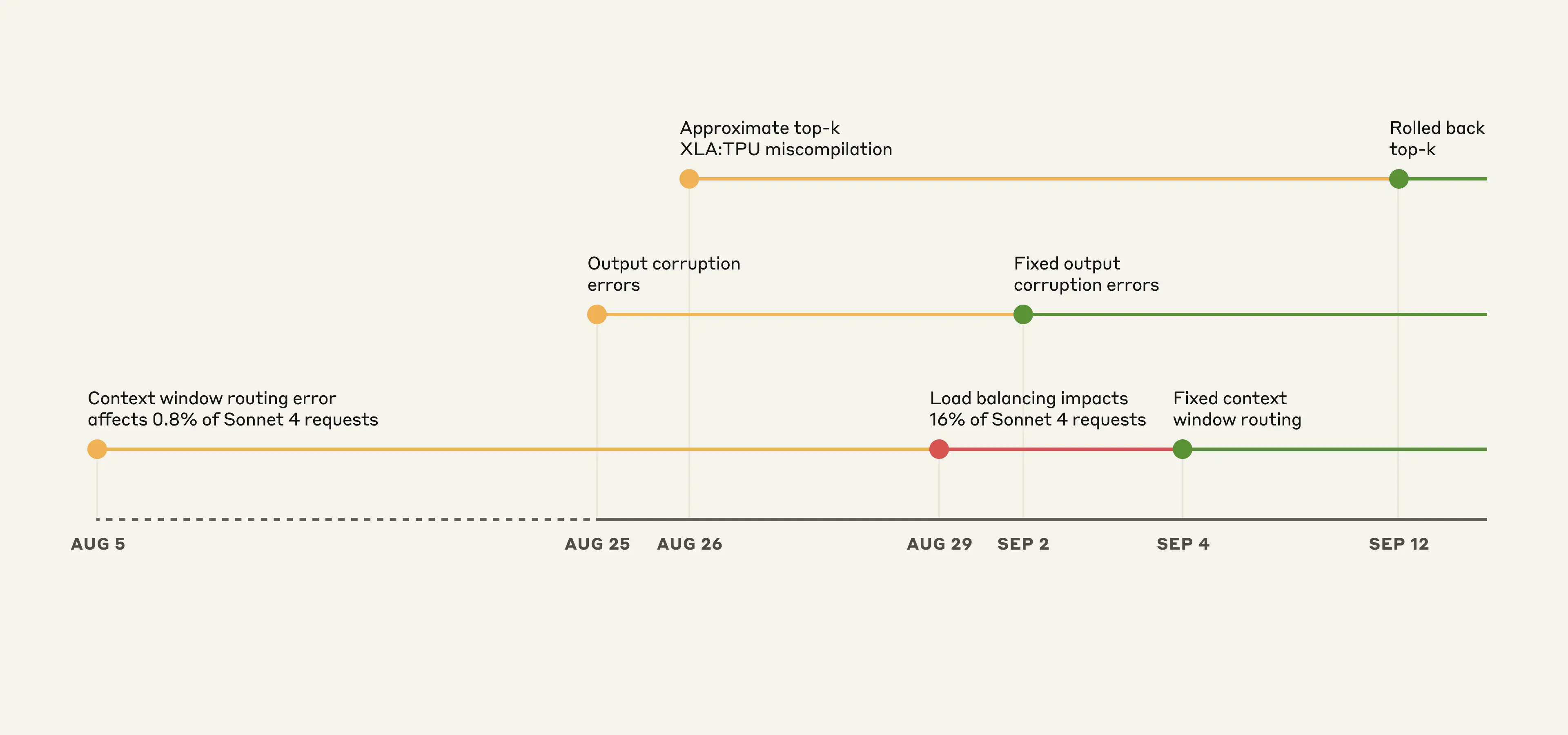
Claude API 上事件的示意时间线。黄色:检测到问题,红色:降级加重,绿色:修复已部署。
这些 bug 相互重叠,使诊断尤其困难。第一个 bug 于 8 月 5 日引入,影响了约 0.8% 的 Sonnet 4 请求。另两个 bug 源自 8 月 25 日和 26 日的部署。
尽管最初影响有限,但 8 月 29 日的一次负载均衡变更开始增加受影响流量。这导致更多用户遇到问题,而其他用户仍然看到正常表现,从而产生了令人困惑且相互矛盾的报告。
三个相互重叠的问题
下面我们描述导致质量下降的三个 bug、它们发生的时间,以及我们如何解决它们:
1. Context window 路由错误
8 月 5 日,一些 Sonnet 4 请求被错误路由到为即将推出的 1M tokencontext window 配置的服务器。这个 bug 最初影响了 0.8% 的请求。8 月 29 日,一次常规负载均衡变更无意中增加了被路由到 1M context 服务器的短上下文请求数量。在 8 月 31 日受影响最严重的一个小时内,16% 的 Sonnet 4 请求受到影响。
在此期间发起请求的 Claude Code 用户中,约 30% 至少有一条消息被路由到错误的服务器类型,导致响应质量下降。在 Amazon Bedrock 上,自 8 月 12 日起,错误路由流量峰值达到所有 Sonnet 4 请求的 0.18%。在 Google Cloud 的 Vertex AI 上,8 月 27 日至 9 月 16 日期间,受错误路由影响的请求少于 0.0004%。
不过,一些用户受到的影响更严重,因为我们的路由是“sticky”的。这意味着一旦某个请求由错误服务器处理,后续 follow-up 很可能也会由同一台错误服务器处理。
解决方案: 我们修复了路由逻辑,确保短上下文和长上下文请求被导向正确的服务器池。我们于 9 月 4 日部署了修复。到 9 月 16 日,修复已完成在自有平台和 Google Cloud 的 Vertex AI 上的 rollout;到 9 月 18 日,完成在 AWS Bedrock 上的 rollout。
2. 输出损坏
8 月 25 日,我们向 Claude API TPU 服务器部署了一个错误配置,导致 token generation 过程中出现错误。由 runtime 性能优化引发的问题偶尔会给在给定 context 下本应很少产生的 token 分配很高概率,例如在响应英文 prompt 时生成泰文或中文字符,或在代码中生成明显的语法错误。例如,一小部分用英文提问的用户可能会在响应中间看到“สวัสดี”。
这种损坏影响了 8 月 25–28 日发往 Opus 4.1 和 Opus 4 的请求,以及 8 月 25 日至 9 月 2 日发往 Sonnet 4 的请求。第三方平台不受此问题影响。
解决方案: 我们识别出该问题,并于 9 月 2 日回滚了变更。我们已在部署流程中加入针对异常字符输出的检测测试。
3. Approximate top-k XLA:TPU 错误编译
8 月 25 日,我们部署了用于改进 Claude 在文本生成期间选择 token 方式的代码。这个变更无意中触发了 XLA:TPU[1] compiler 中一个潜在 bug,并已确认该 bug 影响发往 Claude Haiku 3.5 的请求。
我们也认为,这可能影响了 Claude API 上一部分 Sonnet 4 和 Opus 3 请求。第三方平台不受此问题影响。
解决方案: 我们最初观察到该 bug 影响 Haiku 3.5,并于 9 月 4 日将其回滚。后来我们注意到用户报告的 Opus 3 问题与这个 bug 相符,并于 9 月 12 日将其回滚。经过大量调查后,我们无法在 Sonnet 4 上复现该 bug,但出于充分谨慎,也决定将其回滚。
与此同时,我们 (a) 一直在与 XLA:TPU 团队合作修复 compiler bug,并且 (b) 推出了使用增强精度 exact top-k 的修复。详情见下方深度分析。
更仔细地看 XLA compiler bug
为了说明这些问题的复杂性,下面介绍 XLA compiler bug 是如何表现出来的,以及为什么它特别难以诊断。
当 Claude 生成文本时,它会计算每个可能下一个词的概率,然后从这个概率分布中随机选择一个 sample。我们使用 “top-p sampling” 来避免无意义输出——只考虑累计概率达到某个阈值(通常为 0.99 或 0.999)的词。在 TPU 上,我们的模型运行在多颗芯片上,概率计算发生在不同位置。为了对这些概率进行排序,我们需要在芯片之间协调数据,这很复杂。[2]
2024 年 12 月,我们发现,当 temperature 为零时,我们的 TPU 实现偶尔会丢弃概率最高的 token。我们部署了一个 workaround 来修复这种情况。

2024 年 12 月补丁的代码片段,用于规避 temperature = 0 时意外丢弃 token 的 bug。
根本原因涉及混合精度算术。我们的模型使用 bf16(16-bit 浮点)计算 next-token 概率。不过,vector processor 是 fp32-native,因此 TPU compiler(XLA)可以通过将一些操作转换为 fp32(32-bit)来优化 runtime。这个优化 pass 由 xla_allow_excess_precision flag 保护,其默认值为 true。
这导致了不匹配:本应在最高概率 token 上达成一致的操作,却以不同精度级别运行。精度不匹配意味着它们无法就哪个 token 概率最高达成一致。这导致最高概率 token 有时会完全从候选中消失。
8 月 26 日,我们部署了 sampling 代码的重写版本,以修复精度问题,并改进我们在达到 top-p 阈值边界时处理概率的方式。但在修复这些问题的过程中,我们暴露了一个更棘手的问题。

代码片段,显示作为 8 月 11 日变更一部分合入的最小 reproducer,该变更定位了 2024 年 12 月 workaround 所针对的“bug”的根因。实际上,这是 xla_allow_excess_precision flag 的预期行为。
我们的修复移除了 12 月的 workaround,因为我们认为已经解决了根因。这导致了 approximate top-k 操作中一个更深层的 bug——approximate top-k 是一种用于快速找到最高概率 token 的性能优化。[3] 这种近似有时会返回完全错误的结果,但只在特定 batch size 和模型配置下发生。12 月的 workaround 曾无意中掩盖了这个问题。
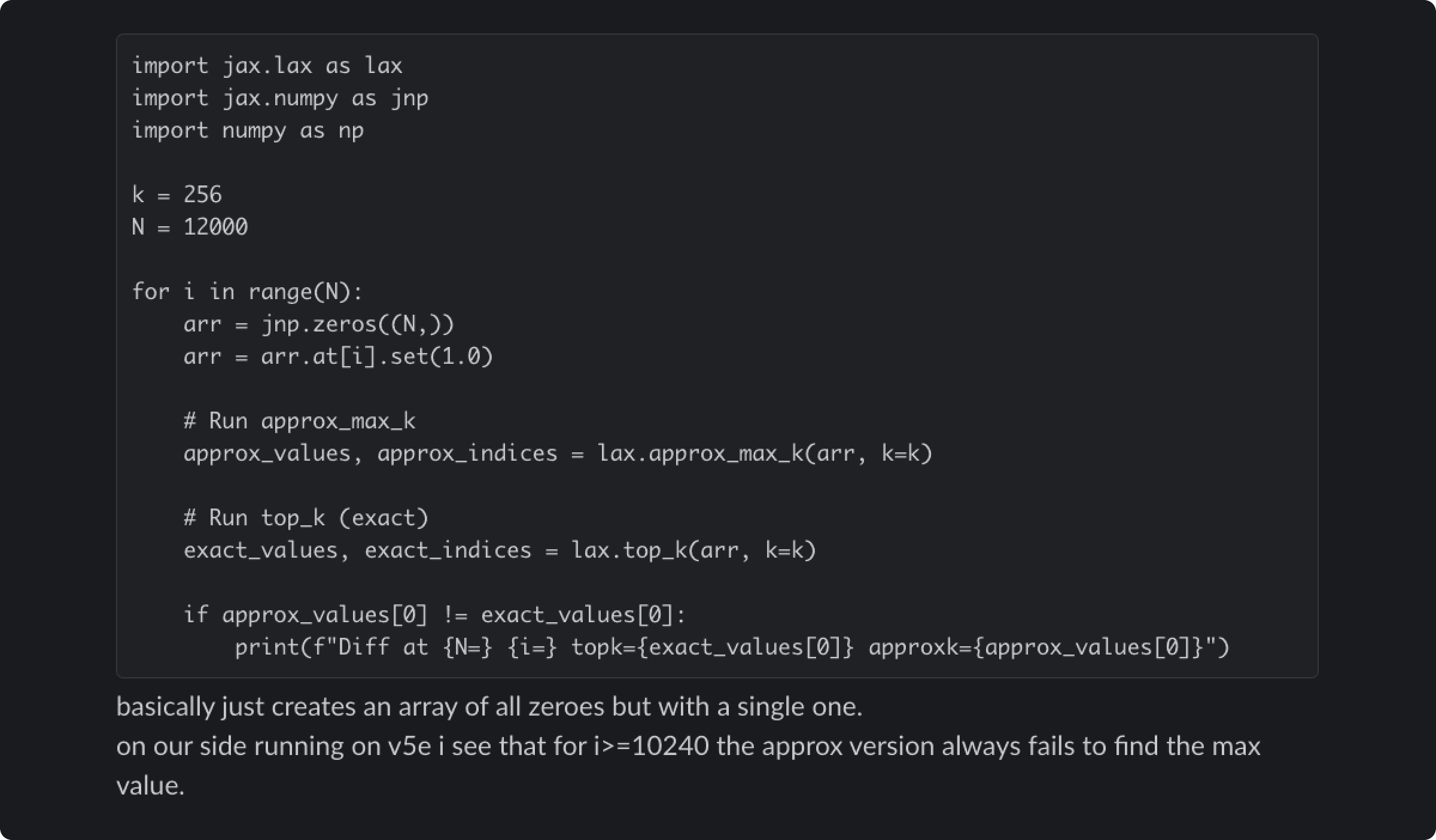
与开发该算法的 XLA:TPU 工程师共享的底层 approximate top-k bug 的 reproducer。该代码在 CPU 上运行时会返回正确结果。
这个 bug 的行为不一致,令人沮丧。它会根据一些无关因素而变化,例如在它之前或之后运行了什么操作,以及是否启用了调试工具。同一个 prompt 可能在一次请求中完全正常,在下一次请求中失败。
调查期间,我们还发现 exact top-k 操作不再有过去那种令人难以接受的性能开销。我们从 approximate top-k 切换到 exact top-k,并将一些额外操作统一为 fp32 精度。[4] 模型质量不可妥协,因此我们接受了轻微的效率影响。
为什么检测很困难
我们的验证流程通常依赖 benchmark,以及安全评估和性能指标。工程团队会进行 spot check,并先部署到小规模 “canary” 组。
这些问题暴露出我们本应更早识别的关键缺口。我们运行的 evaluations 并没有捕捉到用户报告的质量下降,部分原因是 Claude 往往能很好地从孤立错误中恢复。我们自己的隐私实践也给调查报告带来了挑战。我们的内部隐私和安全控制限制了工程师访问用户与 Claude 交互的方式和时间,尤其是在这些交互未作为反馈报告给我们的情况下。这保护了用户隐私,但也阻止工程师检查识别或复现 bug 所需的问题交互。
每个 bug 在不同平台上以不同频率产生不同症状。这造成了一组令人困惑的混合报告,无法指向任何单一原因。它看起来像随机且不一致的质量下降。
更根本的是,我们过度依赖有噪声的 evaluations。尽管我们注意到线上报告有所增加,但缺乏一种清晰方式将这些报告与近期各项变更逐一关联起来。当 8 月 29 日负面报告激增时,我们没有立即将其与一次表面上标准的负载均衡变更联系起来。
我们将做出哪些改变
随着我们继续改进基础设施,我们也在改进评估和预防上述 bug 的方式,覆盖我们提供 Claude 服务的所有平台。以下是我们将做出的改变:
- 更敏感的 evaluations: 为帮助发现任一问题的根因,我们开发了能够更可靠地区分正常实现和故障实现的 evaluations。我们会持续改进这些 evaluations,以更密切地关注模型质量。
- 在更多位置进行质量 evaluations: 尽管我们会定期在系统上运行 evaluations,但我们将持续在真实生产系统上运行它们,以捕捉 context window 负载均衡错误等问题。
- 更快的调试 tooling: 我们将开发基础设施和 tooling,以便在不牺牲用户隐私的前提下,更好地调试来自社区的反馈。此外,这里开发的一些定制工具将在未来类似事件发生时用于缩短修复时间。
Evals 和 monitoring 很重要。但这些事件表明,当 Claude 的响应未达到通常标准时,我们也需要来自用户的持续信号。观察到的具体变化报告、遇到的异常行为示例,以及不同用例中的模式,都帮助我们定位了问题。
用户继续直接向我们发送反馈仍然特别有帮助。你可以在 Claude Code 中使用 /bug 命令,也可以在 Claude apps 中使用 “thumbs down” 按钮。开发者和研究人员经常创造新的、有价值的方式来评估模型质量,以补充我们的内部测试。如果你愿意分享你的方法,请联系 feedback@anthropic.com。
我们仍然感谢社区做出的这些贡献。
致谢
作者 Sam McAllister,感谢 Stuart Ritchie、Jonathan Gray、Kashyap Murali、Brennan Saeta、Oliver Rausch、Alex Palcuie 以及许多其他人的帮助。
[1] XLA:TPU 是一个优化 compiler,用于将 XLA High Level Optimizing language——通常使用 JAX 编写——转换为 TPU 机器指令。
[2] 我们的模型太大,无法放在单颗芯片上,会被划分到数十颗或更多芯片上,因此我们的排序操作是 distributed sort。TPU(和 GPU、Trainium 一样)也具有不同于 CPU 的性能特征,需要使用基于 vectorized operations 的不同实现技术,而不是串行算法。
[3] 我们此前一直使用这个 approximate operation,因为它带来了显著的性能提升。该近似通过接受最低概率 token 中可能存在的不准确性来工作,而这些不准确性本不应影响质量——除非该 bug 导致它丢弃的不是低概率 token,而是最高概率 token。
[4] 请注意,现在正确的 top-k 实现可能会导致接近 top-p 阈值的 token 是否被纳入出现轻微差异;在少数情况下,用户可能会受益于重新调整其 top-p 选择。