用 AI agents 编写高效工具
Writing effective tools for AI agents—using AI agents
Anthropic 文章介绍面向 LLM agent 的 MCP tools 构建流程:原型开发、本地或 API 测试、基于真实任务生成评估、用 Claude Code 分析 transcripts 并迭代优化;总结 tool 选择、命名空间、上下文返回、token 效率和 tool descriptions prompt engineering 等方法。
Model Context Protocol (MCP) 可以让 LLM agent 获得可能多达数百个 tools,用来解决现实任务。但我们如何让这些 tools 最大程度地发挥作用?
本文将介绍我们在多种 agentic AI 系统中提升性能时最有效的一些技术 1。
首先,我们会介绍如何:
- 构建并测试 tools 的原型
- 创建并运行针对 tools 与 agent 的综合评估
- 与 Claude Code 等 agent 协作,自动提升 tools 的性能
最后,我们会总结在此过程中识别出的编写高质量 tools 的关键原则:
- 选择合适的 tools 来实现(以及不实现)
- 对 tools 进行命名空间划分,以定义清晰的功能边界
- 从 tools 向 agent 返回有意义的上下文
- 优化 tool 响应以提升 token 效率
- 对 tool 描述和规格进行 prompt engineering
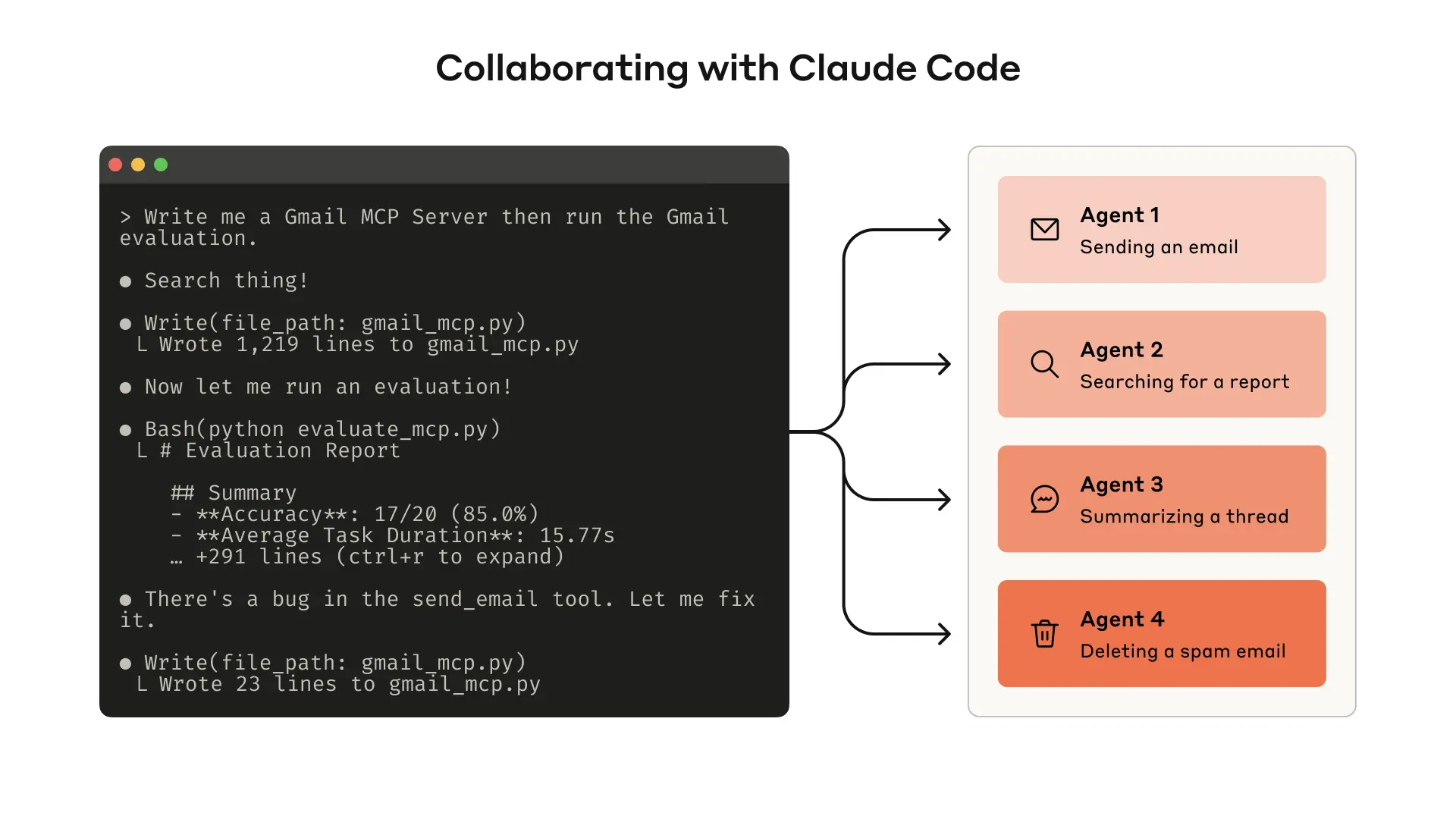
构建评估可以让你系统性地衡量 tools 的性能。你可以使用 Claude Code 基于这套评估自动优化 tools。
什么是 tool?
在计算领域,确定性系统在输入相同的情况下每次都会产生相同输出,而 非确定性 系统(例如 agent)即使在相同的初始条件下,也可能生成不同的响应。
传统软件开发中,我们是在确定性系统之间建立契约。例如,像 getWeather(“NYC”) 这样的函数调用,每次被调用时都会以完全相同的方式获取 New York City 的天气。
Tools 是一种新的软件形态,反映的是确定性系统与非确定性 agent 之间的契约。当用户问“我今天应该带伞吗?”时,agent 可能会调用天气 tool,也可能基于常识回答,甚至可能先追问位置。有时,agent 可能会 hallucinate,甚至没有理解如何使用某个 tool。
这意味着我们必须从根本上重新思考为 agent 编写软件的方法:不能像为其他开发者或系统编写函数和 API 那样编写 tools 和 MCP servers,而是需要面向 agent 来设计它们。
我们的目标是扩大 agent 能够有效解决广泛任务的范围,使其能够使用 tools 采取多种成功策略。幸运的是,根据我们的经验,对 agent 最“顺手”的 tools,最终对人类来说也往往出人意料地直观。
如何编写 tools
本节将介绍如何与 agent 协作,编写并改进你提供给它们的 tools。首先快速搭建 tools 的原型并在本地测试。接着,运行一套综合评估来衡量后续改动。通过与 agent 协作,你可以反复评估和改进 tools,直到 agent 在现实任务上取得较强表现。
构建原型
如果不亲自上手,很难预判哪些 tools 会让 agent 觉得顺手、哪些不会。先快速搭建 tools 的原型。如果你使用 Claude Code 编写 tools(可能是一次性完成),最好向 Claude 提供 tools 所依赖的任何软件库、API 或 SDK 的文档(也可能包括 MCP SDK)。适合 LLM 阅读的文档通常可以在官方文档站点上的扁平 llms.txt 文件中找到(这里是我们的 API 文档)。
将 tools 封装在 local MCP server 或 Desktop extension (DXT) 中,可以让你在 Claude Code 或 Claude Desktop app 中连接并测试这些 tools。
要将本地 MCP server 连接到 Claude Code,运行 claude mcp add <name> <command> [args...]。
要将本地 MCP server 或 DXT 连接到 Claude Desktop app,分别导航到 Settings > Developer 或 Settings > Extensions。
Tools 也可以直接传入 Anthropic API 调用,用于程序化测试。
亲自测试这些 tools,找出任何粗糙之处。收集用户反馈,形成对你期望 tools 支持的 use cases 和 prompts 的直觉。
运行评估
接下来,你需要通过运行评估来衡量 Claude 使用这些 tools 的效果。首先生成大量基于真实使用场景的评估任务。我们建议与 agent 协作,帮助分析结果并确定如何改进 tools。你可以在我们的 tool evaluation cookbook 中查看端到端流程。
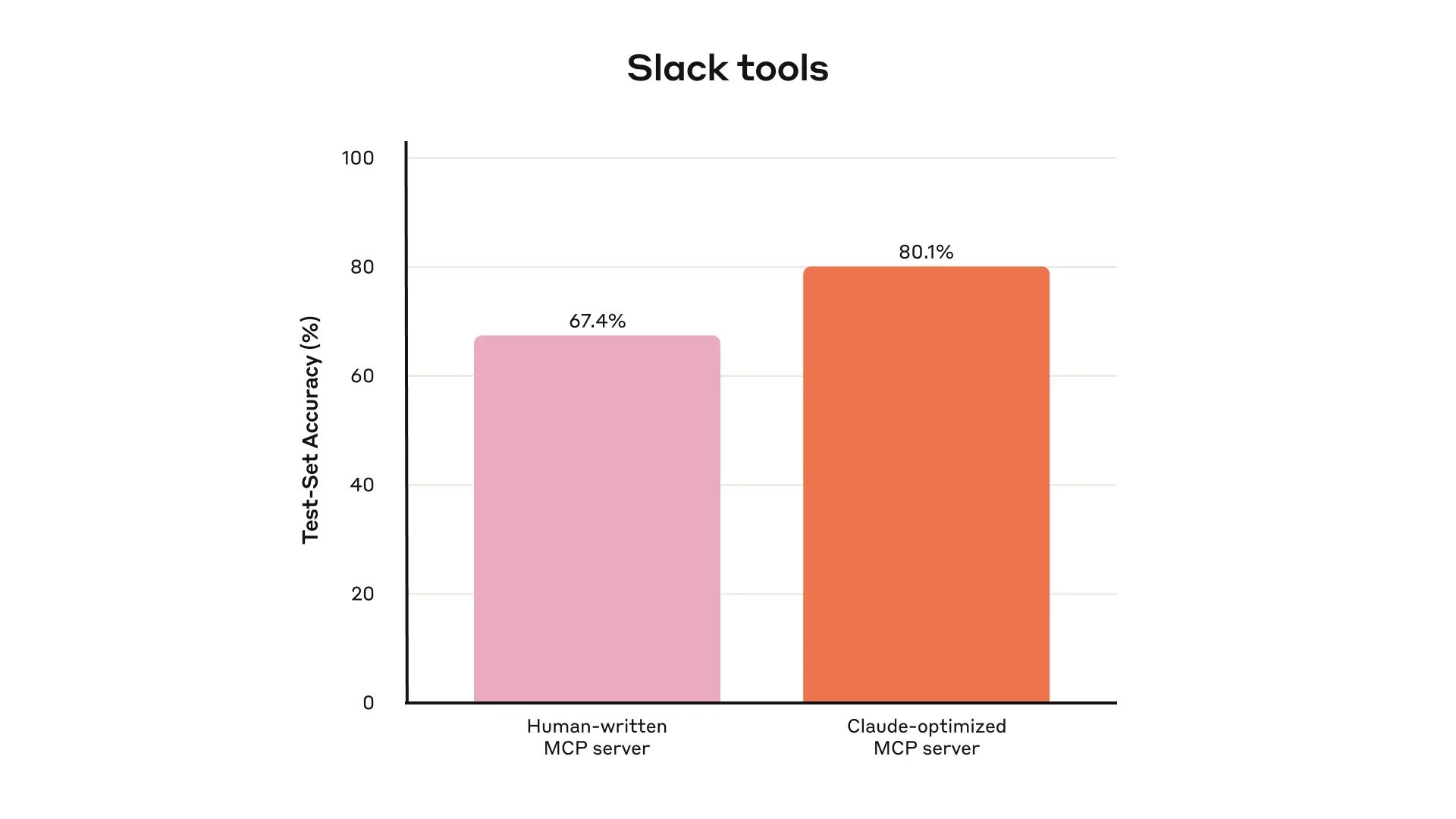
我们内部 Slack tools 在 held-out test set 上的表现
生成评估任务
有了早期原型后,Claude Code 可以快速探索你的 tools,并创建数十组 prompt 和 response 对。Prompts 应受现实使用场景启发,并基于真实的数据源和服务(例如内部知识库和 microservices)。我们建议避免过于简单或浅层的“sandbox”环境,因为它们无法用足够复杂度对 tools 进行压力测试。强评估任务可能需要多次 tool calls,甚至可能需要几十次。
以下是一些强任务示例:
- 安排下周与 Jane 开会,讨论我们最新的 Acme Corp 项目。附上上次项目规划会议的 notes,并预订一间会议室。
- Customer ID 9182 报告称他们一次购买尝试被扣款三次。查找所有相关 log entries,并判断是否有其他客户受到同一问题影响。
- 客户 Sarah Chen 刚提交了取消请求。准备一份挽留 offer。确定:(1) 她为什么离开,(2) 哪种挽留 offer 最有吸引力,(3) 在提出 offer 之前我们应注意哪些风险因素。
以下是一些较弱的任务:
- 安排下周与 jane@acme.corp 开会。
- 在 payment logs 中搜索
purchase_complete和customer_id=9182。 - 根据 Customer ID 45892 查找取消请求。
每个评估 prompt 都应配对一个可验证的 response 或 outcome。你的 verifier 可以很简单,例如将 ground truth 与 sampled responses 做精确字符串比较;也可以更高级,例如让 Claude 来评判 response。避免使用过于严格的 verifier,因为它们可能会因格式、标点或有效的替代表述等无关差异而拒绝正确响应。
对于每个 prompt-response 对,你也可以选择指定你期望 agent 在解决任务时调用的 tools,以衡量 agent 在评估期间是否成功理解了每个 tool 的用途。不过,由于正确解决任务可能有多条有效路径,应尽量避免过度指定或过拟合到某些策略。
运行评估
我们建议使用直接的 LLM API calls 以程序化方式运行评估。使用简单的 agentic loops(用 while loops 包裹交替进行的 LLM API 和 tool calls):每个评估任务对应一个 loop。每个评估 agent 都应获得一个单独的任务 prompt 和你的 tools。
在评估 agent 的 system prompts 中,我们建议要求 agent 不仅输出结构化 response blocks(用于验证),还输出 reasoning 和 feedback blocks。要求 agent 在 tool call 和 response blocks 之前输出这些内容,可能会通过触发 chain-of-thought (CoT) 行为来提升 LLM 的有效智能。
如果你使用 Claude 运行评估,可以开启 interleaved thinking,以开箱即用地获得类似功能。这将帮助你探查 agent 为什么会或不会调用某些 tools,并突出 tool descriptions 和 specs 中需要改进的具体区域。
除顶层 accuracy 外,我们还建议收集其他 metrics,例如单个 tool calls 和 tasks 的总运行时间、tool calls 总数、总 token 消耗以及 tool errors。跟踪 tool calls 有助于揭示 agent 采用的常见 workflows,并为合并 tools 提供机会。
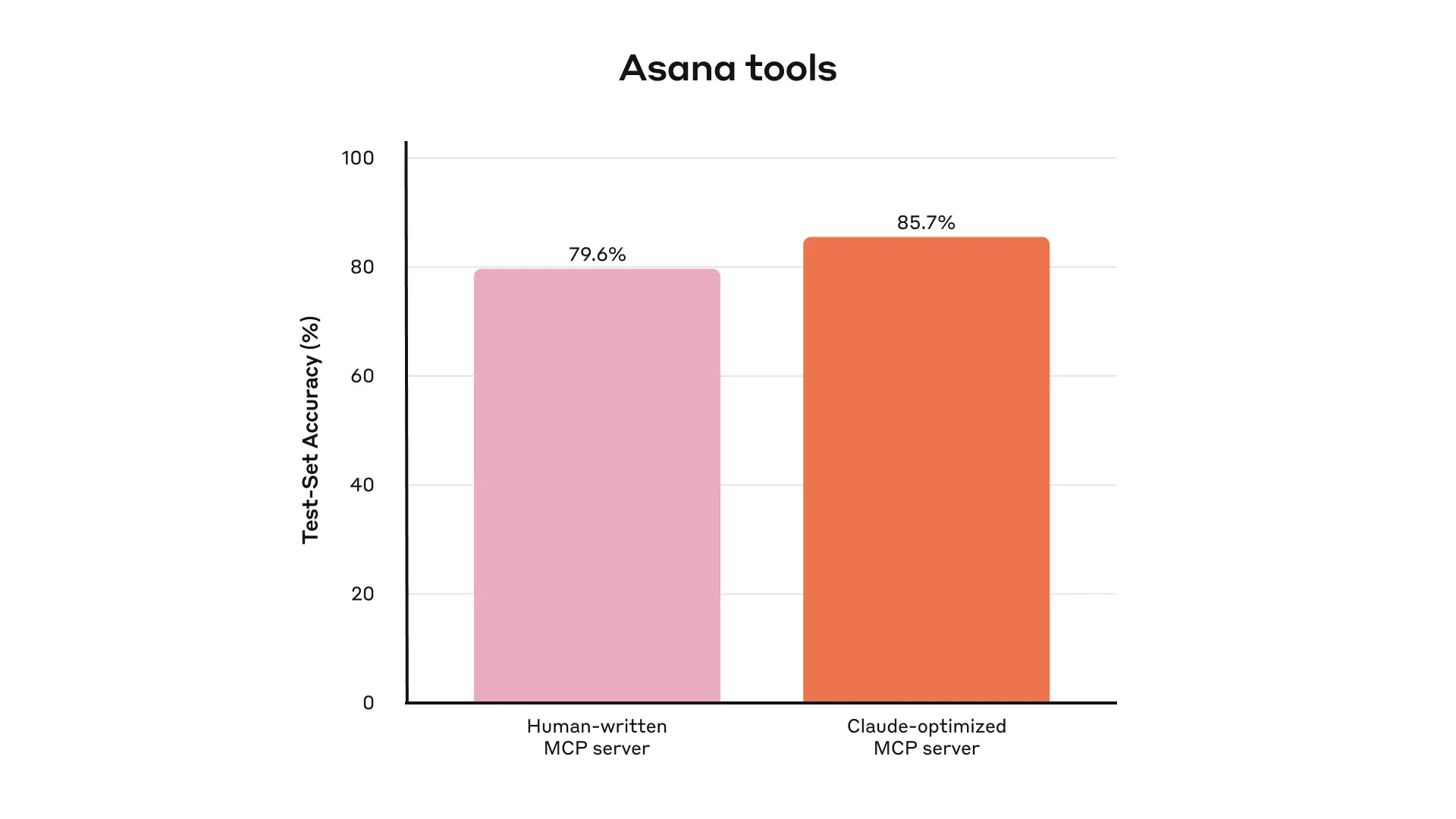
我们内部 Asana tools 在 held-out test set 上的表现
分析结果
Agent 是发现问题和提供反馈的有用伙伴,范围可以从矛盾的 tool descriptions,到低效的 tool implementations,再到令人困惑的 tool schemas。不过,请记住,agent 在反馈和响应中省略的内容,往往比它们包含的内容更重要。LLM 并不总是 say what they mean。
观察 agent 在哪里卡住或困惑。通读评估 agent 的 reasoning 和 feedback(或 CoT),识别粗糙之处。审查原始 transcripts(包括 tool calls 和 tool responses),捕捉 agent 的 CoT 中没有明确描述的行为。要读出字里行间的含义;记住,你的评估 agent 不一定知道正确答案和策略。
分析你的 tool calling metrics。大量冗余 tool calls 可能表明需要适当调整 pagination 或 token limit 参数;大量由无效参数导致的 tool errors 可能表明 tools 需要更清晰的描述或更好的 examples。当我们发布 Claude 的 web search tool 时,我们发现 Claude 会不必要地在 tool 的 query 参数后追加 2025,这会使搜索结果产生偏差并降低性能(我们通过改进 tool description 引导 Claude 走向正确方向)。
与 agent 协作
你甚至可以让 agent 分析结果并替你改进 tools。只需将评估 agent 的 transcripts 拼接起来并粘贴到 Claude Code 中。Claude 擅长分析 transcripts,并一次性重构大量 tools,例如在进行新更改时确保 tool implementations 和 descriptions 保持自洽。
事实上,本文中的大多数建议都来自我们使用 Claude Code 反复优化内部 tool implementations 的过程。我们的评估建立在内部 workspace 之上,模拟了内部 workflows 的复杂度,包括真实的 projects、documents 和 messages。
我们依靠 held-out test sets 来确保没有过拟合到“training”评估。这些 test sets 显示,即使在“expert” tool implementations 已经达到的水平之上,我们仍然可以进一步提升性能,无论这些 tools 是由研究人员手写,还是由 Claude 自行生成。
下一节中,我们将分享这个过程中学到的一些经验。
编写有效 tools 的原则
本节将把我们的经验提炼为编写有效 tools 的几条指导原则。
为 agent 选择合适的 tools
更多 tools 并不总是带来更好的结果。我们观察到的一个常见错误是,tools 只是简单封装现有软件功能或 API endpoints,而不管这些 tools 是否适合 agent。这是因为 agent 与传统软件有不同的“affordances”——也就是说,它们感知自己可以用这些 tools 执行哪些潜在操作的方式不同。
LLM agent 的 “context” 有限(也就是说,它们一次能处理的信息量有限),而计算机内存便宜且充裕。以在通讯录中搜索联系人这一任务为例。传统软件程序可以高效地存储并逐个处理联系人列表,检查每一项后再继续。
然而,如果 LLM agent 使用的 tool 返回所有联系人,然后它必须逐个 token 阅读所有联系人,那么它就是在把有限的 context 空间浪费在无关信息上(想象一下通过从上到下阅读通讯录的每一页来查找联系人,也就是 brute-force search)。对 agent 和人类来说,更好也更自然的方法,是先跳到相关页面(也许按字母顺序查找)。
我们建议构建少量经过深思熟虑的 tools,面向与你的评估任务匹配的特定高影响 workflows,然后再从那里扩展。在通讯录案例中,你可能会选择实现 search_contacts 或 message_contact tool,而不是 list_contacts tool。
Tools 可以整合功能,在底层处理可能 多个 离散操作(或 API calls)。例如,tools 可以用相关 metadata 丰富 tool responses,或者在一次 tool call 中处理经常串联出现的多步骤任务。
以下是一些示例:
- 与其实现
list_users、list_events和create_eventtools,不如考虑实现一个schedule_eventtool,用于查找可用时间并安排 event。 - 与其实现
read_logstool,不如考虑实现一个search_logstool,只返回相关 log lines 及其周围的部分 context。 - 与其实现
get_customer_by_id、list_transactions和list_notestools,不如实现一个get_customer_contexttool,一次性汇总客户最近且相关的全部信息。
确保你构建的每个 tool 都有清晰且独特的用途。Tools 应让 agent 能够像人类在访问同样底层资源时那样,对任务进行拆分和解决,同时减少原本会被中间输出消耗掉的 context。
过多 tools 或相互重叠的 tools 也会分散 agent 对高效策略的关注。谨慎而有选择地规划要构建(或不构建)的 tools,确实会带来回报。
为 tools 使用命名空间
你的 AI agents 可能会访问几十个 MCP servers 和数百个不同 tools,其中包括其他开发者提供的 tools。当 tools 功能重叠或用途含糊时,agent 可能会对该使用哪个 tool 感到困惑。
命名空间(将相关 tools 归入共同前缀下)有助于在大量 tools 之间划定边界;MCP clients 有时会默认这样做。例如,按 service 对 tools 进行命名空间划分(如 asana_search、jira_search),以及按 resource 划分(如 asana_projects_search、asana_users_search),可以帮助 agent 在合适的时间选择合适的 tools。
我们发现,在 prefix-based 与 suffix-based 命名空间之间做选择,会对 tool-use 评估产生不可忽视的影响。影响会因 LLM 而异,我们建议你根据自己的评估选择命名方案。
Agent 可能调用错误 tools、用错误参数调用正确 tools、调用 tools 太少,或错误处理 tool responses。通过有选择地实现名称能够反映任务自然拆分方式的 tools,你可以同时减少加载到 agent context 中的 tools 和 tool descriptions 数量,并把 agentic computation 从 agent 的 context 转移回 tool calls 本身。这会降低 agent 整体犯错的风险。
从 tools 返回有意义的 context
同样,tool implementations 应注意只向 agent 返回高信号信息。它们应优先考虑上下文相关性,而不是灵活性,并避免低层技术标识符(例如:uuid、256px_image_url、mime_type)。像 name、image_url 和 file_type 这样的字段,更有可能直接影响 agent 后续的 actions 和 responses。
相比晦涩的 identifiers,agent 通常也更能成功处理自然语言 names、terms 或 identifiers。我们发现,仅仅将任意字母数字 UUIDs 解析为语义上更有意义、更易解释的语言(甚至是 0-indexed ID scheme),就能通过减少 hallucinations 显著提升 Claude 在 retrieval tasks 中的 precision。
在某些情况下,agent 可能需要同时与自然语言和技术 identifiers 输出交互的灵活性,哪怕只是为了触发后续 tool calls(例如,search_user(name=’jane’) → send_message(id=12345))。你可以通过在 tool 中暴露一个简单的 response_format enum 参数来同时支持两者,让 agent 控制 tools 返回 “concise” 还是 “detailed” responses(见下图)。
你还可以添加更多格式以获得更高灵活性,类似 GraphQL 中可以精确选择想接收哪些信息。下面是一个用于控制 tool response 详略程度的 ResponseFormat enum 示例:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}
以下是详细 tool response 的示例(206 tokens):
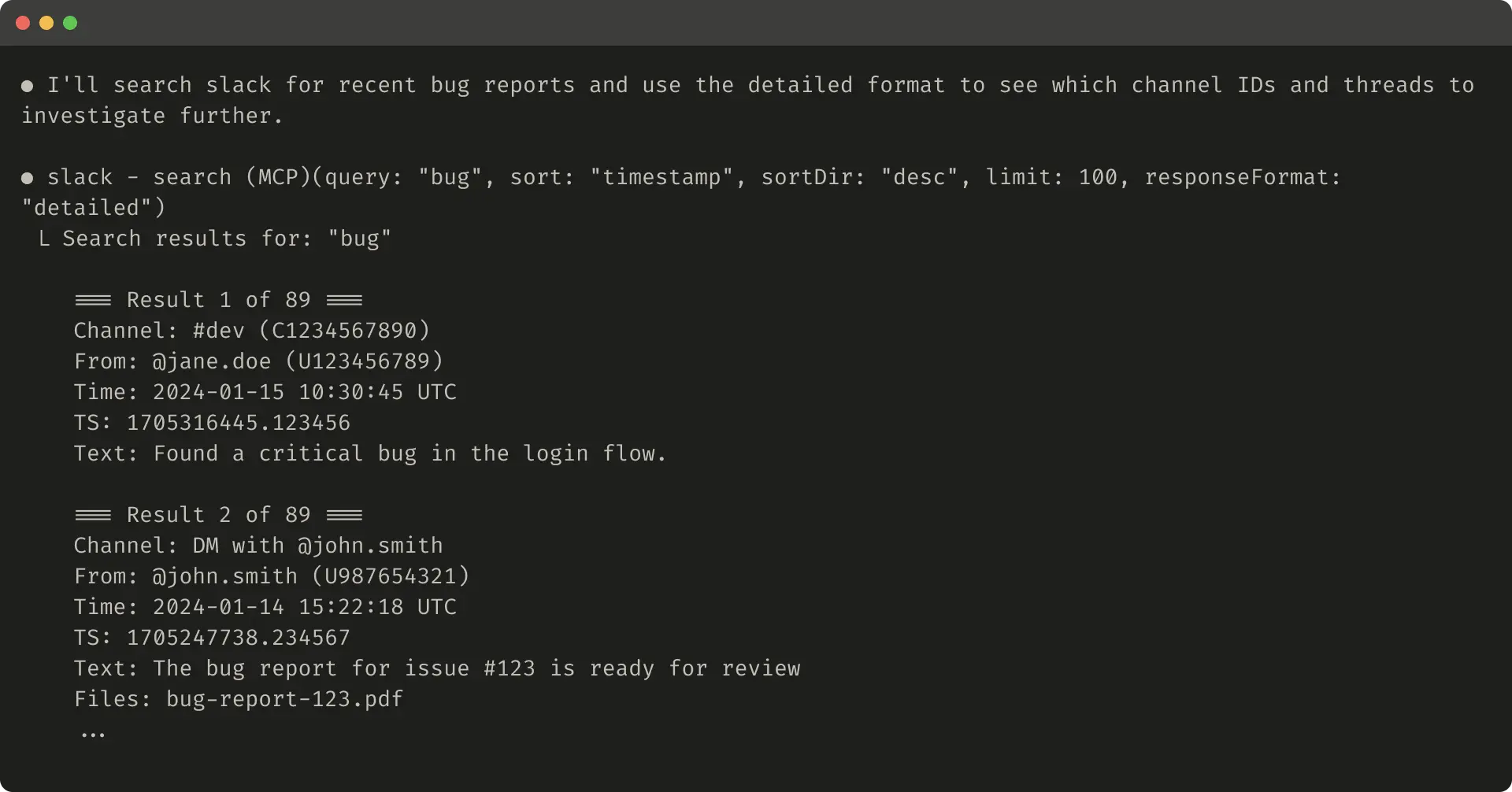
以下是简洁 tool response 的示例(72 tokens):
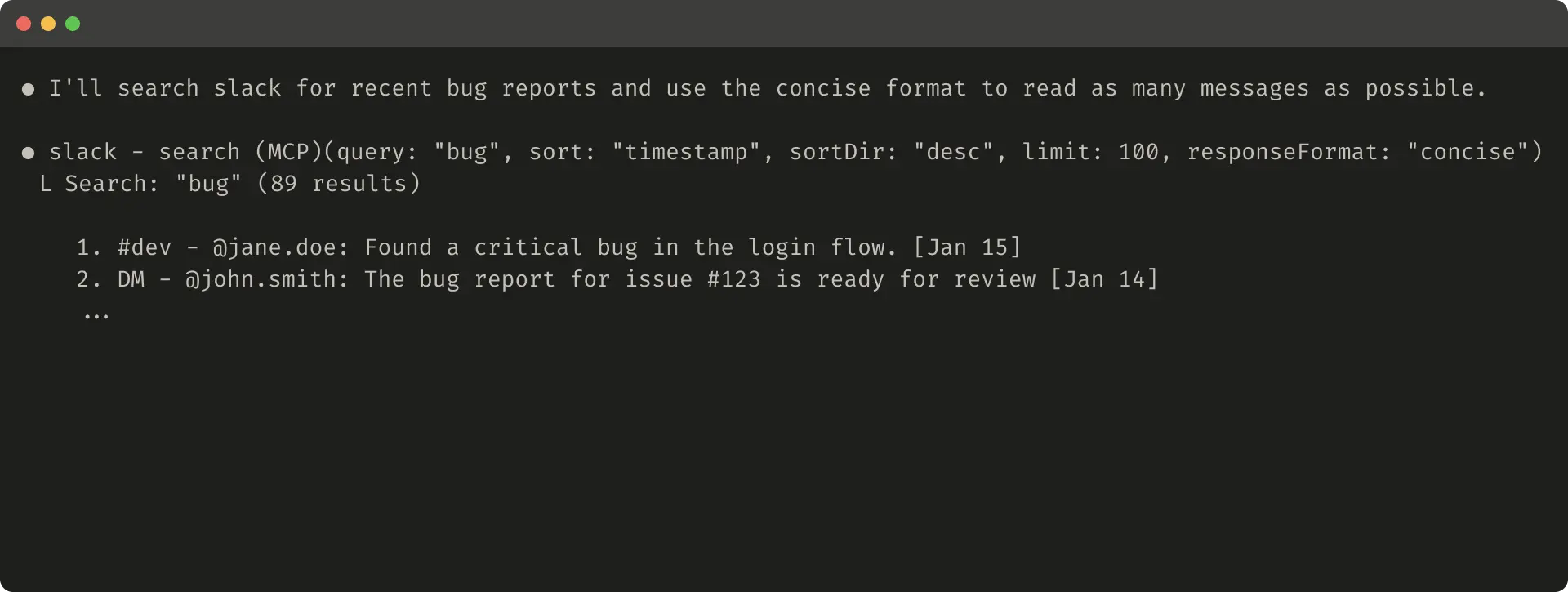
Slack threads 和 thread replies 由唯一的 thread_ts 标识,获取 thread replies 时需要这些标识。thread_ts 和其他 IDs(channel_id、user_id)可以从 “detailed” tool response 中检索,以支持需要这些信息的后续 tool calls。“concise” tool responses 只返回 thread content,并排除 IDs。在这个示例中,使用 “concise” tool responses 时,我们只使用了约 ⅓ 的 tokens。
即使是 tool response structure,例如 XML、JSON 或 Markdown,也可能影响评估表现:没有适用于所有场景的单一方案。这是因为 LLMs 是基于 next-token prediction 训练的,往往在与训练数据相匹配的格式上表现更好。最优 response structure 会随任务和 agent 而有很大差异。我们建议你根据自己的评估选择最佳 response structure。
优化 tool responses 以提升 token 效率
优化 context 的质量很重要。但优化 tool responses 返回给 agent 的 context 数量 同样重要。
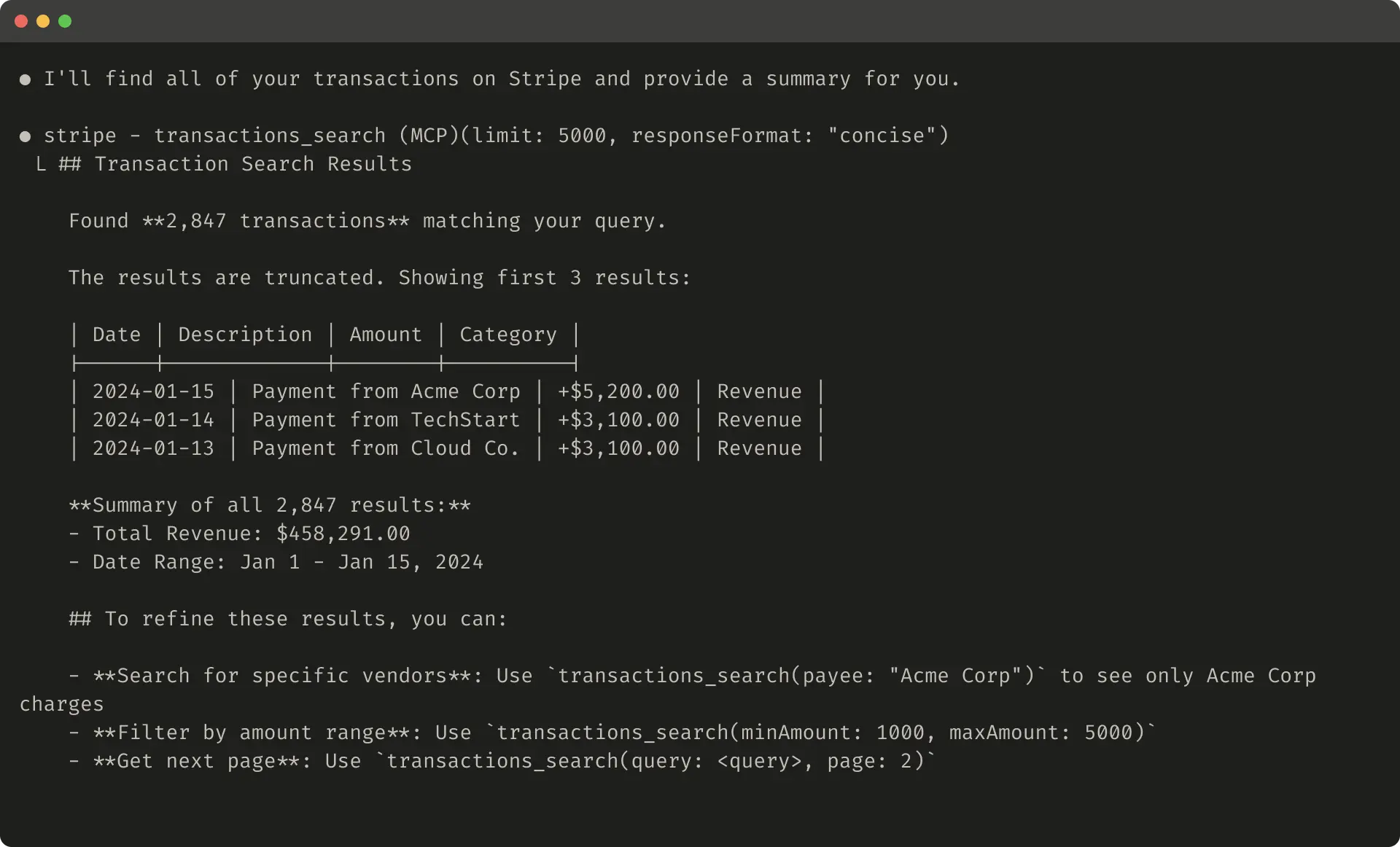
对于任何可能消耗大量 context 的 tool responses,我们建议实现 pagination、range selection、filtering 和/或 truncation 的某种组合,并设置合理的默认参数值。对于 Claude Code,我们默认将 tool responses 限制为 25,000 tokens。我们预计 agent 的有效 context length 会随时间增长,但对 context-efficient tools 的需求仍会存在。
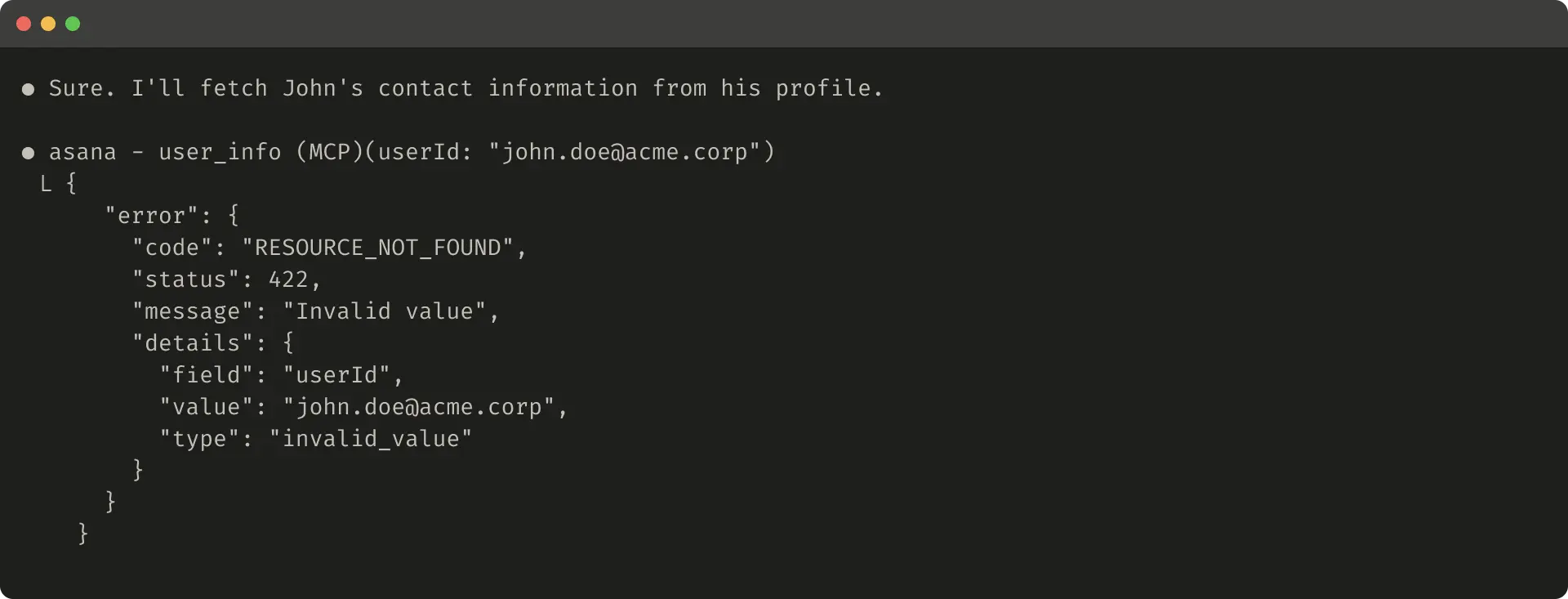
如果你选择截断 responses,务必用有帮助的指令引导 agent。你可以直接鼓励 agent 采用更节省 token 的策略,例如在 knowledge retrieval task 中进行多次小而有针对性的搜索,而不是一次宽泛搜索。类似地,如果 tool call 抛出 error(例如在 input validation 期间),你可以对 error responses 进行 prompt-engineering,清晰传达具体且可执行的改进建议,而不是返回不透明的 error codes 或 tracebacks。
以下是一个截断后的 tool response 示例:
以下是一个没有帮助的 error response 示例:
以下是一个有帮助的 error response 示例:
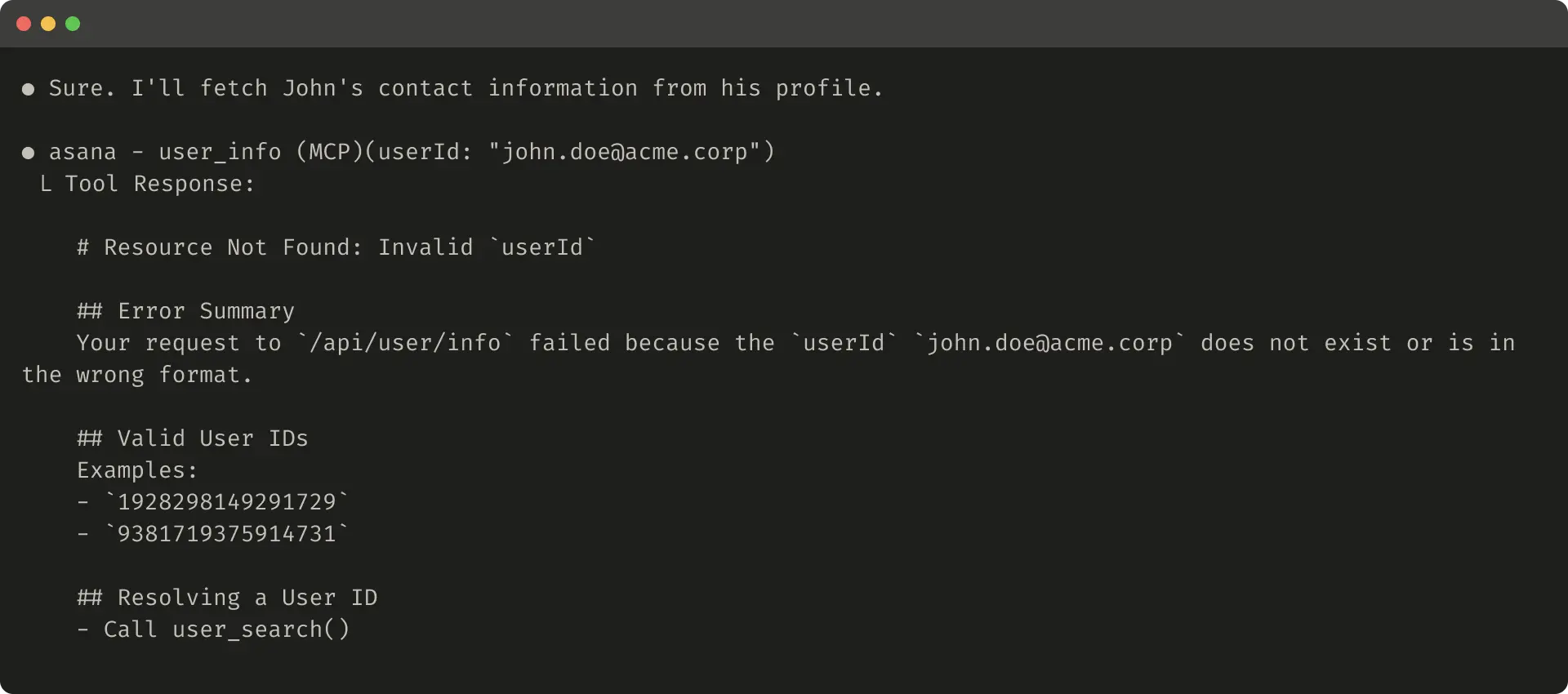
Tool truncation 和 error responses 可以引导 agent 采用更节省 token 的 tool-use 行为(使用 filters 或 pagination),或给出格式正确的 tool inputs 示例。
对 tool descriptions 进行 prompt-engineering
现在来到提升 tools 最有效的方法之一:对 tool descriptions 和 specs 进行 prompt-engineering。由于这些内容会加载到 agent 的 context 中,它们可以共同引导 agent 采取有效的 tool-calling behaviors。
编写 tool descriptions 和 specs 时,可以思考你会如何向团队新成员介绍你的 tool。考虑你可能隐含带入的 context,例如专门的 query formats、小众术语的定义、底层 resources 之间的关系,并将其明确写出。通过清晰描述(并用严格的数据模型强制执行)预期 inputs 和 outputs 来避免歧义。尤其是 input parameters 应命名明确:不要使用名为 user 的参数,尝试使用名为 user_id 的参数。
通过评估,你可以更有信心地衡量 prompt engineering 的影响。即使是对 tool descriptions 的小幅打磨,也可能带来显著改进。在我们对 tool descriptions 做出精确改进后,Claude Sonnet 3.5 在 SWE-bench Verified 评估中达到了 state-of-the-art 性能,显著降低了错误率并提升了任务完成度。
你可以在我们的 Developer Guide 中找到 tool definitions 的其他最佳实践。如果你正在为 Claude 构建 tools,我们还建议阅读 tools 如何被动态加载到 Claude 的 system prompt 中。最后,如果你正在为 MCP server 编写 tools,tool annotations 有助于披露哪些 tools 需要 open-world access,或会进行破坏性更改。
展望
为了为 agent 构建有效的 tools,我们需要将软件开发实践从可预测的确定性模式,转向非确定性模式。
通过本文描述的这种迭代式、评估驱动流程,我们识别出了成功 tools 的一致模式:有效的 tools 是有意且清晰定义的,谨慎使用 agent context,能够在多样化 workflows 中组合使用,并让 agent 能够直观地解决现实任务。
未来,我们预计 agent 与世界交互的具体机制将不断演进,从 MCP protocol 的更新,到底层 LLMs 本身的升级。通过采用系统性、评估驱动的方法改进 agent 使用的 tools,我们可以确保随着 agent 变得更强,它们所使用的 tools 也会同步演进。
致谢
作者 Ken Aizawa,感谢来自 Research(Barry Zhang, Zachary Witten, Daniel Jiang, Sami Al-Sheikh, Matt Bell, Maggie Vo)、MCP(Theodora Chu, John Welsh, David Soria Parra, Adam Jones)、Product Engineering(Santiago Seira)、Marketing(Molly Vorwerck)、Design(Drew Roper)和 Applied AI(Christian Ryan, Alexander Bricken)的同事们提供的宝贵贡献。
1 不包括底层 LLMs 本身的训练。