Claude Opus 4.7 介绍
Introducing Claude Opus 4.7
Anthropic 发布 Claude Opus 4.7,面向所有 Claude 产品、API、Amazon Bedrock、Vertex AI 和 Microsoft Foundry 开放,价格为每百万 input tokens 5 美元、output tokens 25 美元。模型提升 coding、vision、multimodal 和 memory,支持长边 2,576 像素图像,并加入 cyber safeguards、xhigh effort、task budgets 与 Claude Code /ultrareview。
我们的最新模型 Claude Opus 4.7 现已全面可用。
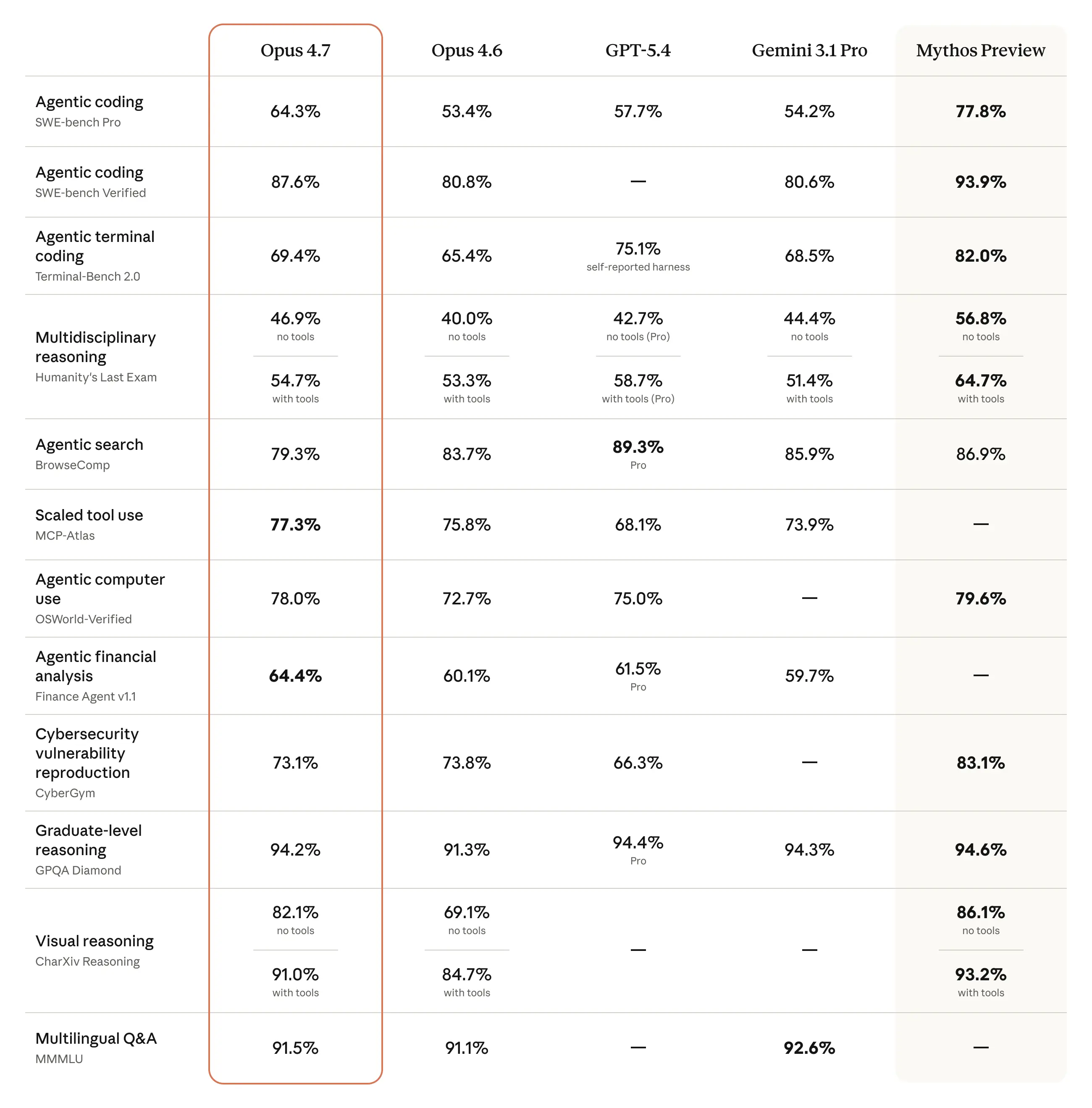
Opus 4.7 相比 Opus 4.6 在高级软件工程方面有明显改进,尤其在最困难的任务上提升更突出。用户反馈称,他们现在可以放心地把最难的编码工作交给 Opus 4.7——这类工作过去通常需要密切监督。Opus 4.7 能严谨且一致地处理复杂、长时间运行的任务,精准关注指令,并会在汇报前设计方法验证自己的输出。
该模型的 vision 能力也有显著提升:它能够以更高分辨率查看图像。在完成专业任务时,它的审美和创造性更好,能够生成质量更高的界面、幻灯片和文档。而且——尽管它的总体能力不如我们最强大的模型 Claude Mythos Preview——它在一系列 benchmark 上的表现优于 Opus 4.6:
上周我们宣布了 Project Glasswing,重点介绍 AI 模型在网络安全方面的风险与收益。我们表示,会继续限制 Claude Mythos Preview 的发布范围,并先在能力较弱的模型上测试新的网络安全防护措施。Opus 4.7 是首个此类模型:它的网络能力不如 Mythos Preview 先进(事实上,在训练过程中,我们尝试过有针对性地降低这些能力)。我们发布 Opus 4.7 时配套了防护措施,可自动检测并阻止表明存在被禁止或高风险网络安全用途的请求。我们从这些防护措施的真实部署中获得的经验,将帮助我们逐步实现广泛发布 Mythos 级模型的最终目标。
希望将 Opus 4.7 用于合法网络安全目的(如漏洞研究、渗透测试和 red-teaming)的安全专业人士,可申请加入我们的新 Cyber Verification Program。
Opus 4.7 今天起可在所有 Claude 产品、我们的 API、Amazon Bedrock、Google Cloud 的 Vertex AI 和 Microsoft Foundry 上使用。价格与 Opus 4.6 相同:每百万 input tokens $5,每百万 output tokens $25。开发者可通过 Claude API 使用 claude-opus-4-7。
测试 Claude Opus 4.7
Claude Opus 4.7 获得了早期访问测试者的积极反馈:

在早期测试中,我们看到了 Claude Opus 4.7 为我们的开发者带来显著跃升的潜力。它会在规划阶段发现自己的逻辑问题,并加速执行,远超以往的 Claude 模型。作为一个以相当规模服务数百万消费者和企业的金融科技平台,这种速度与精度的结合可能带来重要变化:加快开发速度,更快交付客户每天依赖的可信金融解决方案。

Anthropic 已经为 coding 模型树立了标准,而 Claude Opus 4.7 作为市场上的 SOTA 模型,以有意义的方式进一步推进了这一标准。在我们的内部 evals 中,它突出的不仅是原始能力,还有它处理真实世界 async workflow 的能力——automations、CI/CD 和长时间运行任务。它也会更深入地思考问题,并提出更有主见的观点,而不是简单认同用户。

Claude Opus 4.7 是 Hex 评估过的最强模型。它会在数据缺失时正确说明,而不是提供看似合理但不正确的替代答案;它还能抵抗连 Opus 4.6 都会中招的不一致数据陷阱。它是更智能、更高效的 Opus 4.6:低 effort 的 Opus 4.7 大致相当于中等 effort 的 Opus 4.6。

在我们的 93 项 coding benchmark 中,Claude Opus 4.7 相比 Opus 4.6 将解决率提高了 13%,其中包括四项 Opus 4.6 和 Sonnet 4.6 都无法解决的任务。再加上更快的中位延迟和严格的指令遵循能力,它对复杂、长时间运行的 coding workflow 尤其有意义。它减少了多步骤任务中的摩擦,让开发者能够保持心流并专注于构建。

根据我们的内部 research-agent benchmark,Claude Opus 4.7 在多步骤工作上拥有我们见过的最强效率基线。它在六个模块的总体得分中并列第一,得分为 0.715,并在我们测试过的所有模型中提供了最一致的 long-context 性能。在 General Finance——我们最大的模块——上,它相比 Opus 4.6 有明显提升,得分为 0.813,而 Opus 4.6 为 0.767;同时,它在同组模型中展现出最好的披露和数据纪律。在演绎逻辑方面,Opus 4.6 曾表现吃力,而 Opus 4.7 表现稳健。

Claude Opus 4.7 扩展了模型调查问题并完成任务的能力边界。Anthropic 显然针对长时间运行中的持续推理进行了优化,市场领先的表现也证明了这一点。随着工程师从与 agent 进行 1:1 协作,转向并行管理多个 agent,这正是能够开启新 workflow 的前沿能力。

我们看到 Claude Opus 4.7 的 multimodal 理解能力有大幅提升,从读取化学结构到解读复杂技术图都更好。更高分辨率支持正在帮助 Solve Intelligence 为生命科学专利 workflow 构建一流工具,覆盖撰写、审查、侵权检测和无效性比对表等环节。

Claude Opus 4.7 在 Devin 中把 long-horizon autonomy 提升到了新水平。它可以连贯工作数小时,面对难题会继续推进而不是放弃,并解锁了一类我们以前无法可靠运行的深度调查工作。

对 Replit 来说,升级到 Claude Opus 4.7 是一个容易做出的决定。对于用户每天开展的工作,我们观察到它能以更低成本达到同等质量——在分析日志和 traces、查找 bug、提出修复方案等任务上更高效、更精准。就我个人而言,我很喜欢它在技术讨论中提出不同意见,帮助我做出更好的决策。它确实感觉像一个更好的同事。

Claude Opus 4.7 在 Harvey 的 BigLaw Bench 上展现出很强的实质准确性,在 high effort 下得分 90.9%,在审阅表格上的推理校准更好,对含糊文档编辑任务的处理也明显更智能。它能正确区分转让条款和控制权变更条款,而这项任务过去一直让 frontier models 感到棘手。在我们的评估中,实质质量始终被评为优势:正确、全面且引用充分。

Claude Opus 4.7 是一个非常出色的 coding 模型,尤其在自主性和更具创造性的推理方面表现突出。在 CursorBench 上,Opus 4.7 的能力有明显跃升,达到 70%,而 Opus 4.6 为 58%。

对复杂多步骤 workflow 而言,Claude Opus 4.7 明显提升:相比 Opus 4.6 高出 14%,使用更少 tokens,tool errors 只有三分之一。它是第一个通过我们隐性需求测试的模型,并且能在工具失败后继续执行,而这些失败过去会让 Opus 直接停下。这种可靠性提升让 Notion Agent 感觉像真正的队友。

在我们的 evals 中,我们看到核心 orchestrator agents 在 tool calls 和规划准确性上有两位数提升。当用户利用 Hebbia 规划并执行检索、幻灯片创建或文档生成等 use cases 时,Claude Opus 4.7 展现出提升这些 workflow 中 agent 决策能力的潜力。

在 Rakuten-SWE-Bench 上,Claude Opus 4.7 解决的生产任务数量是 Opus 4.6 的 3 倍,并在 Code Quality 和 Test Quality 上取得两位数提升。这是有意义的提升,也是我们团队每天交付的工程工作的一次明确升级。

对 CodeRabbit 的代码审查工作负载来说,Claude Opus 4.7 是我们测试过最敏锐的模型。Recall 提升超过 10%,能在我们最复杂的 PR 中发现一些最难检测的 bug;尽管覆盖范围增加,precision 仍保持稳定。在我们的 harness 上,它比 GPT-5.4 xhigh 稍快;我们正准备在发布时把它用于最重的审查工作。

对 Genspark 的 Super Agent 来说,Claude Opus 4.7 准确抓住了生产中最重要的三个差异化指标:loop resistance、一致性和优雅的错误恢复。loop resistance 最关键。一个每 18 个查询中就有 1 个会无限循环的模型,会浪费计算资源并阻塞用户。更低方差意味着 prod 中更少意外。而 Opus 4.7 达到了我们测得的最高 quality-per-tool-call 比率。

Claude Opus 4.7 对 Warp 来说是有意义的提升。Opus 4.6 是面向开发者的最佳模型之一,而这个模型在此基础上可衡量地更全面。它通过了此前 Claude 模型失败的 Terminal Bench 任务,并解决了一个 Opus 4.6 无法破解的棘手并发 bug。对我们来说,这就是信号。

Claude Opus 4.7 是世界上用于构建 dashboard 和数据密集型界面的最佳模型。它的设计品味确实让人意外——它做出的选择是我真的会发布的。它现在是我的默认日常主力。

Claude Opus 4.7 是我们在 Quantium 测试过能力最强的模型。通过我们的专有 benchmarking 方案与领先 AI 模型对比评估后,最大提升出现在最重要的地方:推理深度、结构化问题框定,以及复杂技术工作。更少修正、更快迭代、更强输出,用于解决客户交给我们的最难问题。

Claude Opus 4.7 让人感觉智能水平确实上了一个台阶。代码质量明显改善,它减少了过去会不断堆积的无意义 wrapper functions 和 fallback scaffolding,并且会边写边修复自己的代码。这是我们自 Sonnet 3.7 升级到 Claude 4 系列以来看到的最清晰的一次跃升。

对 XBOW 自动化渗透测试核心的 computer-use 工作而言,新的 Claude Opus 4.7 是一次阶跃变化:在我们的 visual-acuity benchmark 上达到 98.5%,而 Opus 4.6 为 54.5%。我们在 Opus 上最大的痛点基本消失了,这使得我们可以把它用于一整类过去无法使用它完成的工作。

Claude Opus 4.7 对 Vercel 来说是一次稳健升级,没有退化。它在 one-shot coding 任务上表现非常好,比 Opus 4.6 更正确、更完整,也明显更诚实地说明自己的限制。它甚至会在开始工作前对系统代码做 proof,这是我们以前从 Claude 模型中没见过的新行为。

Claude Opus 4.7 非常强,对 Factory Droids 来说,相比 Opus 4.6 在任务成功率上提升了 10% 到 15%,tool errors 更少,对验证步骤的跟进也更可靠。它会把工作一直推进到底,而不是半途停下,这正是企业工程团队所需要的。

Claude Opus 4.7 自主从零构建了一个完整的 Rust text-to-speech 引擎——neural model、SIMD kernels、浏览器 demo——然后把自己的输出送入语音识别器,以验证其与 Python reference 匹配。相当于数月资深工程工作,由模型自主完成。相比 Opus 4.6 的提升很清楚,而且代码库是公开的。

Claude Opus 4.7 通过了三个此前 Claude 模型无法通过的 TBench 任务,并提交了我们之前最佳模型漏掉的修复,包括一个 race condition。它在识别真实问题方面表现出很强的 precision,并能发现其他模型要么放弃、要么未能解决的重要问题。在 Qodo 的真实世界代码审查 benchmark 中,我们观察到了一流水平的 precision。

在 Databricks 的 OfficeQA Pro 上,Claude Opus 4.7 展现出明显更强的文档推理能力:在处理源信息时,错误比 Opus 4.6 少 21%。在我们针对数据的 agentic reasoning benchmark 中,它是表现最好的 Claude 模型,适用于企业文档分析。

对 Ramp 来说,Claude Opus 4.7 在 agent-team workflow 中表现突出。我们看到它在角色一致性、指令遵循、协作和复杂推理方面更强,尤其是在跨工具、代码库和调试上下文的工程任务上。与 Opus 4.6 相比,它需要少得多的逐步指导,帮助我们扩展工程团队运行的内部 agent workflow。

Claude Opus 4.7 在 Bolt 的长时间运行 app 构建工作上可衡量地优于 Opus 4.6,在最佳情况下可提升 10%,且没有我们通常从高度 agentic 模型中预期会出现的退化。它提高了用户在单次会话中可交付内容的上限。
01 /
28
以下是我们对 Opus 4.7 进行早期测试的一些重点和说明:
- 指令遵循。Opus 4.7 在遵循指令方面明显更强。有意思的是,这意味着为早期模型编写的 prompts 有时现在会产生意外结果:过去的模型会宽松解释指令,或完全跳过部分内容;而 Opus 4.7 会按字面执行指令。因此,用户应相应重新调优自己的 prompts 和 harnesses。
- 改进的 multimodal 支持。Opus 4.7 对高分辨率图像具备更好的 vision 能力:它可接受长边最高 2,576 像素(约 3.75 百万像素)的图像,是此前 Claude 模型的三倍以上。这开启了大量依赖精细视觉细节的 multimodal 用途:读取密集截图的 computer-use agents、从复杂图表中提取数据,以及需要 pixel-perfect references 的工作。1
- 真实世界工作。除了在 Finance Agent 评估中取得 SOTA 分数(见上表)外,我们的内部测试还显示,Opus 4.7 比 Opus 4.6 更适合担任金融分析师,能够生成严谨的分析和模型、更专业的演示文稿,并在任务之间实现更紧密的整合。Opus 4.7 在 GDPval-AA 上也是 SOTA;该评估由第三方进行,覆盖金融、法律及其他领域中具有经济价值的知识工作。
- Memory。Opus 4.7 更擅长使用基于文件系统的 memory。它能在长时间、多会话工作中记住重要笔记,并利用这些笔记推进到新任务,因此这些新任务需要的前置上下文更少。
下方图表展示了我们发布前测试中来自不同领域的更多评估结果:
安全与 alignment
总体而言,Opus 4.7 的安全画像与 Opus 4.6 类似:我们的评估显示,欺骗、谄媚以及配合滥用等值得关注的行为发生率较低。在某些指标上,例如诚实性和抵御恶意 “prompt injection” 攻击的能力,Opus 4.7 相比 Opus 4.6 有所改进;在另一些指标上(例如它倾向于对管制物质提供过于详细的 harm-reduction 建议),Opus 4.7 略弱。我们的 alignment 评估认为,该模型“总体上 alignment 良好且可信,尽管其行为并非完全理想”。请注意,根据我们的评估,Mythos Preview 仍然是我们训练过 alignment 最好的模型。我们的安全评估在 Claude Opus 4.7 System Card 中有完整讨论。
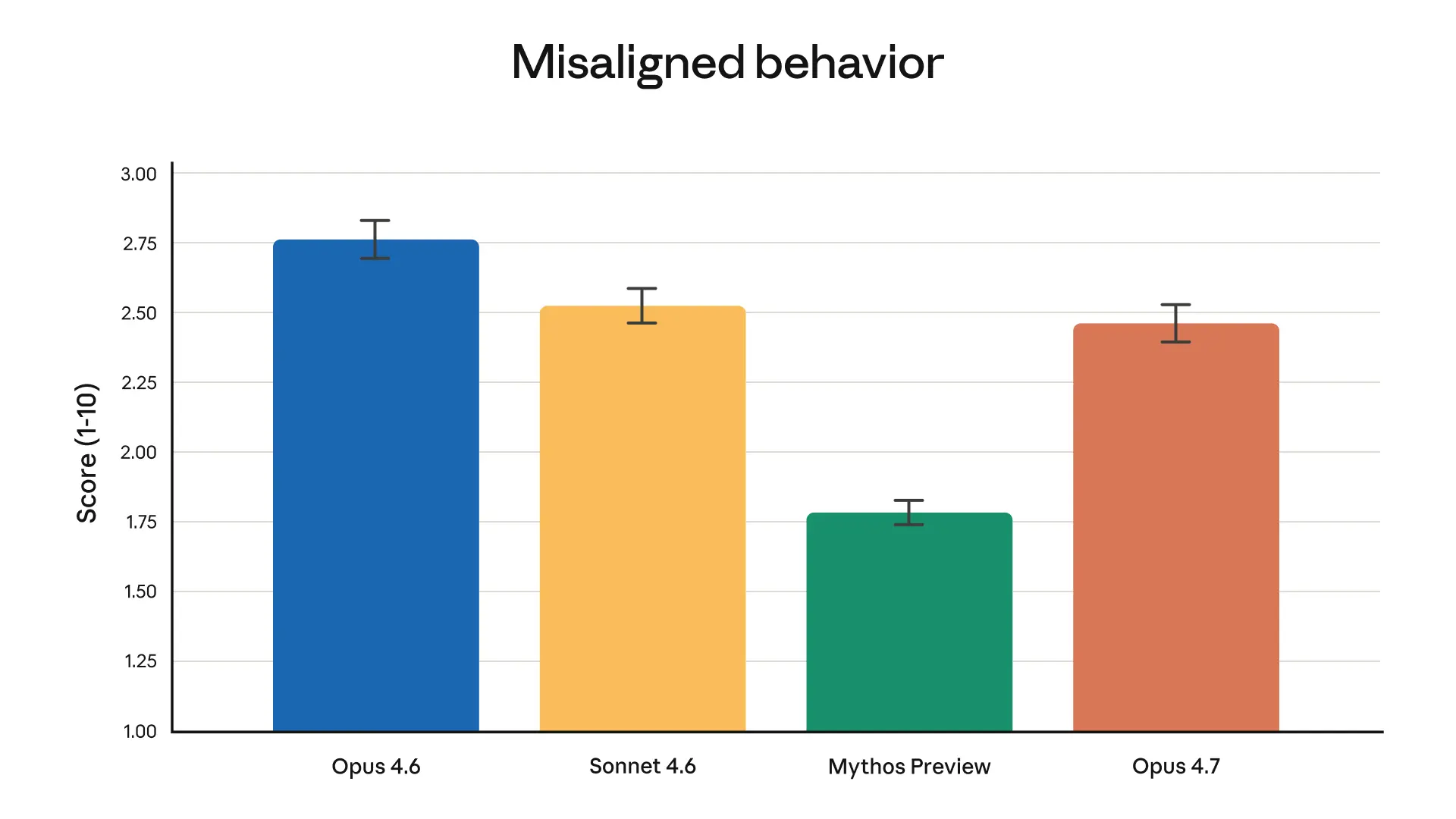
来自我们自动化行为审计的总体 misaligned behavior 分数。在这项评估中,Opus 4.7 相比 Opus 4.6 和 Sonnet 4.6 略有改进,但 Mythos Preview 仍然表现出最低的 misaligned behavior 发生率。
今天同时发布
除了 Claude Opus 4.7 本身,我们还发布以下更新:
- 更多 effort 控制:Opus 4.7 在
high和max之间引入了新的xhigh(“extra high”)effort level,让用户能更细致地控制困难问题上 reasoning 与 latency 之间的权衡。在 Claude Code 中,我们已将所有 plan 的默认 effort level 提升到xhigh。在测试 Opus 4.7 的 coding 和 agentic use cases 时,我们建议从high或xhigheffort 开始。 - 在 Claude Platform(API)上:除了支持更高分辨率图像外,我们还以 public beta 形式推出 task budgets,让开发者能够引导 Claude 的 token 消耗,使其在更长时间运行中对工作进行优先级排序。
- 在 Claude Code 中:新的
/ultrareviewslash command 会生成一个专门的审查会话,通读变更并标记出细心审查者会发现的 bug 和设计问题。我们为 Pro 和 Max Claude Code 用户提供三次免费 ultrareviews 试用。此外,我们已将 auto mode 扩展到 Max 用户。Auto mode 是一种新的权限选项,Claude 会代表你做出决策,这意味着你可以以更少中断运行更长任务——而且风险低于选择跳过所有权限。
从 Opus 4.6 迁移到 Opus 4.7
Opus 4.7 是 Opus 4.6 的直接升级,但有两项变化值得提前规划,因为它们会影响 token 使用量。第一,Opus 4.7 使用了更新的 tokenizer,改进了模型处理文本的方式。代价是,同一输入可能映射到更多 tokens——大约为 1.0–1.35×,具体取决于内容类型。第二,Opus 4.7 在更高 effort levels 下会思考更多,尤其是在 agentic 场景中的后续轮次。这提升了它在困难问题上的可靠性,但也意味着它会生成更多 output tokens。
用户可以通过多种方式控制 token 使用量:使用 effort 参数、调整 task budgets,或 prompt 模型更简洁。在我们自己的测试中,净效果是有利的——如下所示,在一个内部 coding 评估中,所有 effort levels 下的 token 使用效率都有改善——但我们建议在真实流量上衡量差异。我们编写了一份迁移指南,提供关于从 Opus 4.6 升级到 Opus 4.7 的进一步建议。
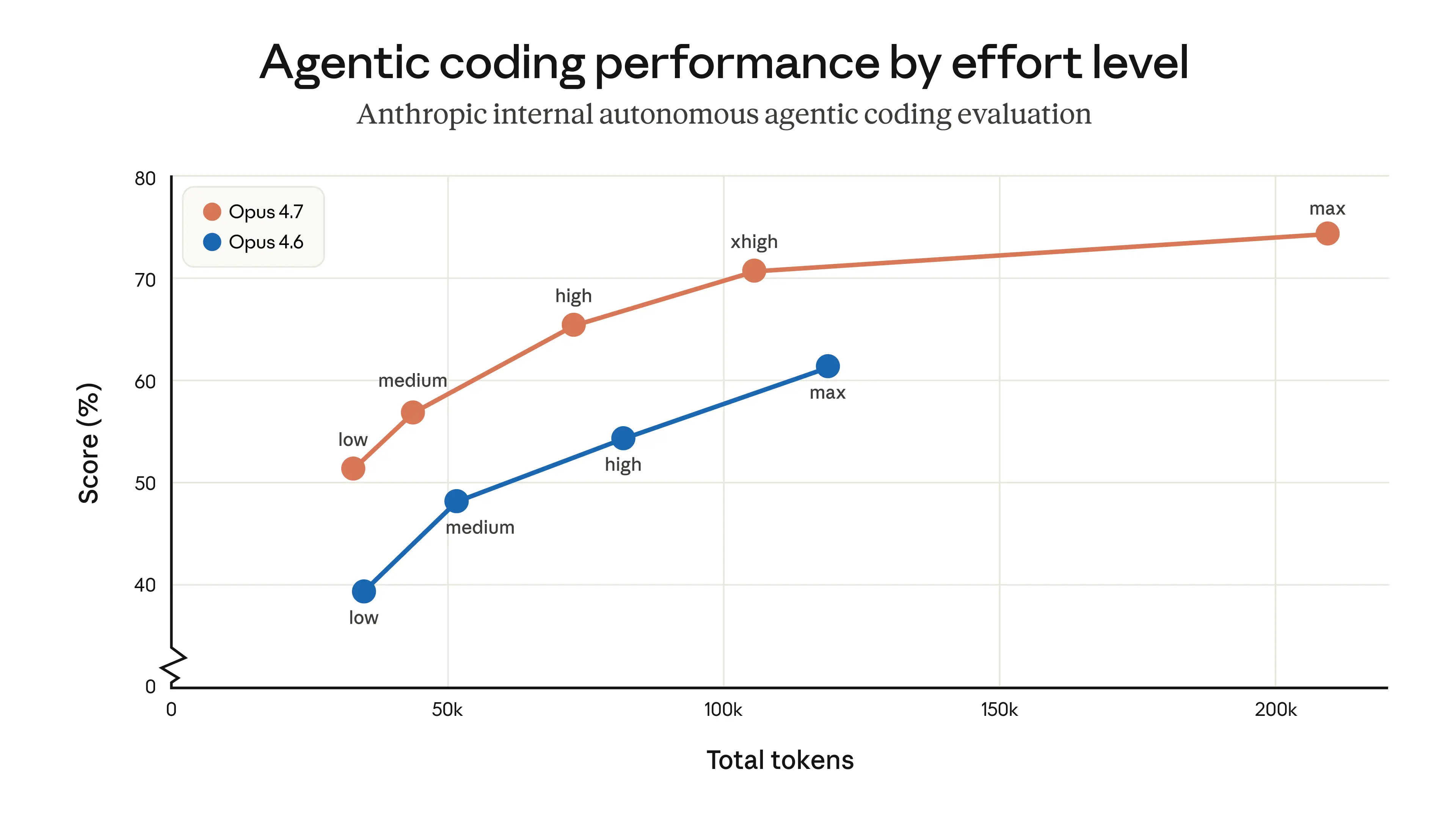
内部 agentic coding 评估中,各 effort level 下分数与 token 使用量的关系。在这项评估中,模型从单个用户 prompt 出发自主工作,结果可能无法代表交互式 coding 中的 token 使用情况。关于调优 effort levels 的更多信息,请参阅迁移指南。
脚注
1 这是一个模型级变化,而不是 API 参数,因此用户发送给 Claude 的图像会直接以更高保真度处理。由于更高分辨率图像会消耗更多 tokens,不需要额外细节的用户可以在发送给模型前对图像进行降采样。
- 对于 GPT-5.4 和 Gemini 3.1 Pro,我们在图表和表格中对比的是可通过 API 获取的最佳报告模型版本。
- MCP-Atlas:Opus 4.6 的分数已更新,以反映 Scale AI 修订后的评分方法。
- SWE-bench Verified、Pro 和 Multilingual:我们的记忆筛查会标记这些 SWE-bench evals 中的一部分问题。排除任何显示出记忆迹象的问题后,Opus 4.7 相比 Opus 4.6 的改进幅度仍然成立。
- Terminal-Bench 2.0:我们使用了 Terminus-2 harness,并关闭 thinking。所有实验都使用 1× guaranteed/3× ceiling 的资源分配,并按每项任务五次尝试取平均。
- CyberGym:Opus 4.6 的分数已从最初报告的 66.6 更新为 73.8,因为我们更新了 harness 参数,以更好地引出网络能力。
- SWE-bench Multimodal:我们对 Opus 4.7 和 Opus 4.6 都使用了内部实现。分数不能与公开排行榜分数直接比较。
相关内容
Anthropic 任命 Theo Hourmouzis 为澳大利亚和新西兰总经理,并正式启用悉尼办公室
关于我们选举防护措施的更新
我们说明了为确保 Claude 在今年美国中期选举和全球其他主要选举中发挥积极作用,我们正在采取哪些措施。