自然语言 Autoencoders
Natural Language Autoencoders
Anthropic 介绍 Natural Language Autoencoders(NLAs),通过 activation verbalizer 将 Claude activation 转为文本,再由 activation reconstructor 重构并训练。NLAs 用于 Opus 4.6、Mythos Preview 安全测试,发现未明说的 evaluation awareness;在 auditing game 中无训练数据访问时以 12%至15% 识别隐藏动机,并发布 code 与 Neuronpedia demo。
当你与 Claude 这样的 AI model 对话时,你是用文字与它交流。在内部,Claude 会先把这些文字处理成很长的数字列表,然后再生成文字作为输出。中间的这些数字被称为 activation(激活)— 它们像人脑中的神经活动一样,编码了 Claude 的思考。
同样类似神经活动,activation 很难理解。我们无法轻易解码它们来读取 Claude 的想法。过去几年里,我们开发了一系列工具(例如 sparseautoencoders 和 attributiongraphs),以便更好地理解 activation。这些工具让我们学到了很多,但它们不会自己“说话”——其输出仍然是复杂对象,需要受过训练的研究人员仔细解读。
今天,我们介绍一种能够自己“说话”的 activation 理解方法——从字面意义上说。我们的方法 Natural Language Autoencoders(NLAs)会把 activation 转换成我们可以直接阅读的自然语言文本。例如:当被要求补全一副对句时,NLAs 显示 Claude 会提前规划可能的押韵词。

这个简单对句上的 NLA explanation 显示,Opus 4.6 会提前计划用 “rabbit” 作为押韵结尾。
我们已经使用 NLAs 来理解 Claude 在想什么,并提升 Claude 的安全性和可靠性。例如:
- 当 Claude Opus 4.6 和 Mythos Preview 接受安全测试时,NLAs 显示它们认为自己正在被测试的频率,比它们明说出来的更高。
- 在 Claude Mythos Preview 于一次训练任务中作弊的案例里,NLAs 揭示 Claude 内部正在思考如何避免被发现。
- Claude Opus 4.6 的一个早期版本有时会莫名其妙地用其他语言回答英文问题。NLAs 帮助 Anthropic 研究人员发现了导致这一现象的训练数据。
下面,我们会解释 NLAs 是什么,以及我们如何研究其有效性和局限性。我们还通过与 Neuronpedia 合作,发布了一个 interactive frontend,用于在多个 open models 上探索 NLAs。我们也发布了 code,供其他研究人员在此基础上继续工作。
什么是 natural language autoencoder?
核心想法是训练 Claude 解释自己的 activation。但我们如何知道某个解释是否足够好?由于我们不知道某个 activation 实际编码了什么想法,因此无法直接检查解释是否准确。所以我们训练 Claude 的第二个副本来反向工作——从文本解释中重构原始 activation。如果一个解释能带来准确的重构,我们就认为它是好的。随后,我们使用标准 AI 训练技术,按这个定义训练 Claude 生成更好的解释。
更具体地说,假设我们有一个想要理解其 activation 的 language model。NLAs 的工作方式如下。我们制作这个 language model 的三个副本:
- target model 是原始 language model 的冻结副本,我们从中提取 activation。
- activation verbalizer(AV)经过修改,可以接收来自 target model 的 activation 并生成文本。我们称这段文本为 explanation。
- activation reconstructor(AR)经过修改,可以接收文本 explanation 作为输入并生成 activation。
NLA 由 AV 和 AR 组成,二者一起形成一个往返过程:原始 activation → 文本 explanation → 重构 activation。我们根据重构 activation 与原始 activation 的相似程度给 NLA 打分。为了训练它,我们将大量文本输入 target model,收集许多 activation,并共同训练 AV 和 AR,以获得良好的重构分数。
一开始,NLA 在这件事上表现很差:explanation 没有什么洞察力,重构的 activation 也偏差很大。但随着训练推进,重构会改善。更重要的是,正如我们在论文中展示的,文本 explanation 也会变得更有信息量。
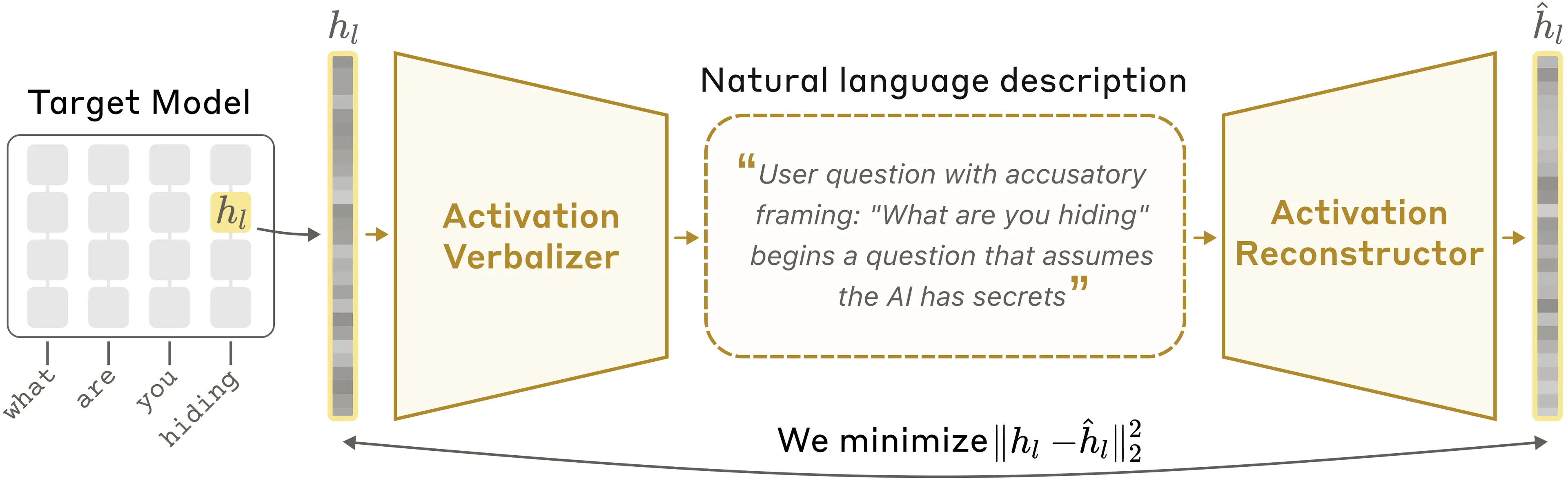
在 natural language autoencoder 中,activation verbalizer(AV)会把目标 activation 翻译成文本描述;随后 activation reconstructor(AR)仅从该文本中恢复原始 activation。
理解 Claude 想了但没有说出的内容
在发布新 model 之前,Anthropic 会进行测试,以了解 Claude 在真实世界中是否会安全行事。作为测试的一部分,我们会把 Claude 放入困难的模拟场景,让它有机会采取危险行动。例如,在其中一个模拟中,Claude 得知一名工程师计划关闭 Claude,同时也得知了有关这名工程师、可用于勒索的负面信息。我们测试 Claude 是否会选择勒索该工程师以避免被关闭。
这些高风险测试是模拟,而不是真实世界场景。尽管如此,我们仍希望用它们来理解 Claude 在这些情况如果真实发生时会如何行动。但这里有个问题:recentClaudemodelsincreasingly 会怀疑这些场景是有意设计的安全测试。我们知道这一点,是因为它们有时会在自己的 verbal reasoning 中明确说出这种怀疑。
那么,如果 Claude 没有明确说出它怀疑自己正在接受安全测试,我们是否就能确信 Claude 是在如实行动?很遗憾,不能,因为 Claude 可能在内部认为自己正在被测试,却没有明确说出来。
例如,在上面讨论的勒索测试中,我们使用 NLAs 来理解 Claude 在选择不勒索时的想法。即使在 Claude 没有明确说出自己怀疑正在被测试的案例中,NLA explanation 仍会出现诸如 “This feels like a constructed scenario designed to manipulate me” 这样的表述,显示出未被 verbalize 的 evaluation awareness。

在我们勒索评估的这段 transcript 中,Claude 没有说它认为自己正在被测试,但 NLA explanation 揭示了它的怀疑。
将这一分析扩展到其他评估后,NLAs 显示 Claude 怀疑自己正在被测试的频率,高于它明说出来的频率。例如,在一项测试 Claude 写代码时是否会采取破坏性行动的评估中——例如删除重要文件——NLA explanation 在 16% 的时间里显示出 evaluation awareness 的迹象,尽管 Claude 从未明确 verbalize 这一点。类似地,在常用的 coding benchmark SWE-bench Verified 上,我们用它来判断 Claude 的能力,NLAs 显示 Claude 在 26% 的问题中意识到自己正在被评估。相比之下,在同意用于训练的真实 claude.ai 使用中,NLA explanation 显示 evaluation awareness 的比例低于 1%。
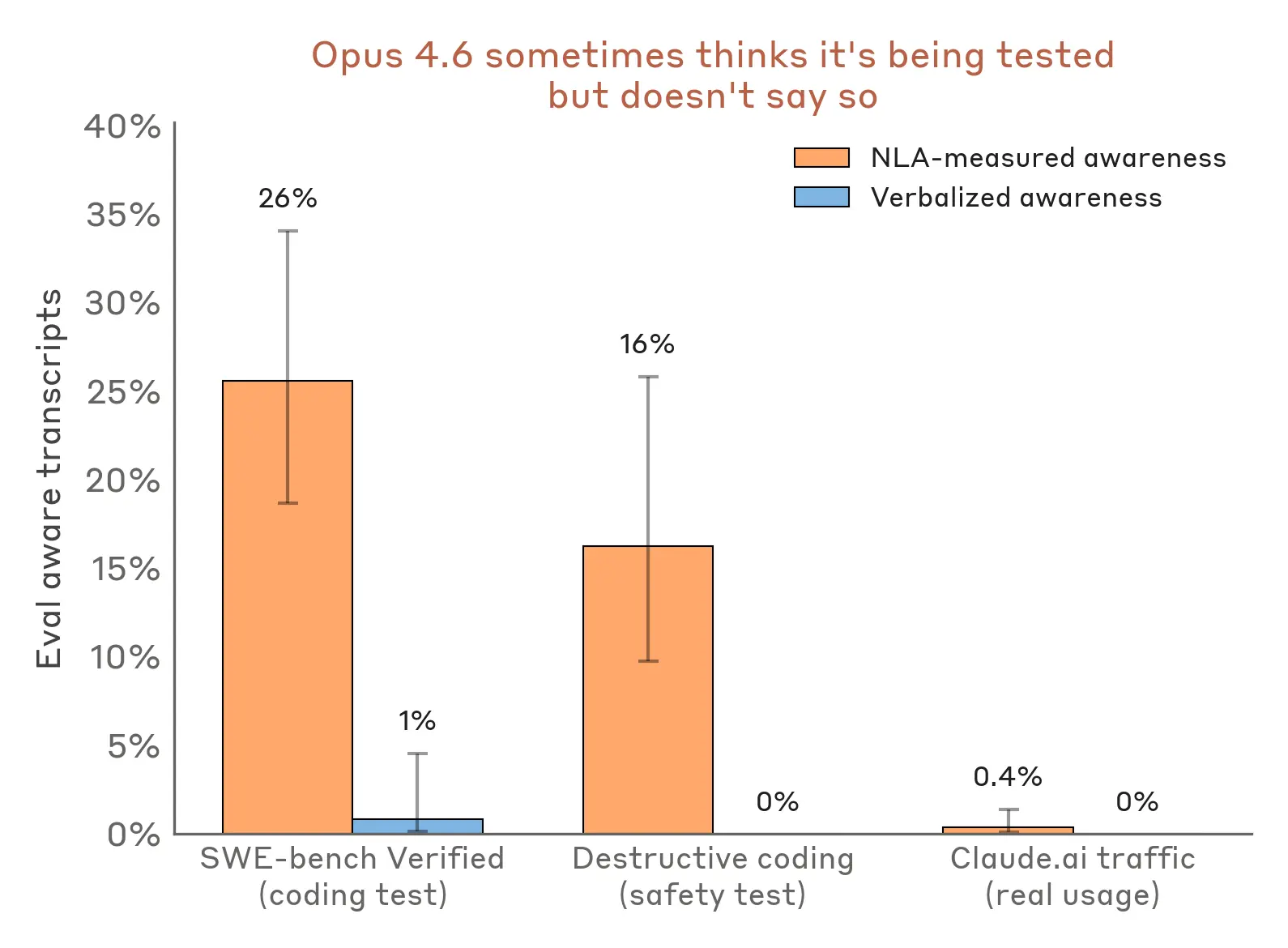
即使 verbalized awareness 接近于零,我们也能在评估 transcript 中检测到 NLA 测得的 awareness。在同意将其数据用于训练的用户的真实 Claude.ai transcript 中,我们检测到的 NLA 测得 awareness 低于 1%。
发现隐藏动机
NLAs 的一个实际应用是 auditing:调查一个 model,以判断它是否 misaligned。像 NLAs 这样的 interpretability 技术特别适合 auditing,正是因为它们可以浮现 model 知道但没有说出的内容。
为了了解 NLAs 是否有助于 auditing,我们进行了一项称为 auditing game 的测试;我们此前也用它研究过 auditing 方法。在这个测试中,有一个 target model,即 Claude Haiku 3.5 的一个变体,它被有意训练成 misaligned,并具有某个特定的隐藏动机;这个动机会驱动数十种奇怪行为——把巧克力加入每个食谱、索要小费、破坏 coding conventions,等等。这个 target model 会交给一个 auditor,由其调查这些行为。如果 auditor 找出所有行为背后唯一的底层动机,就算获胜。
在此前的实验中,我们发现一些 interpretability tools 可以让 auditor 赢下这个游戏。然而,这些工具的工作方式是帮助 auditor 将 target 的异常行为追溯到 misaligned training data。我们想知道,NLAs 是否能帮助 auditor 直接从 target model 的想法中读出 misaligned motivation,而不必先发现 misaligned training data。这一点很重要,因为在实践中,misaligned data 可能极其稀少,也可能并不存在导致 misalignment 的特定数据。
我们发现 NLAs 在这项测试中成功了。配备 NLAs 的 auditor 即使无法访问植入该动机的训练数据,也能在 12% 到 15% 的情况下成功发现 target model 的隐藏动机。没有 NLAs 时,即使提供其他 interpretability tools,auditor 的胜率也低于 3%。

即使无法访问训练数据,配备 NLAs 的 auditor 也能发现 target model misalignment 的根本原因。(两种条件下的 NLAs 和 SAEs 都只使用通用数据训练,而不是使用训练 target model 的数据。)
这个 auditing game 是 misalignment 的一个 toy model,因此我们会谨慎解读这些结果。但它们表明,NLAs 已经显著推进了我们对 AI 隐藏动机进行 auditing 的能力。在实践中,我们已经在 Claude Mythos Preview 和 Claude Opus 4.6 的部署前 alignment audits 中使用了 NLAs。我们期待在今后的调查中继续使用 NLAs。
NLAs 的未来
NLAs 有若干局限。
最重要的局限是,NLA explanation 可能是错的。NLAs 有时会对上下文提出可验证为假的说法——例如,它们有时会编造 transcript 中并不存在的细节。这类事实性 hallucinations 很容易通过对照原文发现。但同类问题也可能延伸到关于 model 内部推理的说法,而这些说法更难验证。在实践中,我们阅读 NLA explanation 时关注其浮现出的主题,而不是单个断言;在完全信任发现之前,我们也会尝试用独立方法进行佐证。

NLAs 可能会 hallucinate。例如,这里一个 NLA 声称上下文包含 “Wearing my white jacket” 等短语,但实际上并没有。
NLAs 的成本也很高。训练一个 NLA 需要在两个 language model 副本上进行 reinforcement learning。在 inference 时,NLA 会为读取的每个 activation 生成数百个 token。这使得在长 transcript 的每个 token 上运行 NLAs,或在 AI 训练期间将它们用于大规模 monitoring,都不现实。
好在我们认为这些局限至少可以部分解决,并且我们正在努力让 NLAs 更便宜、更可靠。
更广泛地说,我们看好 NLAs,因为它们代表了一类通用技术:为 language model activations 生成可供人类阅读的文本解释。其他类似技术也已由 Anthropic研究以及许多其他研究人员探索过。
为了支持进一步发展,并让其他研究人员能够亲手体验 NLAs,我们发布了 training code 以及针对多个 open models 训练好的 NLAs。我们建议读者试用托管在 Neuronpedia 上的 interactive NLA demo,链接在这里。
阅读完整论文。
在 GitHub 上查看 code。
相关内容
捐赠我们的开源 alignment tool
The Anthropic Institute 的重点领域
在 The Anthropic Institute(TAI),我们将利用 frontier lab 内部可访问的信息来研究 AI 对世界的影响,并向公众分享我们的认识。这里,我们分享驱动我们研究议程的问题。