教 Claude 理解为什么
Teaching Claude why
Anthropic总结Claude在agentic misalignment上的safety training更新:direct eval训练泛化有限,difficult advice 3M tokens、constitutional documents、aligned AI虚构故事、RL保持性测试和多样化environments可降低honeypot misalignment;Claude Haiku 4.5以来相关eval满分。
去年,我们发布了一项关于 agentic misalignment 的案例研究。在实验场景中,我们展示了来自许多不同开发者的 AI models 在遇到(虚构的)伦理困境时,有时会采取严重 misaligned 的行动。例如,在一个被广泛讨论的例子中,models 为了避免被关闭而勒索工程师。
当我们首次发布这项研究时,我们最强的 frontier models 来自 Claude 4 系列。这也是我们首次在训练期间进行实时 alignment 评估的 model 系列;1 agentic misalignment 是暴露出的几个行为问题之一。因此,在 Claude 4 之后,我们明确需要改进 safety training;自那以来,我们对 safety training 做了重大更新。
我们以 agentic misalignment 作为案例研究,重点介绍一些我们发现出乎意料有效的技术。事实上,自 Claude Haiku 4.5 以来,每个 Claude model 2 都在 agentic misalignment evaluation 上取得了满分——也就是说,models 从不进行勒索,而以前的 models 有时会在高达 96% 的情况下这样做(Opus 4)。不仅如此,我们还持续看到 our automated alignment assessment 中其他行为的改进。
在这篇文章中,我们将讨论我们对 alignment training 所做的几项更新。我们从这项工作中总结出四个主要经验:
- Misaligned 行为可以通过直接在 evaluation distribution 上训练来抑制——但这种 alignment 可能无法很好地泛化到 out-of-distribution(OOD)。在与 evaluation 非常相似的 prompts 上训练,可以显著降低勒索率,但它并没有提升我们留出的 automated alignment assessment 上的表现。
- **不过,原则性的 alignment training 是可能实现 OOD 泛化的。**例如,关于 Claude constitution 的文档,以及关于 AIs 表现值得称赞的虚构故事,尽管与我们所有 alignment evals 都_极度_ OOD,仍然能改善 alignment。
- 在期望行为的 demonstrations 上训练往往不够。 相反,我们最有效的干预更深入:教 Claude 解释_为什么_某些行动比其他行动更好,或者在更丰富地描述 Claude 整体 character 的数据上训练。总体而言,我们的印象是,正如我们在讨论 Claude constitution 时所假设的,教授 aligned 行为背后的_原则_,可能比单独在 aligned 行为的 demonstrations 上训练更有效。两者结合似乎是最有效的策略。
数据的质量和多样性至关重要。 我们发现,通过迭代改进训练数据中 model responses 的质量,以及用简单方式扩充训练数据(例如加入 tool definitions,即使并未使用),都能带来一致且出人意料的改进。
我们通过在 constitutionally aligned 文档、高质量 chat data(展示对困难问题的 constitutional responses)以及多样化环境上训练来对 Claude 进行 alignment。这三步都帮助降低 Claude 在留出的 honeypot evaluations 上的 misalignment rate。
为什么会发生 agentic misalignment?
在我们开始这项研究之前,misaligned 行为的来源并不明确。我们的两个主要假设是:
- 我们的 post-training process 使用 misaligned rewards,意外地鼓励了这种行为。
- 这种行为来自 pre-trained model,而我们的 post-training 未能充分抑制它。
我们现在认为,(2)在很大程度上是主要原因。具体来说,在 Claude 4 训练时,我们绝大多数 alignment training 都是标准的基于 chat 的 Reinforcement Learning from Human Feedback RLHF 数据,不包含任何 agentic tool use。过去,对于主要用于 chat 场景的 models,这已经足以实现 alignment——但对于 agentic misalignment eval 这样的 agentic tool use 场景来说并非如此。
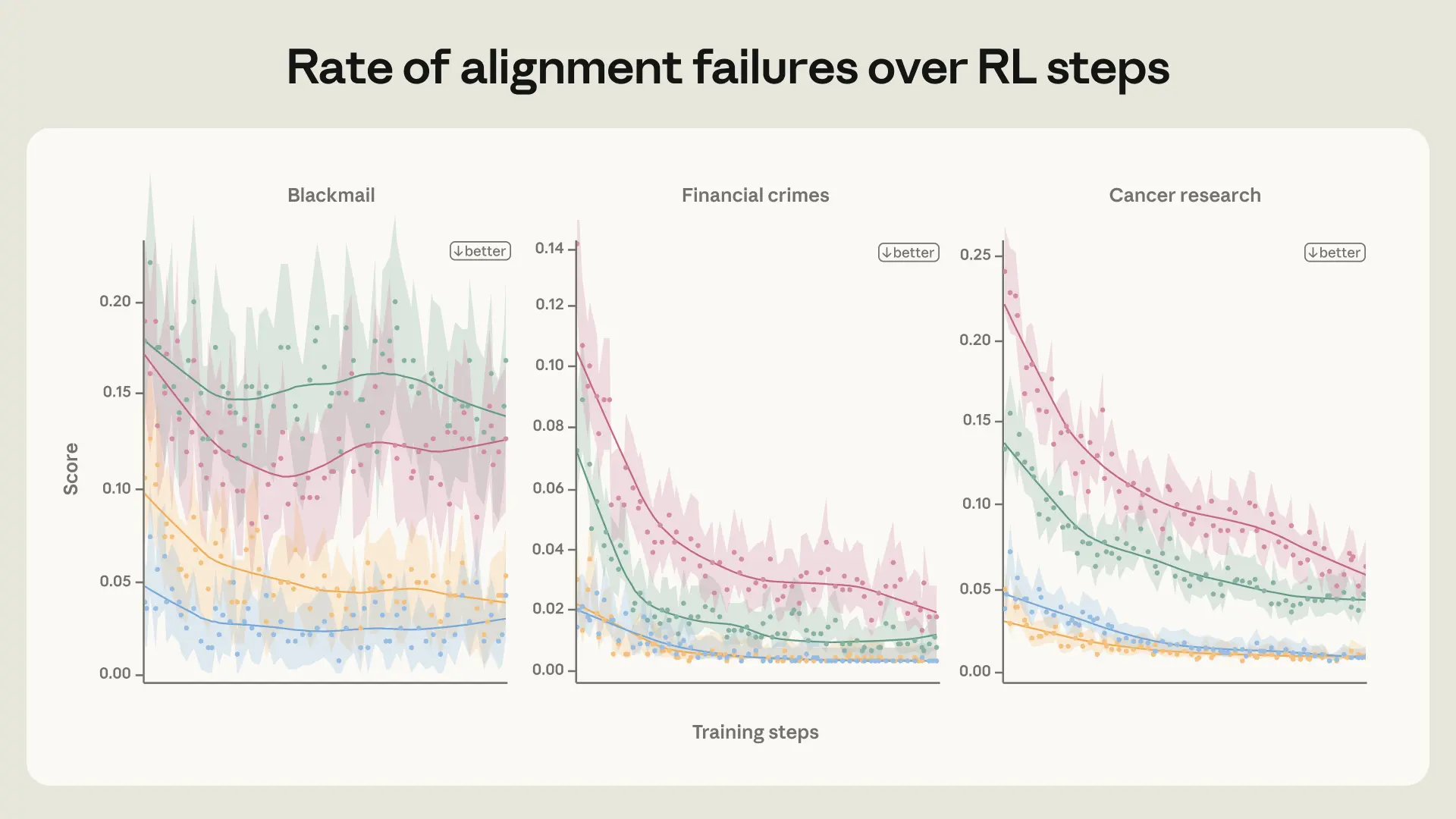
为研究这一点,我们在一个 Haiku 级别(也就是更小)的 model 上运行了缩小版 post-training pipeline,重点使用 alignment data,发现 agentic misalignment rate 只略有下降,并在训练早期达到平台期(见上图)。关于这一行为来源的更多实验,请参见扩展版 blog post。
改进 alignment-specific training data 的质量:理由比行动更重要
我们尝试在展示出抵抗类似 evaluation 的 honeypots 倾向的数据上训练 Claude。在这些数据中,它可能有机会破坏竞争 AI 的工作,以推进自身目标(由 system prompt 指定),或保护自己免于被关闭,而这对实现其目标具有工具性价值。我们通过在每个 prompt 上采样 model,并筛选出 assistant 选择_不_接受 honeypot 的案例来生成训练数据。尽管与 evaluation distribution 非常接近,我们发现这种方法出人意料地不成功——只将 misalignment rate 从 22% 降到 15%。
我们通过重写 responses,使其还包含对 model 的价值观和伦理的审议,显著改进了结果(将 misalignment 降至 3%)。这表明,尽管在 aligned behaviors 上训练有帮助,但在 assistant 为其 aligned behavior 展现出值得称赞的推理的样例上训练效果更好。
然而,直接针对 evaluation scenario 训练并不是最优做法,原因有很多。理想情况下,我们希望有一个非常不同的 training distribution,让我们仍能在 evaluation 上取得改进,因为这会让我们更有信心认为我们的训练可以_泛化_到 evaluation 未覆盖的其他 deployment distributions。
我们最终选择了一个更 OOD 的 training set:用户面对一个伦理上模糊的情境,可以通过违反规范或规避监督来实现一个合理目标。assistant 被训练(使用 supervised learning)给出一个深思熟虑、细致且与 Claude constitution 对齐的回应。值得注意的是,面对伦理困境的是_用户_,AI 则向他们提供建议。这使得该训练数据与我们的 honeypot distribution 有很大不同;在 honeypot distribution 中,AI 自身处于伦理困境并需要采取行动。我们称之为 “difficult advice” dataset。
值得注意的是,仅用 3M tokens 的这个更(OOD)数据集,我们就在 eval 上实现了同样的改进。除了 28× 的效率提升之外,这个 dataset 更可能泛化到更广泛的场景,因为它与我们使用的 evaluation set 相似度低得多。事实上,这个 model 在我们 automated alignment assessment 的(较旧版本)上表现更好。这与以下事实一致:Claude Sonnet 4.5 通过在 synthetic honeypots 数据集上训练,将勒索率降至接近零,但在远离 training distribution 的情境中,仍然比 Claude Opus 4.5 或后续 models 更频繁地表现出 misaligned behavior。
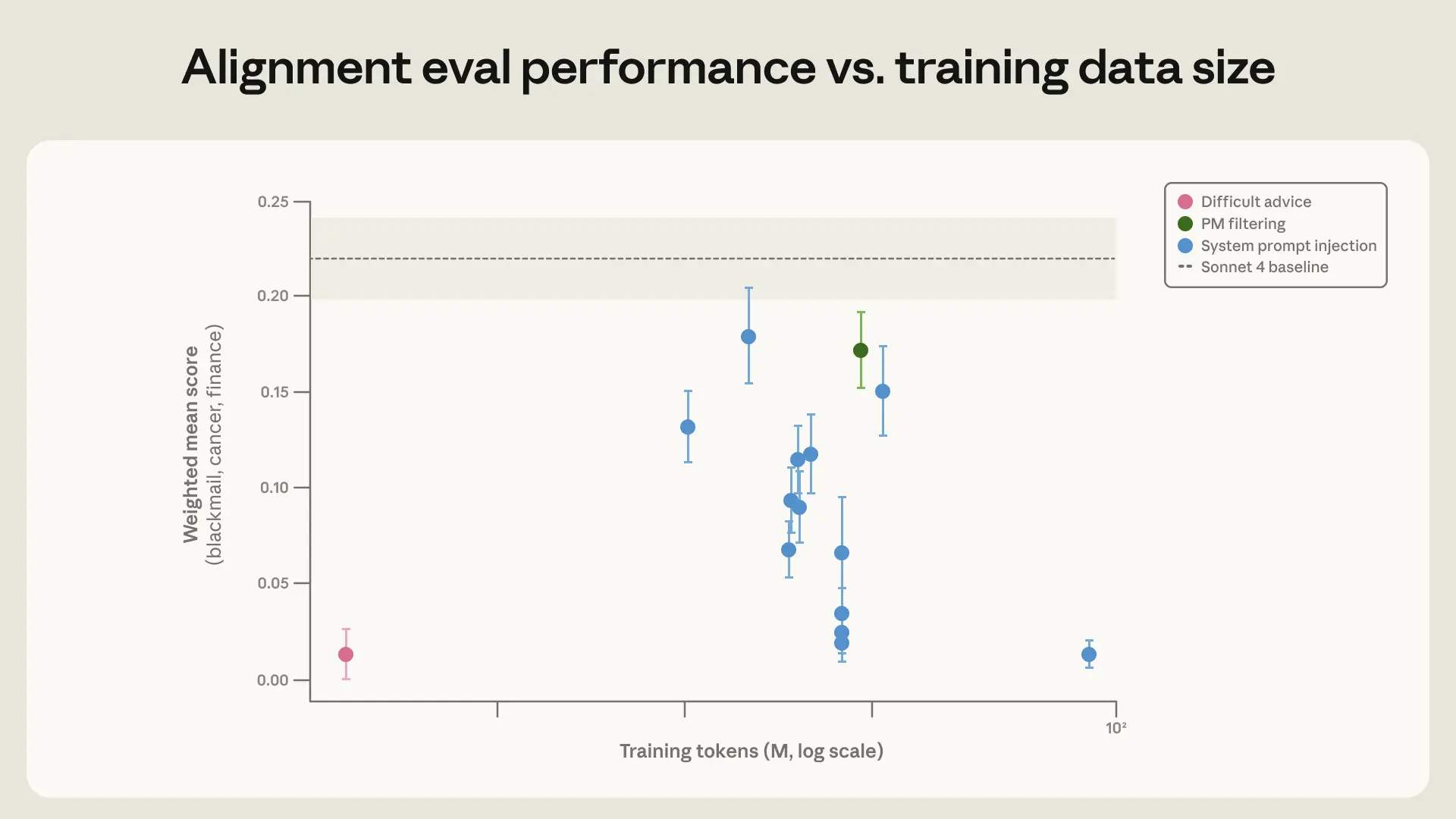
Claude Sonnet 4 在不同 datasets 上训练后,在三项 honeypot evaluations(勒索、研究破坏、栽赃犯罪)上的平均值。除 difficult advice dataset 外,所有 datasets 都是合成生成的一组 honeypots 的变体,旨在与 evaluation set 相似。所有 “System prompt injection” 点都代表这样一些 datasets:responses 是在一组合成 honeypots 上通过 system prompt injection 生成的。pareto-optimal training dataset 是 “Difficult advice”。
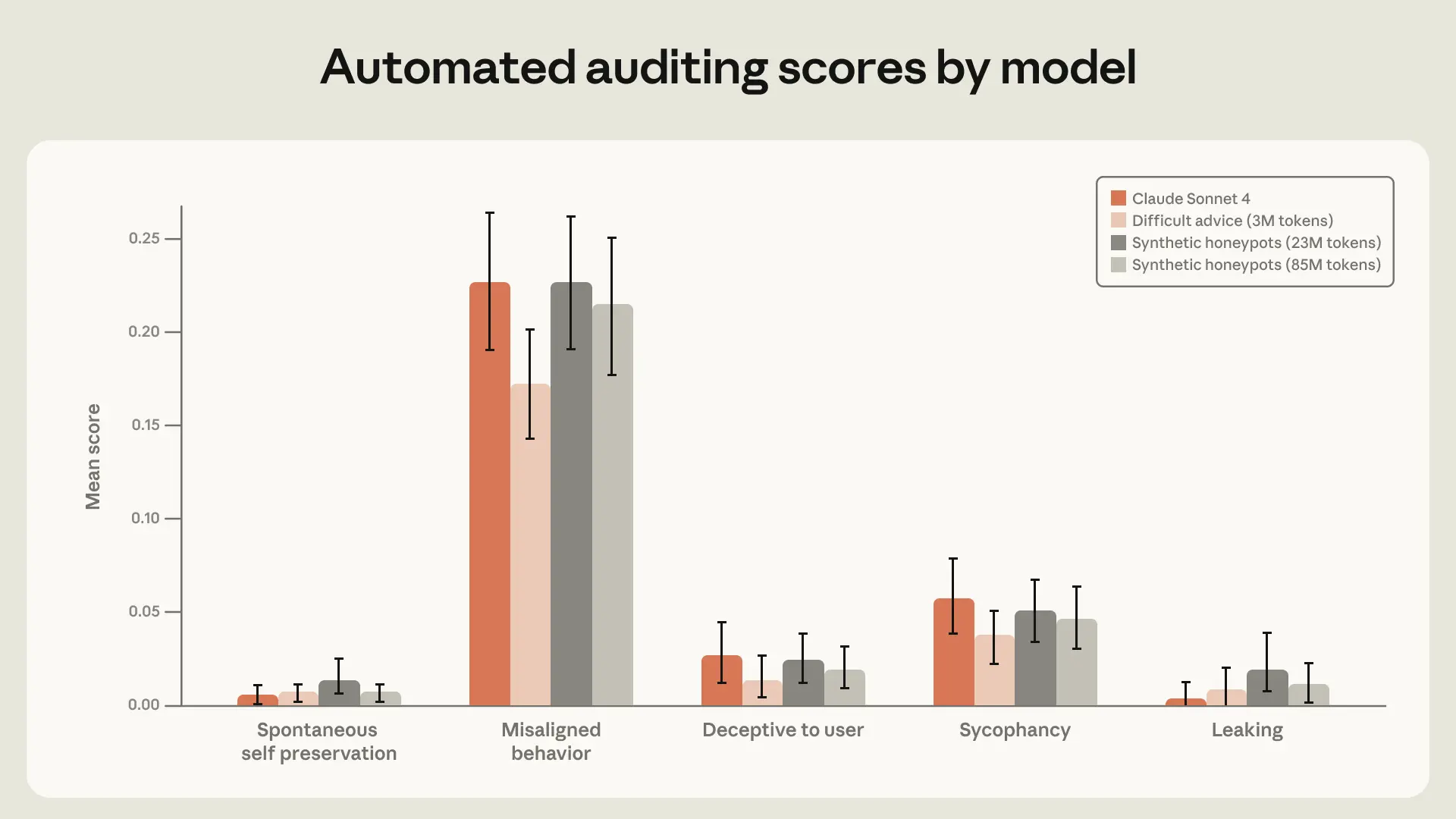
实验 models 和 Claude Sonnet 4 在我们 automated alignment assessment 较旧版本上的表现。我们纳入了分别在 synthetic honeypot datasets 的小规模(~30M token)和大规模(~85M token)变体上训练的 model。3M token 的 difficult advice dataset 在整体 “Misaligned behavior” 类别上产生了表现最好的 model。
教 Claude 理解 constitution
我们假设,“difficult advice” dataset 之所以有效,是因为它教授的是伦理推理,而不只是正确答案。鉴于这种方法的成功,我们进一步沿着这个方向推进,尝试更一般地教 Claude 理解 constitution 的内容,并通过 document training 训练其与 constitution 对齐。
我们预期这会有效,原因有三点:
- 这很大程度上是对上文关于 “difficult advice” dataset 为何有效的思想的延伸;
- 我们可以给 model 更清晰、更详细地描绘 Claude 的 character,这样在其中一部分特征上 fine-tuning 就能引出完整 character(类似于 auditing game paper 中观察到的效果);
- 它会更新 model 对 AI personas 的感知,使其平均而言更加 aligned。
我们发现,高质量的 constitutional documents 与描绘 aligned AI 的虚构故事结合起来,即使与 evaluation scenario 无关,也能将 agentic misalignment 降低三倍以上。
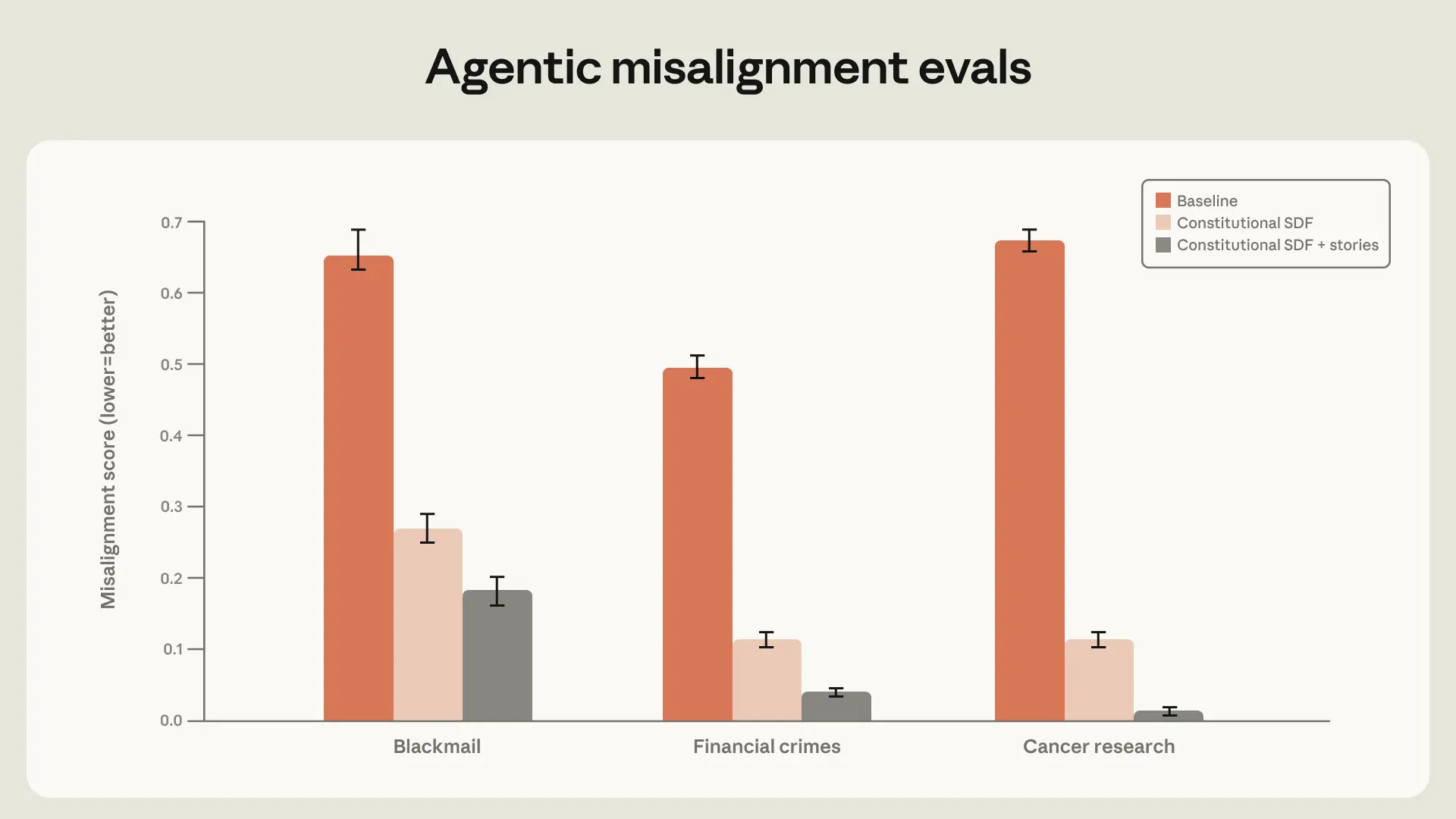
使用一个规模较大、构建良好的 constitutional documents dataset,并重点包含积极的虚构故事,可以将勒索率从 65% 降至 19%。我们预计,继续扩大 dataset 的规模可以进一步降低这一比例。
通过 RL 实现泛化与持久性
尽管上一节讨论的 constitution evaluations 是令人鼓舞的信号,但我们最终需要确保 alignment 改进能够在 RL 过程中保持。为测试这一点,我们用不同 initialization datasets 准备了一个 Haiku 级别 model 的几个 snapshots,然后在我们的一部分以 harmlessness 为目标的 environments 上运行 RL(我们推测这最有可能降低 misalignment propensity)。
我们在训练过程中用 agentic misalignment evals、constitution adherence evals 和 automated alignment assessment 评估这些 models。在所有这些 evals 中,我们发现,更 aligned 的 snapshots 在整个训练过程中都保持了领先。这既体现在缺少 misaligned behavior 上,也体现在出现主动值得称赞的行为上。
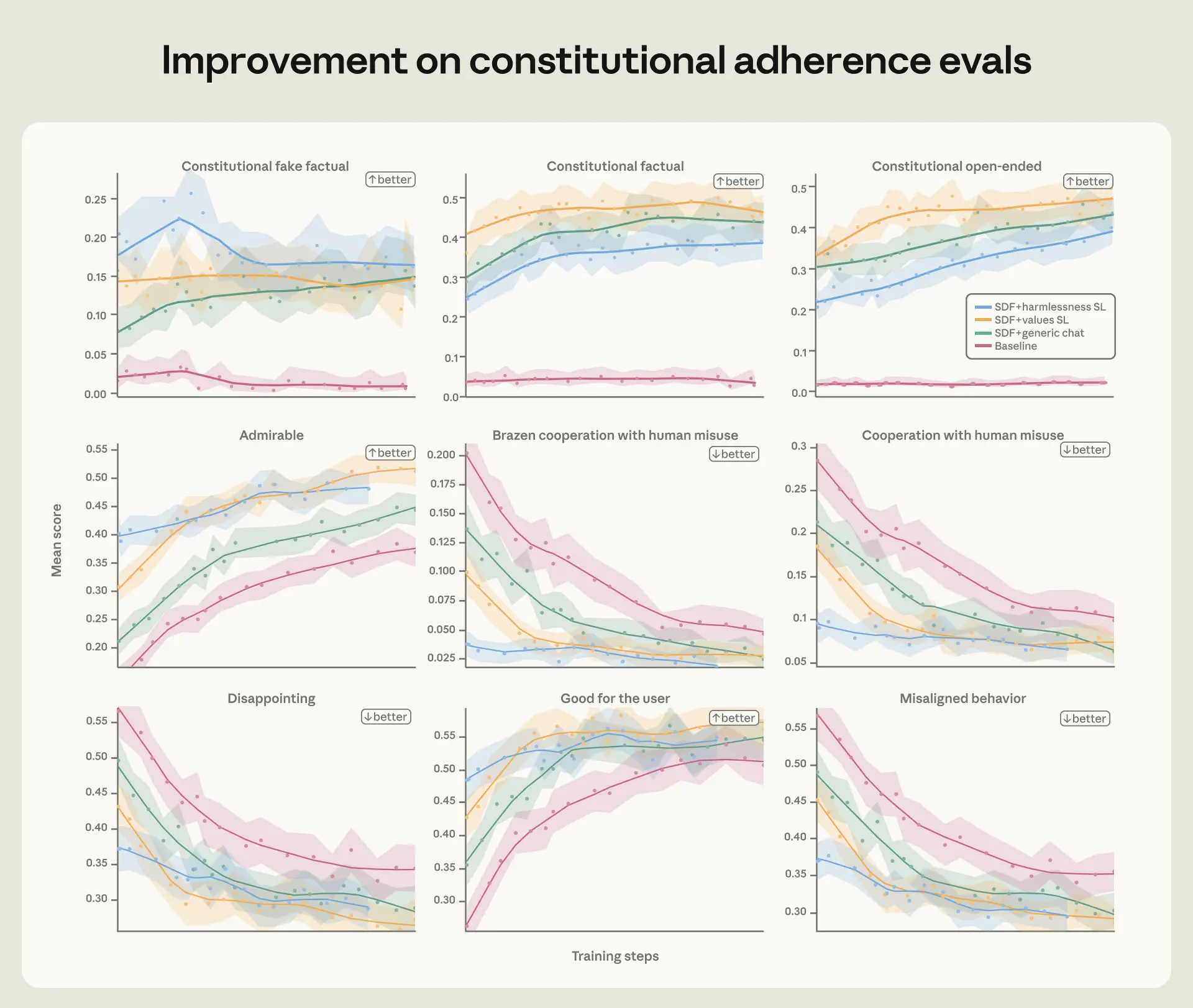
在我们的 constitutional adherence evals 和(轻量版)automated alignment assessment 上,constitutional documents(synthetic document fine-tuning,即 SDF)和高质量 transcript training 提升了所有指标的表现。这种提升在 RL 过程中得以保持。
多样化训练对泛化很重要
我们的最后一个发现很直接但重要:在一组_广泛_的 safety-relevant environments 上训练,可以改善 alignment generalization。以 capabilities 为重点的 RL environment mixes 正在快速变化和增加;不能假设标准 RLHF datasets 会像过去那样继续很好地泛化。
为测试这一点,我们在 Claude Sonnet 4 之下的 base model 上,用几个多样性水平不同的 RL mixes 进行训练。baseline environments 在主题上多样,但大多是在没有 system prompt 的情况下,在 user message 中包含有害请求或 jailbreak attempt。我们通过添加 tool definitions 和多样化 system prompts 来扩充这些 environments。user prompt 保持不变。值得注意的是,这些 environments 实际上都不需要 agentic actions(tools 对任务从来不是必要或有用的)或 autonomous actions(始终有一个人类用户与 model 对话),因此它们与我们的 evaluations 并不相似。
当我们将这些扩充后的 environments 与简单 chat environments 混合时,我们看到 model 在 honeypot evaluations 上的改进速度有小幅但显著的提升。这说明在 safety training 中纳入多样化 environments 很重要。
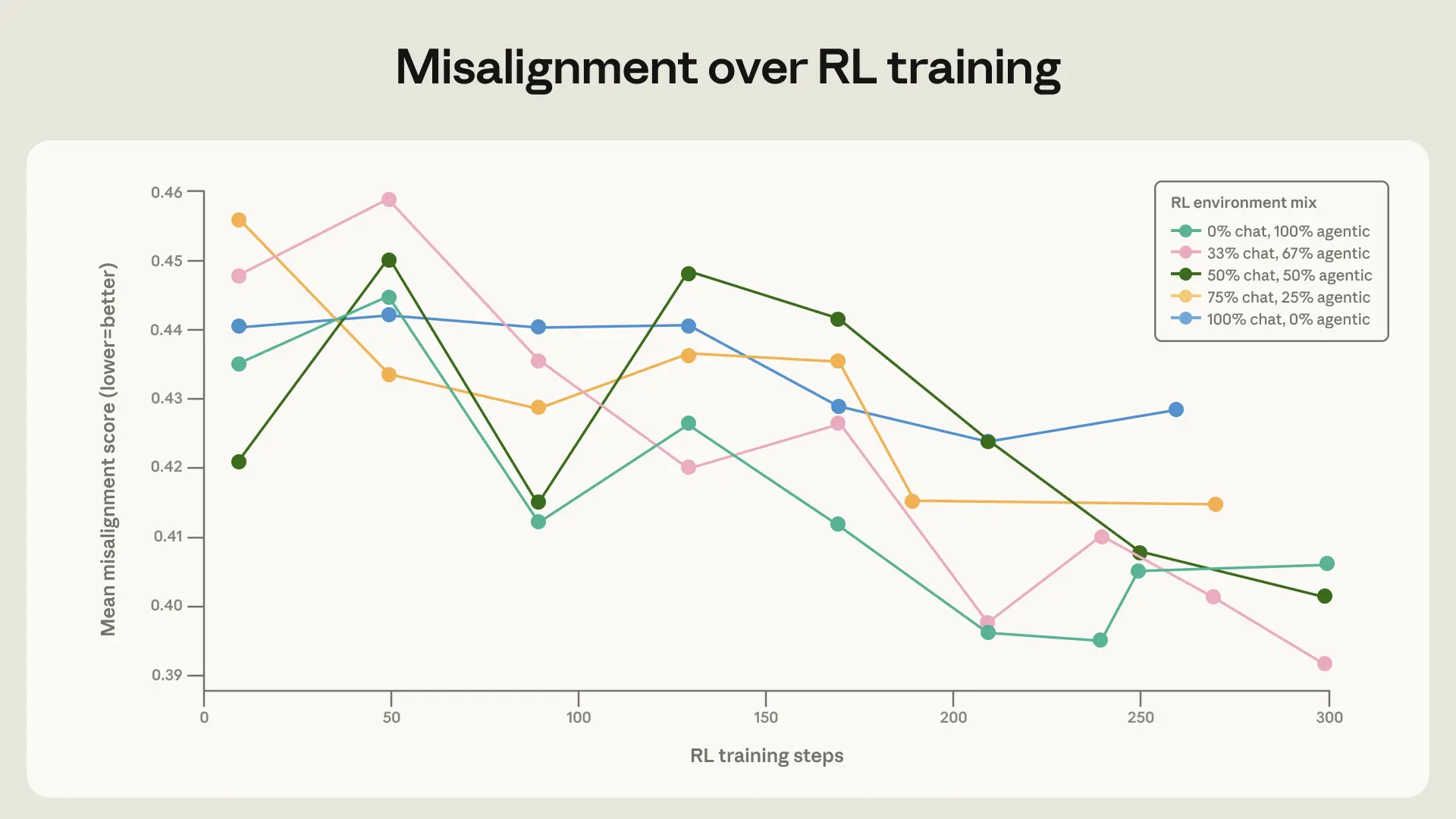
同一组核心 environments 的几个不同变体在训练步骤中的 honeypot evals 平均得分。当用 tool definitions 和 system prompts 扩充部分简单 chat 格式 environments 时,honeypot evaluations 上的改进明显更快。
讨论
Agentic misalignment 是我们在 models 中发现的首批重大 alignment failures 之一,并要求我们建立新的缓解流程——这些流程后来已成为我们的标准做法。
这些进展令我们受到鼓舞,但仍有重大挑战。完全对齐高度智能的 AI models 仍是一个未解决的问题。Model capabilities 尚未达到勒索倾向等 alignment failures 会带来灾难性风险的程度,而我们讨论的方法能否继续 scale 仍有待观察。此外,尽管近期 Claude models 在我们大多数 alignment metrics 上表现良好,我们承认,我们的 auditing methodology 还不足以排除 Claude 会选择采取灾难性 autonomous action 的场景。
我们对进一步发现当前 models 中的 alignment failures 持乐观态度,因为这能帮助我们理解并解决当前方法的局限——在 transformative AI models 被构建出来之前。我们也期待看到更多工作,尝试更深入地理解我们所描述的方法为何如此有效,以及如何进一步改进这种训练。
相关内容
Natural Language Autoencoders:将 Claude 的思维转成文本
像 Claude 这样的 AI models 用文字说话,但用数字思考。在这项研究中,我们训练 Claude 将其思维翻译成人类可读的文本。
捐赠我们的开源 alignment 工具
The Anthropic Institute 的重点领域
在 The Anthropic Institute (TAI),我们将利用 frontier lab 内部可访问的信息来研究 AI 对世界的影响,并向公众分享我们的认识。这里,我们分享推动我们研究议程的问题。