Sub-32B 开放权重
Sub-32B Open Weights
阿里巴巴Qwen3.5 27B(推理型)与Google DeepMind Gemma 4 31B(推理型)在Artificial Analysis Intelligence Index上分别得分42和39,与GPT-5(medium/low)持平。Qwen3.5 27B在Agentic Index得55分,领先GPT-5(medium)的46分;Gemma 4 31B在TerminalBench Hard(36% vs. 27%)和HLE(23% vs. 18%)上领先GPT-5(low)。两模型均可在单张H100(80GB)以BF16运行,或量化后在MacBook本地部署。Qwen3.5 27B消耗9800万输出token,Gemma 4 31B消耗3900万token,后者token效率高2.5倍。两模型在AA-Omniscience得分分别为-42和-45,落后于GPT-5的-10。
Sub-32B 开放权重模型
所有文章 2026年4月14日
Sub-32B 开放权重模型现已达到 GPT-5 级别的智能水平
Sub-32B 开放权重模型现已达到 GPT-5 级别的智能水平:Qwen3.5 27B(推理型)在 Artificial Analysis Intelligence Index 上得分为 42,与 GPT-5(medium)持平;Gemma 4 31B(推理型)得分为 39,与 GPT-5(low)持平。
阿里巴巴的 Qwen3.5 和 Google DeepMind 的 Gemma 4 是最近发布的两个开放权重系列,推动了 sub-32B 总参数量模型类别的发展。两者均提供多种尺寸,包含推理型和非推理型变体,并支持原生多模态输入。它们共同代表了该参数量下开放权重智能的最先进水平。Qwen3.5 27B 在 Artificial Analysis Intelligence Index 上达到了更高的绝对智能水平,而 Gemma 4 31B 则更具 token 效率。
尽管这些 sub-32B 模型现已匹配 GPT-5 级别的智能分数,但其智能构成有所不同。与 GPT-5 变体相比,这两个开放权重模型在事实知识和幻觉避免方面明显落后:AA-Omniscience 得分为 -42(Qwen3.5 27B)和 -45(Gemma 4 31B),而 GPT-5(medium)为 -10,GPT-5(low)也为 -10。开放权重模型取得进展的主要领域在于 agent 性能和关键推理:Qwen3.5 27B 在 Artificial Analysis Agentic Index 上以 55 分大幅领先 GPT-5(medium)的 46 分;Gemma 4 31B 在 TerminalBench Hard(36% vs. 27%)和 HLE(23% vs. 18%)上领先 GPT-5(low)。
Qwen3.5 27B 和 Gemma 4 31B 均可在单个 NVIDIA H100(80GB)上以 BF16 精度运行,通过量化甚至可以在 MacBook 上本地运行。这是一个实用的门槛,使得这些模型在数据中心之外也能被使用。这与上一代相比是一个重大转变:Gemma 3 于 2025 年 3 月作为非推理模型发布,在 Intelligence Index 上得分为 10。Qwen3 有两个迭代版本——原始 Qwen3 系列和 2507 更新版,旗舰型号 Qwen3 235B A22B(推理型)在原始版本上得分为 20,在 2507 变体上得分为 30。
关键要点:
➤ Qwen3.5 27B(推理型)在 Intelligence Index 上得分为 42,消耗 9800 万输出 token;而 Gemma 4 31B(推理型)得分为 39,消耗 3900 万 token。 这 2.5 倍的 token 效率差距是关键的权衡点。Qwen3.5 27B 的优势广泛——GPQA(86%)和 IFBench(76%);而 Gemma 4 31B 在 SciCode(+3.9 个百分点)和 TerminalBench Hard(+3.8 个百分点)上领先。
➤ 两个系列在 sub-32B 类别中均提供原生多模态输入。 Qwen3.5 27B(推理型)在 MMMU-Pro 上得分为 75%,Gemma 4 31B(推理型)得分为 73%,使它们成为该参数量下需要视觉理解能力的应用中领先的两个开放权重选择。
➤ 尽管匹配了 GPT-5 的分数等级,但两个模型在 AA-Omniscience 上仍大幅落后——这与较小的模型规模存在已知相关性: Qwen3.5 27B(推理型)得分为 -42,Gemma 4 31B(推理型)得分为 -45。相比之下,GPT-5(medium)得分为 -10,而 Qwen3.5 自家的 397B A17B 兄弟模型得分为 -30。知识回忆受益于更大的参数量,这些 sub-32B 模型无法仅靠推理努力来缩小这一差距。
➤ 开放权重的前沿也已显著超越 32B 参数量。 GLM-5.1(推理型)在 Intelligence Index 上以 51 分领先开放权重模型,Kimi K2.5(推理型)为 47 分,Qwen3.5 397B A17B(推理型)为 45 分,尽管这些模型远大于 sub-32B 模型。顶级开放权重模型与专有前沿(Gemini 3.1 Pro Preview 和 GPT-5.4(xhigh)均为 57 分)之间的差距已缩小至仅 6 分。
➤ 在 32B 以下的开放权重模型中,Qwen3.5 占据了智能 vs. 总参数量和智能 vs. 活跃参数量的 Pareto 前沿。 得分为 42 的密集 27B(推理型)与 122B A10B MoE 模型相当,但总权重仅为后者的五分之一;得分为 37 的 35B A3B(推理型)仅激活 3B 参数。得分为 39 的 Gemma 4 31B(推理型)是总参数量方面的主要挑战者,而得分为 31 的 26B A4B(推理型)则在约 4B 活跃参数层级展开竞争。
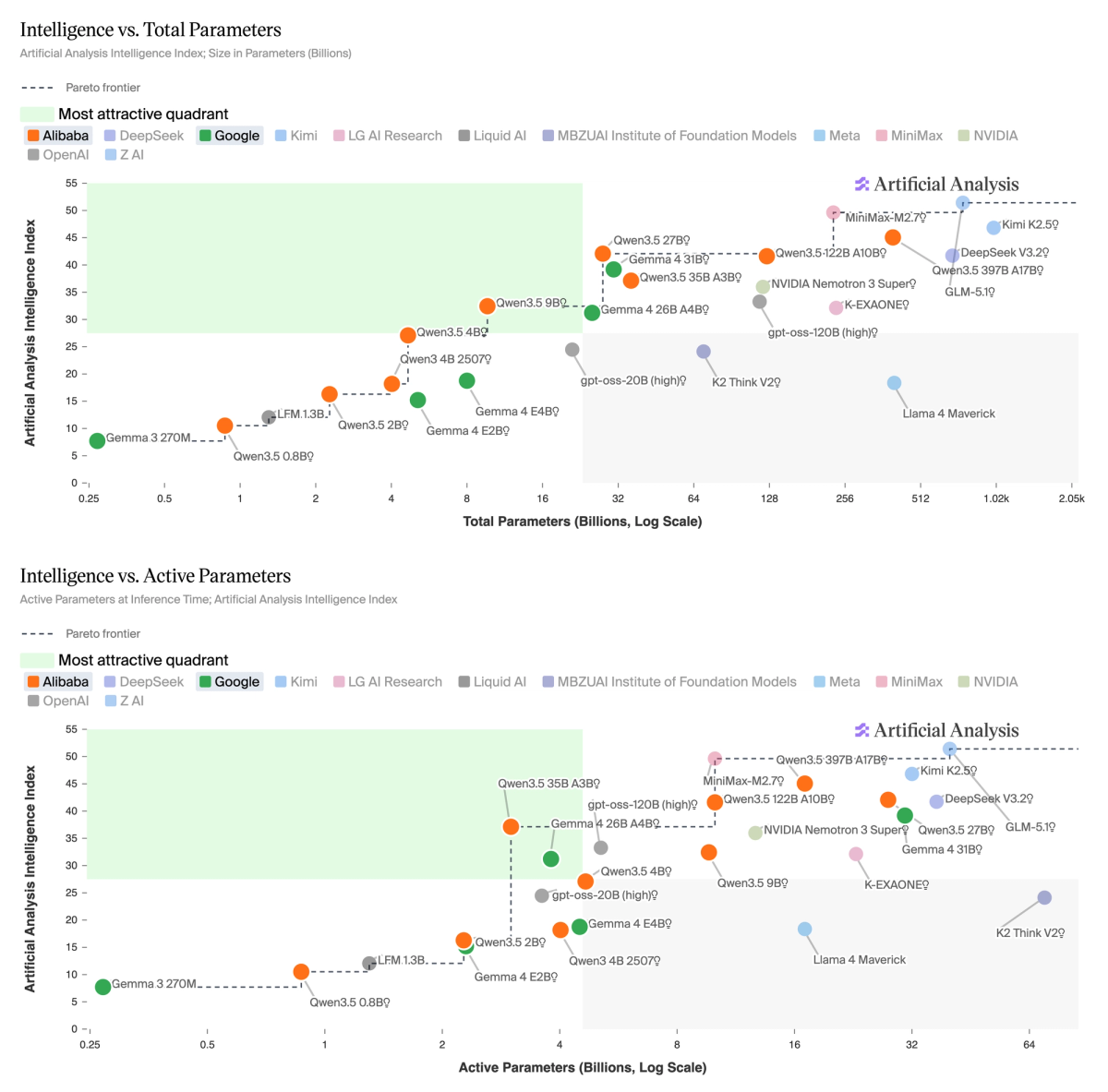
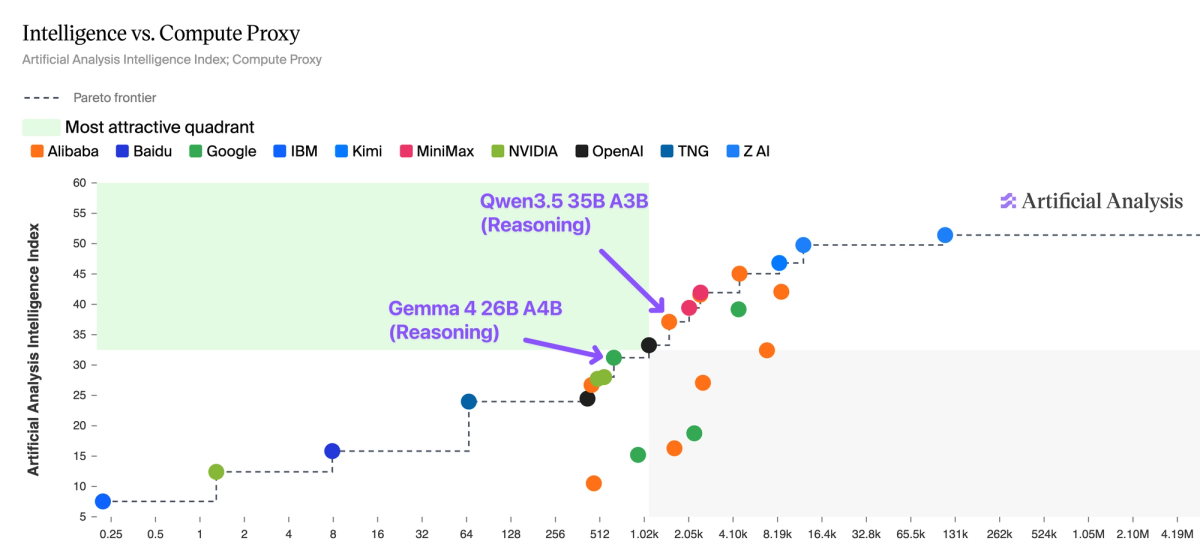
Gemma 4 处于智能 vs. 计算代理(Compute Proxy)的 Pareto 前沿——这是我们开发的一个指标,用于估算总推理计算量,同时考虑活跃参数和 token 生成。Qwen3.5 35B A3B(推理型)得分为 37,但消耗了 1 亿输出 token;而 Gemma 4 26B A4B(推理型)仅消耗 7300 万 token,得分为 31。
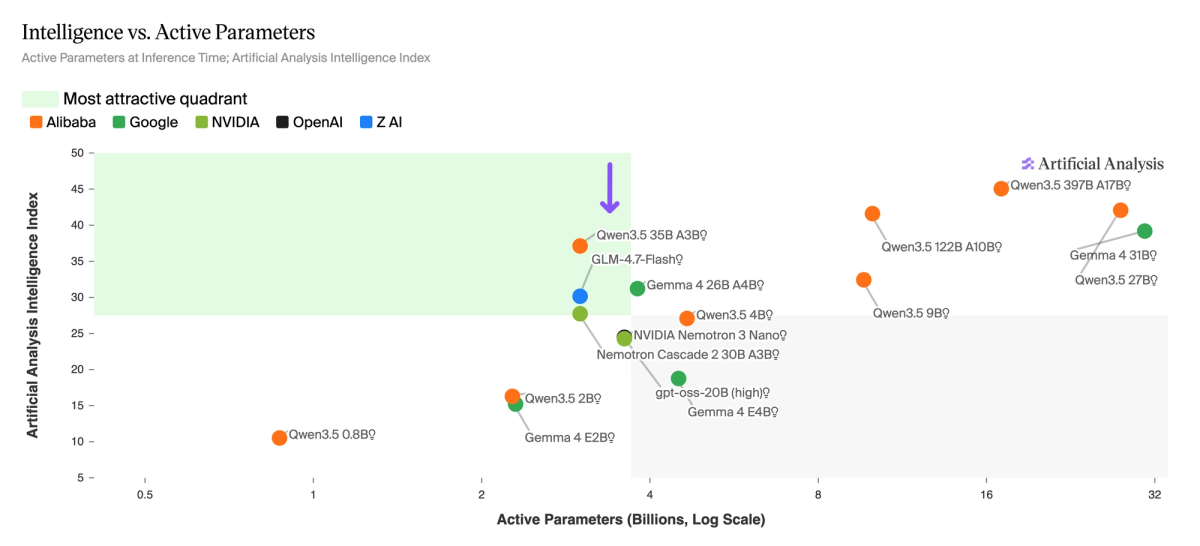
约 3-4B 活跃参数层级的竞争日益激烈——目前有来自五个不同实验室的六个模型在此竞争。 一年前,这个层级还不存在。Qwen3.5 35B A3B(推理型)在 Intelligence Index 上以 37 分领先,其次是 Gemma 4 26B A4B(推理型)31 分、GLM-4.7-Flash(推理型)30 分、Nemotron Cascade 2 30B A3B 28 分,以及 gpt-oss-20B(high)和 NVIDIA Nemotron 3 Nano 30B A3B(推理型)均约为 24 分。多个实验室迅速汇聚到约 3-4B 活跃参数点,反映了向针对边缘推理成本优化的 MoE 架构以及更小、更智能的密集模型的广泛转变。
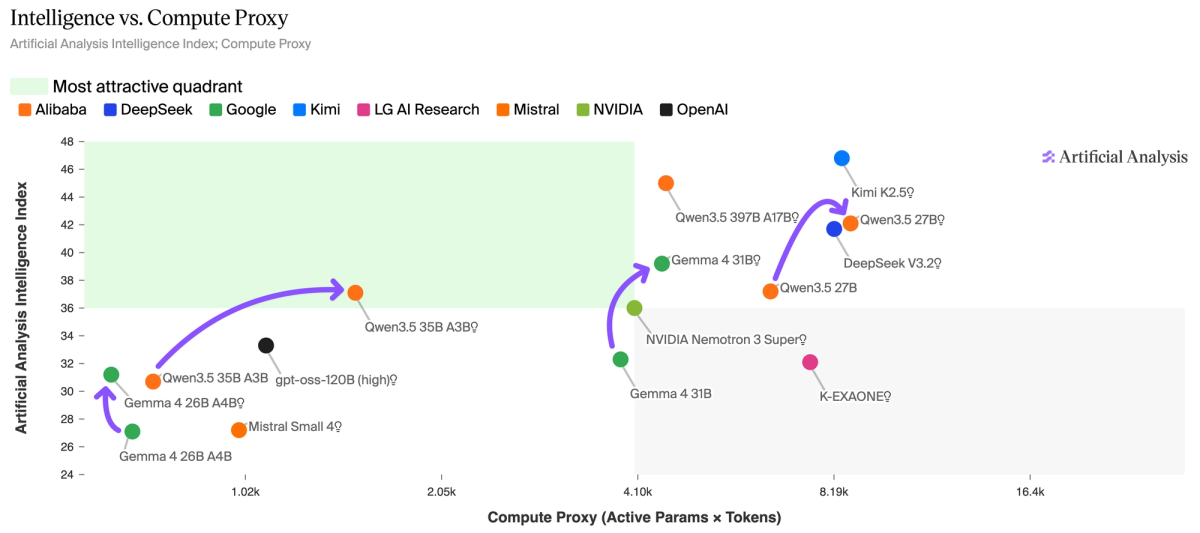
非推理模式在 sub-32B 开放权重领域具有竞争力。 Gemma 4 31B(非推理型)在 Intelligence Index 上得分为 32,仅消耗 710 万输出 token——比其推理模式少 5.5 倍,分数仅下降 7 分。Qwen3.5 27B(非推理型)得分为 37,消耗 2500 万 token——比其推理模式少 4 倍,分数下降 5 分。对于延迟敏感或高吞吐量的部署,这些非推理模式现在的表现已与不到一年前的前沿推理模型相当,而计算量却少得多。
阅读最新文章
 ### OpenBMB 发布 MiniCPM-V 4.6 1.3B Instruct OpenBMB 发布新模型 2026年5月11日
### OpenBMB 发布 MiniCPM-V 4.6 1.3B Instruct OpenBMB 发布新模型 2026年5月11日 ### 近期开放权重模型发布 回顾 Moonshot AI、小米和 DeepSeek 近期的开放权重模型发布 2026年4月30日
### 近期开放权重模型发布 回顾 Moonshot AI、小米和 DeepSeek 近期的开放权重模型发布 2026年4月30日 ### xAI 发布 Grok 4.3,提升 agent 性能并降低定价 Grok 4.3 的基准测试与分析 2026年4月30日
### xAI 发布 Grok 4.3,提升 agent 性能并降低定价 Grok 4.3 的基准测试与分析 2026年4月30日
订阅我们的通讯
邮箱地址 订阅
Artificial Analysis
探索
公司
© 2026 Artificial Analysis