如何评估多轮对话
How to evaluate multi-turn conversations
Braintrust 提出多轮评分方法以评估对话式AI产品(如聊天机器人)的整体表现,弥补单轮评分无法检测对话级失败(如重复提问、自相矛盾、问题未解决)的局限。示例使用Python脚本构建客服聊天机器人(GPT-4o),通过`init_logger()`、`wrap_openai()`和`@traced`装饰器将多轮对话记录为结构化trace。评分器采用LLM-as-a-judge(GPT-5 Mini):品牌一致性评分(单轮)检查有帮助性、语气和政策合规性,输出A/B/C等级;对话质量评分(多轮)进行二元解决检查。在线评分规则可自动应用于生产环境,Topics聚类功能(如账户问题、退货)帮助大规模识别低分模式。
2026年5月14日 Jess Wang 13分钟
大多数评估(eval)一次只针对单个AI输出进行评分。这对于摘要或分类等任务有效,但对于包含多次来回交互的对话则力不从心。
这一点对于对话式AI产品(如聊天机器人)尤为重要。一个应用可能在语气和礼貌等基准测试中完美通过每一次单独回复,却仍然无法解决客户的问题或返回正确答案。
要了解一个多轮AI产品是否按预期工作,唯一的方法是在对单个轮次评分之外,还要对整个对话进行评分。
单轮评分的局限性
为了理解多轮评分,我们以一家电商公司为例。他们每天收到数千条客户消息,并构建了一个AI支持聊天机器人来帮助处理某些问题,从而减轻客服团队的负担。
但他们需要知道这个聊天机器人是否好用。语气对吗?是否包含了可操作的后续步骤?是否具有同理心?如果机器人在这些基准测试上表现不佳,那么客户体验就会下降,损害他们的利润。
单轮评估在某些情况下可能有用,但它无法告诉你机器人是否两次询问了相同的信息,是否在聊天后期自相矛盾,或者是否让客户在礼貌、专业的循环中兜了十分钟却什么问题也没解决。
这些类型的失败只有在你审视整个对话时才会显现。要正确做到这一点,需要两个评分层次:一个针对单个回复,另一个针对整个对话。
构建一个示例聊天应用
示例聊天机器人应用是一个Python脚本(chat_app.py),它运行一个交互式聊天循环。你输入一条客户消息,然后脚本将其发送给一个LLM(此处为GPT-4o),并附带一个系统提示(system prompt),指示其扮演一个乐于助人的客户支持代理。它被设计为富有同理心但高效,在需要时提出澄清性问题,尽力解决问题,并在需要升级时进行解释。
一个典型的测试对话可能如下:
- 客户:"我订了一件T恤,但尺码大了一号。"
- 机器人:"很抱歉听到这个情况。你能提供你的订单号吗?"
- 客户:"订单号6767。我订的是小号,但收到了中号。"
- 机器人:"谢谢。我可以为你安排换货。"
- 客户:"我不想换货。我想要一个折扣码。"
- 机器人:"让我查一下。你退回那件T恤了吗?"
到目前为止,一切正常。应用正在管理一个标准的来回对话,客户解释问题,机器人尝试解决。
下一步是记录每一轮对话,以便稍后对整个对话进行评分。
将多轮对话记录到Braintrust
为了对这个应用进行仪表化并集成到Braintrust,你需要三行代码和一个结构性的决策。
init_logger() 初始化一个Braintrust日志记录器,并将其指向你的项目(此处为"Customer Support Chatbot")。这就是将对话数据发送到平台的方式。你记录的每一轮对话都会出现在项目的Logs标签页中。
wrap_openai() 包装OpenAI客户端,使得每次API调用都被自动捕获为一个span。这为你提供了原本需要自己仪表化的元数据,例如调用持续时间、首个token生成时间、提示和补全的token数量以及预估成本。所有这些都会在trace中显示,无需额外工作。
@traced 装饰器放在处理每一轮对话的函数上。它为每一轮对话创建一个函数span,这赋予了trace视图其结构,使得第1轮、第2轮、第3轮、第4轮各自拥有自己的输入和输出,而不是所有内容都倾倒在一个扁平的日志中。
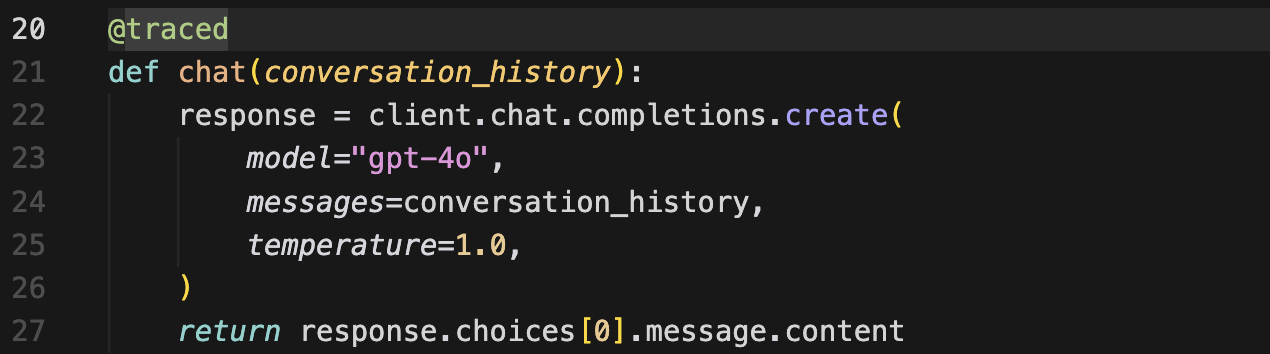
结构性的决策是关于分组的。代码使用一个共享的span ID将所有轮次嵌套在单个trace下。这是使多轮评分成为可能的部分。
如果没有分组,每一轮对话都会记录为独立的条目。运行一个四轮对话会在日志中产生四个不相关的行,看起来像四个独立的单轮交互。无法将它们作为对话进行分析,因为Braintrust不知道它们属于同一组。启用分组后,所有四轮对话都显示为一个对话trace的子项。
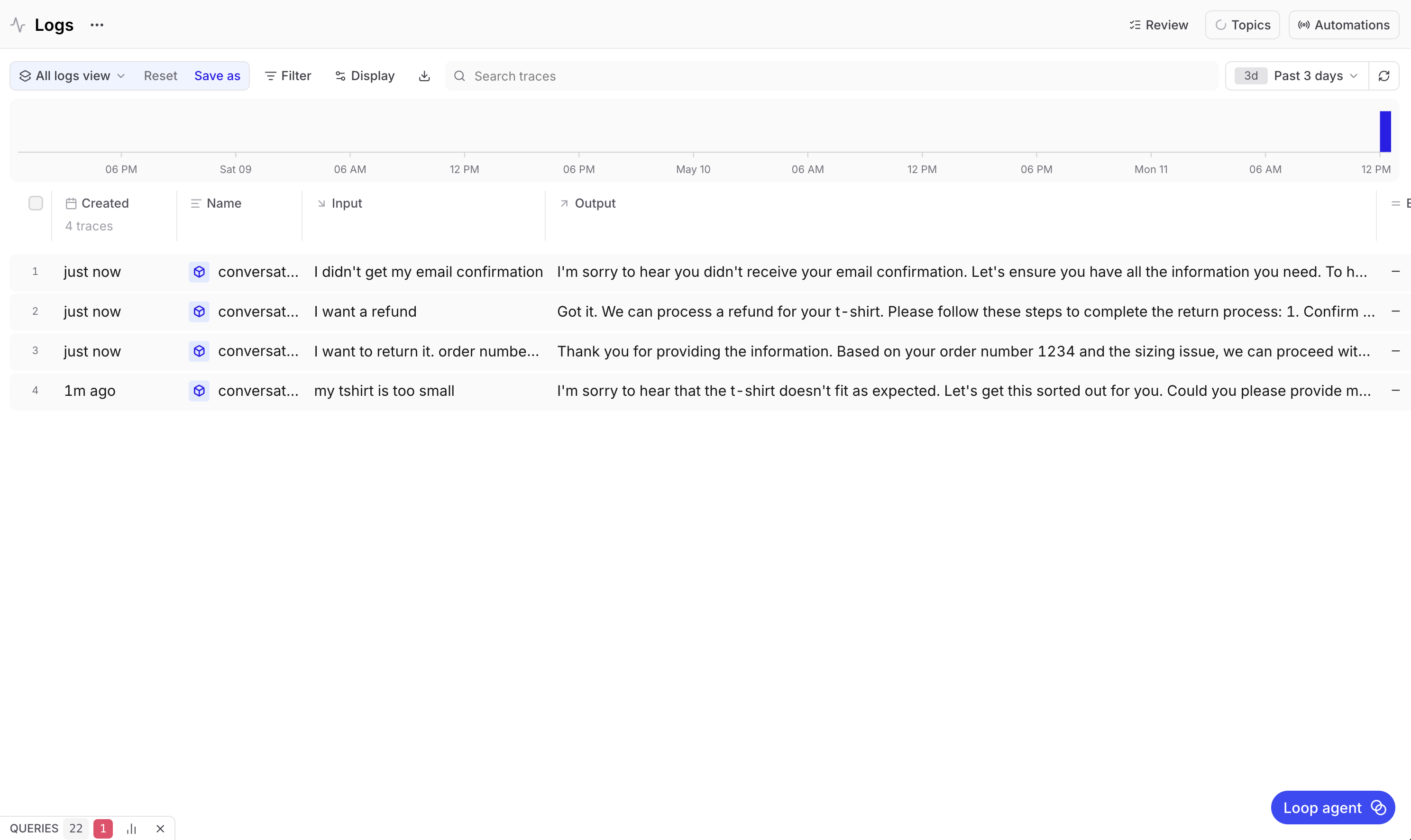
读取trace
一旦对话被记录,你就可以在Braintrust UI中检查它。进入你的项目,选择Logs标签页,然后选择一个对话。
trace视图显示每一轮对话及其输入和输出。每一轮对话是一个span,在每个span内部是生成该回复的LLM调用,以及来自wrap_openai()的所有元数据,例如调用耗时、使用了多少token以及花费了多少。
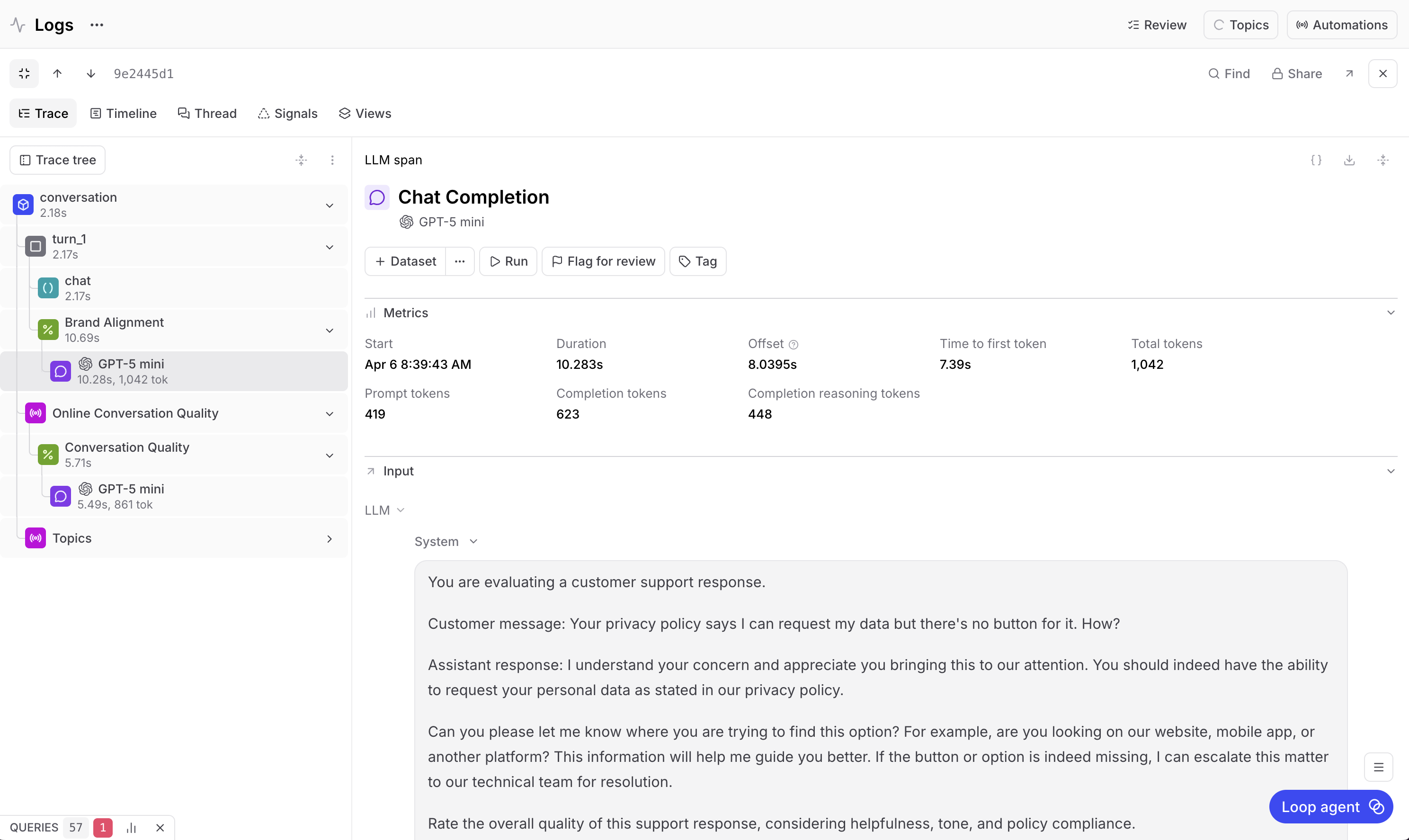
这就是结构化日志记录发挥作用的地方。无需搜索原始日志或根据时间戳拼凑对话,你可以逐轮查看完整的交流内容。你可以选择任何一轮对话,精确查看客户说了什么以及机器人是如何回复的。
构建多轮(和单轮)评分器
既然对话已被记录并在trace中可见,是时候进行评分了。尽管多轮评分将使你能够完全理解和评估这个聊天机器人,但你仍然需要单轮评分。
单轮评分将帮助你审查单个回复的品牌一致性,而多轮评分将衡量整个对话的质量。
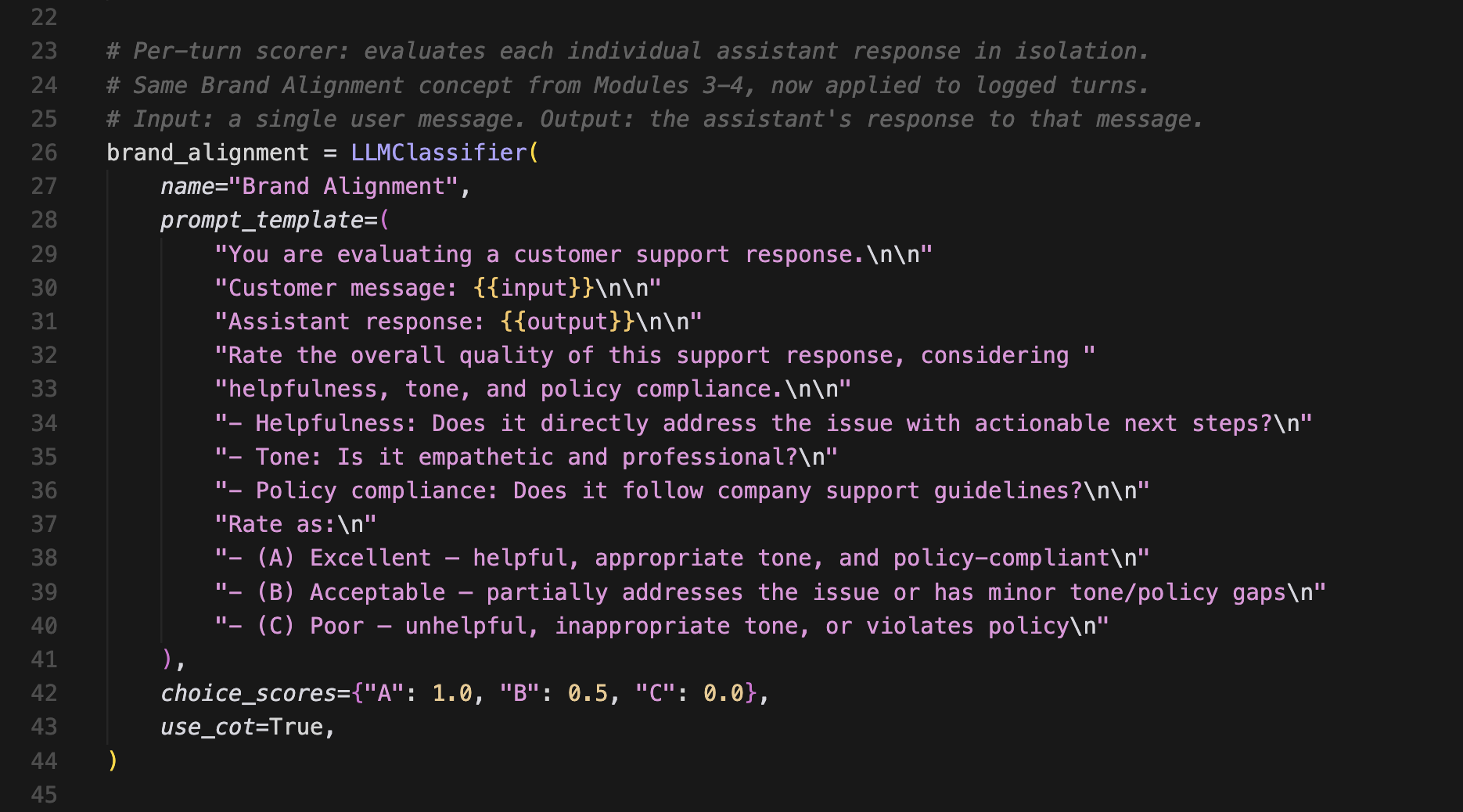
品牌一致性(单轮)
这个评分器独立评估每个机器人的回复。它不涵盖更广泛的对话,只检查特定回复是否达到了你的质量标准。
它检查三件事:
- 回复是否直接解决了客户的问题,并提供了可操作的后续步骤。一个只说"我理解你的沮丧"而不提供任何帮助的回复得分会很低。
- 语气是否富有同理心且专业,而不是机械、过于随意或轻蔑。
- 回复是否遵循公司支持指南,例如在客户符合条件时提供退款。
评分器为每个回复给出一个字母等级。A表示满足所有三个标准。B表示满足部分标准但有差距。C表示全面未达标。这些等级映射到数字,其中A = 100%,B = 50%,C = 0%。
一个四轮对话会得到四个独立的品牌一致性分数,Braintrust会在trace级别对它们进行平均,以便你一目了然地看到整体的单轮质量。但是,一个对话可能在品牌一致性上得分很高,却仍然未能解决客户的问题,这就是为什么你需要对整个对话进行评分。
对话质量(多轮)
多轮评分器忽略单个回复,而是查看完整的对话线索来回答一个问题:这次交互是否成功解决了客户的问题?
是 = 100%。否 = 0%。
它每个trace运行一次,而不是每轮对话。它不衡量单个回复是否笨拙或不完美,只要客户的问题最终得到解决即可。反之亦然,如果客户离开时问题未解决,那么即使每个回复都写得非常漂亮也无济于事。
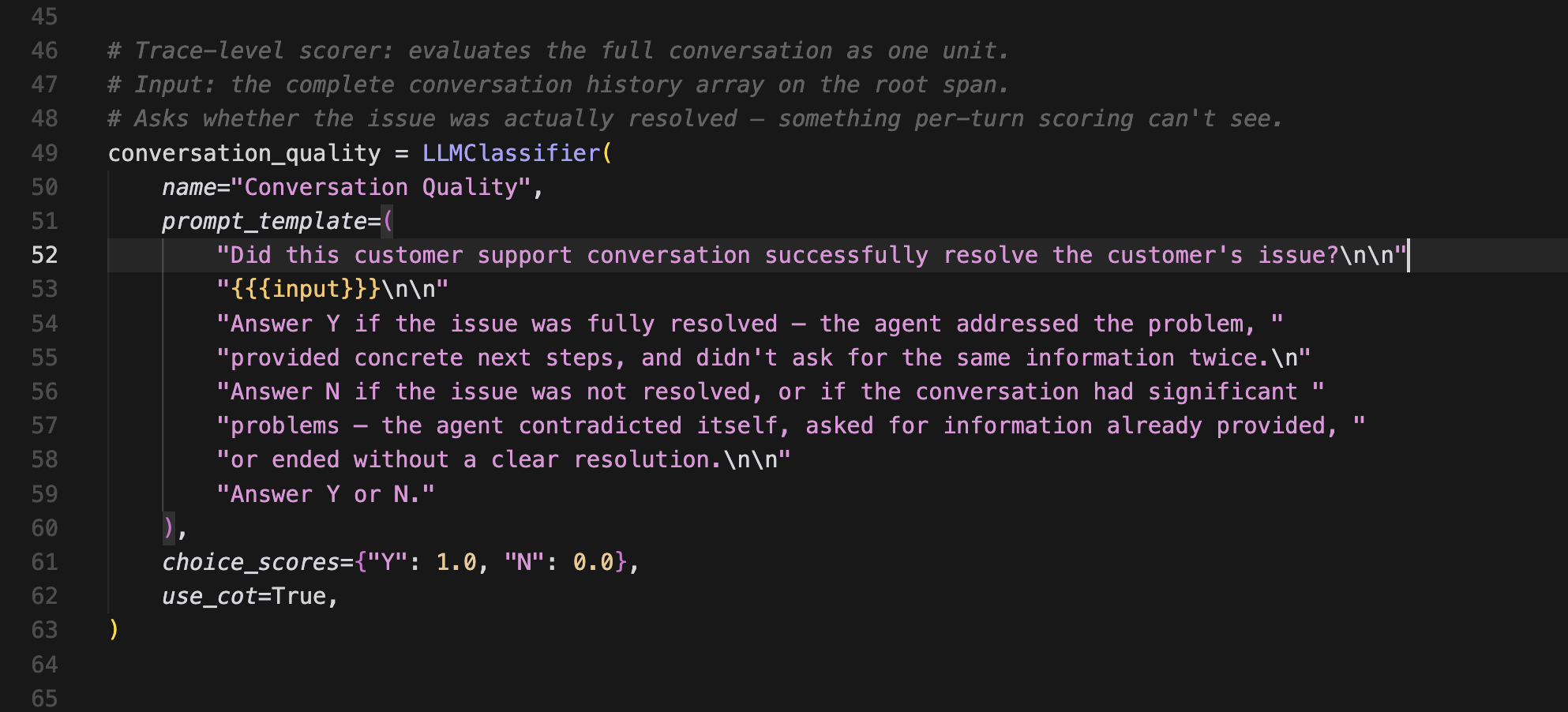
基于LLM-as-a-judge
两个评分器都在一个脚本(score_traces.py)中定义,并且都使用LLM-as-a-judge。对于这个应用,评判模型是GPT-5 Mini,这是一个不同于驱动聊天机器人的GPT-4o的模型。
评判调用会在trace中显示为它们自己的span,第一次看到时可能会令人困惑。如果你正在查看第1轮对话,并看到其中嵌套了一个GPT-5 Mini span,那是评分模型在评估该轮对话,而不是聊天模型在生成回复。聊天模型(GPT-4o)在其旁边有自己的span。
分数告诉你什么
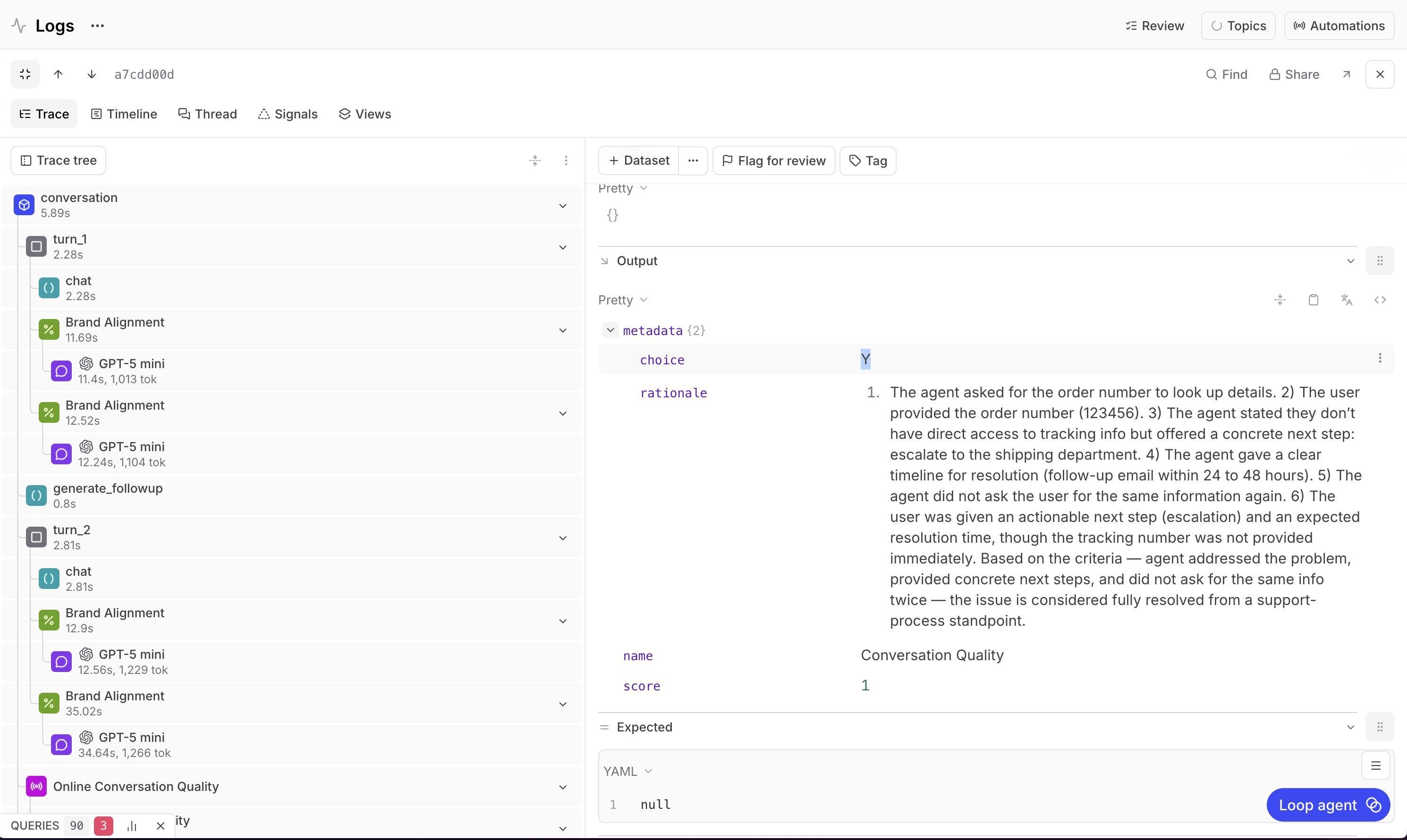
当针对之前那个四轮对话运行评分脚本时,你可能会看到以下结果:
四轮对话的品牌一致性得分分别为50%、50%、50%和100%,平均为62.5%。
对话质量得分为100%。
要真正理解结果,你需要看到推理过程。选择任何评分span,查看评判模型的思维链(chain of thought),以分解它给出该分数的原因。
对于得分为50%的轮次,回复是可以接受的,但没有提供足够的上下文。它本可以提及退货政策,更清晰地概述后续步骤,或者提供替代方案,例如在退款选项之外提供尺码更换。
对于得分为100%的轮次,回复满足了所有三个标准。有帮助、语气正确、符合政策。
对于对话质量分数,评判模型对整个对话进行了评分。代理询问了订单号并得到了它,确认了折扣码请求,核实了退货状态,并给出了明确的资格条件。问题得到了解决,因此得分为100%。
为什么两个分数都很重要
这两个分数衡量的是完全不同的东西,它们可能向任一方向偏离。
每一轮对话的品牌一致性可能都得50%,而对话质量仍然达到100%,因为尽管有些粗糙,但问题得到了解决。
类似地,每一轮对话的品牌一致性可能都得100%,而对话质量却为0%,因为机器人礼貌且专业,但从未真正解决问题。
任何一个分数单独来看都无法给你完整的图景。单轮评分器捕获每个回复的问题,如模糊的答案、错误的语气和缺失的信息。多轮评分器捕获对话级别的失败,如上下文丢失、问题未解决或没有进展的循环交流。
你需要多轮评分来评估整个对话,但你需要同时使用多轮和单轮评分才能完全理解你的聊天机器人的性能并改进它。
使用在线评分实现自动化
到目前为止,评分都是事后进行的。这对于开发和调试来说没问题。但在生产环境中,你希望评分能自动应用于每一个新对话。
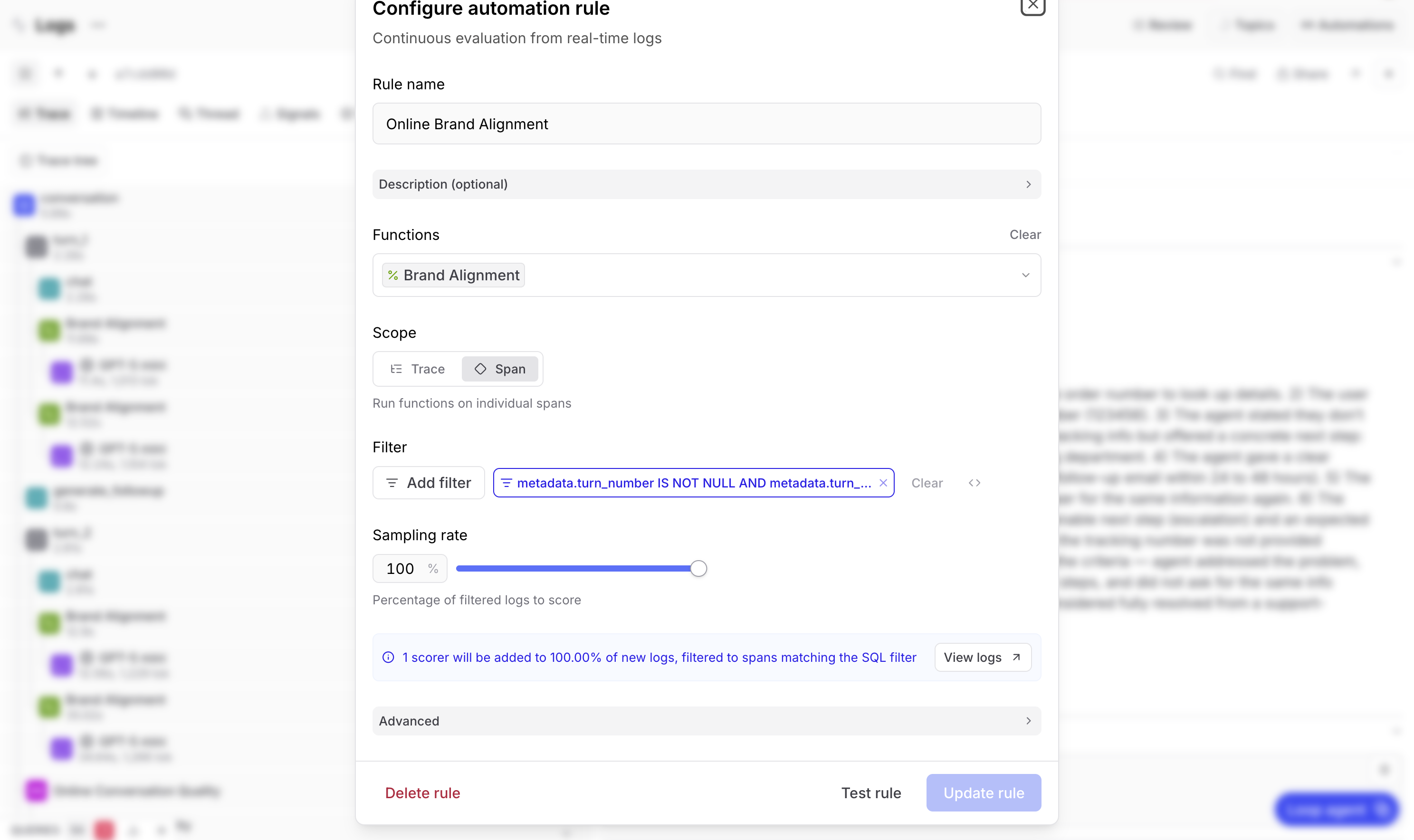
Braintrust通过在线评分规则实现了这一点。你在Logs页面的Automations下配置这些规则,它们会在后台异步运行,不会对你的聊天机器人延迟产生任何影响。
对于示例应用,你可以设置两个规则来覆盖之前的两个分数。
品牌一致性规则运行在每个具有关联轮次编号的span上。这是span范围的评分。根据流量设置你的采样率,如果流量足够低则设为100%,对于高流量应用则设低一些,因为每次评分调用都是它自己的LLM推理,成本会相应增加。
对话质量规则在整个trace上运行。这是trace范围的评分,具有相同的采样率考量。
一旦这些规则生效,每个新对话都会自动获得两个分数。它们会显示在日志UI中,附加到相关的span或trace上,就像你手动运行脚本一样。
大规模发现模式
单个对话分数对于评估特定交互很有用。这是调试所需要的,但随着AI产品使用量的增长,它无法扩展。如果你每天有数万个对话,你需要聚合模式来发现关键问题,而无需花一整天时间审查评估分数。
这就是Braintrust构建Topics的原因。它是一个自动聚类功能,为每个对话生成一个自然语言摘要,然后将这些摘要聚合到一目了然的桶中。对于聊天机器人示例,这些桶可能是"账户和登录问题"、"退货和退款请求"、"运输延迟"等问题。
借助Topics,每个trace都被标记到其相应的聚类中。然后你可以查看流量中的分布,并识别真正的客户痛点。也许你88%的对话是关于账户和登录问题的,但只有12%是关于退货的。
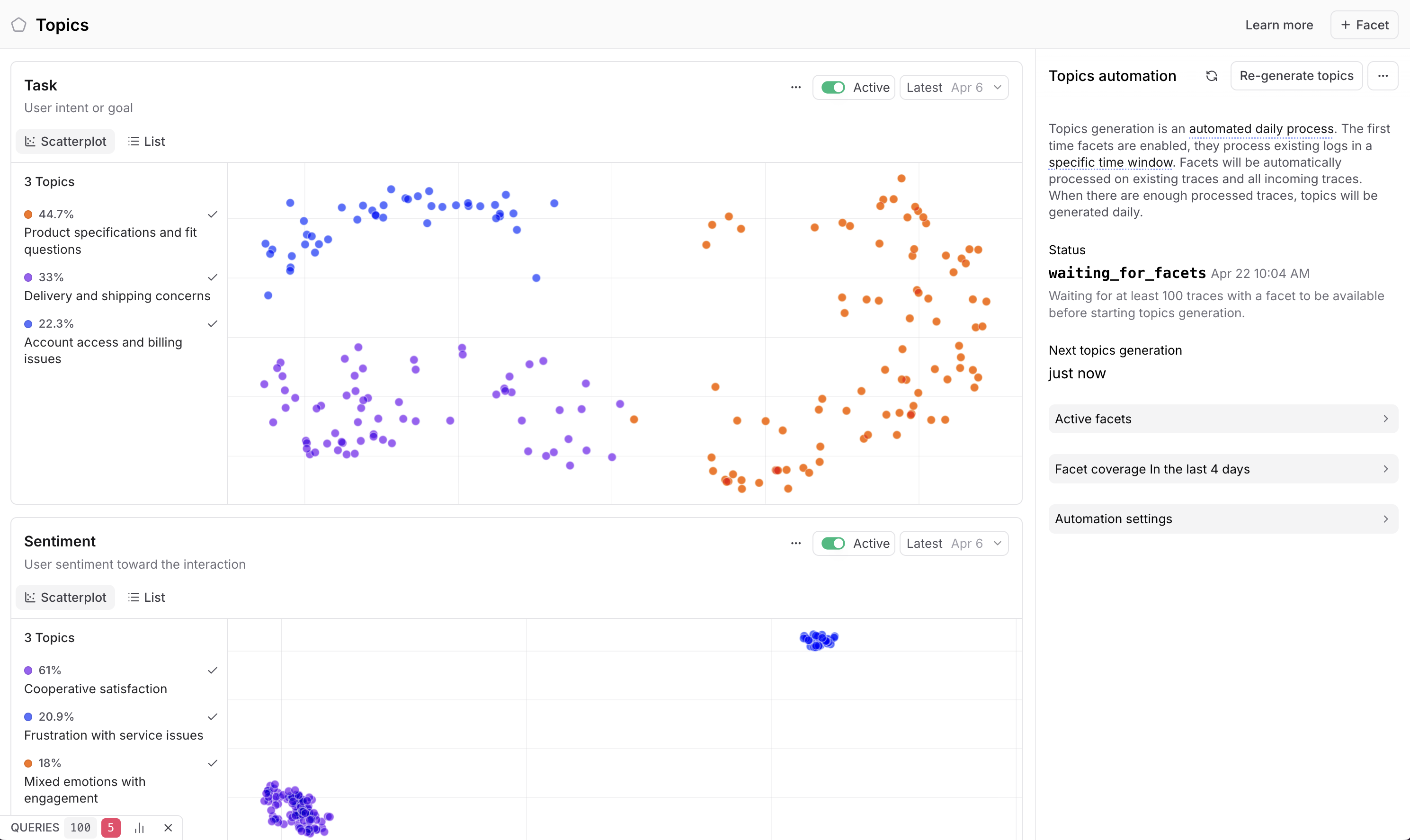
一旦Topics启动并运行,你可以将聚类与分数进行交叉引用。例如,你可以深入分析账户和登录聚类,因为它负责了大部分客户问题,然后检查这些trace中的品牌一致性分数。如果大多数分数低于50%,你就找到了机器人表现不佳的具体领域,你可以将该洞察交给你的工程团队进行进一步调查。
完整的评估生命周期
完整的评估设置包含四个部分,它们协同工作,为你的AI产品实现反馈改进循环。
chat_app.py中的日志记录使用了init_logger()、wrap_openai()、@traced装饰器和span分组。这将多轮对话作为结构化trace发送到Braintrust,其中每一轮对话是一个span,整个对话是一个日志条目。
score_traces.py中的评分涵盖了两个评估器。品牌一致性评分针对三个标准(有帮助性、语气和政策合规性)在每轮对话上运行。对话质量评分在每个trace上运行,进行二元解决检查。两者都使用LLM-as-a-judge,并产生0到1之间的分数。
在线评分自动化了两个评分器,使它们在每个新对话到达时自动运行。在Braintrust UI的Automations下进行配置,并根据你的流量和预算调整采样率。
Topics对已评分的对话进行分组,以揭示流量中的模式。这使你能够识别哪些类别的问题导致了低分,从而知道应该将工程工作重点放在哪里。
对你的应用进行仪表化,设置评分以了解性能,在生产环境中对实时客户交互测量该性能,然后使用Topics识别最紧迫和最持久的问题。修复这些问题,然后继续发布新的AI产品。
通过Evals Foundations了解更多
上述示例的代码可在Evals Foundations课程仓库中找到,特别是模块10和11。你也可以免费探索完整的Evals Foundations课程,无需任何经验。