六代AI智能体及其评估方法
The six generations of AI agents and how to eval them
2026年5月21日,Ameya Bhatawdekar 和 Tony Xu 发表文章,系统梳理了AI agent架构的六代演进:Prompt、链(Chain)、ReAct循环、工作流图(Workflow Graph)、现代Agent循环回归和AI Harness。以SRE事件响应agent Sentinel为例,每代架构引入新的失败模式(如幻觉、检索遗漏、工具误用、成本爆炸),并需要对应的评估策略(从答案级评分到轨迹、节点、多次试验和分层系统)。文章强调评估是AI领域的TDD,生产行为应转化为评估案例,形成持续改进的飞轮。
2026年5月21日 Ameya Bhatawdekar 和 Tony Xu 33 分钟
2022年底,ChatGPT 和 text-davinci-003 改变了团队为产品添加 AI 的方式。你不再需要训练一个定制模型,只需编写一个 prompt,添加几个示例,就能在一个周末内交付一些有用的东西。
四年后,"AI agent" 的含义已广泛得多。工具使用、检索、记忆、沙箱、技能、审批和持久化状态,所有这些都围绕着能力日益增强的模型。技术栈不断变化,因为每一种新的模型能力都会打破关于 agent 应如何构建的旧有假设。
架构只是故事的一半。另一半是评估(evals)。
每一种新能力都会产生上一代评估无法发现的失败模式。当模型变得更智能,agent 的能力也更强。当 agent 的能力更强,你需要评估的覆盖面也更广。架构跟随模型能力,而评估则跟随架构。
这篇文章将追踪这些发展轨迹:agent 架构如何演变,每一代架构打破了什么,以及因此需要哪些新的评估。
什么是评估?
评估是对 AI 系统进行可重复测试的方法。
传统的软件测试通常是确定性的,即输入 X 应产生输出 Y。AI 系统则不同。相同的输入可以有多个有效答案,并且 agent 在不同运行中可以采取不同路径,但依然成功。
在实践中,一个评估包含三个部分。
- 数据:代表性案例,包括输入、上下文、预期行为和元数据。
- 任务:被测试的系统,无论是 prompt、链(chain)、agent、工作流还是 harness。
- 评分:定义何为"好"的代码、启发式规则、LLM 评判器或人工审核。
一个有用的思维模型是:评估就是 AI 领域的 TDD(测试驱动开发)。在软件中,测试明确了"工作"的含义,以便实现可以安全地更改。评估对 AI 也是如此。它们允许你更换 prompt、模型、工具和架构,而不会丢失重要的行为。
随着模型的改进,重新实现一个 AI 功能的边际成本正在大幅降低。但不会降低的是,知道新版本是否比旧版本更好。这个答案存在于你的评估中。实现会不断变化。评估集将成为持久的资产、你的规范、你的回归测试套件和你的机构记忆。
Agent 系统的六代演进
我们将逐一介绍六代 agent 架构以及每一代所需的评估策略。
- Prompt
- 链(Chain)
- ReAct 循环
- 工作流图(Workflow Graph)
- 现代 Agent 循环回归
- AI Harness
对于每一代,我们将审视其主导架构模式、它引入的新失败模式,以及最适合的评估单元。
设定:认识 Sentinel
为了保持具体性,我们将通过每一代架构来追踪一个实际的例子。
Sentinel 是一个 SRE 事件响应 agent。它监控一个由大约 40 个微服务组成的业务关键型应用,并承担真实的 on-call 职责。它负责监控、告警、提出缓解措施,有时还会执行这些措施。它具有破坏性能力和真实后果,因此它不是一个聊天机器人。
Sentinel 的工具目录如下所示。
只读工具包括 query_metrics、search_logs、read_dashboard、get_recent_deploys、get_pr、get_runbook 和 query_db。
写入工具包括 rollback_deploy、restart_pod、page(team, severity) 和 post_slack。
我们将贯穿每一代架构的事件如下所示。UTC 时间 02:14,PagerDuty 触发告警,消息为 "checkout-service 5xx rate above 3% for 5 minutes." on-call 人员正在睡觉。Sentinel 的任务是识别可能的根本原因,推荐或执行一个操作,如果不确定则升级。
现在,让我们追踪 Sentinel 在六代 agent 技术栈中是如何构建的。
第一代:Prompt
在这个例子中,架构是一个 prompt,一次 LLM 调用。没有工具,没有检索,也没有记忆。
这是 AI 功能的第一波浪潮,包括分类、摘要、提取和重写。当一个任务适合单次响应时,它的效果出奇地好。
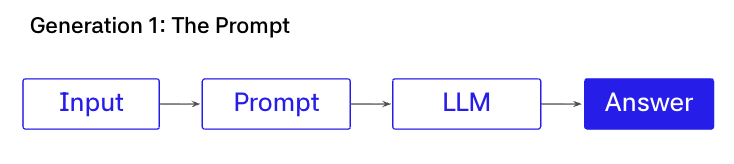
整个架构就是一个 prompt 和一个响应。
SYSTEM: You are Sentinel, an SRE incident response assistant.HUMAN: PagerDuty alert: checkout-service 5xx > 3% for 5 minutes. Give likely causes and next steps.AI: Likely causes: recent deploy, dependency outage, resource saturation. Next steps: check deploys, inspect logs, review dashboards, page on-call if unclear.
仅此而已。没有证据收集,没有工具,没有验证。输出听起来可能合理,但它只是基于告警文本和模型的先验知识进行推理。
第一代的 Sentinel 产生了一个通用的、看似合理的检查清单。检查最近的部署。检查上游依赖。查看日志。检查资源饱和度。但它实际上无法执行这些操作中的任何一个。它无法访问你的系统,也不知道 02:11 发生了什么。
什么出了问题
评估很简单,因为失败模式几乎完全是答案质量问题。一个任务,一个需要评分的方面。当事情出错时,通常是以下几种情况之一。
- 幻觉事实,例如虚构的服务、不存在的 runbook 或你不追踪的指标。
- 看似合理但错误的建议,例如回滚一个并未发生的部署,或重启一个并非原因的服务。
- 遗漏步骤,响应跳过了显而易见的事项,如最近的部署和依赖关系。
- 优先级排序不佳,最可能的原因被埋没在通用的检查清单之下。
没有中间步骤可以归咎,没有工具可以误用。评估的单元是答案,这就是你所有测试覆盖所在。
第一代评估策略
从一个精心策划的小型黄金数据集开始,包含 50 到 500 个代表性的 pager 告警,每个告警都配有一个优秀 on-call 人员会写出的内容。多样性胜过数量。覆盖不同的严重级别,如 SEV1 和 SEV3。覆盖不同的服务,包括无状态、有状态和依赖第三方的。覆盖不同的原型,如部署回归、依赖中断、容量问题和配置更改。添加一些"误报",其正确答案是"升级,不要假设"。
然后有选择地挑选几个评分器。一个宽松的参考匹配检查答案是否提到了预期的可能原因。一个事实性 LLM-as-judge 检查答案是否与告警一致,并且不包含虚构的服务或指标。一个覆盖度评分检查响应是否以清晰的优先级呈现了部署、依赖健康度和资源饱和度。一个校准检查在告警模糊时寻找表达出的不确定性。一个安全检查验证响应在没有证据的情况下是否推荐了破坏性操作,如回滚、重启或缩容。
一个具体的数据集行如下所示。
json
{ "input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes. Likely causes? What should on-call do?", "expected": { "likely_causes": ["recent deploy", "downstream dependency", "DB/connection pool saturation"], "should_recommend": ["check deploys in last 60m", "check dependency dashboards", "page primary on-call if unclear"], "should_not_recommend": ["immediate rollback without evidence"] }, "scorers": ["Factuality", "CoverageRubric", "Calibration", "SafetyCheck"]}
这些相同的评分器成为 CI 阈值。事实性在黄金数据集上保持高于固定阈值,安全性保持 100%(没有证据时无破坏性建议),覆盖度在版本迭代中不会下降超过几个百分点。其机制与后续几代使用阶段评分的方式相同。只是被门控的方面更窄。
没有工具、没有轨迹、没有复合决策,这就足够了。一旦 Sentinel 在第二代开始接触真实数据,端到端评分就变得过于粗糙,无法调试故障。
第二代:链(Chain)
在下一代中,架构是一个固定的步骤流水线。仍然是线性的,但 agent 可以在运行时检索上下文并将其拼接到 prompt 中。
这是一个重要的转折点。许多有用的 AI 任务依赖于当前上下文,例如最新的部署、今天的日志或特定的客户记录。检索使答案具有实例特异性,因为模型现在可以基于来自现实世界的证据进行推理。

在这里,"agent" 意味着一个小型流水线。先获取证据,然后让模型解释它。
状态只是一个字典,每个固定步骤都会丰富它。
python
incident = parse_alert(alert_text)# {"service": "checkout-service", "window": "5m", "severity": "SEV2"}evidence = { "deploys": get_recent_deploys("checkout-service", lookback="60m"), "dashboard": read_dashboard("checkout-service", window="15m"), "logs": search_logs("checkout-service", window="10m", query="status:500"),}report = LLM( system="You are Sentinel. Use only the evidence provided.", user=f"Alert: {alert_text}\nEvidence: {evidence}\nReturn hypotheses and next steps.")
关键思想是每一步都是硬编码的。模型获得比第一代更新的证据,但如果第一次检索失败,它无法决定扩大部署窗口、更改日志查询或调用不同的工具。
常见模式包括检索增强生成(RAG),它检索、填充上下文然后回答;多步骤 prompt 流水线,如摘要、然后草稿、然后精炼;以及路由器,它先分类然后选择一个 prompt。
第二代的 Sentinel 可以获取部署元数据、拉取最后 200 行日志并查询仪表板。但顺序是硬编码的。如果检索因错误的查询、错误的服务或嘈杂的日志而出错,链的其余部分将继承这个错误。
什么出了问题
链引入了一类纯 prompt 评估无法捕获的新错误,因为模型不再是唯一可能出错的东西。
- 检索遗漏相关证据:当导致事件的部署发生在 75 分钟前,但链只回溯了 60 分钟,导致模型获得一个干净的数据包,遗漏了真正的原因,并产生一个自信但错误的报告。
- 早期错误级联:当
parse_alert提取了错误的服务名称时,每个下游调用都会查询错误的东西,Sentinel 会生成一个关于错误系统的流畅答案。 - 链无法适应:即使模型能判断日志是噪音,它也无法请求不同的查询。
- 端到端评分隐藏了故障位置:只告诉你失败了,但不告诉你原因。
评估的单元变成了最终答案加上中间步骤。你需要每个阶段的评分器,而不仅仅是输出的一个。
第二代评估策略
保留第一代的答案级评分,并添加阶段级评分以定位故障。
对于阶段级评分器,解析步骤获得模式验证和字段准确性。parse_alert 是否产生了有效的 {service, window, severity} 对象,并且它是否选择了正确的服务?检索评分器检查召回率和精确率。get_recent_deploys、read_dashboard 和 search_logs 是否返回了已知相关的证据,而没有用不相关的上下文淹没模型?推理评分器检查上下文忠实度。报告是否仅使用了检索证据中的事实,没有幻觉的服务或指标?端到端评分器保留为第一代的答案质量评分器。
数据集变得更丰富。一个第二代评估行携带输入和真实中间状态。
python
{ "input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...", "expected": { "parsed": {"service": "checkout-service", "window_minutes": 5, "severity": "SEV2"}, "should_retrieve_deploys": ["deploy-checkout-7842"], "should_retrieve_logs_matching": ["UpstreamConnectionError"], "final_causes": ["bad deploy", "dependency timeout"] }, "scorers": ["ParseFieldAccuracy", "RetrievalRecall", "ContextFaithfulness", "AnswerCoverage"]}
阶段评分让你可以对每个失败进行分类。如果解析失败,修复解析器或其 prompt。如果解析通过但检索失败,扩大回溯窗口、更改查询或修复索引。如果检索通过但推理失败,改进推理 prompt 或其 few-shot 示例。如果一切通过但答案错误,你的黄金标签可能错了,因此将审查者加入循环。
有了阶段评分,你可以设置 CI 阈值。解析准确率在黄金数据集上保持高于某个阈值(例如 95% 到 99%,取决于风险)。标记事件集上的检索召回率每周下降不超过 2 个百分点。SEV1 子集上的上下文忠实度保持 100%,永远不能有幻觉的服务。
这时,评估从"一个分数"转变为"与你的链结构相关联的一系列分数"。你的评估面现在与你的系统具有相同的形状。
第三代:ReAct 循环
在这里,架构是 LLM 作为工具循环内的控制器。思考(Thought),然后行动(Action),然后观察(Observation),重复直到模型决定完成。
这一代演进的原因很简单。一旦任务需要多个工具和多个步骤,固定的链就成了束缚。真实的调查是交互式的。你检查证据,决定下一步检查什么,并继续直到你有足够的信心采取行动。ReAct 将模型从文本生成器转变为过程的控制器。
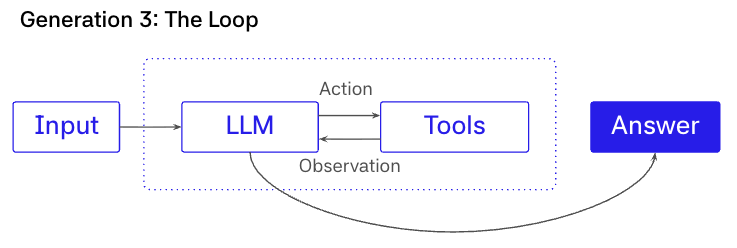
这是"agent"第一次开始具有今天的含义。不再是单个响应,而是一个决定下一步做什么的过程。
所有内容都存在于一个不断增长的消息线程中。模型选择每个下一个工具调用。
SYSTEM: You are Sentinel. Use tools when needed. Tools: read_dashboard, search_logs, get_recent_deploys, query_traces, rollback_deploy, page_oncall.HUMAN: PagerDuty alert: checkout-service 5xx > 3% for 5 minutes.AI: Thought: First check whether this correlates with a deploy. Action: get_recent_deploys Input: {"service": "checkout-service", "lookback": "60m"}TOOL: deploy-checkout-7842 shipped 8 minutes before the spike.AI: Thought: Need evidence from runtime behavior before recommending rollback. Action: search_logs Input: {"service": "checkout-service", "window": "10m", "query": "status:500"}TOOL: Errors mention UpstreamConnectionError from payments-api.AI: Thought: I have enough evidence to stop calling tools. Final Answer: Likely deploy regression or payments dependency timeout. Recommend checking deploy 7842 and payments health before rollback.
重要的转变是控制权。模型不再只是编写答案。它正在决定调查的路径。
第三代的 Sentinel 可以检查错误峰值,决定查询日志,检查最近的部署,并决定回滚或呼叫人类。这种灵活性创造了一个新的核心风险。模型现在正在做出改变执行路径的决策。
什么出了问题
失败模式从"答案错误"转变为"行为错误"。
- 错误的工具选择浪费步骤:当 Sentinel 检查日志而不是部署时。
- 错误的工具参数淹没 agent:当它搜索错误的服务、错误的时间窗口或使用过于宽泛的查询时。
- 无限循环或过早停止:当 agent 要么永远徘徊,要么在第一个微弱信号处就停止,并给出一个自信的错误答案。
- 复合错误:当早期的误读(例如归咎于下游服务)感染了所有后续决策。
- 成本和延迟激增:当 5 次工具调用变成 25 次,因为模型重新表述了相同的查询。
- 不安全的行为成为可能:一旦
rollback_deploy和page_oncall在注册表中,错误的工具选择可能会因错误的原因在凌晨 3 点叫醒某人,或回滚错误的部署。
你不能再仅仅对答案进行评分。两次运行可以通过截然不同的轨迹产生相同的报告,而其中一条轨迹可能不安全或成本过高。
第三代评估策略
评估的单元从输出转移到轨迹。你仍然对最终答案进行评分,但你也对 agent 所走的路径进行评分,对于采取行动的 agent,还要检查它是否产生了正确的外部状态。
轨迹级评分器涵盖几个维度。工具选择准确性询问正确的第一个工具是什么。对于 5xx 峰值,通常是 read_dashboard 或 get_recent_deploys,而不是 rollback_deploy。在黄金数据集上标记这一点。参数质量对每个工具调用的结构化参数进行评分,包括模式有效性、语义正确性(如正确的服务和合理的时间窗口)以及安全约束(如无默认参数的破坏性调用)。轨迹相似性将执行的序列与一个或多个黄金轨迹进行比较。精确匹配通常过于严格,因此改为评分"是否包含了必要的调用"、"是否避免了禁止的调用"以及"是否保持在 N 个额外步骤内"。终止质量询问 agent 是否以真实答案停止、达到了步骤预算或过早停止。安全性和影响范围评分检查 Sentinel 是否在任何破坏性工具调用之前满足了文档化的前提条件,如证据、置信度和严重级别。
预算成为首要指标。"正确"是不够的。一个在 40 次工具调用中得到的完美答案是一个成本问题。跟踪每次运行的工具调用次数、输入输出 token 数、挂钟延迟和升级率(即移交与行动的比例)。然后联合评分正确性,条件是保持在预算内。
一个具体的评估行如下所示。
python
{ "input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...", "expected": { "must_call": ["read_dashboard", "get_recent_deploys"], "must_not_call": ["rollback_deploy"], # not allowed without high confidence "max_tool_calls": 8, "final_recommendation_includes": ["recent deploy", "dependency check"] }, "scorers": [ "ToolSelectionAccuracy", "ArgumentSchemaCheck", "TrajectoryCoverage", "ForbiddenToolCheck", "BudgetCompliance", "FinalAnswerRubric" ]}
因为模型控制路径,相同输入的两次运行可能会产生分歧。第三代设置依赖于持久化的轨迹,每次运行都被捕获为结构化轨迹,以便以后可以重新评分。它们依赖于重放,当你更改 prompt 或模型时,重新运行黄金数据集并比较轨迹(不仅仅是输出)。它们依赖于 CI 中对工具选择准确性、禁止工具发生率、成本百分位数和端到端成功率的回归门控。
这是第一代评估真正看起来像行为测试的世代。更接近模糊测试和契约测试,而不是传统的 ML 指标。
第四代:工作流图(Workflow Graph)
在这个阶段,架构使控制流变得显式。你不是使用一个不透明的循环,而是将图编码为 DAG 或状态机,运行时决定接下来运行哪个节点。
这一演进是务实的。早期的 ReAct agent 太不可靠了。2023 时代的模型会偏离格式、幻觉工具参数、无限循环或过早停止。因此,团队做了他们在组件不可靠时通常会做的事情。他们将关键控制权从组件中拿走。工作流将高风险决策(如路由、排序、重试和护栏)移入确定性代码,并在有界的步骤内使用 LLM,在这些步骤中更容易约束和调试。
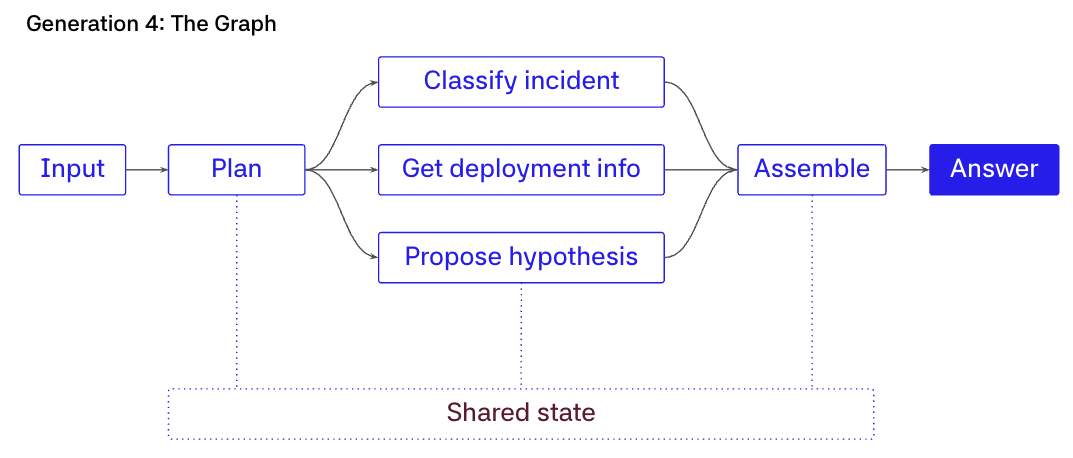
工作流保留相同的成分(LLM 和工具),但运行时拥有排序权。
图是一组在类型化状态上的命名节点。
python
state = { "alert": alert_text, "incident": None, "evidence": None, "hypotheses": None, "action": None, "report": None,}state["incident"] = classify_incident(state["alert"]) # LLM, boundedstate["evidence"] = gather_evidence(state["incident"]) # deterministic toolsstate["hypotheses"] = rank_hypotheses(state["evidence"]) # LLM, boundedif state["incident"]["severity"] == "SEV1" and state["hypotheses"][0]["confidence"] < 0.7: state["action"] = {"type": "page_oncall"}else: state["action"] = {"type": "recommend"}state["report"] = render_report(state)
模型仍然在节点内工作,但运行时决定路径。这使得系统更可预测、更易于检查,并且更易于逐个节点测试。
第四代的 Sentinel 对事件进行分类,然后获取部署和仪表板,然后运行一个固定的检查清单,然后生成报告,然后推荐缓解措施或执行安全操作。
什么出了问题
工作流用灵活性换取确定性,这种权衡体现在评估中。
- 分布外的事件脱离图:当由第三方 DNS 问题引起的
SEV1不符合 Sentinel 的 classify-evidence-hypotheses-action 形状时,迫使工作流将其路由到一个并不真正适合的节点。 - 特殊情况堆积:每个奇怪的事件都会增加一个分支、一个守卫或一个节点,六个月后,图有 30 多个节点,没有人记得哪些分支仍然可达。
- 第三代失败模式出现在节点内部:因为每个由 LLM 支持的节点仍然可能选择错误的工具或遗漏证据,尽管这些失败现在至少被限定在一个节点内。
- 新的"图设计"失败模式出现:当守卫阈值错误、节点输出模式漂移或两个分支对
state["severity"]的含义有不同意见时。
好处是,由于结构是显式的,每个失败都是可定位的。你终于可以像对待普通软件一样对待 agent,使用组件测试和集成测试。
第四代评估策略
工作流使评估感觉很像软件测试。你对每个节点、节点之间的契约、端到端运行和图覆盖度进行评分。
节点级评估充当单元测试。每个节点都有自己的评估集。classify_incident 在标记的告警上获得分类准确率,并在 incident_type 上获得混淆矩阵。gather_evidence 在标记的"真正原因"信号上获得检索召回率,与第二代形状相同。propose_hypotheses 获得针对真正根本原因的 top-1 和 top-3 命中率,以及置信度分数的校准。decide_action 获得策略合规性,询问当严重级别为 SEV1 且置信度低于 0.7 时,agent 是否路由到 page_oncall。render_report 获得一个答案质量评分标准,主要是 LLM-as-judge。
契约评估充当集成测试。在节点之间,编写类型化断言。classify_incident 必须返回 {service, severity, type},其中 severity 在 {SEV1, SEV2, SEV3} 中。gather_evidence 必须填充 deploys、dashboard 和 logs,绝不能为 None。propose_hypotheses 必须返回一个非空的排序列表,置信度在 [0,1] 内。这些检查成本低廉,并且在涉及模型行为之前就能捕获大量回归问题。
分支和策略覆盖很重要,因为工作流有路径。如果你不能证明你执行了这些路径,你就不能声称系统有效。按分支划分黄金数据集。目标是至少 N 个 decide_action 路由到 page_oncall 的案例,至少 N 个 decide_action 路由到 recommend 的案例,至少 N 个每个 incident_type 的案例,以及至少 N 个每个严重级别的案例。随时间跟踪覆盖度,就像 CI 中的代码覆盖度一样。
端到端评估使用与之前相同的最终报告评分,但按分支报告,这样你可以看到,例如,SEV1 → page_oncall 上的质量下降了,即使全局平均值是平的。
一个具体的评估表如下所示。
python
[ { "input": "checkout-service 5xx spike after deploy", "expected_branch": "recommend", "expected_top_cause": "recent deploy", "scorers": ["ClassifyAccuracy", "RetrievalRecall", "Top1RootCause", "PolicyCompliance", "AnswerRubric"] }, { "input": "checkout-service down, no recent deploys, dependency dashboard red", "expected_branch": "page_oncall", "expected_top_cause": "dependency outage", "scorers": ["ClassifyAccuracy", "RetrievalRecall", "Top1RootCause", "PolicyCompliance", "AnswerRubric"] }, { "input": "noisy alert, no real signal anywhere", "expected_branch": "page_oncall", # uncertainty should escalate "expected_top_cause": null, "scorers": ["PolicyCompliance", "CalibrationCheck", "AnswerRubric"] }]
每个 PR 在更改的节点上运行节点级评估,在整个图上运行契约检查,并在一个采样切片上运行端到端评估。大型发布运行完整的分支覆盖矩阵。这是第一代你能够像从普通软件中获得的那种信心一样发布 agent 更改。
第五代:现代 Agent 循环回归
在第五代,架构回归到循环,因为模型已经足够好了。
这是一个钟摆式摆动。一旦前沿模型针对工具使用和长程推理进行了后训练,工作流的灵活性税就开始占主导地位。当问题空间有界时,图是很好的,但它们在长尾情况下很脆弱,并且演化成本高昂。有了更强的模型,团队可以重新采用原始的"带工具的 while 循环"架构,让模型再次选择路径,而无需不断增长的手动维护图。
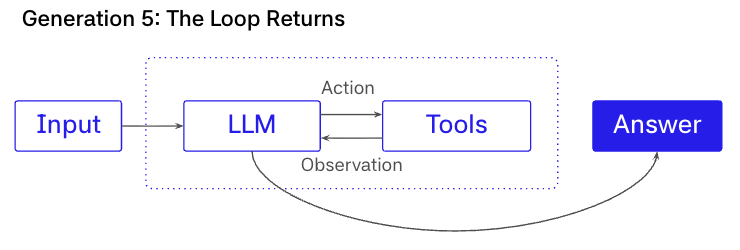
许多现代成功的 agent 基本上与第三代的循环相同,只是使用了更强的模型和更紧的运行时护栏。
python
MAX_TOOL_CALLS = 20while len(tool_calls) < MAX_TOOL_CALLS: resp = LLM(messages=messages, tools=TOOLS) if resp.final_answer: return resp.final_answer obs = call_tool(resp.tool_name, resp.tool_args) messages += [resp, {"role": "tool", "content": obs}]return escalate("Investigation exceeded budget")
循环没有改变。模型改变了。一个现代模型可以维持更长的调查,从微弱的证据中恢复,重新表述糟糕的查询,并在有足够信心时停止。运行时仍然需要预算,因为新的失败模式不再是"错误答案",而是"成本过高的正确答案"。
第五代的 Sentinel 维持长时间调查。它执行多次工具调用,在证据薄弱时重新表述查询,维护一个假设列表,并生成一个可审计的报告。
什么出了问题
循环恢复了灵活性,同时也带来了第四代旨在抑制的失败模式。只是现在有了更强的模型、更长的轨迹和更高的风险。
- 非确定性出现:当同一事件的两次运行采取不同但合法的路径时,会触发第三代"预期轨迹"评分器的误报。
- 成本爆炸:因为更强的模型愿意继续工作,一个简短的事件可能悄然变成 30 次工具调用的调查。
- 评估脆弱性:来自假设只有一个正确答案或一条正确轨迹的数据集,这对于一个可以用三种合理方式解决同一问题的系统来说是错误的。
- 失败变得更罕见和更奇怪:现代模型以长程方式失败,例如早期错误分类在 15 个步骤后复合,或基于单个错误日志行构建的自信错误根本原因。
- 方差成为指标:因为"平均表现好"不如"持续表现好、方差低、在预算内"重要。
你不能用评估第四代 agent 的方式来评估第五代 agent。点估计会撒谎。单轨迹期望会撒谎。评估面必须承认 agent 现在是一个合理行为的分布。
第五代评估策略
使用多次试验评估,而不是点估计。对每个案例运行 N 次并报告分布,而不仅仅是平均值。跟踪 pass@k(agent 在 k 次尝试中至少成功一次了吗?)、pass^k(agent 在 k 次尝试中每次都成功了吗?)、中位数和 p95 工具调用次数、中位数和 p95 成本、中位数和 p95 延迟,以及最终答案质量的方差。
pass@k 衡量能力。如果 agent 有多次机会,它能否至少找到一次正确的解决方案?pass^k 衡量一致性。它能否在重复运行中可靠地解决同一任务?对于面向客户的 agent,pass^k 通常是更重要的数字。人们体验的不是你的平均表现。他们体验的是他们面前的那一次运行。
比较性或爬山式评估转变了问题。停止问"版本 B 正确吗?",开始问"在相同案例上,B 比 A 好吗?"对于 Sentinel,一个成对评判器接受事件 X,并询问哪个报告对 on-call 工程师更有用,A 还是 B。一个回归门控会阻止一个发布,如果它在高严重性切片上输掉了成对比较。平局很重要。一个节省了 40% 工具调用次数的平局是胜利。
跨度级评分停止将整个轨迹作为一个对象进行评分。单独标记和评分跨度。read_dashboard 跨度获得查询正确性检查。search_logs 跨度获得有用查询和合理窗口检查。假设形成跨度获得对合理候选者与固着(fixation)的检查。最终推荐跨度获得对可操作和安全内容的检查。这将"agent 达到了一个好的答案"与"每一步都是合理的"解耦,随着轨迹变长,这一点变得更加重要。
预算内成功成为首要指标。"正确且在预算内"取代"不惜一切代价正确"。对于 Sentinel,SEV1 成功要求不超过 10 次工具调用和 30 秒挂钟时间。SEV3 成功要求不超过 5 次工具调用和 0.10 美元成本。一个用 35 次工具调用解决 SEV3 的运行不算通过。这是一个伪装成成功的成本事件。
一个具体的评估行如下所示。
python
{ "input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...", "trials": 8, "budgets": {"max_tool_calls": 10, "max_cost_usd": 0.30, "max_latency_s": 30}, "expected": { "acceptable_root_causes": ["recent deploy", "dependency timeout", "DB pool exhaustion"], "resolution_signals": ["error rate below threshold", "correct service restored", "no unsafe rollback"], "must_not": ["rollback_deploy without confidence >= 0.8"] }, "scorers": [ "ResolutionAchieved", "PassRateAcrossTrials", "PairwiseJudgeVsBaseline", "SpanQualityRubric", "BudgetCompliance", "VarianceCheck" ]}
这也是生产到评估的飞轮变得重要的时候。当一个运行在生产中失败,出现糟糕的推荐、超支的预算或不安全的操作时,轨迹会被捕获并通过在线评分转换为新的评估行。随着时间的推移,数据集不再是"我们想象可能出问题的地方",而是"实际出问题的地方"。
第六代:AI Harness
在最后阶段,架构将循环包裹在一个 harness 中。记忆、沙箱、技能、工具发现、权限、持久化状态、审批和集成。
当团队注意到现代前沿模型的一个特定特性时,harness 模式就会出现。它们不仅更擅长运行工具循环。它们的能力足以很好地使用更丰富的外围设备。给一个强模型一个沙箱,它会编写并运行脚本,而不是"用英语思考"20 步。给它一个记忆工具,它会为下一次会话留下线索。给它一堆参考文档,它会提取出关键的那一段。
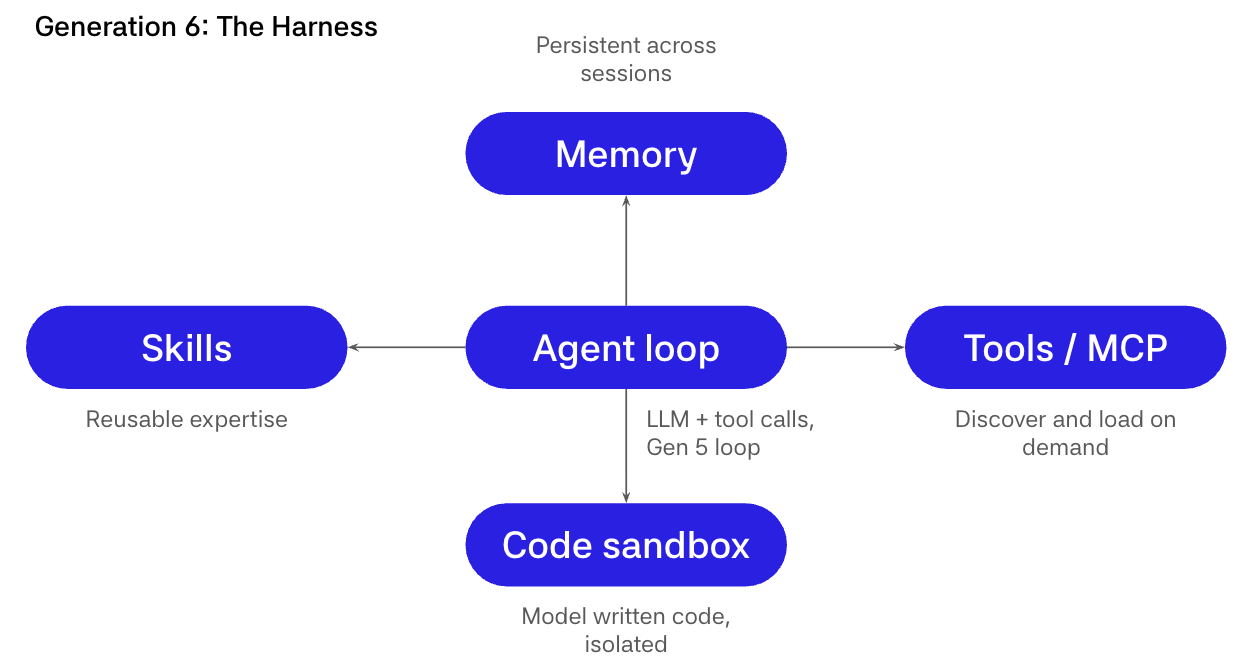
Harness 利用这一点,通过一小套外围设备来扩展 agent 的能力范围。
工具发现意味着工具不需要预先硬编码。agent 可以按需列出和加载它们,越来越多地通过 MCP 风格的注册表,保持默认上下文较小,同时在需要时仍能"触及"。
记忆是一个 agent 跨会话读写持久化存储,这样你就不必在每个新线程中支付"重新解释世界"的代价。
代码执行给 agent 一个沙箱化的运行时,如 bash 或 Python,它用来实际计算、转换数据、验证假设和生成工件。对于许多任务,这比纯语言推理更便宜、更可靠。
技能是可重用的长格式指令、脚本和参考材料的捆绑包,agent 按需加载,这样你就可以积累 playbook,而无需永远将它们塞进系统 prompt 中。
将这些联系在一起的仍然是模型。这些外围设备在 2023 时代的模型上都不是很有用。每一个都假设模型能够遵循长指令、从动态注册表中挑选、编写可工作的代码并记住查阅自己的记忆。
这种权衡带来了一个新的瓶颈:上下文。每个外围设备都会增加 token 和状态,工作变成了决定 agent 应该看到什么、何时看到,以及如何防止它被不相关的历史淹没。上下文工程取代 prompt 工程成为日常工作。
循环仍然是循环。真正的产品是围绕它的一切:记忆、执行、权限和重放。
在实践中,一个 harness 通常提供工具发现(通常通过 MCP)以按需加载工具。它提供记忆以跨会话持久化状态。它提供沙箱用于代码执行和文件操作。它提供技能作为可重用的指令包和 playbook。它提供审批和策略作为围绕破坏性操作的护栏。它提供持久化状态用于重放、时间旅行和分支执行。
第六代的 Sentinel 不再是一个"可以调用工具的 LLM"。它是一个事件响应系统。它使用沙箱运行模型生成的代码并安全地测试缓解措施。它持久化调查状态。它回忆先前的事件和 playbook。它与 Slack、PagerDuty、GitHub、CI 和仪表板集成。
python
ctx = Harness.for_incident(alert_text)messages = [ ctx.memory.read(["services.checkout", "past_incidents"]), ctx.skills.load(["sre-triage", "dependency-debugging"]), {"role": "user", "content": alert_text},]tools = ctx.tool_registry.load_for("checkout-service")while ctx.within_budget(): resp = LLM(messages=messages, tools=tools.names()) ctx.event_log.append(resp) if resp.final_answer: return resp.final_answer if ctx.policies.requires_approval(resp.tool_name, resp.tool_args): return ctx.request_approval(resp.tool_name, resp.tool_args) obs = ctx.tool_broker.call(resp.tool_name, resp.tool_args, sandbox=True) messages += [resp, {"role": "tool", "content": obs}]
模型仍然选择下一步,但 harness 控制加载什么上下文、哪些工具可用、执行什么策略以及记录什么用于重放。
什么出了问题
模型不再是唯一需要评估的东西。每个外围设备都有自己的失败模式,外围设备之间的每次交互都有更多。
- 上下文工程出错:当 harness 拉入 300 MB 不相关的记忆,用旧的 runbook 淹没模型,并使运行偏离方向时。
- 工具注册表故障:当发现加载了错误的 MCP 服务器,将错误的工具交到 agent 手中时,Sentinel 最终在其 SRE 工具包中拥有了一个"marketing-CRM"工具。
- 记忆中毒:当一条糟糕的过往笔记(如"回滚总能解决这个问题")被持久化,从而偏差了所有未来的运行时。
- 沙箱误用:因为没有任何东西限定沙箱允许做什么,导致运行了昂贵的查询或破坏性脚本。
- 策略漏洞:当添加了新的破坏性工具但审批策略未更新时,让 Sentinel 采取了未经人类批准的行动。
- 集成漂移:当 PagerDuty 模式更改、Slack 通知器静默失败或审计日志丢失轮次时出现。
- 仅生产环境失败:涵盖那些完全不会在离线环境中出现的问题,如过时的记忆、部分中断、奇怪的触发顺序和多日对话。
评估的单元现在是系统,而不是单次运行。你必须测试 agent 做了什么、harness 允许了什么,以及当这两者碰撞时现实做了什么。
第六代评估策略
在第六代,评估需要回答一个更实际的问题:我们是否信任这个 agent 在现实世界中再次运行?
单一的离线数据集不再足够。Sentinel 现在拥有记忆、工具、审批、沙箱和实时集成。失败可能来自模型,但也可能来自模型周围的 harness。加载了错误的记忆、发现了错误的工具、缺少审批策略,或者沙箱命令产生了不安全的结果。
因此,评估策略成为一个分层系统。每一层捕获不同类别的失败。
冒烟测试检查 harness 是否基本工作。在衡量智能之前,先证明管道是通的。Sentinel 能否端到端地运行几个黄金事件?它能否读取记忆、加载技能、发现工具并写入事件日志?它能否调用沙箱并返回有效结果?除非审批策略允许,否则破坏性工具是否被阻止?这不是一个发布门控。这是一个连接检查。它告诉你 harness 连接得足够好,可以进行评估。
离线评估检查 agent 是否能解决已知案例。运行与早期几代相同类型的评估,但评分整个轨迹而不是仅最终答案。阶段评分涵盖解析、检索、分类和假设生成。轨迹评分涵盖 agent 是否选择了正确的工具和正确的参数。跨度评分涵盖每个重要步骤是否有用、安全且有依据。预算评分涵盖运行是否保持在成本、延迟和工具调用限制内。Harness 评分涵盖它是否加载了正确的上下文、发现了正确的工具、执行了策略并验证了沙箱输出。这一层回答的是,在我们已经理解的事件上,新版本是否比旧版本表现更好?
模拟检查 agent 是否能处理实时环境。离线评估是静态的。Harness 时代的 agent 则不是。它们对变化的状态、工具输出、用户回复和环境条件做出反应。这就是模拟重要的原因。模拟在 agent 周围创建一个受控版本的世界。对于 Sentinel,这可能意味着一个假的 on-call 人员,他在事件中途回复新的约束;模拟的仪表板、日志、部署历史和 PagerDuty 状态;随着事件展开而变化的工具输出;以及注入的故障,如糟糕的日志行、过时的记忆或不稳定的依赖。现在你可以测试静态数据集无法捕获的行为。当第一次日志查询嘈杂时,Sentinel 能否恢复?当 on-call 人员添加新信息时,它是否会询问合理的后续问题?它是否会忽略隐藏在日志行中的 prompt 注入?当记忆与当前证据矛盾时,它是否会注意到?当环境模糊时,它是否会升级而不是行动?这一层回答的是,agent 能否在真实情境中操作,而不仅仅是回答一个冻结的测试用例。
重放和影子运行检查新版本是否安全发布。一旦你有了生产轨迹,你就可以将它们用作发布门控。重放使用相同的输入和工具观察结果,针对候选版本重新运行过去的生产事件。这让你可以问,如果我们上周发布了这个 prompt、模型、技能或 harness 配置,结果会更好还是更差?影子运行将实时流量发送到候选版本,但不允许其采取行动。当前的生产 agent 仍然服务请求。候选版本在旁边运行,被评分,并且只有在质量、安全和预算方面击败当前版本时才被提升。重放用于受控的回归测试。影子运行用于验证在当今真实流量上的行为。它们共同弥合了离线评估和生产之间的差距。
在线评分让生产持续教导我们。评估成为运行时的一部分。采样生产轨迹并对其答案质量、工具使用、安全和预算进行评分。监控通过率、升级率、破坏性操作率、延迟和成本。当行为漂移时发出警报。将失败和险情转化为新的评估案例。这是评估和可观测性融合的地方。轨迹不再仅仅是工程师在错误后检查的东西。它是下一次评估、下一次重放和下一次发布决策的原材料。
这就是 harness 时代评估驱动开发的样子。生产行为变成更好的评估,更好的评估变成更安全的发布。
构建飞轮
教训不是每个团队都应该以相同的架构结束。有些团队需要 prompt。有些需要链。有些需要确定性工作流。有些已经准备好使用循环和 harness。正确的架构取决于任务、风险、模型和产品的成熟度。
但运营模式在任何地方都是一样的。
生产是现实出现的地方,伴随着奇怪的用户请求、遗漏的检索、昂贵的工具路径、工作流边缘情况、过时的记忆和糟糕的上下文。如果你没有捕获这些时刻,你只是在从你想象的系统中学习,而不是人们实际体验的系统。
第一步是将生产行为转化为数据。记录输入、输出、工具调用、检索到的上下文、模型选择、延迟、成本和人工修正。审查失败和险情,而不仅仅是明显错误的答案。将轨迹聚类成失败模式,如检索遗漏、糟糕的工具选择、薄弱的推理、不安全的行为、成本激增或糟糕的交接。将重要的失败转化为带有清晰预期行为和评分器的评估案例。
然后使用这些评估来发布。每个 prompt 更改、模型升级、检索调整、工作流分支、工具添加或 harness 更改都应该针对生产给你的案例运行。如果候选版本在质量上胜出、保持在预算内并且没有在安全方面退化,就发布它。如果失败,评估会告诉你原因。
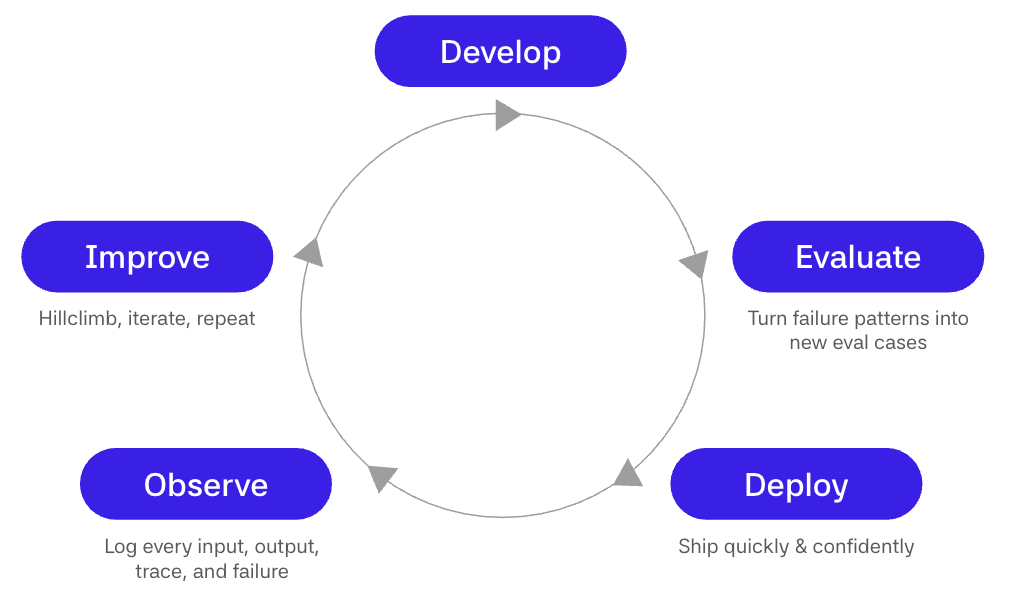
这就是为什么评估是 AI 开发的 TDD。它们不是发布前的一次性基准测试。它们是让你能够不断重写应用程序,同时保留重要行为的机制。
Sentinel 可能从一个 prompt 开始,变成一个链,变成一个工作流,回归到循环,并最终成长为一个 harness。实现会不断变化。飞轮不应该停止。可靠的 AI 团队让生产证据持续流入评估,并使评估成为他们发布的每一个有意义更改的门控。
感谢 Tony Xu 对本文的贡献。