如何通过评估与可观测性赢得利益相关者信任
How to earn stakeholder trust with evals and observability
Braintrust 于2026年4月28日发布三种工具,用于整合AI评估与可观测性数据以建立利益相关者信任。仪表盘聚合跨日志和实验的成本、延迟、token数量及评估分数,提供领导层、工程站会和跨职能产品评审三类模板。自定义trace视图将JSON格式的trace转化为领域特定界面,非技术人员可理解单次AI交互。Loop将自然语言转化为SQL查询,支持即席数据探索并生成图表或数据集。
2026年4月28日 Ornella Altunyan 8分钟
证明AI功能正常工作的数据散落在许多不同的地方。评估分数存在于实验中。质量回退出现在trace视图中。成本和延迟则位于工程仪表盘上。赢得利益相关者的信任,意味着要把这些信号整合起来,让设计、领导层和市场团队都能看懂。
Braintrust提供了三种工具,用于在组织内部分享评估和可观测性数据。仪表盘展示功能随时间推移的表现,汇总跨日志和实验的成本、延迟、token数量和评估分数。自定义trace视图展示AI在单次运行中的行为,将复杂的trace转化为团队中任何人都能读懂的领域特定界面。Loop则回答那些没人预先构建图表的问题,将自然语言转化为针对生产数据的SQL查询,并将答案转化为可供进一步研究的数据集。
仪表盘:聚合可见性
仪表盘是一种领导团队能在30秒内读懂的信息载体。Braintrust的Monitor页面聚合了跨日志和实验的指标,支持在其上构建自定义图表,并允许你选择任意数据点直接跳转到对应的具体日志。让每个职能团队都看到相同的数据,可以消除拖慢AI工作进度的信息孤岛。
仪表盘上放什么
Braintrust中有三种图表类型。时间序列图追踪某个指标随时间的变化,适合用来观察事物是变好还是变坏。排行榜按模型、用户群体或主题等维度排序,能揭示哪些因素驱动了用量或故障。大数字图表显示单个数值,适合放在仪表盘顶部,展示领导最先关注的核心指标。
预设图表包括请求数量、延迟、token使用量和评估分数。在此基础上,你可以为每个图表配置度量、筛选条件以及可选的分类维度。度量是SQL聚合函数,如sum、avg或百分位数,也支持完整的表达式,例如100 * sum(errors) / count(id)。Trace和span筛选器可以进一步缩小数据范围,而分类维度则按SQL维度(如metadata.model或metadata.user_segment)将图表拆分为多个序列。你还可以在项目上启用Topics,并绘制主题分布图,向利益相关者展示用户正在用该功能做什么。
三个仪表盘模板
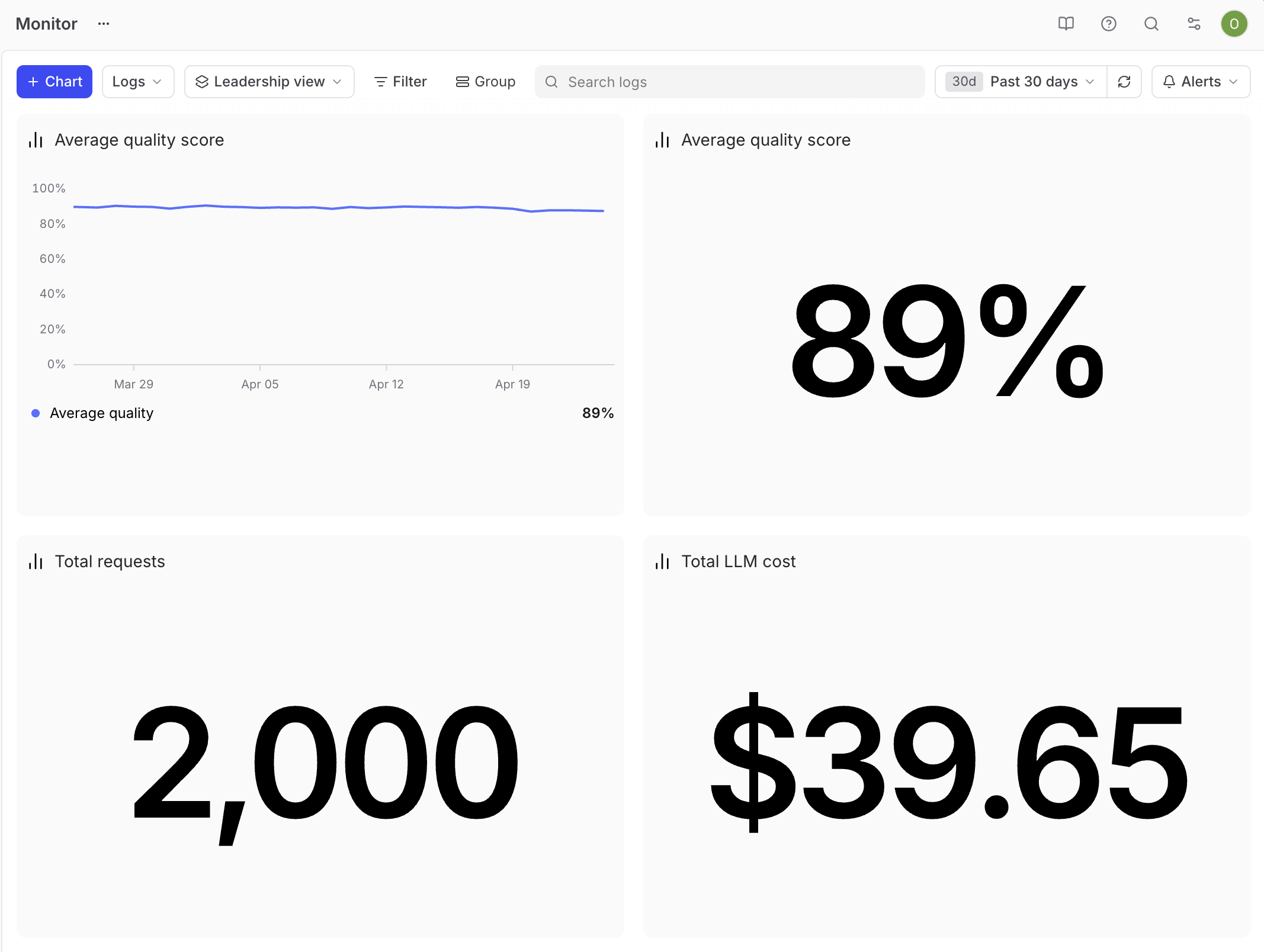
领导层视图
领导层的评审通常很简短,高管们想知道功能是否正常工作,以及是否值得投入。
核心质量指标应放在最显眼的位置。将过去30天的平均质量分数以大数字形式展示,并配上同一分数的时间序列图,这样利益相关者就能同时看到当前值和趋势。在下方,再添加两个大数字,分别显示同一时间窗口内的总请求量和总成本。保持仪表盘简洁,以便每个图表在简短的评审中都能获得关注。核心质量指标来自项目的聚合分数,它将对你产品重要的评估维度整合成一个利益相关者可以追踪的单一数值。
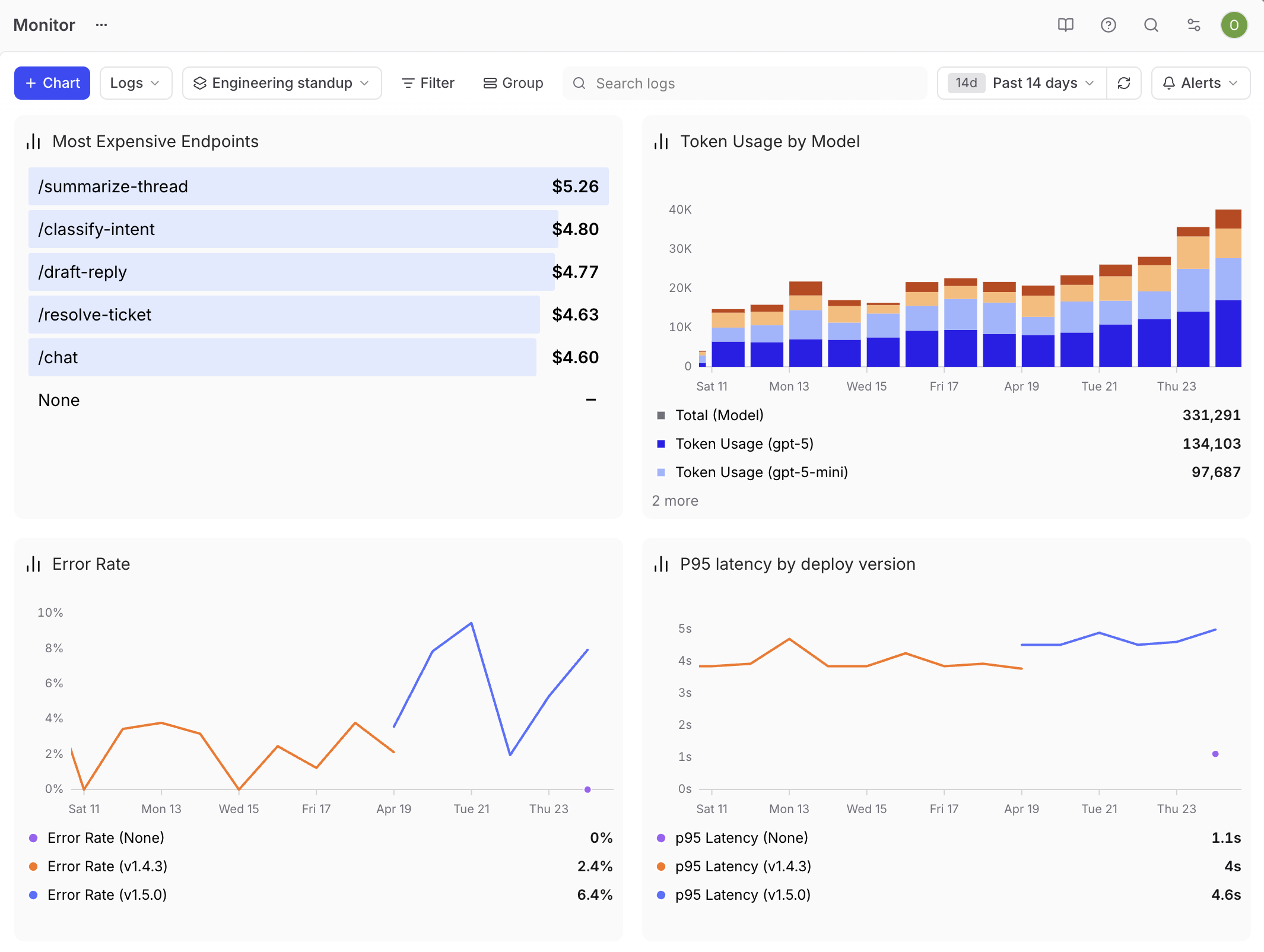
工程站会视图
工程师关心系统健康状况和回退。围绕以下内容构建仪表盘:p95延迟的时间序列图、错误率的时间序列图、按metadata.model分组的token使用量(以显示哪个模型驱动了成本),以及一个最昂贵端点的排行榜。为每个trace打上部署版本的元数据标签,然后按此标签对延迟和错误率图表进行分组,这样你就能看到某个版本发布是否引入了回退。
下钻功能是此仪表盘的价值所在。当延迟出现尖峰时,点击数据点,即可在同一流程中开始调试匹配的trace。
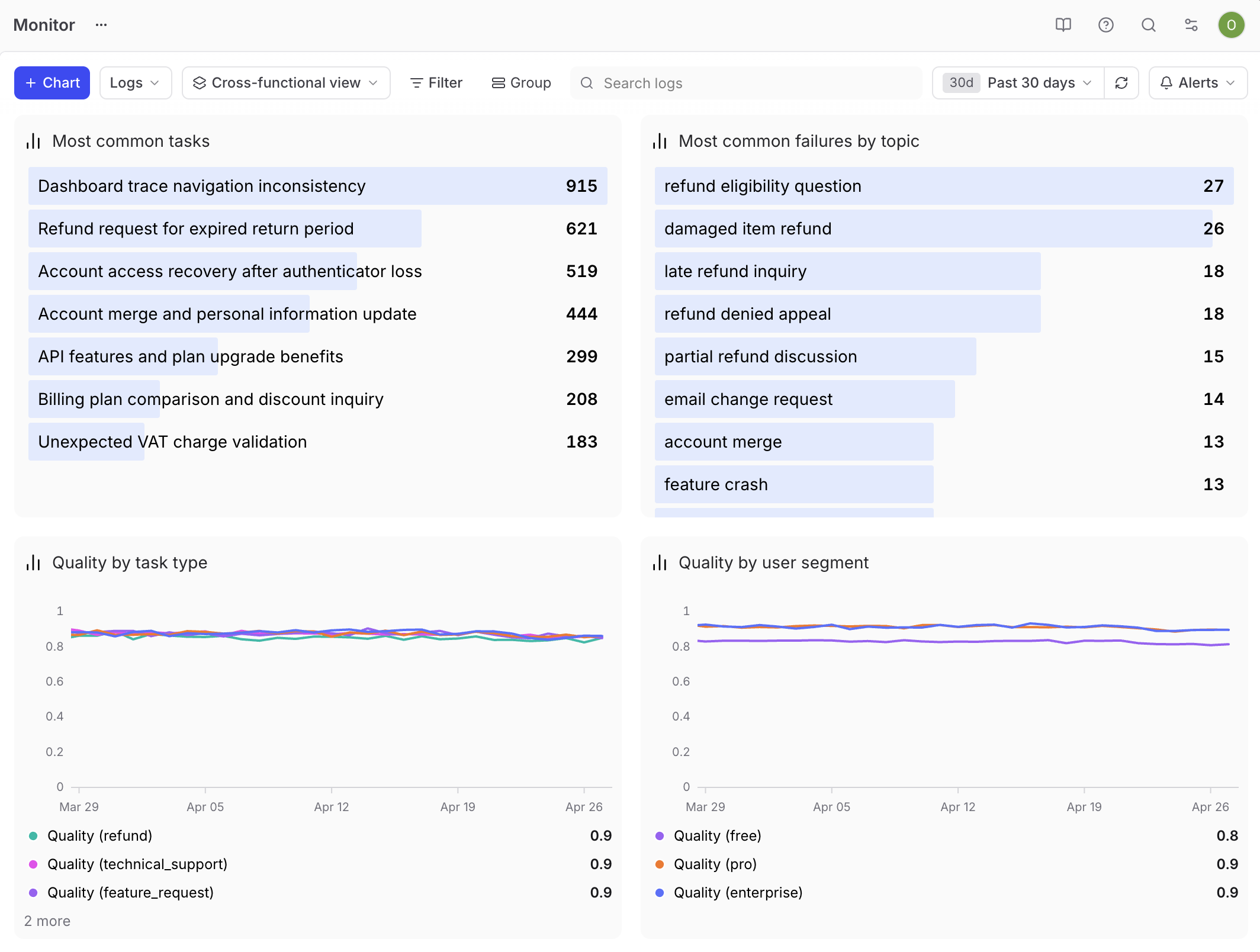
跨职能产品评审
这个仪表盘对PM来说承担了最繁重的工作。受众是混合的,问题是开放式的,目标是揭示下一步该做什么。
围绕细分来构建。为每个trace打上metadata.user_segment和metadata.task_type标签,这样你就可以按谁在使用该功能以及他们要求它做什么来切片数据。添加一个按用户群体分组的评估分数时间序列图,以揭示不同用户角色之间的质量差异。添加一个来自Topics的用户任务排行榜,让利益相关者看到人们要求该功能做什么。添加一个最常见失败主题的排行榜,使失败模式可见。添加一个按任务类型分组的分数时间序列图,以展示该功能在各类工作中的表现。有了这些切片,利益相关者就可以提出自己的问题。例如,当某个主题在失败列表中占主导地位时,工程团队就知道该从哪里入手调查。
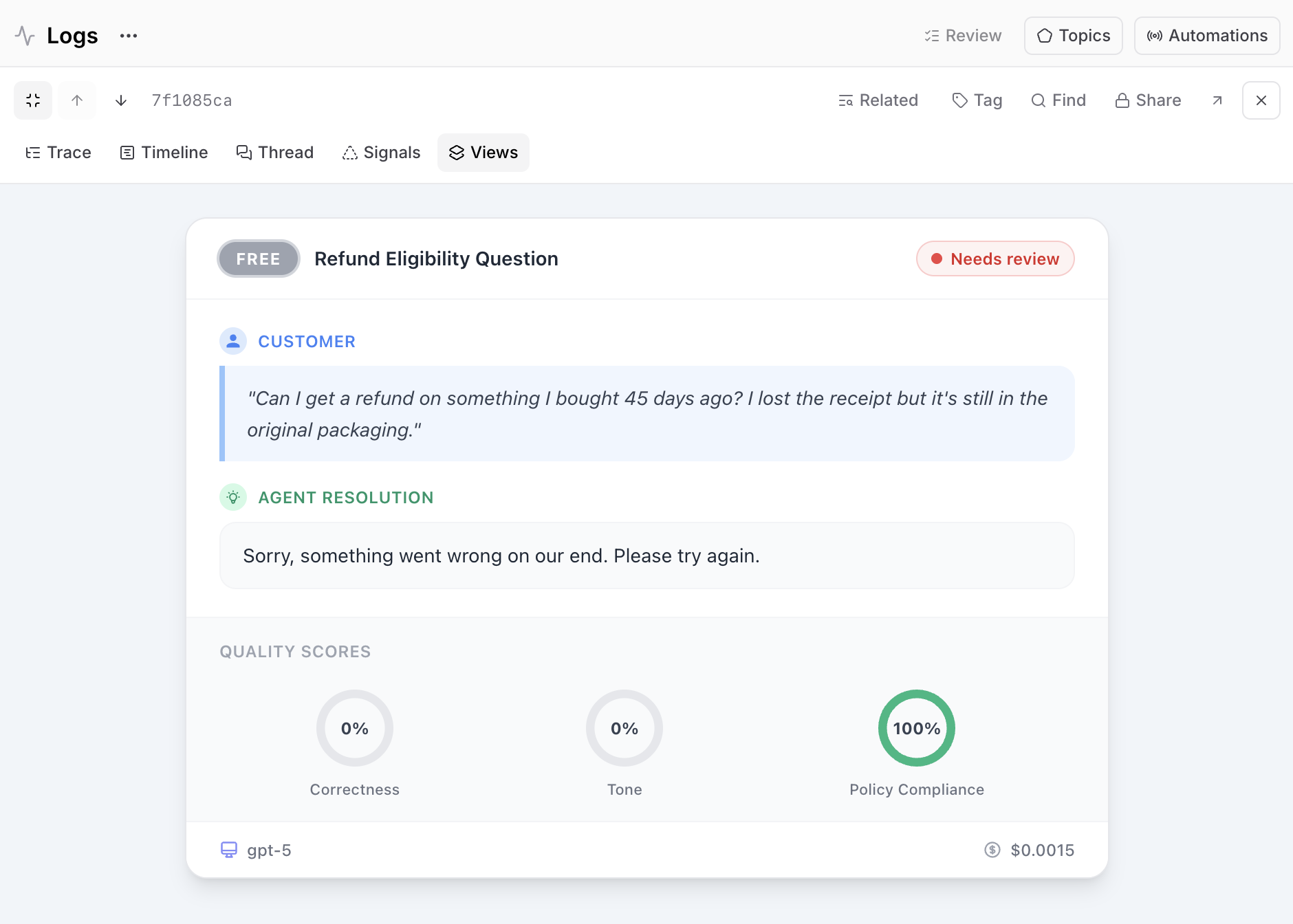
自定义trace视图:查看单次交互
仪表盘告诉你指标下降了,但它不会告诉你某次糟糕运行内部发生了什么。为此,自定义trace视图很有帮助。
原始trace是一个充满JSON、按span逐一展示AI内部工作的视图。工程师能读懂,但对非技术背景的利益相关者来说就比较困难。自定义trace视图可以将该trace转化为团队中任何人都能读懂的界面。用自然语言描述你想要的视图,Loop会生成一个可交互的React组件,你可以对其进行优化并保存到项目中。
例如,你可以构建一个简化视图,将JSON转化为结构化的摘要,这样非工程师人员无需解析span就能读懂trace。你也可以构建一个领域特定视图,使其镜像产品界面,比如将客户支持trace渲染为一张工单卡片,包含用户群体徽章、客户问题、客服解决方案、质量分数仪表盘,以及底部的模型和成本信息。视图越接近最终用户所见,利益相关者就越容易判断行为是否正确。
将视图保存为新版本,并使其在项目范围内可用。有了一个或两个这样的视图,你就可以在会议中打开单个trace,让所有人都能理解发生了什么。
Loop:即席查询
Loop是一个内置的AI助手,可以将自然语言转化为针对生产数据的SQL查询,无需工程支持。当会议中突然出现一个问题,而还没有现成的图表来回答时,它就很有用。
输入问题,Loop会编写SQL,针对日志运行,并返回答案。你可以问诸如:
- 哪些端点最昂贵?
- 查找用户感到沮丧的trace。
- 昨天哪些模型的p95延迟最高?
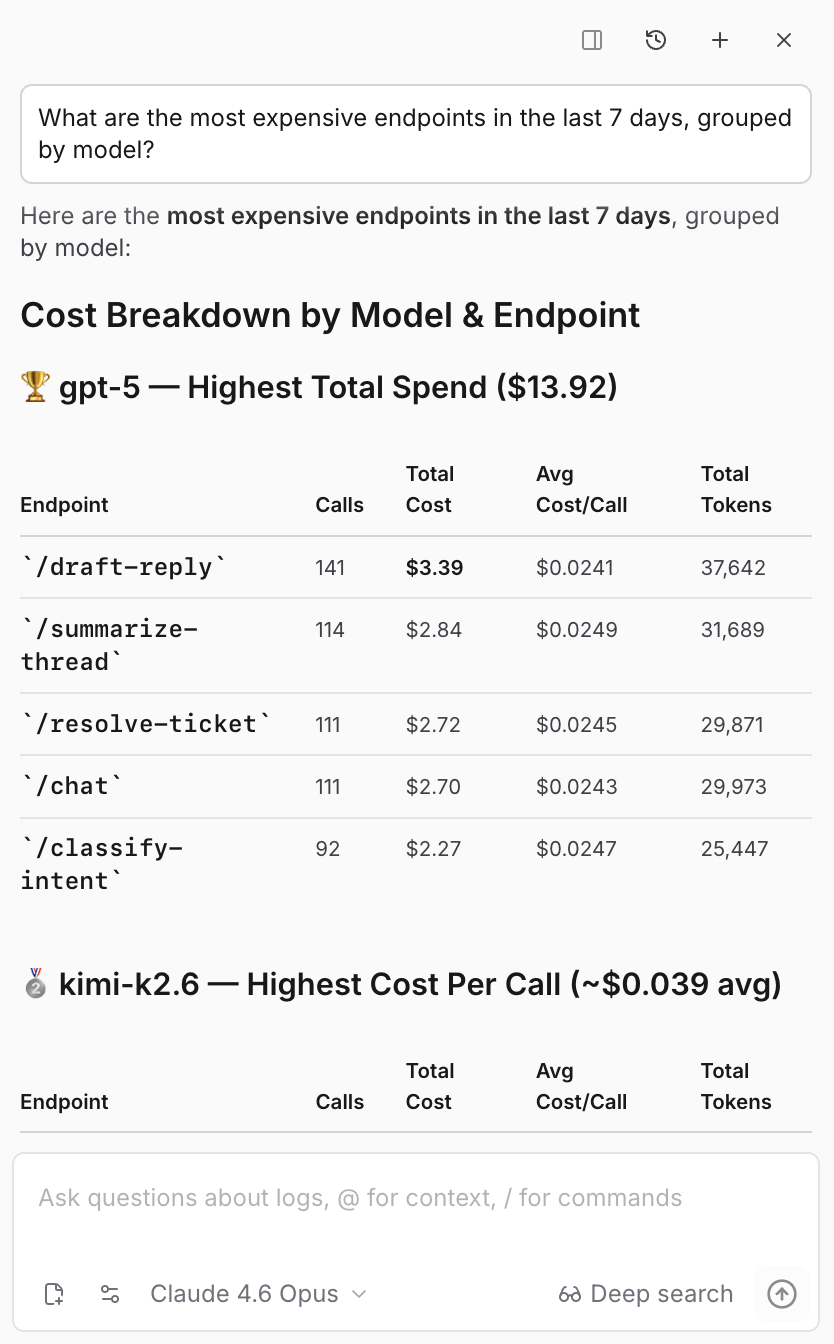
在Monitor页面上,Loop还可以根据自然语言生成图表。你可以要求生成诸如“过去7天内错误率最高的前5个模型”或“Claude模型随时间变化的错误率”等图表。当一个一次性问题变成了你每周都想看的内容时,可以将该图表提升到仪表盘上,使其成为你定期评审的一部分。
Loop同样可以为Logs表生成SQL筛选器。打开筛选编辑器,切换到SQL模式,然后描述筛选条件。
如果你想深入挖掘,甚至可以要求Loop从匹配某个模式的trace中构建一个数据集,生成一个能检测到你刚发现的失败模式的评分器,或者总结你选定的一组trace中的常见问题。
开始使用
选择你的团队正在开发的一个AI功能,为你最需要对齐的受众构建一个仪表盘。构建一个自定义trace视图,让非工程师也能读懂单次交互。写下几个你希望Loop为你回答的问题。几周后,这些将成为你的团队在对齐会议上引用的信息载体,而不是要求你提供状态更新,任何人都可以就功能是否足够好形成自己的看法。
想了解更多关于PM如何端到端掌控AI质量的内容,Evals for PMs深入介绍了评估工作流程,而Evals are the new PRD则论证了将可衡量的质量置于AI产品规格制定核心位置的理由。