SWE-Check:Bug 检测快 10 倍
Introducing SWE-Check: 10x Faster Bug Detection
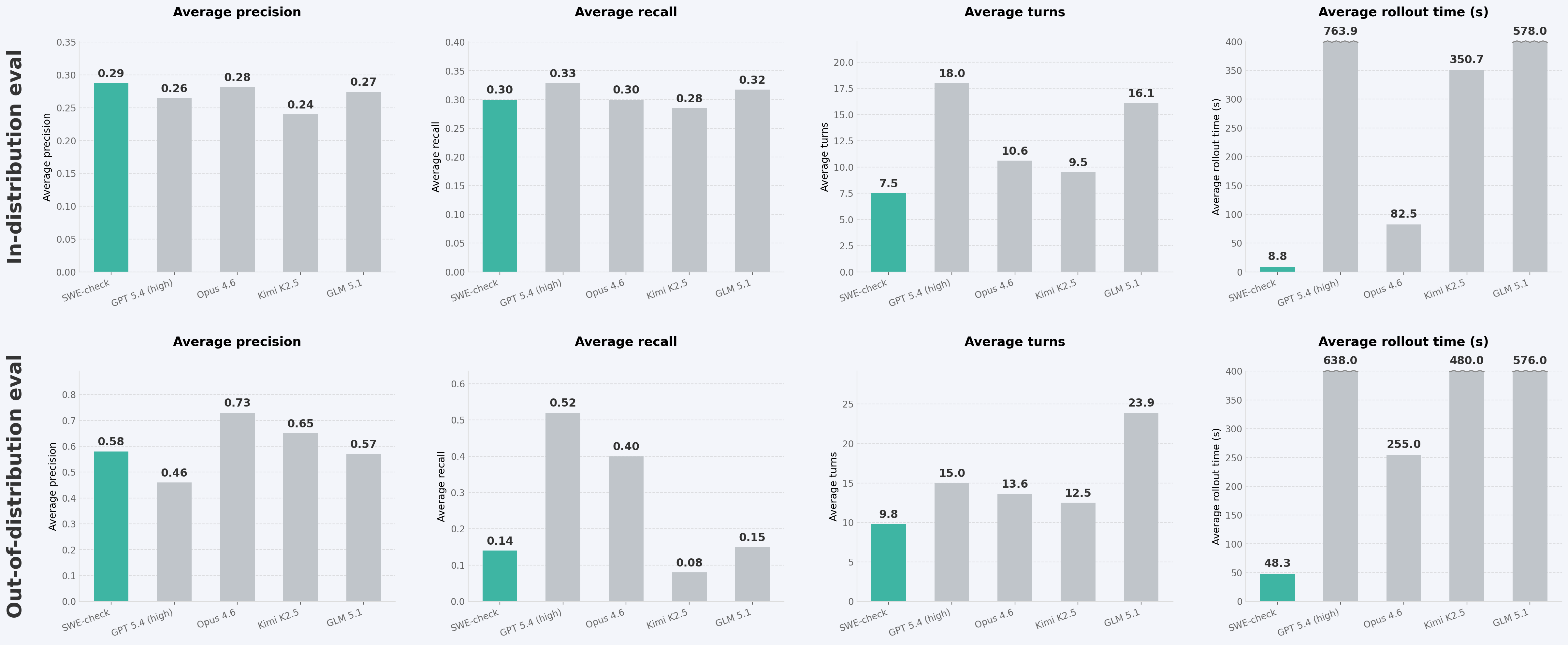
Cognition 与 Applied Compute 通过协作 RL 训练专用 bug detection 模型 SWE-check,集成 Windsurf 生产 harness,采用 reward linearization 和 two-phase post-training。其 in-distribution eval 相对 Opus 4.6 的 delta F1 从 0.09 降至 0,out-of-distribution 从 0.49 降至 0.29,runtime 快一个数量级,预览版已在 Windsurf Next 提供。
更小、更专用的模型,在其训练任务上可以以一小部分成本和延迟,媲美 frontier generalists。
我们与 Applied Compute 合作,通过协作 RL-train 一个 bug detection 模型来验证这一点。结果是 SWE-check:它在内部 in-distribution evals 上达到 frontier 性能(相对 Opus 4.6 的 delta F1 从 0.09 变为 0),并在 out-of-distribution evals 上取得了有意义的进展(相对 Opus 4.6 的 delta F1 从 0.49 降至 0.29)。
虽然 SWE-check 在纯能力方面的 out-of-distribution evals 上仍落后于 frontier,但它的 wall-clock runtime 快一个数量级、inference cost 更低,使得即时且免费的 bug detection 体验成为可能,而这是 frontier models 难以提供的。我们会继续改进这个模型,并预计在 data generation pipeline 上的进一步工作也将帮助我们缩小 out-of-distribution evals 上与 frontier 性能的差距。SWE-check 的预览版今天已在 Windsurf Next 中提供,并将很快在主线 Windsurf 中发布。
下面是我们的做法:
- 在 RL 期间与生产环境原生集成
- 使用一种我们称为 reward linearization 的新技术,将期望的全局指标转换为 sample-level reward
- 引入多个 post-training 阶段,构建一个既有能力、又与产品使用模式对齐的模型
SWE-check Agent 及其要求
SWE-check agent 会分析当前 diff,并标记任何可能由该改动引入的 bug。
一个新的 config flag 会静默地将输出值从 timestamps 切换为 normalized fractions。每个被修改的文件在内部都是一致的,但要发现问题,需要跨三个文件追踪 data contract,才能看到假设在哪里发生了分歧。
这不是典型的 code analysis 任务;与在 chat interface 中运行的普通 coding agents 不同,SWE-check agent 会生成结构化输出,其中包含 bug 描述和 bug-fixes,并能在 Windsurf 中良好渲染。
下面是我们训练数据集中一个 ground truth bug 的示例,用于说明模型所训练的任务类型:
Repository: block/goose
Commit: cd0b7d69
PR(s) fixing bugs that trace back to this commit:#5066
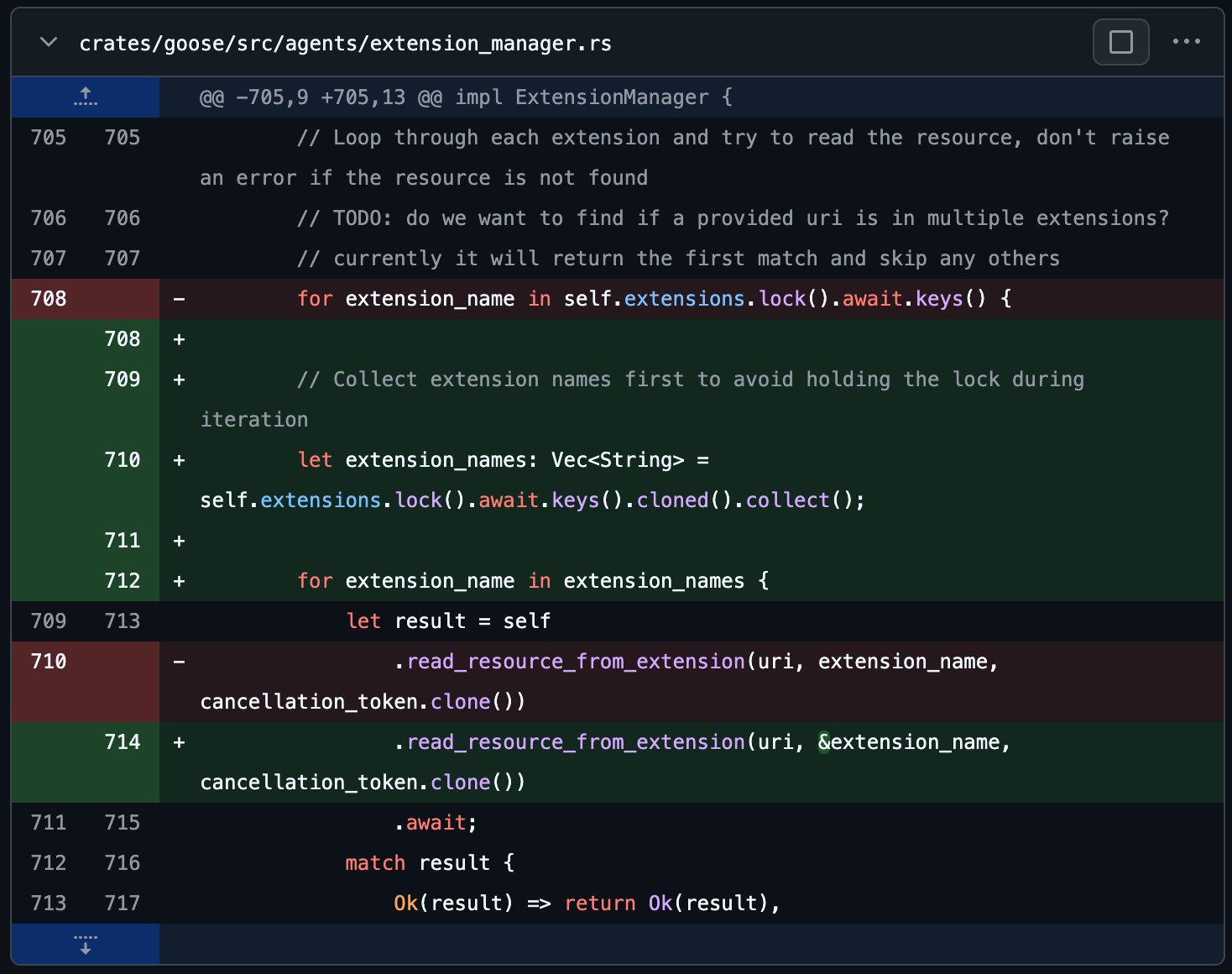
Bug 1: Concurrency & Threading - High severity(2 处改动)
- Description: 代码在持有 extensions mutex guard 的情况下,遍历 self.extensions.lock().await.keys() 返回的 keys view。随后 loop body 又 await 了对 read_resource_from_extension 的调用,而该调用本身可能尝试锁定同一个 self.extensions mutex。在一个会导致重新加锁尝试的 await 期间持有 mutex guard 会造成 deadlock,因为在请求重新加锁前,原 guard 并未释放。这表现为 extension manager 在尝试从 extensions 读取 resources 时挂起。
- Fix: 在进入 extension-specific logic 进行迭代和 await 之前,代码现在会在持有锁时通过 clone keys 将 extension names 收集到一个拥有所有权的 Vec 中,然后立即释放锁。后续迭代会在收集到的 names 上运行(不持有 mutex),并用每个 name 的 reference 调用 read_resource_from_extension。这避免了在 await 期间持有 extensions mutex,并消除了导致 deadlock 的 reentrant lock attempt。集合操作上方还添加了一条简短说明注释,以记录原因。
- Ground truth bug-fix:
训练期间,模型从一个 sandbox 中开始,其中 repo 已 checkout 到 source commit;然后它的任务是输出自己识别出的 bug,包括描述和 bug-fixes。这些 bug 会与该 source commit 的 ground truth bugs 进行比较。
这个 agent 还需要接近实时,让用户保持 in flow,并尽一切可能避免我们所说的 The Semi-Async Valley of Death。幸运的是,像 Cerebras 这样的 inference providers 可以在几秒钟内,在最终输出之前完成数千 tokens 的密集 intermediate thinking。
与此同时,模型需要有极高质量:在确实存在细微 bug 时可靠地找到它们,同时也不要用愚蠢的 non-bugs 打扰用户。在决定进行 RL 训练之前,我们让同事们在 SWE-check harness 中 dogfood 各种现成的 frontier models,包括 open-source 和 closed-source。他们发现,达到质量门槛的 frontier models 对 IDE 中的 on-demand bug detection 来说太慢、太贵。这促使我们 RL-train 一个 open-source model,让它在这个任务上高度专用——快速且有能力。
我们运行了两个主要 evals:
- in-distribution eval:从我们的 data pipeline 生成的任务中随机抽取一个子集,并从构成训练分布的其他任务中保留出来。
- out-of-distribution eval:由 Cognition 内部在 Cognition codebase 中收集的 bug 组成,并在训练过程中完全 hold-out。
下面是最终训练模型与 frontier closed-source 和 open-source models 的性能对比:
使用生产设置进行训练
一个经过训练成为 specialist 的更小、更快、更便宜的模型,可以在它的 “spike”(即其专长领域)上达到 frontier performance。为了在我们选择的 spike——SWE-check 任务——上,在三个维度都提供尽可能好的结果,我们必须复刻模型在生产中实际被 serve 的环境。这将确保训练中观察到的任何增益,都能直接转化为 Windsurf IDE 中更好的最终用户体验。
为此,我们在 training sandbox 中复刻了 Windsurf harness 可用的 toolset。我们还整理了一个涵盖多种 programming languages、bug types 多样的数据集,并共同迭代该数据集,以确保其分布能代表生产环境中的预期情况。
我们还做了大量工作,使 training reward 与 SWE-check agent 早期版本 dogfooding trials 中的用户行为对齐。例如,我们查看了用户在调用 SWE-check 后多久切换离开的统计数据(下一节会详细说明)。
最后,也是我们认为最重要的一点,我们迭代训练了 多个 模型,并与 dogfooding 建立了紧密 feedback loop。尽管我们投入了大量精力让模型针对 reward function 进行训练,但最终最重要的仍然是人类偏好,以及这个 agent 在实际工作中使用起来的感受。参与 dogfooding 的人对每次迭代都给了我们极其有价值的反馈。
例如,在一次迭代中,我们收到反馈:模型会不断报告一些 bug,但如果它只是查一下 code block 中某个变量的定义,就会知道该 code block 是正确的。我们意识到,agent 无法访问 turn-efficient tracing tools 来帮助它查找定义和引用,于是我们在 Windsurf 和训练设置中构建并暴露了这些新工具,然后重新训练。
specialization 过程的关键结论是:来自生产环境的反馈会直接驱动 training runs 的迭代。所有进入 model training run 的内容,都能直接追溯到生产环境的某个方面,或来自真实用户的反馈。
我们如何设计 reward function
post-training 中使用的 reward 决定了模型的行为。我们的 technical report 聚焦两个关键想法:
- Reward linearization:提供 sample-level reward,作为 hill-climbing population level statistic 的 proxy。我们取一个能代表用户偏好的全局指标,并将其转换为可分配给每个单独 sample 的 reward。
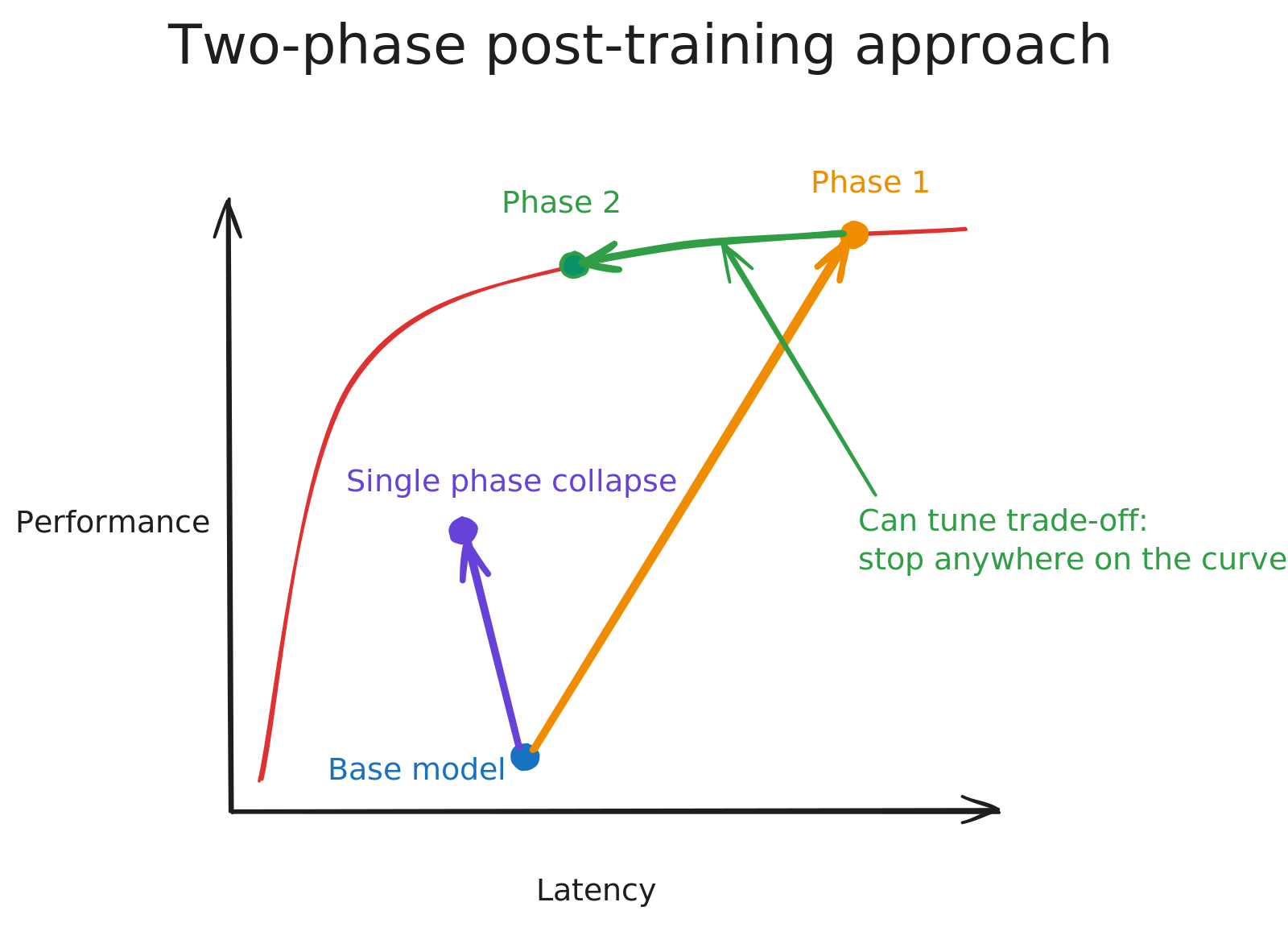
- Two-phase post-training:先最大化能力,然后通过降低 latency 使模型与产品使用模式对齐。我们发现,将 post-training 拆分为这些阶段,比简单地针对一个同时捕捉能力和使用模式的 reward function 进行训练,能得到更强的模型。
Reward linearization
我们首先形式化训练设置。每个 rollout τ 都有自己的一组 ground truth bugs(可能为 0)。我们按如下方式为一组 predicted bugs 打分:
- 我们首先用一个简单的 LLM-judge pass 检查 bugs 的 scope 是否正确——如果列表中的任何 bug 实际上是两个不同问题的聚合,我们将分数设为 0。
- 然后,我们检查列表中的每个 predicted bug 是否匹配某个 ground truth bug。
- 这些检查的结果使我们能够计算 sample-level precision 和 recall,我们将其定义为 P(τ) 和 R(τ)。它们应始终是 0 到 1 之间的数字。我们按如下方式处理 edge cases: 1. 如果没有 predicted bugs,也没有 ground truth bugs,我们将 precision 和 recall 设为 1 2. 否则,如果 predicted bugs 和 ground truth bugs 两个列表中恰好有一个为空,则将 precision 和 recall 设为 0
我们如何在许多 samples 上聚合这些分数?有两种合理做法:
- 我们可以聚合 true positives (TP)、false positives (FP) 和 false negatives (FN) 的全局总数,计算全局 precision 和 recall,然后将它们组合成一个 f_β score。
- 我们可以在 samples 上平均 P(τ) 和 R(τ),得到 average precision 和 average recall,然后将它们组合成一个 f_β score。
由于我们不希望模型在 ground truth bugs 很多的样例上表现得不成比例地好(以牺牲 ground truth bugs 很少或没有的样例上的表现为代价),因此我们选择第二种做法。
🚨 β 的选择:模型的早期迭代使用 β=1,并产生了许多 false positives,在 dogfooding 期间将许多 benign diffs 标记为 bugs。为缓解这一点,我们决定切换到 β=0.5,强调 precision。
我们定义 R_pop = E_τ[R(τ)] 和 P_pop = E_τ[P(τ)]。我们最终希望模型提升以下指标:
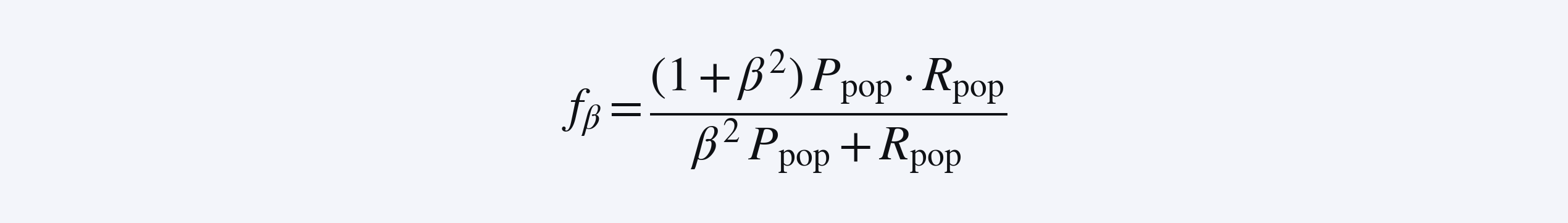
给定这个全局指标,那么我们的 sample level reward 应该是什么?一个关键观察是,我们不能直接使用
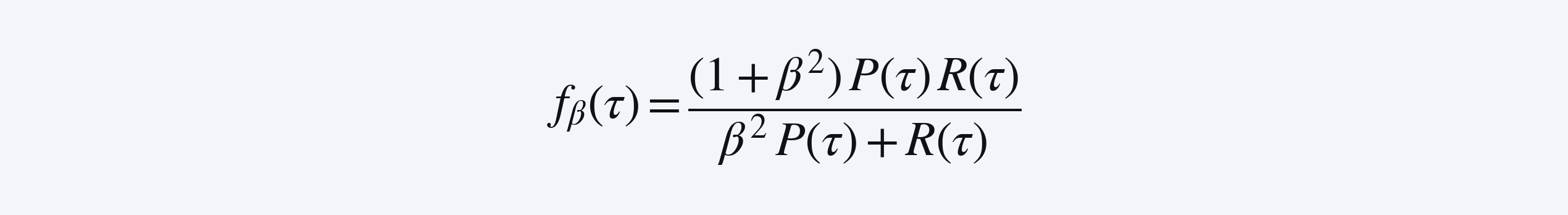
因为对 f_β(τ) 求平均并不会得到 f_β。这促成了我们关于 reward linearization 的想法:我们根据 P_pop 和 R_pop 计算 f_β 的一阶近似,使得平均运算实际能够成立!
由于我们对 P_pop、R_pop 的初始值(称为 P_pop,init 和 R_pop,init)以及 TP/FP/FN rates 的初始分布有较好了解,因此可以用 P_pop 和 R_pop 的合适一阶线性近似来近似 f_β 值:
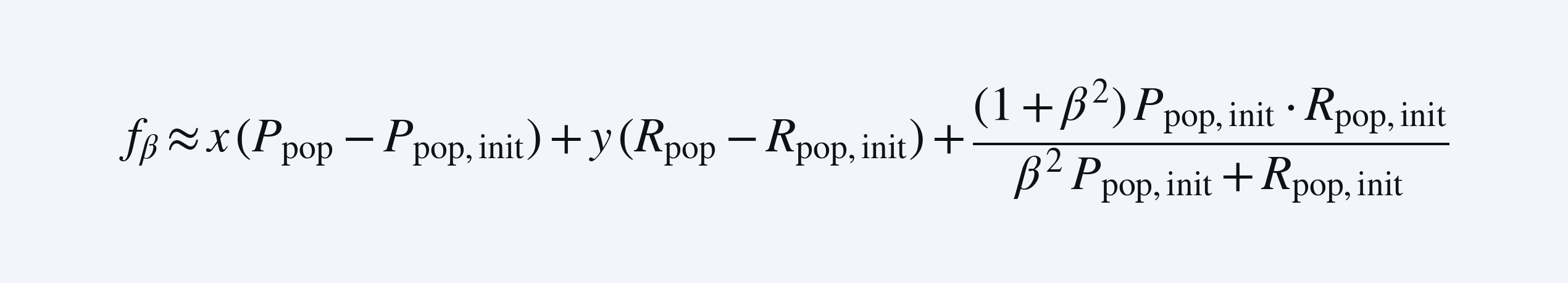
🚨 重要的是,一阶近似需要在了解 TP/FP/FN rates 初始值的情况下完成。在我们的 runs 中,TP/FP/FN rates 的变化并没有在运行过程中显著改变最终的 slopes,因此我们使用了固定的 linearization;如果某些初始值偏离过大,我们的方法可以通过在训练期间重新校准一阶近似来泛化。
那么,一个有效的 sample-level reward function(因为它的平均值会得到上面期望的 f_β 近似)可以是:
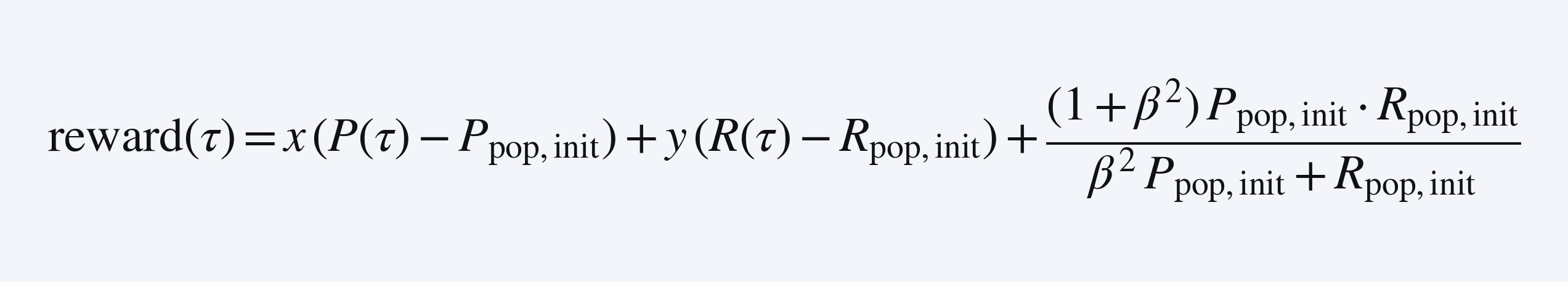
事实上,我们可以对 reward function 进行平移/缩放,因此可以强制 y=1 并移除所有常数项。在我们的案例中,最终使用的 sample level reward 是 reward(τ) = ½·P(τ) + R(τ)。一个对每个 sample 接收 reward(τ) 的模型,最终会按预期提升全局 f_β 指标!
Two-phase post-training
我们的目标是训练一个具有 frontier performance、同时 latency profile 好得多的模型。我们发现,最有效的训练方法是将过程拆分为两个不同阶段。这两个阶段只在 reward function 上不同,其余训练设置完全相同。
- Capability maximization:reward function 是我们在 reward linearization 部分计算出的 base reward function。通过提升这个 reward,模型会纯粹专注于最大化 bug detection skill,而不会因增量 latency 受到惩罚。Capability maximization 占据了整体训练过程的大部分。
- Product alignment:reward function 是 base reward function 加上额外的 “latency penalty”。为了计算 latency penalty,我们首先使用 completion tokens 数量和 tool-calling turns 估计 rollout 的 latency。然后,我们使用 SWE-check agent 早期内部版本的 dogfooding data,观察用户在调用 SWE-check 后多久切换离开的统计分布。
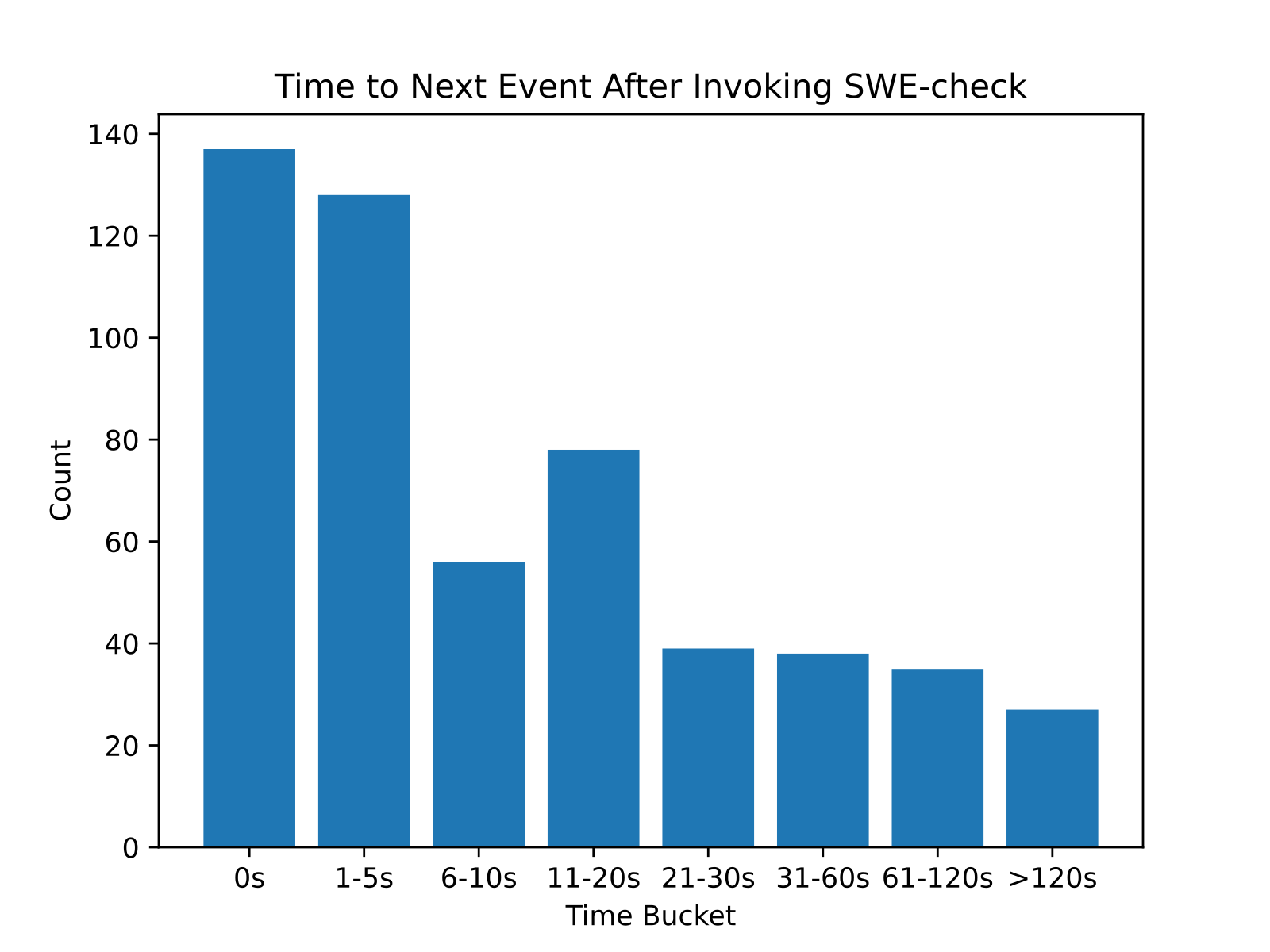
这个分布实际上是我们有多少时间让用户保持 in-flow 的 proxy。然后我们计算该分布的 CDF,并用它定义一个随估计 latency 缩放的 penalty。给定时间点的 CDF 表示届时已有多少比例的用户已经转向其他事情。
我们对 penalty 进行归一化,使其在即时响应时从 0 开始,在尾部为 1,然后在 bucket midpoints 之间做线性插值。
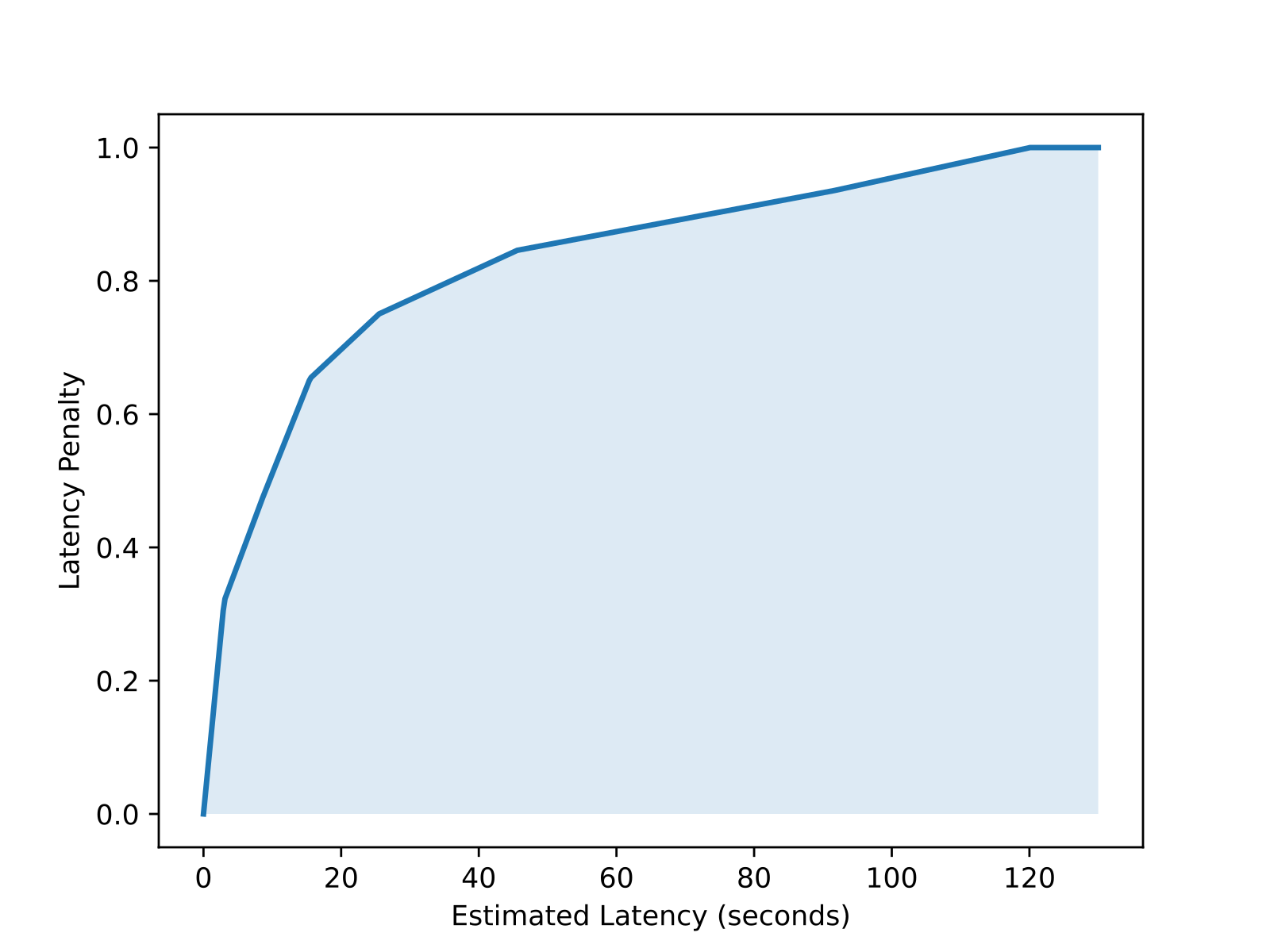
product alignment reward 推动模型去除冗余 tokens,并改进 parallel tool-calling,同时不会为了超出用户体验所需的 latency 而牺牲性能。就 training compute 而言,Product alignment 是一个比 capability maximization 短得多的阶段。
这种 two-phase approach 优于从一开始就使用单个 combined reward function 训练的替代方案。当能力和产品约束被同时优化时,模型往往会收敛到局部最优:例如,学会变得极快,但只生成浅层分析,满足了 latency target,却漏掉了真实 bug。将阶段分离,使模型能够先形成对任务的真实理解,然后学习如何高效压缩这种理解。
此外,在 post-training 的第二阶段,我们观察到:
- 起初,当 latency penalty 被降低时,模型性能几乎没有退化;
- 随后,随着 latency penalty 继续降低,模型性能开始更明显下降。
因此,第二阶段是一个可调旋钮,我们可以用它精确选择最适合我们 use case 的 performance-latency profile。在我们的案例中,如前所述,我们根据产品使用模式选择了这条 Pareto frontier 上的一个点。
结论
总结一下,model specialization 是一种强有力的工具,可以在 latency、cost 和 user experience profile 更优且与产品功能深度对齐的情况下,接近 frontier performance。
与 harness 原生集成确保我们的训练收益会反映到生产中。频繁的 dogfooding trials 让我们能够快速将用户反馈转化为 training recipe 的变化。使用 reward linearization 让我们能够有效地将一个生产性能指标下沉到 sample level,用于训练。将 post-training 拆分为多个阶段,使我们能够在 model training 中平衡两个不同目标:核心任务能力和产品 latency 要求。
最终模型仍有有意义的改进空间——尽管它位于 Pareto frontier 上,但它并不是这个任务上绝对能力最强的模型。本文讨论的 training recipe 已被证明能在 in-distribution 和 out-of-distribution evals 上良好 hill-climb;随着更广的数据组合和改进的 base models,我们预计性能会随时间继续提升。
你今天就可以在 Windsurf Next 中使用 cmd+U 快捷键试用 SWE-check 预览版。它很快将在 Windsurf 中提供。