Cohere 发布 Command A+
Introducing Command A+ | Cohere
Cohere 开源了 Command A+,一款 218B 总参数量、25B 激活参数量的混合专家(MoE)模型,采用 Apache 2.0 许可证。该模型支持 128K 输入上下文、64K 最大生成长度,覆盖 48 种语言及文本、图像、工具使用模态。在 𝜏²-Bench Telecom 上得分从 37% 提升至 85%,Terminal-Bench Hard 编码性能从 3% 提升至 25%,MMMU Pro 达 63%。提供 W4A4 量化版本,可在 2 块 H100 或 1 块 B200 上运行,TOPS 提升 63%,TTFT 降低 17%。
今天,我们开源了 Command A+。Command A+ 是一款混合专家(MoE)模型,它高效、通用且可私有化部署,专为高性能 agentic 任务而设计,计算开销极低。
这款模型源于我们与客户一起部署 North 的一年经验,它超越了 Command 系列的所有前代产品,并将其能力统一到一个可扩展的单一模型中。
现在,Command A+ 在 Apache 2.0 许可证 下免费提供,这推进了 Cohere 使主权 AI 成为技术现实的使命——让开发者能够在实验、部署和生产工作流中直接使用企业级的 agentic 能力。
访问 Hugging Face 下载权重——提供多种近无损量化版本——并阅读我们的实现指南。如需专用、托管的推理环境,请立即在 Model Vault 中部署 Command A+。
概览
| 模型 | command-a-plus-05-2026 | | --- | | 许可证 | Apache 2.0 | | 架构 | 稀疏 / MoE | | 模型大小 | 218B 总参数量;25B 激活参数量 | | 上下文长度 | 128K 输入上下文;64K 最大生成长度 | | 输入模态 | 文本、图像、工具使用 | | 输出模态 | 文本、推理、工具使用 | | 语言 | 支持 48 种语言。完整列表 | | 优化方向 | 推理、agentic 工作流、RAG、多语言、多模态文档处理 | | 支持框架 | vLLM、Transformers | | 硬件(最低) | 1× B200 @ W4A4 2× H100s @ W4A4 |
向北而行
过去一年,North——Cohere 用于构建和部署 agentic AI 的集成企业工作空间——一直是我们大部分创新的驱动力。通过这项工作,我们着手为客户构建一个统一的模型,以简化部署、支持本地运行,并整合 Command 系列的能力。
这项工作已初见成效。请阅读我们的客户如何利用 North 改造其运营。
然而,主权 AI 的意义远不止 Cohere 本身。赋予工程师自行运行、控制和调整模型的能力,是这一代 AI 面临的最严峻挑战。
我们针对实际、以开发者为中心的使用场景优化了 Command A+,包括支持低位量化、高效推理以及与开放推理框架的集成。实现人人可用的 AI 独立性。
我们迫不及待地想看到社区将用它构建什么。
Command,整合一体
Command A+ 在企业工作负载的关键维度上优于之前的 Command A 模型,包括多模态理解、检索、长周期和复杂推理。
| Command A+ | Command A | Command A Reasoning | Command A Vision | Command A Translate | |
|---|---|---|---|---|---|
| 大小 | 218B A25B | 111B | 111B | 112B | 111B |
| 推理 | ✓ | — | ✓ | — | — |
| 多模态 | ✓ | — | — | ✓ | — |
| 工具使用 | ✓ | ✓ | ✓ | — | — |
| 多语言 | 48 | 23 | 23 | 6 | 23 |
图 2:比较 Command A+ 与 Command A 系列其他模型的能力。
与 Command A Reasoning 相比,𝜏²-Bench Telecom 得分从 37% 提升至 85%,Terminal-Bench Hard 上的 agentic 编码性能从 3% 提升至 25%。在非 agentic 推理、指令遵循和其他代码生成任务上也取得了进步。
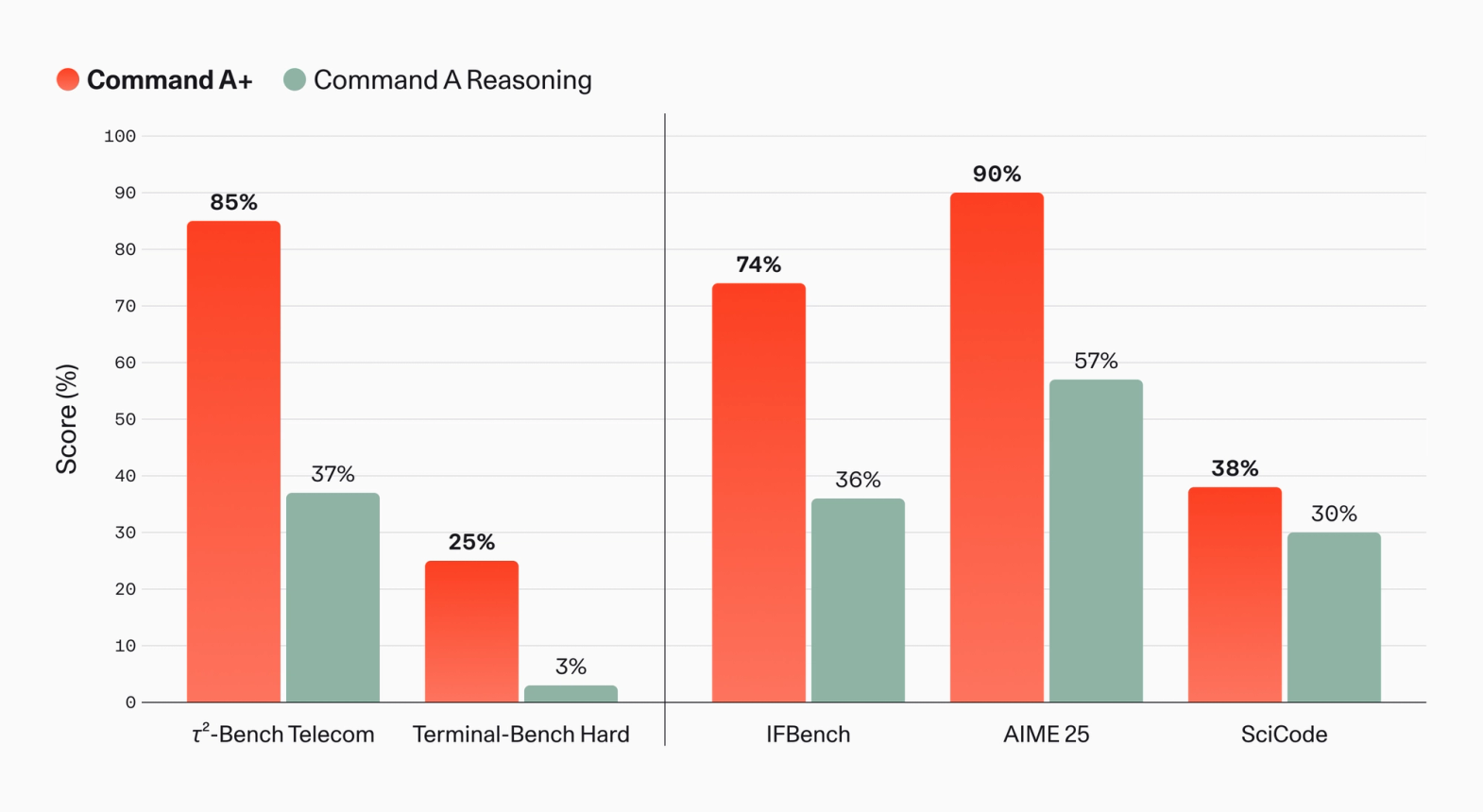 图 3:Command A+ 和 Command A Reasoning 在一系列流行开源 benchmark 上的性能。详情见脚注。1
图 3:Command A+ 和 Command A Reasoning 在一系列流行开源 benchmark 上的性能。详情见脚注。1
Command A+ 在 North 应用中表现强劲,反映了其最初的设计目标。Agentic 问答准确率和电子表格分析质量分别比 Command A Reasoning 提升了 20% 和 32%。记忆性能——测试 North 在跨对话和存储数据进行推理方面的能力——Command A+ 得分为 54%,而 Command A Reasoning 为 39%。
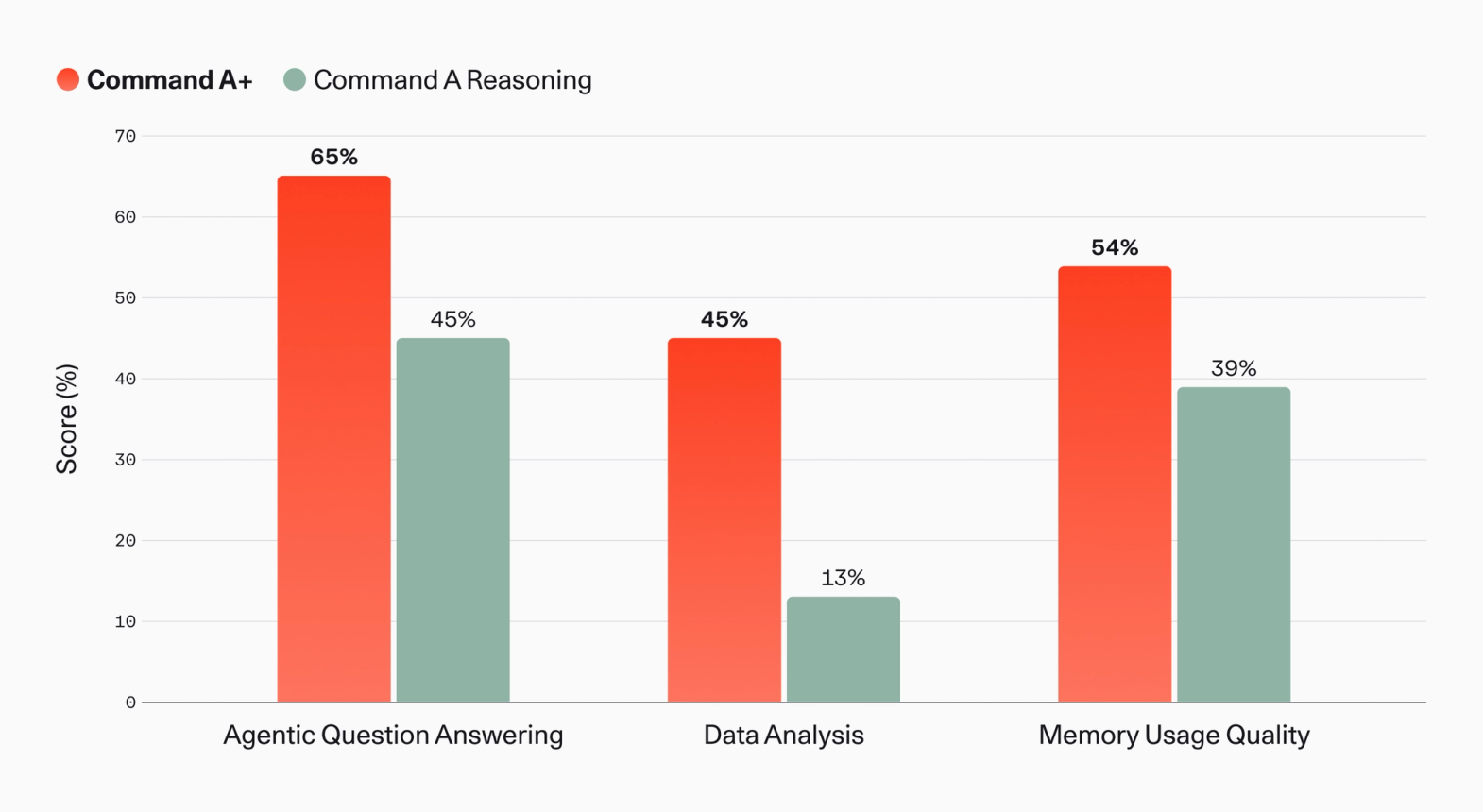
图 4:North 上三项内部评估的性能提升。Agentic 问答衡量模型使用 MCP 连接的云文件系统回答企业问题的能力。数据分析衡量模型对上传的电子表格执行数据科学任务的能力。记忆使用质量衡量 agent 利用 North 记忆系统中先前会话的信息来回答后续会话问题的能力。所有评分均使用 LLM-as-a-judge 技术。
在多模态理解和推理方面,Command A+ 在 MMMU Pro 上达到 63%,在 MMMU 上达到 75.1%(后者 Command A Vision 为 65.3%)。MathVista 得分从 73.5% 提升至 80.6%,CharXiv 推理从 46.9% 提升至 52.7%,反映了文档理解任务的广泛进步。
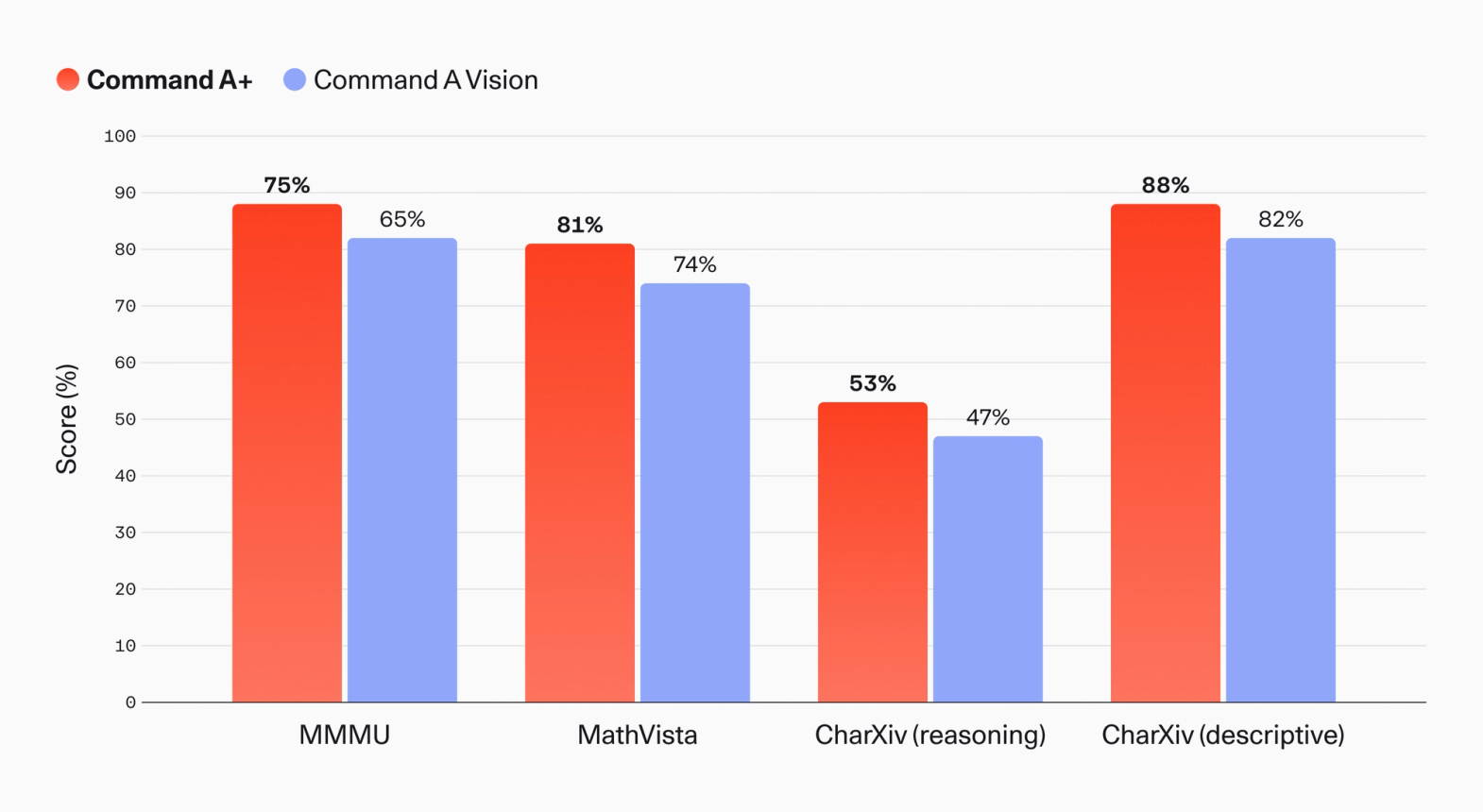
图 5:Command A+ 和 Command A Vision 的多模态性能比较。Command A+ 是 Cohere 首个多模态推理模型,在 CharXiv 推理等相关任务集上相比 Command A Vision 有显著提升。我们遵循给定 benchmark 的标准方法。
Command A+ 显著扩展了多语言能力,语言覆盖范围从 23 种扩大到 48 种,并在机器翻译和多语言推理方面取得了进步。
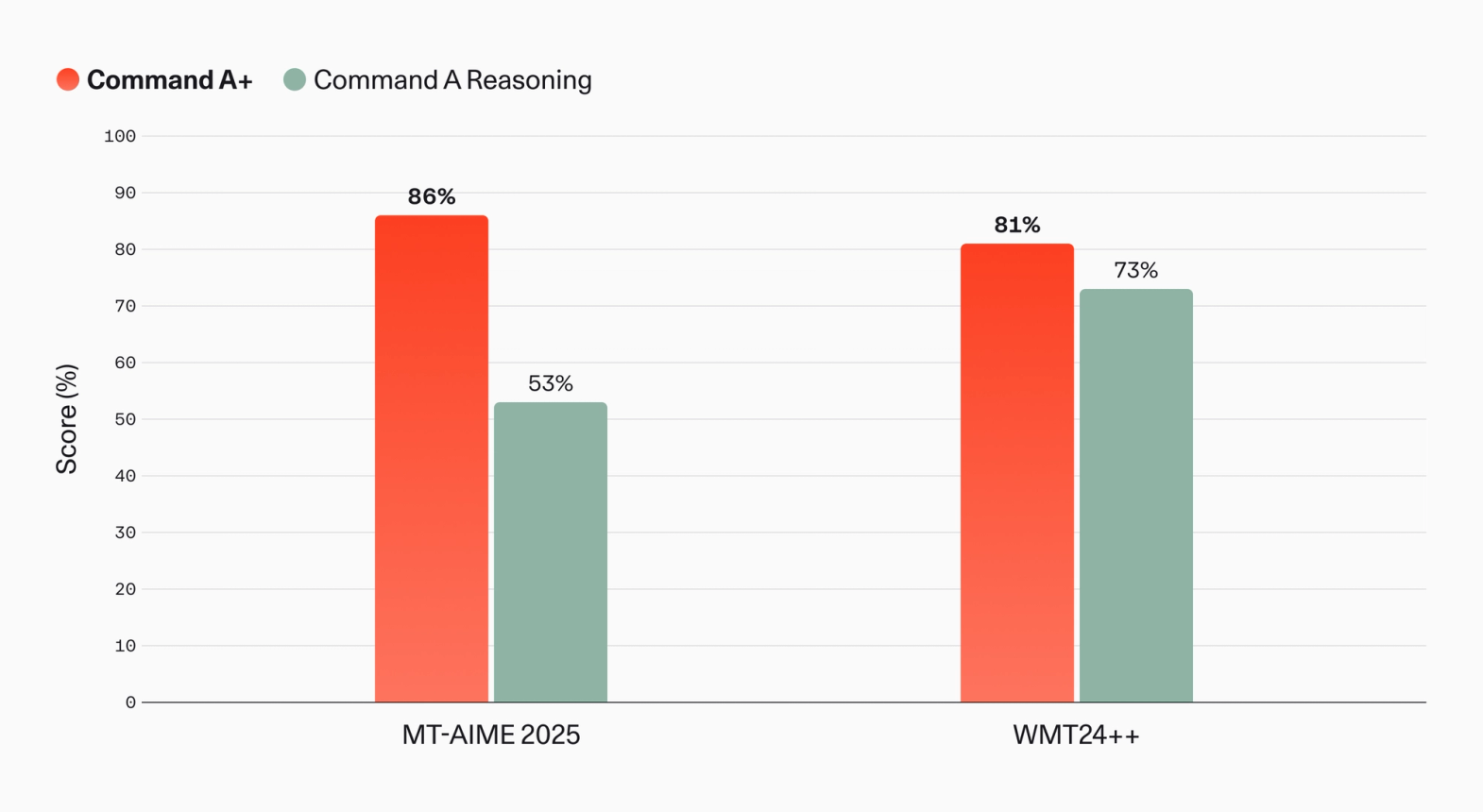 图 6:Command A+ 和 Command A Reasoning 的多语言性能比较。MT-AIME 2025 是 AIME-2025(一个英文数学 benchmark)的内部翻译版本,针对阿拉伯语、日语和韩语进行评估。WMT24++ 是一个广泛使用的公开 benchmark,此处使用 xCOMETxl 进行评估。2
图 6:Command A+ 和 Command A Reasoning 的多语言性能比较。MT-AIME 2025 是 AIME-2025(一个英文数学 benchmark)的内部翻译版本,针对阿拉伯语、日语和韩语进行评估。WMT24++ 是一个广泛使用的公开 benchmark,此处使用 xCOMETxl 进行评估。2
Command A+ 在 Artificial Analysis Intelligence Index 上获得 37 分,优于其他领先的开放模型,反映了其作为企业 agentic 工作流通用模型的实力 [3]。
规模化的效率
效率是企业 AI 部署的核心约束。它通过决定可靠且经济高效地服务模型所需的计算、内存、延迟、功耗和基础设施,来确定语言模型能否在实际规模下部署。
我们设计 Command A+ 时注重极高的硬件效率。该模型目前在 Hugging Face 上提供 16-bit (BF16)、8-bit (FP8) 和 4-bit (W4A4) 量化版本,质量差异几乎不可察觉。实际上,这使得 Command A+ 可以仅在两块 NVIDIA H100 或一块 NVIDIA Blackwell GPU 上运行,且几乎没有质量下降。
Command A+ 也是我们迄今为止最快的模型,总参数量为 218B,激活参数量为 25B,而 Command A Reasoning 的密集架构为 111B。在相同的量化和并发级别下,其每秒输出 Token 数(TOPS)提升高达 63%,首 Token 时间(TTFT)降低高达 17%。W4A4 量化额外贡献了 47% 的速度提升和 13% 的延迟降低。
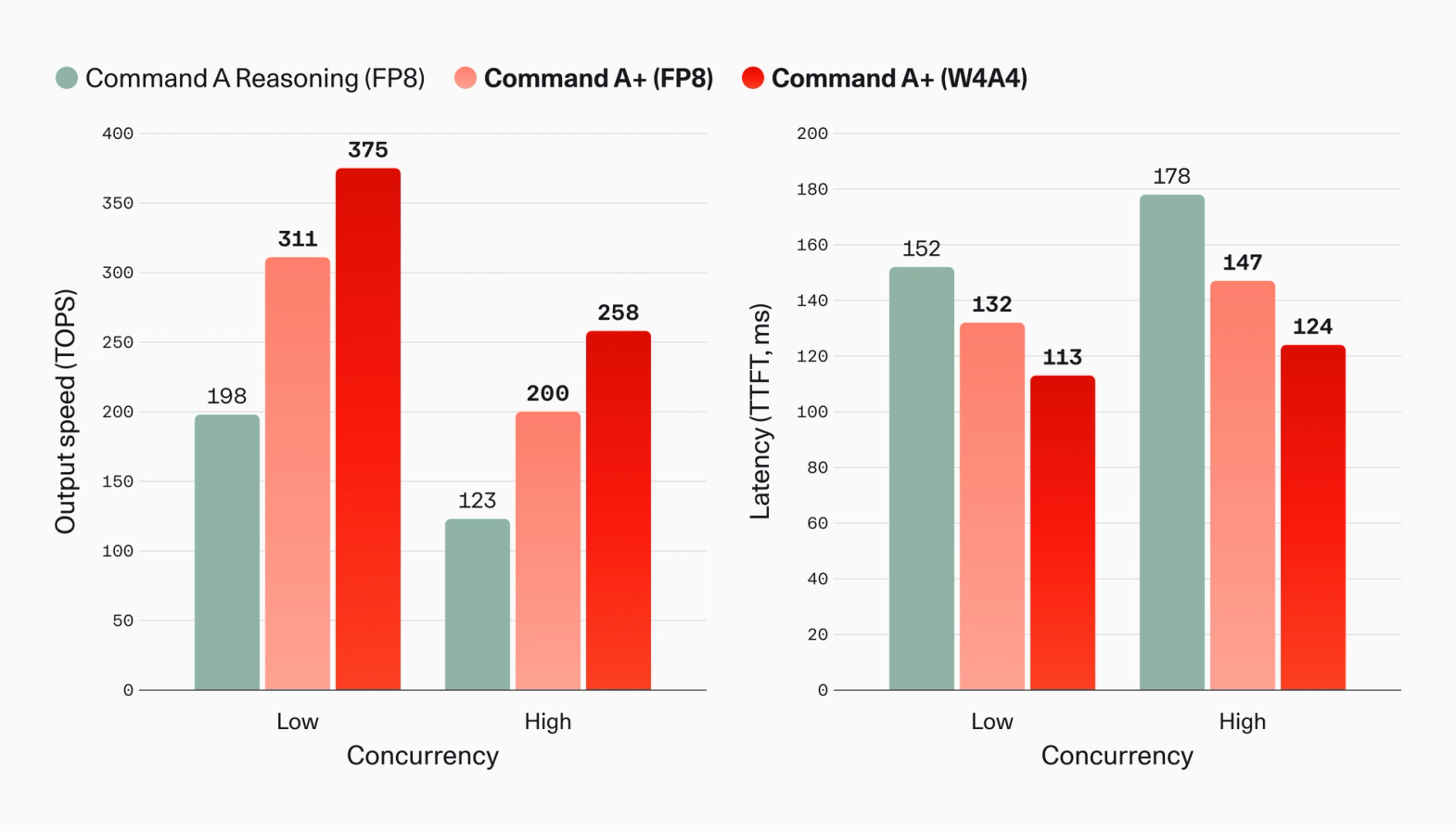 图 7:不同并发度和模型量化下 Command A+ 与 Command A Reasoning 的速度和延迟比较。TOPS = 模型生成 Token 时每秒接收的 Token 数(即从 API 收到第一个 chunk 之后)。TTFT = API 请求发送后收到第一个 Token 的时间(秒)。4
图 7:不同并发度和模型量化下 Command A+ 与 Command A Reasoning 的速度和延迟比较。TOPS = 模型生成 Token 时每秒接收的 Token 数(即从 API 收到第一个 chunk 之后)。TTFT = API 请求发送后收到第一个 Token 的时间(秒)。4
我们还使用推测解码来加速文本生成,同时不影响输出质量。我们针对模型的 MoE 架构优化了该方法,为文本和多模态输入额外提供了 1.5-1.6 倍的推理加速。在此处阅读更多关于我们工作的内容。
Command A+ 是首个使用我们最新 tokenizer 的模型,相比前代实现了显著的压缩改进。现在生成相同响应所需的 Token 更少,从而降低了推理成本的主要驱动因素。值得注意的是,这些改进也惠及主要的非欧洲语言,这些语言在 tokenizer 训练中通常代表性不足。阿拉伯语的 tokenization 效率提升了 20%,韩语提升了 16%,日语提升了 18%。
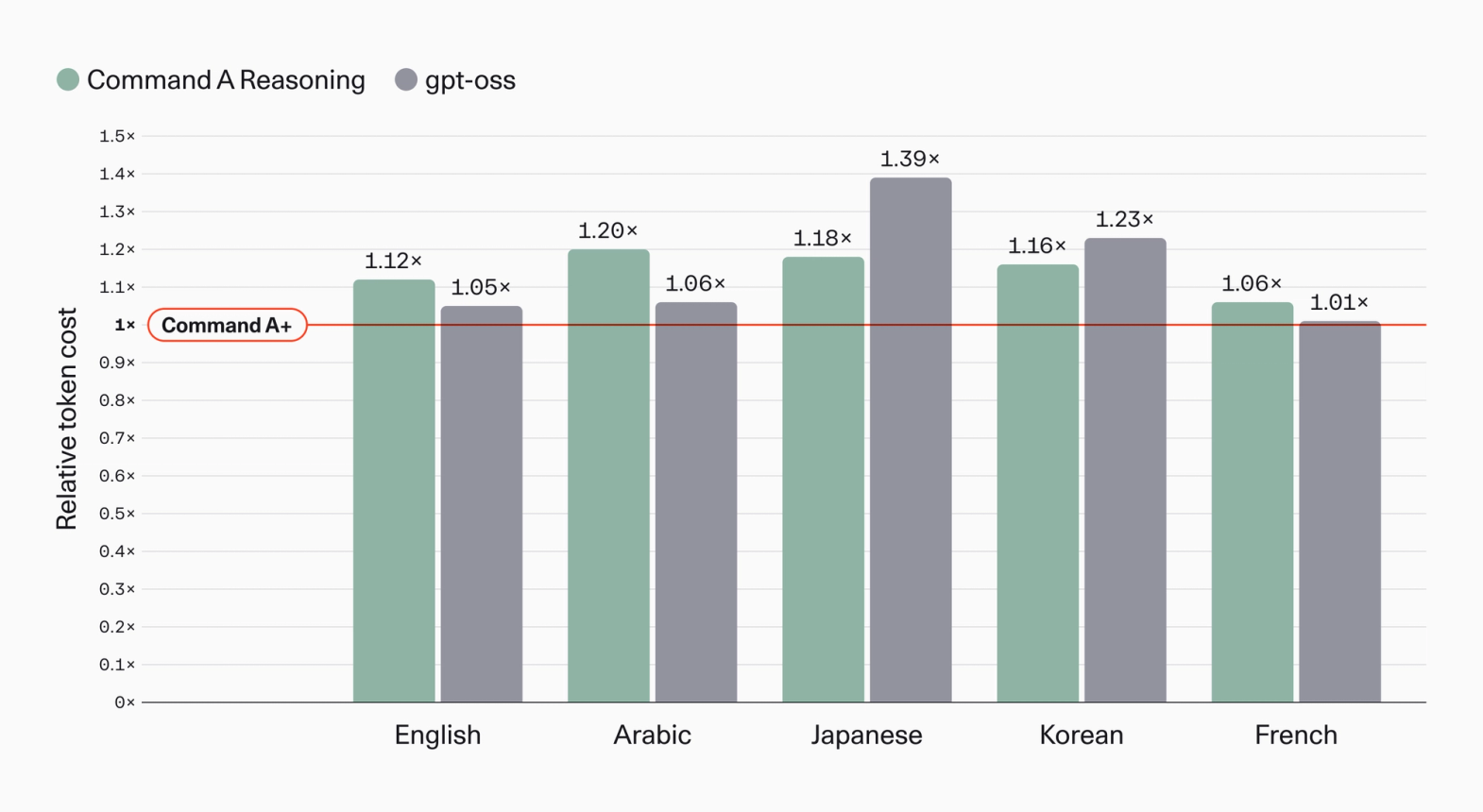
图 8:Command A+、Command A Reasoning 和 gpt-oss 对不同语言产生的 Token 数量比较(以 Command A+ tokenizer 产生 Token 数量的倍数表示)。
Vivek Mahajan 企业执行官、企业副总裁、首席技术官,负责系统平台 富士通有限公司
下一步是什么?
当今主权 AI 的进步取决于同时推进三个方向:性能、安全性和成本。在 Cohere,我们正在这三个方面进行投资——既在我们的模型中,也在驱动 North 的特定领域能力中。
这意味着改进推理、多模态理解和编码性能,同时确保模型完全适合在客户环境中运行。目标不仅仅是更强的 benchmark,而是能够在实际运营约束下支持企业级转型的系统。
我们已经将这种方法应用于其他模型系列——包括 Embed、Rerank 和 Transcribe——在这些领域,我们在实现高效、成本感知推理的同时,取得了最先进的性能。
开始使用
Command A+ 现已可在 Hugging Face 以及通过 Model Vault 获取。您也可以在 我们的 Space 或使用 Cohere API 密钥 免费试用该模型。
请访问我们的文档获取详细的模型规格、部署指南和入门 cookbook。
脚注
1 𝜏²-Bench Telecom 使用标准设置和来自 [Barres et al. 2025] 的用户模拟进行评估。Terminal-Bench Hard 使用 Terminus-2 harness 按照 Artificial Analysis 的方法进行评估。AIME 2025 在官方 2025 年 30 道题集上评估,每道题重复 10 次。得分是该 300 样本数据集上的 pass@1。IFBench 为单轮、宽松评估模式,报告的得分对应 1470 个样本(294 个独特提示重复五次)的提示准确率。Scicode 使用 65 个测试问题(包含 288 个子问题)进行评估。我们按照 Artificial Analysis 的方法,使用 'scientist-annotated background' 提示每个子问题。
2 MT-AIME 使用 Command A Translate 从英文翻译而来。WMT24++ 得分是 50 个变体的平均值:所有支持的语言,包括原始 WMT24++ 测试集中的 ar_EG、ar_SA、pt_BR、pt_PT、zh_CN、zh_TW。塞尔维亚语使用内部音译至西里尔字母进行评估。爱尔兰语和马耳他语是 WMT24++ 的内部创建翻译。
3 为了高效大规模训练 Command A+ 模型,我们利用 NVIDIA 的 CUDA-X 生态系统(CUTLASS、cuBLAS、TE 和 NCCL)进行高性能计算、内核优化和多 GPU 通信。
4 所有模型均在单个 NVIDIA HGX B200 节点(8 块 GPU)上测量,使用 vLLM 和张量并行(TP=8),针对 LiveCodeBench。提示词约 3K Token,最大输出长度为 8K。