为何MoE模型能从推测解码中获益更多
Why MoE models get more from speculative decoding
Cohere 在生产级 MoE 模型上验证了推测性解码(SD)的加速比非单调性:随 batch size(BS)先增后降,中等 BS 时存在最佳点。MoE 的低算术强度(k/N)使模型在更高 BS 下仍受带宽限制,专家路由的时间相关性使验证时独特专家数比独立性基线减少 20–31%。BS=1 时的高加速比源于固定开销平摊,Amdahl 分解显示路由专家权重加载仅占前向传播的 30–55%。研究为协同优化模型稀疏性与 SD 提供了设计启示。
背景
大语言模型一次生成一个 token。每个 token 都需要一次完整的前向传播,这使得生成过程本质上很慢。推测性解码(Speculative Decoding, SD)针对这一瓶颈:一个快速的小型“草稿”模型猜测接下来的 token,而完整的“目标”模型在单次前向传播中验证所有 $K + 1$ 个 token。当猜测正确时,你几乎只需花费一个 token 的成本就能获得多个 token。
混合专家(Mixture-of-Experts, MoE)模型引入了一个有趣的变数。每个 token 只激活模型参数的一小部分——称为“专家”——这使得单个 token 的计算成本很低。但在验证过程中,$K + 1$ 个 token 可能会路由到不同的专家,从而可能从内存中加载比单 token 解码多得多的权重。这种额外的加载是否会抵消推测性解码本应带来的加速?
MoESD 的最新工作预测答案是微妙的:MoE 的低算术强度会产生一条非单调的加速曲线,其中增益首先随 batch size 增加而 增加,然后才下降。
在这篇文章中,我们在自己的生产级 MoE 模型上验证了这一预测,并将分析扩展到两个方向。首先,我们研究了专家路由中的时间相关性——这是先前工作中记载的 MoE 模型的一个结构特性——并量化了它对 SD 验证成本的影响。其次,我们揭示了 BS=1 时异常高加速背后的一个独特机制,其中固定开销的平摊作用是无法仅通过路由分析来解释的。最后,我们还为协同优化模型稀疏性和推测性解码提出了具体的设计启示。
观察非单调的加速曲线
在 LLM 推理中,推理系统会将多个并发请求进行批处理,使它们的解码步骤在单次前向传播中一起执行——并行处理的请求数量称为 batch size(BS)。由于 LLM 解码在小 BS 时受内存带宽限制,在大 BS 时变为计算受限,因此 batch size 从根本上决定了推测性解码能带来多少收益。我们使用 vLLM,针对密集模型和 MoE 模型,在不同 batch size 下对 SD 加速比进行了基准测试。
密集基线(Command A,111B)。 加速比随 batch size 单调递减——在模型受带宽限制的低 BS 时增益最高。
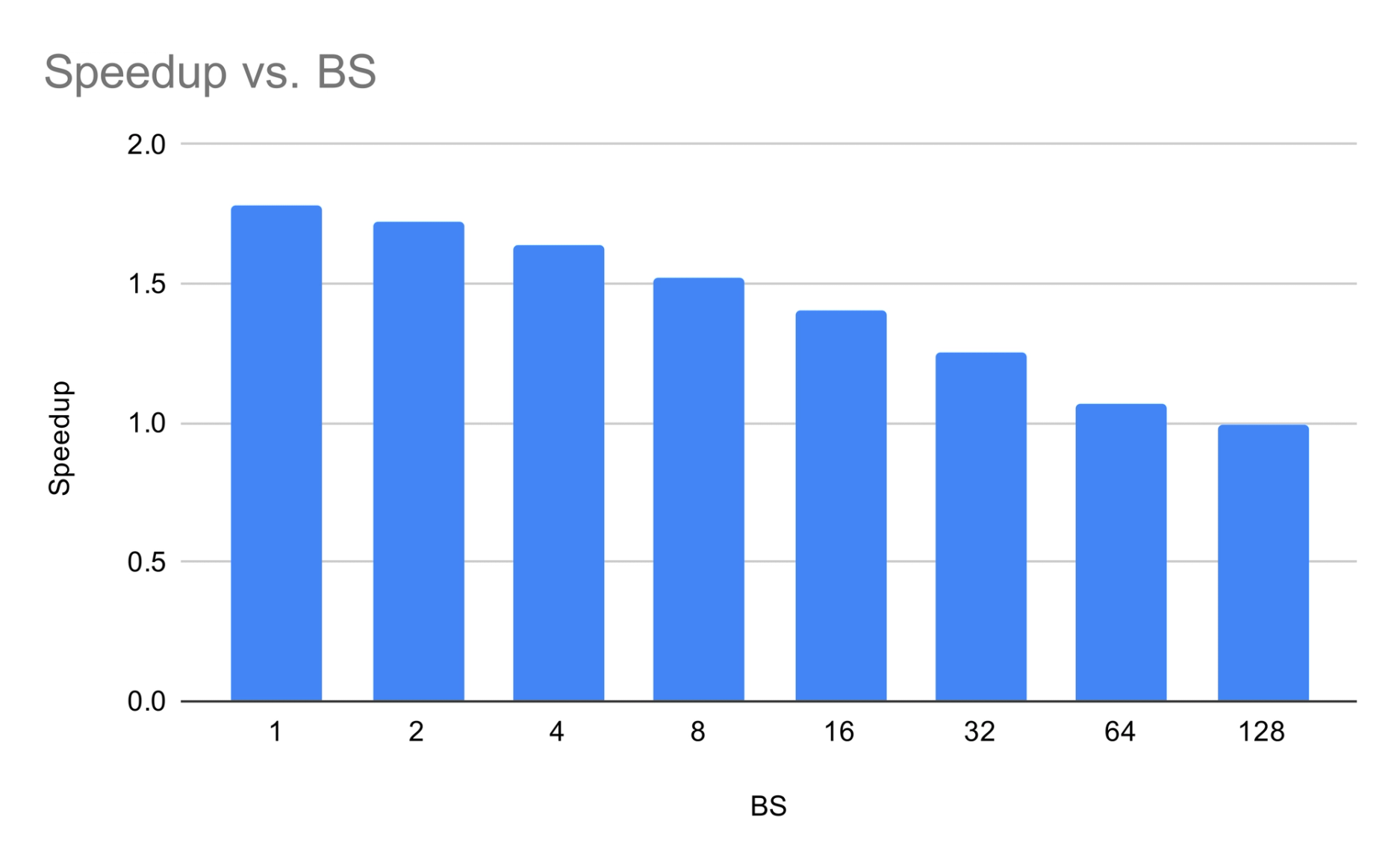
图 1:Command A 加速比
Cohere MoE + SD$K = 3$。 加速比先增加后下降——这是 MoESD 预测的非单调形状。BS=1 时的增益异常高;我们将在后续章节重新审视这一异常。
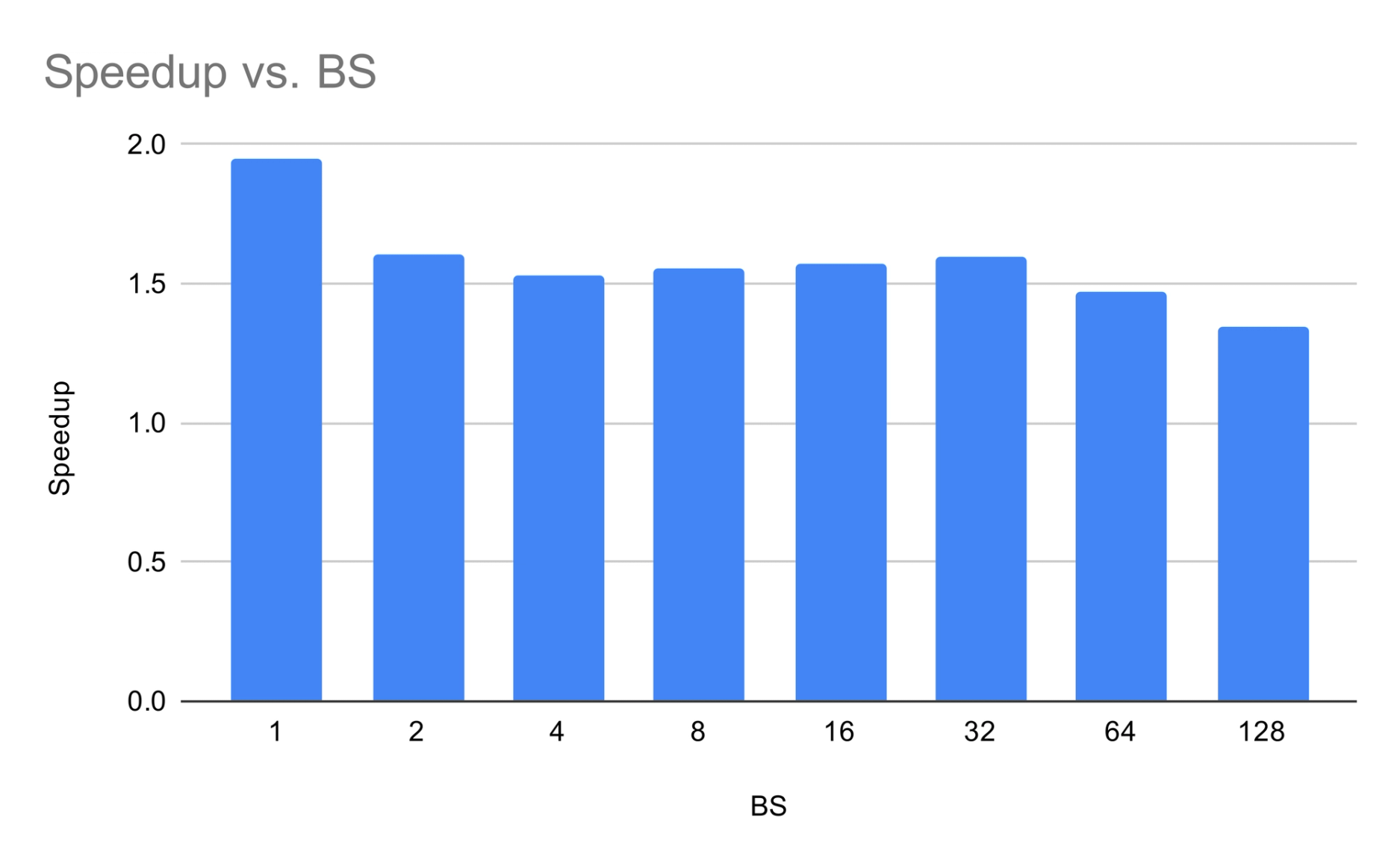
图 2:Cohere MoE 加速比
这种对比非常鲜明:密集模型的 SD 增益单调递减,而 MoE 模型在中等 batch size 时表现出一个最佳点。是什么创造了这个最佳点,为什么 BS=1 如此突出?
为什么 MoE 会创造最佳点:算术强度
非单调曲线的关键在于算术强度。对于一个总共有 N 个专家的 MoE 层,其中每个 token 选择其中的 $k$ 个(top-k 路由),处理 $T$ 个 token 并带有 $S$ 个共享专家,其算术强度为:
$$ A I = \frac{T \left(\right. k + S \left.\right)}{N + S} $$
当 $S = 0 : A I = T k / N$。稀疏性(较低的 $k / N$)使得 $A I$ 保持较低,从而在任何给定的 $T$ 下,将层更深地推入带宽受限区域。
正如 MoESD 所分析的,这为 SD 创造了三种 batch size 区间:
低 BS——部分专家加载。 模型受内存带宽限制,但解码尚未加载所有专家。验证在解码成本之上增加了额外的专家权重加载,限制了 SD 的增益。
中等 BS——最佳点。 解码和验证都几乎加载了所有专家——验证几乎没有增加额外的权重加载。由于 $A I$ 保持较低(得益于稀疏性),模型仍然受带宽限制,使得验证 token 几乎免费。SD 增益在此达到峰值。
高 BS——计算受限。 算术强度超过了机器的运算与字节比。每个额外的验证 token 都需要成比例的计算成本,SD 增益消失。
更稀疏的模型(更低的 $k / N$)在带宽受限状态下保持更久,将最佳点推向更高的 batch size。
与 SD 加速比的联系
根据 MagicDec 和 MoESD,SD 加速比主要由验证成本比率 $T_{t} \left(\right. K + 1 \left.\right) / T_{t} \left(\right. 1 \left.\right)$ 决定。草稿开销通常可以忽略不计。对于 $K = 3$,关键指标是:
$$ \frac{T_{t} \left(\right. 1 \left.\right)}{T_{t} \left(\right. 4 \left.\right)} \in \left(\right. 0 , 1 \left]\right. $$
当这个值接近 1(验证≈免费)时,加速比接近理论最大值 $A L$(接受长度)。接下来的部分通过专家重叠分析和 Amdahl 定律来测量和建模这个比率。
协同设计模型稀疏性与推测机制
三区间分析得出了一个具体的设计原则:对于给定的目标 batch size,稀疏比率 $k / N$ 决定了模型是处于带宽受限的最佳点,还是进入 SD 增益消失的计算受限区域。
更稀疏的模型(更低的 $k / N$)在更高的 batch size 下仍保持带宽受限,从而拓宽了最佳点。更密集的模型会更早地进入计算受限区域。这意味着稀疏性不仅仅是一个参数效率的调节旋钮——它直接决定了在给定的目标 BS 负载下,推测性解码能带来多少收益。
共享专家与路由专家的比率增加了第二个杠杆:共享专家在低 BS 时降低了验证成本(通过减少前向传播中用于路由专家权重加载的时间比例),但提高了有效的 $k / N$,从而将计算受限的转变点提前。在极端情况下,一个共享所有专家的模型等同于一个密集模型,完全没有最佳点。
对于在设计时已知目标 BS 的系统,这两个旋钮可以相应设置:
高目标 BS——通过以下方式最大化 SD 收益:
降低$k / N$:每个 token 激活更少的专家,使算术强度保持较低,即使在大 batch size 下模型也受带宽限制。
增加路由专家与共享专家的比率:更多的路由专家(更少的共享专家)使有效的 $k / N$ 保持较低,从而维持带宽受限状态。
低目标 BS——计算方式发生变化:共享专家是有益的,因为它们减少了前向传播中用于路由权重加载的时间比例,使验证成本更低。由于 batch size 较小,模型无论如何都保持带宽受限。
专家路由与验证成本
算术强度框架解释了加速曲线的 形状,但预测实际的验证成本需要理解专家如何在 token 之间共享。如果验证期间的连续 token 路由到相同的专家,则需要从内存中加载的独特权重就更少。
专家路由中的时间相关性——相邻 token 倾向于激活重叠的专家集合——已被记录为 MoE 模型的一个结构特性。在这里,我们在 SD 验证设置中研究这一现象,使用 vLLM 中修改版的 enable_return_routed_experts API 来捕获 MT-Bench 数据集上每个 token 的专家路由决策,从而量化其对验证成本的影响。
符号与基线
- $N$ 表示每个 MoE 层的专家数量
- $k$ 表示每个 token 选择的专家数量(top-k)
- $L$ 表示 MoE 层的数量
- $e x p e r t s \left(\right. t \left.\right)$ 表示为 token $t$ 选择的 $k$ 个专家索引的集合
- $p_{e}$ 表示 $\text{P}(\text{专家}\textrm{ } e \textrm{ }\text{被}\textrm{ }\text{随机}\textrm{ }\text{token}\textrm{ }\text{选中})$,从数据中估计
在一个 MoE 层中,一个学习到的路由器为每个 token 选择 $k$ 个专家(从 $N$ 个中)。只有被选中的专家的权重会从 HBM 加载到 SRAM 并应用。对于 SD 验证,关键问题是:对于所有 $K + 1$ 个 token,必须加载多少个 独特 专家?
由于每个 token 恰好选择 $k$ 个专家:
$$ \underset{e}{\sum} p_{e} = k . $$
我们在三种假设下比较路由统计:
- 均匀基线——所有专家等可能 $p_{e} = k / N$,token 独立。
$$ \text{期望}\textrm{ }\text{重叠}\textrm{ }\text{比率} = \frac{k}{N} $$
$$ \text{对于}\textrm{ }\text{B}\textrm{ }\text{个}\textrm{ }\text{token}\textrm{ }\text{的}\textrm{ }\text{期望}\textrm{ }\text{独特}\textrm{ }\text{专家数} = N \left[\right. 1 - \left(\left(\right. 1 - \frac{k}{N} \left.\right)\right)^{B} \left]\right. $$
2. 独立性基线——来自数据的经验 $p_{e}$,但 token 仍然是独立的。捕获了非均匀的流行度,但没有时间相关性。
$$ \text{期望}\textrm{ }\text{重叠}\textrm{ }\text{比率} = \frac{1}{k} \underset{e}{\sum} p_{e}^{2} $$
$$ \text{对于}\textrm{ }\text{B}\textrm{ }\text{个}\textrm{ }\text{token}\textrm{ }\text{的}\textrm{ }\text{期望}\textrm{ }\text{独特}\textrm{ }\text{专家数} = \underset{e}{\sum} \left[\right. 1 - \left(\right. 1 - p_{e} \left.\right)^{B} \left]\right. $$
3. 经验测量——直接从连续 token 中测量,保留了相邻 token 之间的时间相关性。
独立性基线与经验测量之间的差距隔离了时间相关性的影响——这种机制使得 SD 验证比基线预测的成本更低。
均匀
随机水平
无
独立性
专家流行度偏差
仅非均匀 p(sub e)
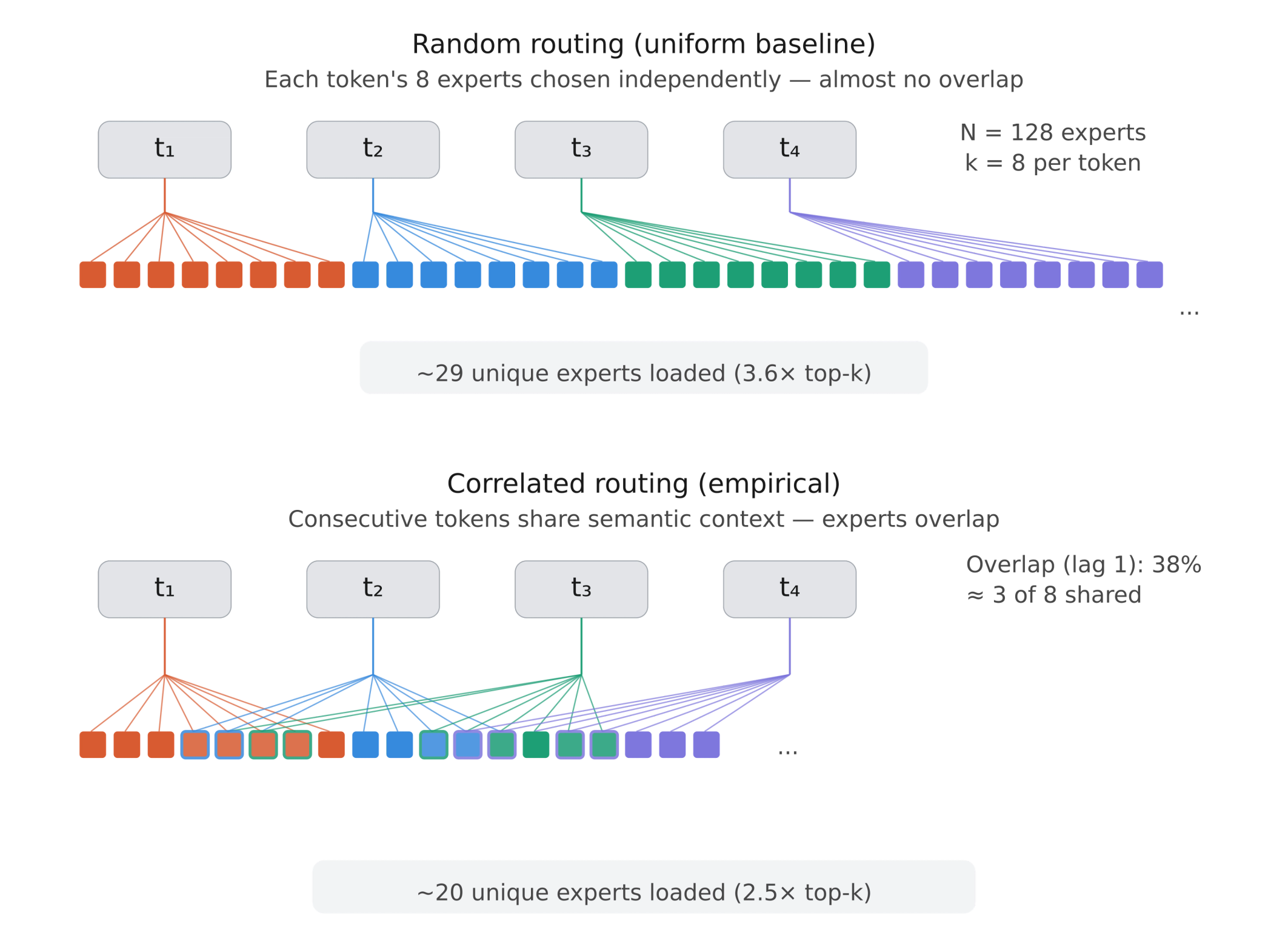
图 3:四个验证 token 的随机 vs. 相关专家路由
专家选择概率
我们的模型为每个 token 从 $N = 128$ 个专家中选择 $k = 8$ 个。各个层有明显的偏好——一个层中最受欢迎的专家可能达到均匀基线 $\left(\right. p_{\text{uniform}} = k / N = 0.0625 \left.\right)$ 的 $10 \times$。这种偏斜意味着专家激活随着 batch size 增加而 更快饱和,通过减少验证期间的独特专家数量来惠及 SD。
期望活跃专家数 vs. batch size
1
8.0
8.0
1.00
2
14.7
15.5
0.95
4
25.4
29.1
0.87
8
40.6
51.6
0.79
16
59.3
82.4
0.72
32
78.8
111.8
0.71
64
96.1
125.9
0.76
对于 $K = 3$ 的 SD,关键行是 BS=4:经验值 25.4 对比均匀值 29.1。实际路由集中了专家。经验值/均匀值的比率随着 BS 增加而下降然后恢复——这条曲线反映了 MoE 的 SD 增益曲线。
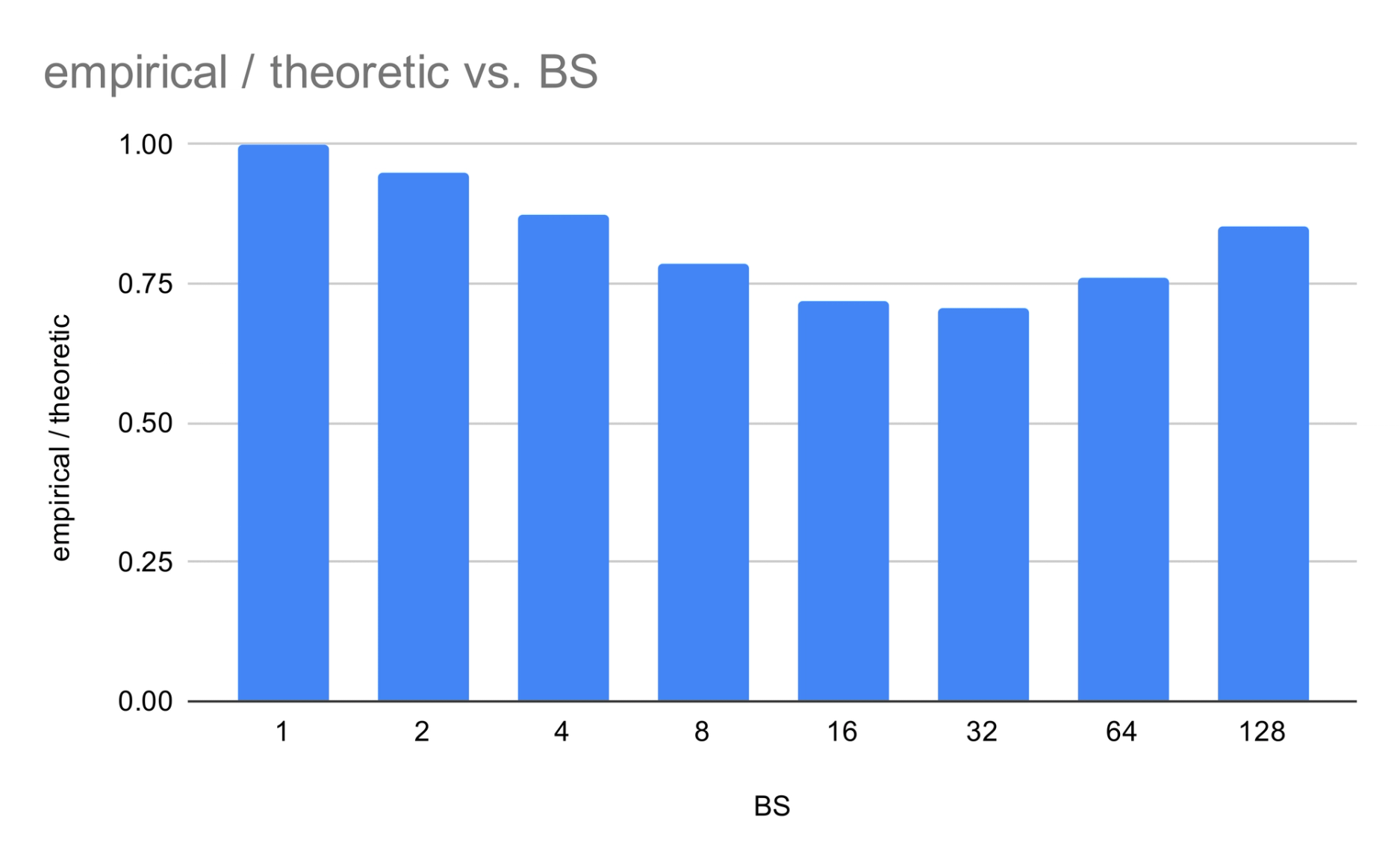
图 4:经验值 / 理论期望活跃专家数
相邻 token 之间的专家重叠
1
0.381
2
0.329
3
0.301
4
0.299
独立性基线
0.118
在步骤 1,38% 的重叠(8 个专家中共享 3.0 个)远高于独立性基线(11.8%)和均匀下限(6.3%)。相关性随距离衰减,但在步骤 4 时仍比独立性预测高 2–4 倍。这种时间相关性水平与本文中观察到的路由一致性模式一致,并对 SD 有直接影响:连续验证 token 之间共享的专家越多,必须加载的独特权重就越少。
逐层变化(步骤 1): 网络中间层显示出最强的重叠(~0.50),而早期层(~0.32)和最终层(~0.25)则较少。早期层尚未发展出强烈的语义路由;随着模型收敛到输出分布,最终层的相关性降低。
验证成本:$K = 3$ 时的独特专家数
经验值(相关)
20.36
独立性基线
25.4
时间相关性使独特专家数比独立性基线减少了 20–31%。验证四个 token 激活了约 2.5× top-k(而不是基线预测的 3.2–3.6×)。
跨数据领域的泛化
我们在 13 个 Spec-Bench 类别和来自 Aya Human Annotated 的七种语言上进行了验证。步骤 1 的专家重叠比率:
13 个 Spec-Bench 类别
0.377–0.385
0.381
专家重叠是 MoE 在自然文本上路由的一个结构特性,而不是输入分布的特性。对于任何现实的工作负载,次线性验证缩放都成立。
揭秘 BS=1 时的高加速比
我们的目标端测量揭示了一个谜题:在 BS=1 时 $T_{t} \left(\right. 1 \left.\right) / T_{t} \left(\right. 4 \left.\right) = 0.80$,但在 BS=2 时下降到 0.65。专家路由无法解释这个差距——专家集中在 BS=2 时实际上略微 更好。先前对 MoE 推测性解码的分析并未涉及此效应。
解释完全在 MoE 层之外。在非常低的 batch size 下,非专家操作(注意力、归一化、通信、内核启动)是开销主导的。在 BS=1 时,一次验证 4 个 token 异常好地平摊了这些固定开销。在 BS=2 时,我们验证 8 个 token,这种低 batch 的开销红利就减少了。
Amdahl 定律分解
为了量化这一点,我们将目标前向传播分解为两个部分:
- 路由专家权重加载(比例 $f$):与加载的独特专家数量成比例。
- 其他所有操作(比例 $1 - f$):在小 BS 时近似为固定成本。
这给出了验证成本比率:
$$ \frac{T_{t} \left(\right. K + 1 \left.\right)}{T_{t} \left(\right. 1 \left.\right)} = f \cdot \frac{\text{unique} \left(\right. K + 1 \left.\right)}{k} + \left(\right. 1 - f \left.\right) $$
对于我们的带有共享专家的模型 $\left(\right. f = 0.30 , u n i q u e \left(\right. 4 \left.\right) / k = 2.55 \left.\right) :$
$$ \frac{T_{t} \left(\right. 4 \left.\right)}{T_{t} \left(\right. 1 \left.\right)} \approx 0.30 \times 2.55 + 0.70 = 1.46 $$
T(4)/T(1)
1.46×
1.25×
隐含加速比 (AL/[T(4)/T(1)])
1.87×
2.18×
($A L = 2.73$;隐含加速比忽略草稿成本以隔离目标端效应。)
Amdahl 估计将验证比率高估了约 17%(1.46× vs 1.25×),但由此产生的加速比差距较小:1.87× vs 2.18×。这是因为路由专家比例 $f$ 仅为 0.30–0.55(有共享专家时更低),因此大部分前向传播是固定成本计算,不受验证缩放误差的影响。
为什么模型会高估?它忽略了两个效应:
- 任何非专家的 GPU 内核在 BS=1 时都受启动开销主导(2–10μs,其中 2–3μs 仅为启动),因此批处理 4 个 token 几乎免费地平摊了这些开销
- 带有四个 token 的专家 GEMM 获得了更好的计算-读取重叠,并平摊了每个专家的内核启动开销。
较低的 $f$ 有帮助——因此共享专家在低 BS 时降低了验证成本——但有一个权衡:它们提高了有效的 $k / N$,将模型更早地推向计算受限。在极端情况下,所有共享专家 = 一个没有带宽受限最佳点的密集模型。
将测量值代入 SD 公式确认了草稿模型的成本约为一个目标解码步骤的 15%(三个草稿 token,每个约 5%),这与我们 14.3% 的性能分析测量结果一致。
结论
MoE 的稀疏性,通常被视为批处理验证的一个复杂因素,实际上通过几种相互增强的方式帮助了推测性解码。
首先,MoE 的低算术强度($k / N$)使模型在比密集模型高得多的 batch size 下仍保持带宽受限,创造了一条非单调的加速曲线,在中等 BS 时有一个最佳点,此时验证几乎免费。
其次,专家路由中的时间相关性显著减少了验证期间加载的独特专家数量,从朴素的 $\left(\right. K + 1 \left.\right)$ x 最坏情况减少到 BS=1 时的仅 1.25–1.42×。这种局部性在 13 个任务类别和七种语言中成立,并且不是任何特定工作负载的人为产物。
第三,在非常低的 batch size 下,固定开销的平摊提供了超出专家路由分析预测的额外提升——我们通过 Amdahl 定律对目标前向传播的分解识别出了这一机制。
对于系统设计,其含义是可操作的:给定一个目标 batch size,可以协同优化稀疏性和共享专家与路由专家的比率,以保持在 SD 能带来最佳回报的带宽受限状态。
致谢
在 Cohere 方面,感谢 Acyr Locatelli 和 Bharat Venkitesh 在整个工作中提供的技术支持。
准备好构建你的下一个项目了吗?登录或在 Cohere Dashboard 上创建一个账户。如果你正在我们这家领先的企业 AI 初创公司寻找新的技术职位,请查看职位空缺。