如何针对你的语言、领域或口音微调 Nemotron 3.5 ASR
How to Fine-Tune Nemotron 3.5 ASR for Your Language, Domain, or Accent
NVIDIA 发布 Nemotron 3.5 ASR,一个 600M 参数的流式多语言语音转文本模型,基于 Cache-Aware FastConformer-RNNT 架构,可从单个 checkpoint 实时转录 40 种语言-区域变体,并内置标点和大小写。该模型在 Artificial Analysis 的独立 benchmark 中,于所有流式 ASR 模型里延迟排名第二(语音结束后 0.07 秒输出最终转录)。其前身 Nemotron 3 ASR(仅英文)已在 Hugging Face 和 NIM 上发布。模型以开放权重形式在 Hugging Face 发布,支持用户检查、微调和部署。微调实验显示,针对希腊语和保加利亚语在保留的 FLEURS 测试集上,使用 80ms 块流式模式,WER 分别从 35% 降至 24%(相对改进 32%)和从 22% 降至 15%(相对改进 31%)。
](https://huggingface.co/maryameee)




介绍 NVIDIA Nemotron 3.5 ASR,流式多语言模型:一个 600M 参数的语音转文本模型,能够从单个 checkpoint 实时转录 40 种语言-区域变体,并内置标点和大小写。它是今年早些时候在 Hugging Face 和 NIM 上发布的流行 Nemotron 3 ASR 模型(仅英文)的继任者。自发布以来,Nemotron 3 ASR 已在 Artificial Analysis 的独立 benchmark 中得到验证,在所有流式 ASR 模型中延迟排名第二——语音结束后仅需 0.07 秒即可得到最终转录文本——并在 AA-WER 流式索引与最终转录时间排行榜中位于“最具吸引力象限”,使其成为在准确率-延迟权衡上表现最佳的模型之一。该模型采用 Cache-Aware FastConformer-RNNT 架构,能够流式处理音频,无需进行导致大多数流式 ASR 变慢的冗余重计算——因此您可以同时获得低延迟和高准确率,而非顾此失彼。Nemotron 3.5 ASR 以开放权重形式在 Hugging Face 上发布——您可以检查、微调和部署它,无需依赖 API 或按次计费。除非您选择,否则不会有数据离开您的基础设施。而且由于它是一个强大的基础模型,您可以针对自己的语言、领域或口音进行微调。本文后半部分将详细介绍具体方法。
当今多语言语音识别的问题
如果您曾经构建过需要转录语音的产品,您可能遇到过以下障碍之一:
- 多语言税。 您想支持多种语言,于是拼凑了 40 个不同的模型——或 40 个不同的供应商 API——每个都有其独特的特性、延迟特征和计费方式。您的基础设施变成了一个一次性集成的博物馆。
- 流式与准确率的权衡。 实时字幕需要低延迟,但大多数“流式”ASR 系统通过反复重新处理重叠的音频窗口来假装实现流式。这会消耗计算资源并增加延迟。降低延迟,准确率就会急剧下降。
- 后处理流水线。 原始的 ASR 输出通常是一段没有标点、全小写的文本墙。您需要再添加一个模型来处理标点和大小写,这又增加了一个活动部件。
- “已知语言”假设。 许多系统要求您预先告知语言。但如果客服热线中,通话者在句子中间从英语切换到西班牙语,该怎么办?
Nemotron 3.5 ASR 的设计目标是将这四个问题全部整合到一个模型中。
它能做什么
一个模型,40 种语言-区域变体。 一个 600M 参数的 checkpoint 可以转录英语(美式/英式)、西班牙语(美式/西班牙式)、德语、法语(法国/加拿大)、意大利语、阿拉伯语、日语、韩语、葡萄牙语(巴西/葡萄牙)、俄语、印地语、土耳其语、越南语、荷兰语、乌克兰语、波兰语、芬兰语、普通话、捷克语、保加利亚语、斯洛伐克语、瑞典语、克罗地亚语、罗马尼亚语、爱沙尼亚语、丹麦语、匈牙利语、挪威博克马尔语、挪威尼诺斯克语、希伯来语、希腊语、立陶宛语、拉脱维亚语、马耳他语、斯洛文尼亚语和泰语。无需按语言部署,无需切换模型。
实时流式,正确实现。 该模型基于 Cache-Aware FastConformer 编码器构建。传统的“缓冲”流式在每个步骤重新处理重叠的音频块,多次重复相同的工作。而该模型则缓存编码器的内部状态并重复使用——每个音频帧只处理一次,没有重叠。结果是计算量和端到端延迟显著降低,且准确率不受影响。
原生标点和大小写。 输出是可直接用于生产的文本——正确的大小写、逗号、句号、问号——直接来自模型。无需单独的标点恢复步骤。
语言条件控制,由您选择。 您可以通过两种方式运行:
- 告知模型输入语言(
target_lang=en-US),当您知道语言时——通常能获得最佳准确率。 - 让模型检测语言(
target_lang=auto),当您不知道时——模型会检测语言并相应地进行转录。
工作原理(两分钟版本)
该模型有两个主要部分:
Cache-Aware FastConformer 编码器(24 层)。 FastConformer 是 Conformer 架构的高效演进,具有线性可扩展的 attention。其中的“cache-aware”部分是流式的魔法所在:编码器会缓存来自先前帧的 self-attention 和卷积激活,因此当新音频到达时,它只计算真正新的部分。没有任何内容被重新计算。
RNNT(循环神经网络转录器)解码器。 RNNT 是流式 ASR 的主力解码器——它随着音频流逐帧输入而逐帧输出文本,这正是实时转录所需要的。
在此基础上,该模型增加了基于 prompt 的语言 ID 条件控制:语言信号与音频一起输入,使得一组权重能够将其输出专门针对目标语言——或者在 auto 模式下,自行推断语言。
该模型在涵盖所有支持语言的大规模语音数据上进行了训练,使用了公共和专有数据的混合,并归一化为带标点、大小写正确的文本。
一个值得了解的参数:att_context_size
流式 ASR 本质上是在 输出文本的速度 和 模型在确定输出前能“窥视”多少未来音频 之间进行权衡。Nemotron ASR 通过 attention context size 直接暴露了这一权衡:
| Attention Context | 块大小(延迟) | 用例 |
|---|---|---|
[56, 0] |
80ms(超低) | 超低延迟语音代理 |
[56, 1] |
160ms(低) | 交互式语音代理,对话式 AI |
[56, 3] |
320ms(平衡) | 对话式 AI,实时字幕 |
[56, 6] |
560ms(中等) | 高准确率,合理延迟 |
[56, 13] |
1.12s(高) | 最高准确率,高延迟 |
同一个 checkpoint 覆盖了整个范围——您在推理时选择操作点,无需重新训练。
几分钟内即可试用
该模型以 NeMo checkpoint 形式发布。克隆 NeMo 分支并将流式推理脚本指向您的音频:
git clone https://github.com/NVIDIA-NeMo/NeMo.git
使用已知语言进行转录:
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=es-ES \
att_context_size="[56,3]" \
strip_lang_tags=true
或者让模型检测语言:
python ${NEMO_ROOT}/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=${MODEL_PATH} \
dataset_manifest=${MANIFEST_PATH} \
output_path=${OUTPUT_FOLDER} \
target_lang=auto \
att_context_size="[56,3]" \
strip_lang_tags=true
音频应为单声道 .wav 文件。manifest 是一个标准的 NeMo JSON-lines 文件:
{"audio_filepath": "/path/to/clip.wav", "duration": 4.27, "text": "reference transcript"}
模型会自动在每个完成的句子末尾预测语言标签,例如“This is a test sample. ”。strip_lang_tags=True 会移除语言标签 以提高可读性。
深入探讨:为您的语言微调 Nemotron ASR
Nemotron 3.5 ASR 开箱即用表现强劲——但它在训练时使用的数据混合中,某些语言的数据量远多于其他语言。长尾区域变体仍有提升空间,而几小时的领域内音频加上正确的配方,就能显著缩小差距。
为了具体说明,我们进行了一个实际示例:以基础模型为起点,针对两种中等资源欧洲语言——希腊语和保加利亚语——进行优化,然后在保留数据上诚实地进行测量。以下结果来自该次运行。本节是高级概述,编码示例位于配套的 GitHub 仓库中。当我们发布涵盖整个流程的 agentic SKILL.md 时,本博客将相应更新。
为什么要微调?
以下几种情况值得微调:
- 优化长尾区域变体。 预训练数据较少的语言获益最大。
- 领域专长或专业词汇。 基础模型很少遇到的医学、法律、金融或技术词汇。
- 口音、方言和声学环境。 电话、远场、车载或特定说话人群。
- 新语言。 引导尚未覆盖的区域变体。
微调能力预览
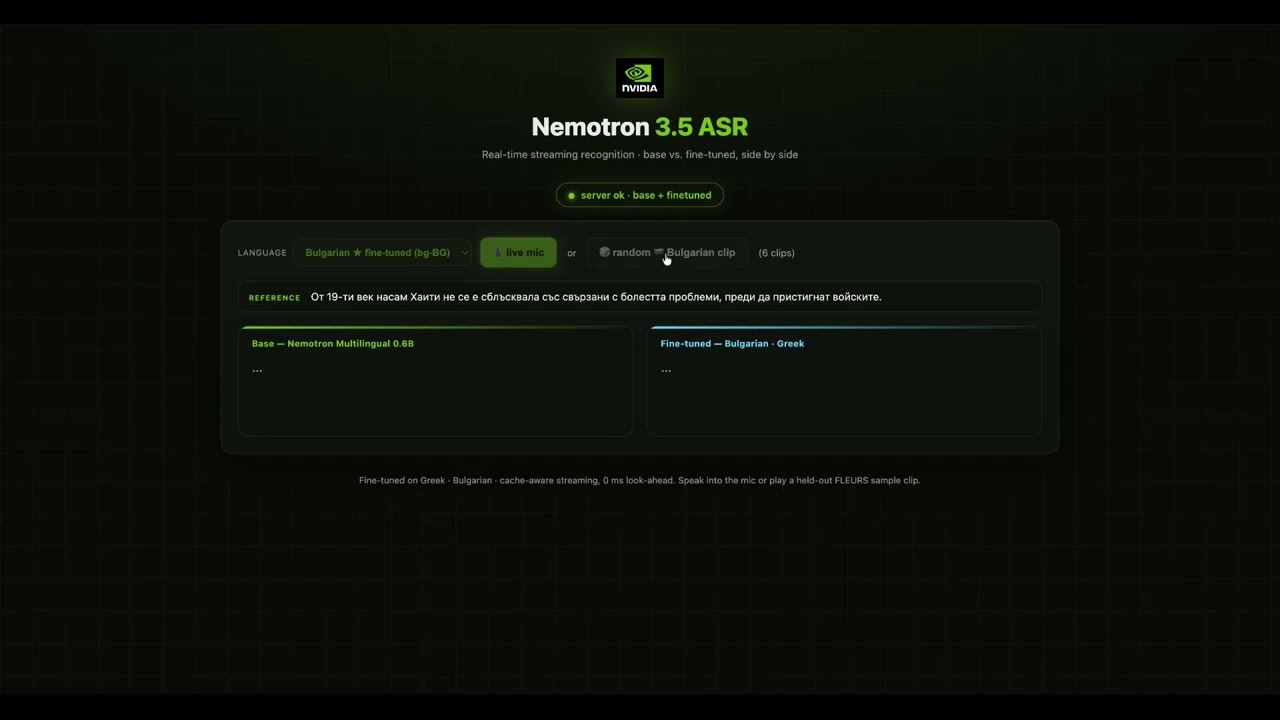
🎥 视频演示:在 YouTube 上观看
此演示展示了多语言流式推理、延迟/准确率权衡、部署选项以及下文描述的微调工作流程。
配方概览
整个工作流程分为五步:
- 将训练器指向目标语言的 tarred 语音数据——无需逐个文件解包,由 NeMo/Lhotse 高效流式处理。
- 从基础 checkpoint(
init_from_nemo_model)开始微调,使用相同的 Cache-Aware FastConformer-RNNT 配方,并根据每个片段的语言标签进行条件控制。 - 在模型从未见过的保留集上进行评估——使用您将部署的相同低延迟流式设置(例如
att_context_size=[56,0],80ms 块;0ms lookahead)。 - 在语言表现薄弱的地方添加更多数据并重新训练。
- 导出并部署微调后的 checkpoint。
第一步——数据
我们从公共多语言语料库(Granary、Common Voice、FLEURS)中为两种语言(希腊语和保加利亚语)整理了一个平衡的、约 2000 小时的混合数据集,并保存为 tarred NeMo/Lhotse shard。最重要的两个细节是:
- 每个片段都带有
target_lang标签——这是驱动模型基于 prompt 的语言条件控制的关键,因此正确设置标签(并使用模型识别的值)至关重要。 - 匹配基础模型的文本风格——带标点、大小写正确的转录文本,因为这是模型输出的格式。
保留的 FLEURS 测试集(未包含在训练中)为我们提供了每种语言诚实的、真实场景下的 benchmark。
第二步——训练
对流式 RNNT 模型进行直接的全参数微调,由固定的步数预算驱动(这是使用流式/可迭代数据进行调度的正确方式)。它在单个 GPU 上运行以进行快速验证,并可干净地扩展到多 GPU 以进行更完整的运行。对于像这样的小数据集,一个 epoch 只需几分钟,而非几小时。
第三步——评估
我们在保留的 FLEURS 测试集上测量了词错误率(WER),使用 80ms 块的流式模式——这是最苛刻的条件,没有未来音频的“窥视”。与基础模型相比,改进显著,尤其是对于最初表现最弱的语言:
| 语言 | 基础模型 | 微调后 | WER 相对改进 |
|---|---|---|---|
| 🇬🇷 希腊语 | 35 | 24 | 32% |
| 🇧🇬 保加利亚语 | 22 | 15 | 31% |
在保留的 FLEURS 测试集上,最低延迟流式模式下的原始 WER(%)。基础模型和微调模型使用相同的评估方式。
基础模型中错误率较高的语言在短时间微调后变得真正可用——保加利亚语的错误率降低了一半以上。
第四步——在需要的地方扩展数据
为了测试更多数据能带来多大提升,我们随后混入了约 2000 小时的议会语音数据(MOSEL/VoxPopuli),这些数据是 Granary 数据集的一部分,将训练池从约 290 小时扩展到约 2300 小时。即使在这次更长运行的中途,最弱的语言也得到了进一步改善(例如保加利亚语降至 20 多的高位),这证实了一个明显的杠杆:更多目标语言数据持续有帮助——尽管不同语言和领域的收益不均衡,因此需要测量而非假设。
第五步——部署
微调后的模型与基础模型架构相同,因此可以直接放入相同的服务路径,您可以在推理时通过 att_context_size 选择延迟/准确率操作点,与第一部分完全相同。
我们的经验
- 微调对资源不足的语言具有变革性——最大的收益来自基础模型最薄弱的地方。
- 在部署延迟条件下,对保留数据进行评估。 训练集分数会美化结果;在 0 ms lookahead 下的独立测试集才能揭示真相。
- 正确设置语言标签。 Prompt 条件控制功能强大,但对不匹配的语言标签毫不宽容。
- 保护其他语言。 在多语言模型中进行专门化时,混入模型其他语言的一部分(“重放”)并重新检查它们,这样您就能优化目标区域变体,而不会侵蚀其余部分。
- 更多数据有帮助,但不均衡。 增加小时数可靠地改善了大多数语言;有一种语言停滞不前——这提醒我们,领域匹配与原始数量同样重要。
📦 完整的演示——数据准备脚本、训练配置、具体命令以及完整的 benchmark 数字——位于配套的 GitHub 仓库中。本节是概述;仓库是构建指南。
对于生产环境服务,请关注本月晚些时候发布的 NIM,它将提供 gRPC 流式支持,并支持 NVIDIA Ampere、Hopper、Blackwell、Lovelace、Turing、Volta 和 Jetson。
您可以用它构建什么
该模型解锁的一些用例:
- 亚秒级语音代理——ASR → LLM → TTS 循环,其中语音转文本环节不再是瓶颈。
- 实时多语言会议字幕——一个流,参与者使用不同语言,实时字幕。
- 全球规模的呼叫中心分析——一个 ASR 后端,取代按语言划分的供应商混乱局面。
- 直播和活动的实时字幕 + 翻译。
- Jetson 上的设备端转录,适用于隐私敏感或无网络环境。
开始使用
准备好使用单个流式 ASR 模型构建多语言语音应用了吗?
🤗 试用 Nemotron 3.5 ASR:nvidia/nemotron-3.5-asr-streaming-0.6b
🧠 使用 NVIDIA NeMo 运行和微调:github.com/NVIDIA-NeMo/NeMo
📚 探索训练示例:微调 Notebook
无论您是在构建语音代理、多语言字幕系统、联络中心分析还是设备端语音应用,Nemotron 3.5 ASR 都提供了一个单一的多语言模型,可以针对您的用例进行部署、定制和微调。
我们期待看到您的构建成果。请在模型讨论页面分享您的 benchmark、微调结果和语言适配:
💬 模型讨论:https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b/discussions
模型:https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b
许可证:OpenMDW-1.1
运行时:NeMo 26.06+