在应用计算中扩展强化学习
Scaling Reinforcement Learning at Applied Compute
Applied Compute 为 DoorDash、Cognition、Mercor 等企业训练定制 AI agent,核心机制为强化学习(RL),通过奖励函数、评估体系和持续学习循环构建“特定智能”。创始团队来自 OpenAI Codex 和 o1 项目,认为后训练(post-training)是竞争关键。公司使用 Modal 平台实现 RL 训练循环中的展开、评估和推理阶段,利用其 Sandboxes 提供快速启动、网络隔离的临时容器,以及 serverless 扇出和低延迟冷启动,保持 GPU 满载并支持高并发评分。
客户案例
2026年5月20日·6分钟阅读
Applied Compute 为 DoorDash、Cognition 和 Mercor 等企业训练定制 AI agent。创始团队来自 OpenAI 的 Codex 和 o1 项目,他们创立公司时围绕一个特定论点:随着前沿模型商品化,竞争层面向后训练(post-training)转移。那些拥有自己的奖励函数(reward function)、评估体系(eval)和持续学习循环(continual learning loop)的公司,将超越那些没有这些能力的公司。
他们称之为"特定智能"(Specific Intelligence),而 Modal 正在助力实现这一使命。
通过专门微调构建特定智能
Applied Compute 构建具备特定智能的 agent:为单一公司打造的 AI,基于其专有数据训练,每次使用都会持续改进。
AC 训练特定智能 agent 的核心机制是强化学习(Reinforcement Learning, RL)。RL 让模型在可回放环境中多次尝试任务,根据奖励函数对每次尝试进行评分,并朝着奖励函数偏好的行为方向更新权重。
对于 DoorDash,这意味着训练一个最先进的商家入驻模型:摄入拍摄的餐厅菜单照片,生成 DoorDash 在生产环境中使用的结构化店铺展示。对于 Cognition,则是一个定制的 bug 捕获 agent,能在开发者保存提交后的几秒内发现潜在问题。
"前沿模型设定下限,专门化模型和定制后训练提升上限。"
—— Yash Patil,Applied Compute 首席执行官
选择合适的基础设施
典型的 RL 训练循环包含三个需要持续协同工作的组件:
- 展开(Rollouts):Agent 在可回放环境中尝试任务
- 评估(Evals):根据奖励函数对每次尝试进行评分
- 推理(Inference):在生产环境中服务训练好的模型,同时捕获新的轨迹数据
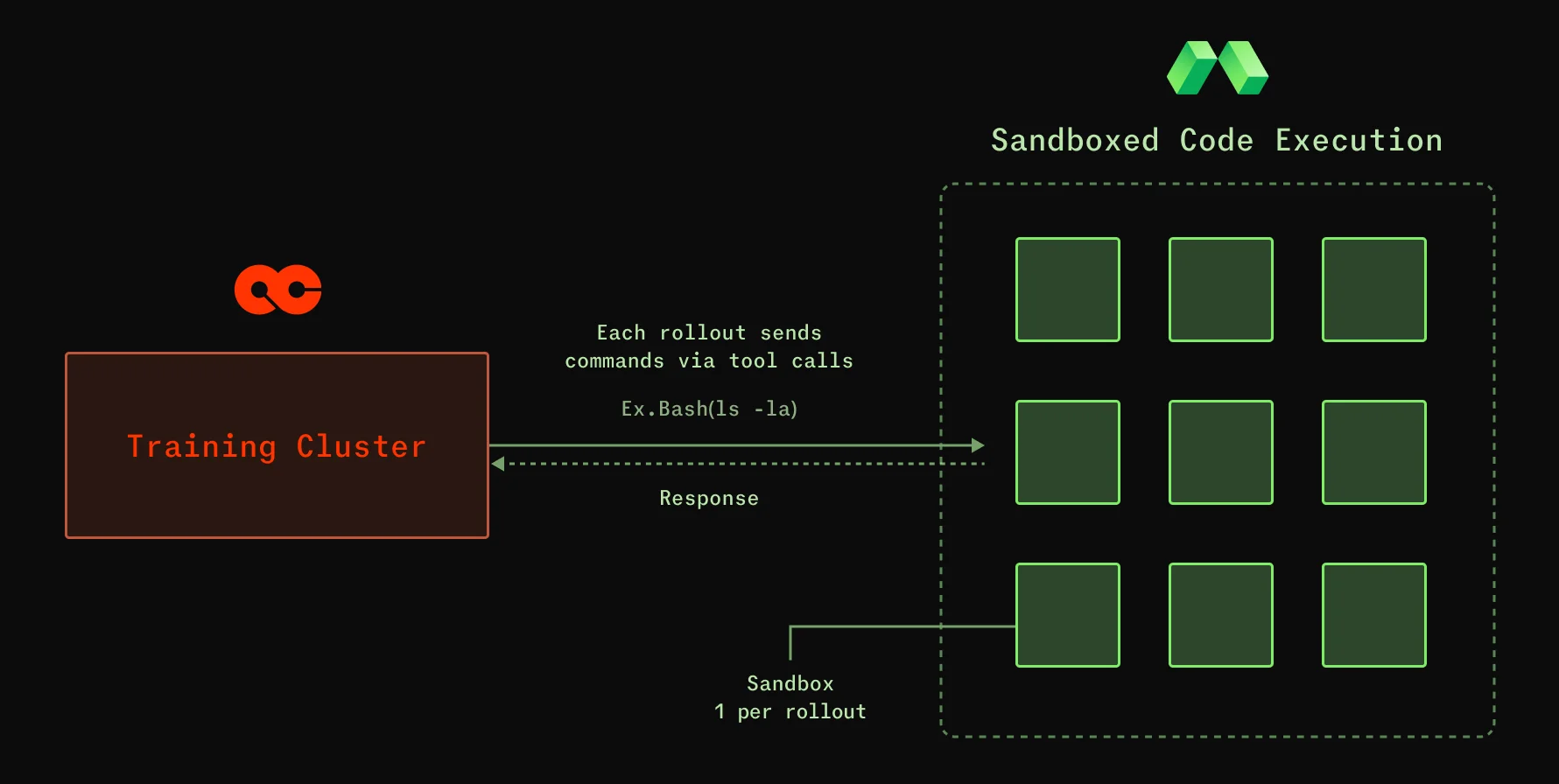
每个组件都有不同的基础设施特征。展开阶段是突发性的且 CPU 密集。评分阶段需要大规模并行。推理阶段需要优化 GPU 访问。Modal 提供了恰当的基元(primitive),使每个阶段能以所需方式运行、共享状态并保持循环紧凑。
在选定平台之前,Applied Compute 评估了市场上几乎所有的沙箱和执行提供商。
Modal 是唯一能在循环的每一层提供合适基元,同时保持各层之间低成本边界的选项。
"Modal 显然非常灵活,其结构让我们能够构建这些复杂环境,并且真正专注于性能和可靠性。"
—— Yash Patil,Applied Compute 首席执行官
复杂环境的灵活性与保真度
RL 训练让模型并行尝试任务数千次,每次尝试都在自己独立的临时环境中进行。这些环境很重,经常需要模拟整个生产系统——Salesforce、Slack、内部 API——其保真度足以让 agent 无法区分它们与生产环境中将要遇到的真实服务。"训练 agent 的环境应该就是它们实际执行任务的环境,"Patil 说。训练-测试不匹配是已部署 RL 系统中最常见的失败模式之一。
Modal Sandboxes 为团队提供了具有快速启动、完整文件系统和网络隔离以及快照语义(用于可回放性)的临时容器。它们为 Applied Compute 提供了一个基础,可以在其上构建任意复杂的生产系统模拟,同时保持训练循环所依赖的确定性,从而将工程精力投入到环境保真度上,而不是绕开平台限制。
性能延迟:保持 GPU 满载
展开阶段需要同时运行推理和沙箱。当训练过程中并行启动数千个沙箱时——通常持续工作一到三个小时——P50 和 P90 启动延迟会直接转化为推理端的 GPU 利用率。GPU 时间是循环中的主要成本,沙箱初始化的每一毫秒都意味着加速器空闲的一毫秒。
"让 CPU 部分尽可能快,效果就越好,"Patil 说。Modal 预构建、积极缓存的容器镜像和亚秒级冷启动使训练循环保持 GPU 受限而非 CPU 受限,这是任何严肃 RL 工作负载所需的运行状态。
负载下的可靠性
每次展开都必须通过单元测试、专家编写的评分标准或 LLM-as-judge 运行来评分,同样的评分层也在生产环境中运行,对数千条并发轨迹上的实时 agent 行为进行评分。这项工作需要大规模并行的 CPU 计算。Applied Compute 利用 Modal Functions 提供廉价的 serverless 扇出,无需专用集群。
在如此高的并发度下,个别失败是不可避免的;关键属性是平台恢复的速度。Modal 的自动重试、每次调用的隔离以及托管调度,确保了评分层和展开层的持续运行。
特定智能的未来
"每家公司都将开始构建自己的智能堆栈,就像他们构建自己的软件堆栈一样。"
Patil 认为前沿模型不会消失,但我们将越来越多地看到公司拥有后训练、持续学习循环、评估体系以及专有数据管道,使他们的 AI 真正属于自己。Applied Compute 正在组建团队和平台,使这一愿景变得可行——一次服务一个客户,将研究人员嵌入每个客户,将其机构判断编码为奖励函数,并持续运行循环,直到生成的模型表现得像组织的一员,而不仅仅是另一个工具。
Modal 是云基础设施,为 AC 提供快速实现这一愿景所需的基础。速度足够快,能让数千次并行展开保持 GPU 受限。灵活性足够高,能承载任意复杂的生产系统模拟。弹性足够强,能在长时间并发运行中保持评分层存活。所有这些都在整个 RL 循环的统一环境中实现。