自动扩缩 Autoresearch:在 Modal 上为你的 agents 提供弹性 GPU
Autoscaling Autoresearch: Give your agents elastic GPUs on Modal
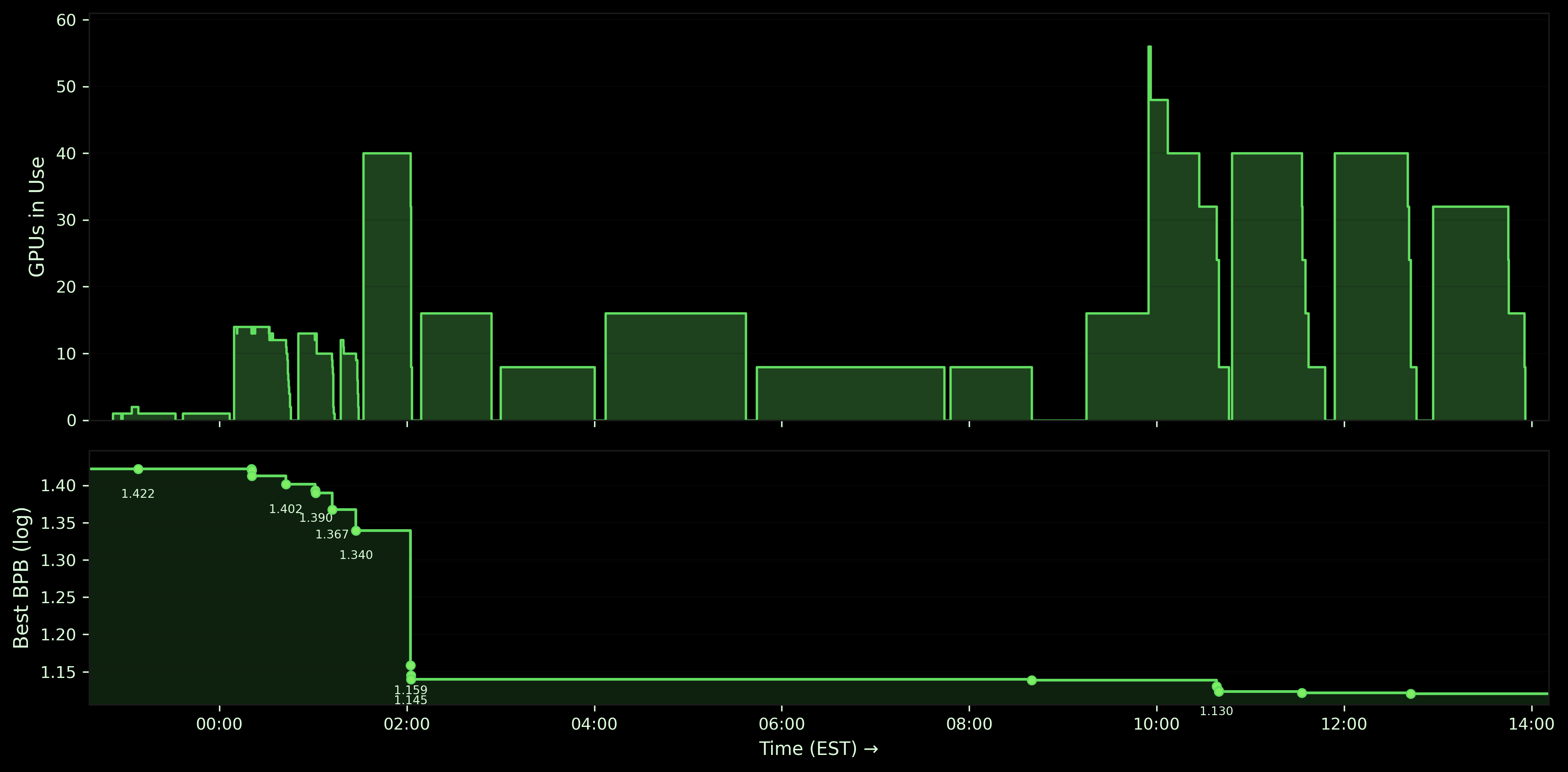
Modal 展示用 autoresearch Skills 让 Claude Code 处理 OpenAI Parameter Golf:15 小时内完成 113 个实验、238 GPU-hours,通过 Sandbox、modal run、Volumes 在 single-GPU 与 8×H100 间 autoscaling,核心训练较 8×H100 workstation 快 5x,最终 BPB 约 1.1206。
工程
2026 年 4 月 14 日•8 分钟阅读
在 Karpathy-san 发布 autoresearch 之后,许多人开始接受用 AI 加速 AI research。
但 autoresearch 带来了一个熟悉问题的新版本:如何给 research 提供所需的 compute,而不把钱浪费在不需要的 compute 上?
Modal 解决了这个问题。为了演示,Tony 把一些相关的 Modal Skills 交给 Claude Code,让它处理 OpenAI 的 Parameter Golf challenge,然后就去睡觉了。
15 小时后他醒来时,它已经跑了 113 个实验,总计 238 GPU-hours;核心训练运行的完成速度比单台 workstation 快 5x,同时只使用 dedicated cluster 的一小部分资源。
Autoresearch 💚Autoscaling
Research 是不可预测的,research workloads 也是如此。研究人员,或其 agent,可能需要几十甚至上百块 GPU 并行跑 hyperparameter sweep,然后降到一块 GPU 来 debug 问题,再扩展回几个 8-GPU cluster 做 validation——这一切都发生在同一个工作会话里。
一个大型的 always-on reservation 能给你这种 burst capacity,但代价很高:即使 agent 正在“Thinking…”,没有使用 cluster,你也在为它付费。而且大多数 cluster 都很难用。单个 instance 或 workstation 便宜且易用,但它会迫使实验串行运行,拖垮迭代速度。
你真正想要的是两全其美:单机的易用性和成本控制,加上大型 cluster 的 burst capacity。
而且问题不只是需要_多少_ compute,还有需要_哪种_ compute。Debug CUDA error 需要一个 interactive sandbox,让 agent 可以检查状态并快速迭代。12 小时的 training run 需要带 retries 和 checkpointing 的 fault-tolerant batch job。Hyperparameter sweep 需要几十个独立 job 并行运行。
传统 cloud infrastructure 会迫使你和你的 agent 选择一种模式并坚持下去。你真正想要的是让 agent 自己在每个时刻决定使用多少 compute、哪种 compute,并让 infrastructure 跟上。
这正是 Modal 提供的能力:为 human researchers 和 agents 所需的 development experience,并由我们的 custom serverless runtime 让它变得顺滑且具备成本效率。
Agent 可以写一个 training script,用 @app.function(gpu='H100:8') 装饰它,然后用 modal run 启动。如果有 bug,它可以调用 modal.Sandbox.create(gpu='H100:8') 来启动一个 interactive Sandbox。无论哪种方式,GPU 都会在数秒内启动,从一块 GPU 扩展到几十或上百块 GPU 只是改一个参数。工作完成后,它们会自动释放——不会因为 idle cluster 通宵运行而醒来看到意外账单。
Agents 和人类一样,已经发现 Modal 的 CLI-maxxing、code-mode interface 很容易使用。但也和人类一样,它们会需要一些 docs and guidance。所以我们写了一套 Skills,指导 agent 如何使用 Modal 的 compute primitives,包括启动 interactive Sandboxes、用 modal run 编写并运行 training jobs、用 Volumes 管理 persistent storage,以及编排并行 sub-agents。Agent 不必从零学习 Modal 的 API,而是直接获得所需的模式,用来 provision GPU、运行实验并自行清理。
Parameter golf
OpenAI 的 Parameter Golf challenge 要求你把一个 language model 压缩成 ≤16 MB 的 artifact,并在 8×H100 上于 10 分钟内运行,同时最小化 bits-per-byte(每字节比特数)。由于 Modal 允许 agent 通过一个简单的 API call provision 和 release GPU,它可以自行扩展——探索时启动几十个便宜的 single-GPU runs,validation 时运行 5 个并行的 8×H100 实验,debug 时降为串行执行,完成后缩到零。下面我们会详细梳理时间线,以及它使用 Modal 带来的具体加速和效率收益。
Stage 1: 从小规模开始验证 pipeline
Agent 的起步方式和任何优秀的 research engineer 一样——先做 smoke test。它通过 Modal 的 API(modal.Sandbox.create())启动一个 single-GPU sandbox,训练了一个很小的 8M-parameter model 一个 epoch,将其 quantized,然后运行 evaluation。在大约一小时内做了四个快速实验,以确认整个 pipeline 可以 end-to-end 工作。Baseline BPB:1.42。
我们通过与 8xH100 workstation(足以单独运行每个实验)相比的 speedup gains,以及与 40-GPU cluster(足以承载持续的并发负载)相比的 efficiency savings 来总结结果。Speedups 来自并发运行超过 workstation 最大 GPU 数的任务;efficiency gains 来自使用少于 cluster 总 GPU 数的资源。
| 相比 Workstation 的 Speedup | 相比 Cluster 的 Efficiency | BPB |
|---|---|---|
| 1x | 40x | 1.42 |
这个 validation 步骤没有获得 speedup,因为它从未使用超过 8 块 GPU——大多数时候只用一两块。但这也意味着,相比让 cluster 约 98% idle,成本节省很大!
Stage 2: 横向扩展做广泛探索
Pipeline 跑通后,agent 需要探索 search space:model sizes、learning rates、sequence lengths、training durations。它并行启动了 约40 个独立的 single-GPU sandboxes——每个都是不同的 hyperparameter combination,每个都通过一次 modal.Sandbox.create(gpu='H100') call provision。没有 job queue,没有 resource allocation config,只是每个实验一个 function call。整个 broad sweep 在 36 分钟的 wall time 内完成。
之后它收窄范围:又做了 23 个 single-GPU 实验,聚焦最有前景的 model sizes 和 learning rates,然后做了 4 个更激进的 run,进一步推进最佳配置。BPB 在三个子阶段中稳步下降:1.40,然后 1.37,再到 1.34。探索阶段共计约 14 GPU-hours,覆盖 68 个实验,全部在 single GPU 上完成。
| 相比 Workstation 的 Speedup | 相比 Cluster 的 Efficiency | ∆BPB |
|---|---|---|
| 1.25x | 4x | 0.08 |
这里相对 workstation 的总体 speedup 不算大,但 peak speedup 实际上相当可观:约 40 个 run 在约 40 分钟完成,而不是三个小时。这就是午饭后或去 Mission Cliffs 一趟回来就能拿到结果,与要等到晚上再回来查看的区别。并且 efficiency savings 仍然很可观。
Stage 3: 扩展到更大规模做 validation
到半夜时,agent 已经清楚哪些 architectures 表现最好。它需要 full scale validation。
于是它把每个实验从 single-GPU 扩展到 8×H100。Infrastructure 变化只是一个参数:gpu='H100' 变成 gpu='H100:8'。没有新的 cluster config,没有 deployment manifest——Modal 处理 multi-GPU provisioning 的方式和处理 single-GPU 一样。Agent 以 full scale 运行了前五个配置——5 × 8×H100,40 块 GPU 同时运行——BPB 从 1.34 降到 1.14。
| 相比 Workstation 的 Speedup | 相比 Cluster 的 Efficiency | ∆BPB |
|---|---|---|
| 5x | 1x | 0.2 |
这里我们看到了 Modal deployment 相比 workstation 的 speedup 收益:核心实验在四小时内完成,而不是二十小时。这就是同一个工作日内能看到结果,和需要等整个周末的区别。
Efficiency gains 现在很小。但这是对 cluster 不现实的最佳情况假设!我们假定它正好为这次运行做了完美 provision。但就像 golf 一样,research 不是追求完美的游戏。因此在实践中,研究人员要么 underprovision 而失去 speedup,要么 overprovision 而失去 efficiency。Modal 会让 GPU allocation 始终保持精确匹配。
Stage 4: 缩回小规模进行 debug
然后 agent 卡住了。Model 训练正常,但 quantization 步骤——用 GPTQ compression 以满足 16 MB budget——在 CPU 上运行,耗时超过 45 分钟。10 分钟的 evaluation window 意味着 submission 甚至无法完成。瓶颈在 post-training pipeline。
接下来是一段很长的 debugging。Agent 先尝试了最明显的修复:提高 timeouts。45 分钟,然后 60 分钟、90 分钟,再到两小时。在这个阶段,它回退到一次只运行一到两个实验,因为在诊断一个顺序 bottleneck 时,并行化没有意义。五个半小时,超过 60 GPU-hours,每个 run 都 timed out。
然后它彻底改变了方法。它把 quantization 步骤改写为在 GPU 上运行。下一个实验总计 52 分钟完成,包括 training 和 quantization。
| 相比 Workstation 的 Speedup | 相比 Cluster 的 Efficiency | ∆BPB |
|---|---|---|
| 1.25x | 4x | 0 |
同样,debugging 的 speedup 不大——不过这里有几种策略可以并行推进。但 efficiency savings 很可观。
Stage 5: 再次扩展完成优化
完整 pipeline 跑通后,agent 进入优化阶段。它先做了一轮 validation——2 个并行的 8×H100 实验,以确认修复没有让质量退化(BPB:1.1420)。然后它扩展到 5 个并行的 8×H100 实验——一次 40 块 GPU,每个实验测试不同的 architectures、learning rate schedules、regularization 和 data mixing strategies。Modal 的 elastic provisioning 意味着它可以从一个 debugging sandbox 扩展到 40 块同时运行的 GPU,再缩回来,全部通过简单的 sandbox creation call 完成。
BPB 在三轮优化中缓慢下降:1.1230,然后 1.1217,再到 1.1206。最后一轮 4 × 8×H100 返回 1.1220——略差。Agent 识别出收益递减。它 scale to zero 并停止。
| 相比 Workstation 的 Speedup | 相比 Cluster 的 Efficiency | ∆BPB |
|---|---|---|
| 3.8x | 1.3x | 0.02 |
在这个阶段,我们同时看到了两种收益:在并行尝试策略时,可以达到峰值实验吞吐量,相比 workstation 获得很大 speedup;同时又可以随着实验需求随时间变化调整吞吐量,相比 cluster 获得显著的 efficiency 收益。
scaling 与 research 的时代
在社交媒体和 panel 上,你会听到关于我们处在 research 时代还是 scaling 时代的争论。
在 Modal,我们不喜欢虚假的取舍,无论是 development speed 与 engineering efficiency 之间,还是 peak scale 运行与做 novel research 之间。Coding agents、autoresearch,以及其他将 artificial intelligence 应用于 research 的方式,都证明了这种二选一是错误的。我们可以既拥有 LeCake,也把它吃掉。
想自己试试吗?把我们的 autoresearch Skills 放进你的 agent,并让它处理你的问题。我们很想听听你的发现。