用一个 Python 字典将多模态推理性能提升 >10%
Boosting multimodal inference performance by >10% with a single Python dictionary
Modal 在 H100 上分析 SGLang 服务 Qwen2.5-VL-3B-Instruct 的 multimodal workload,用 py-spy 定位 scheduler 中 CUDA IPC handle 重复打开的 host overhead,并以 Python dict cache 替代逐 tensor 簿记。启用后 throughput 从 22.2 提至 25.7 req/s,TTFT、TPOT 分别下降 13.2%、17.2%,改动已合入 SGLang v0.5.10。
Engineering
2026 年 5 月 4 日•5 分钟阅读
tl;dr:Multimodal models 很有前景,但 inference engine 还没有针对它们做好优化。我们在一个 multimodal workload 上分析了 SGLang 的 scheduler,发现可以用一次简单的 cache lookup,替换围绕共享 GPU memory 的高成本簿记逻辑。在目标 workload 上,throughput 和 latency 都提升了 10% 以上。该改进已合并到 SGLang v0.5.10。
| Metric | Handle Cache OFF | Handle Cache ON | Improvement |
|---|---|---|---|
| Throughput (req/s) | 22.2 | 25.7 | +16.2% |
| TTFT mean (ms) | 965 | 838 | -13.2% |
| TPOT mean (ms) | 72 | 60 | -17.2% |
Multimodal vision-language models (VLMs) 给 artificial intelligence 装上了“眼睛”。我们的用户会部署较小的 VLM,用于高效解析非结构化文档;也会部署大型 VLM,为能够看到自己正在设计的 app 的 multimodal coding agents 提供能力。
这些新的输入类型和新模型,给 SGLang 和 vLLM 这样的开源 inference engine 带来了新的挑战。其中最顽固的挑战之一,是如何最大化性能——和以往一样,这里也只能靠持续打磨,一次做一个小改进。
这篇 blog post 讲述的就是其中一个不起眼的改动。
在与一位客户合作时,我们在 H100 上 benchmark Qwen2.5-VL-3B-Instruct,注意到 SGLang 的 throughput 早早进入平台期,明显低于 GPU 可承载的水平。解决办法是牢记 inference performance engineering 的“黄金法则”:never block the GPU.
识别 host overhead
当你发现 inference performance 问题时,先别急着进入 CUDA MODE,也别立刻在 Nsight Compute 里细看 warp stall reasons——甚至可以先放下 Torch Profiler!先检查简单的事情:host 上发生了什么,为什么它不够快?
在 SGLang 这样的 (V)LM inference engine 中,scheduler 是关键的 host-side component,也是潜在瓶颈——它是一个 single-threaded loop,控制着 GPU work 的提交。
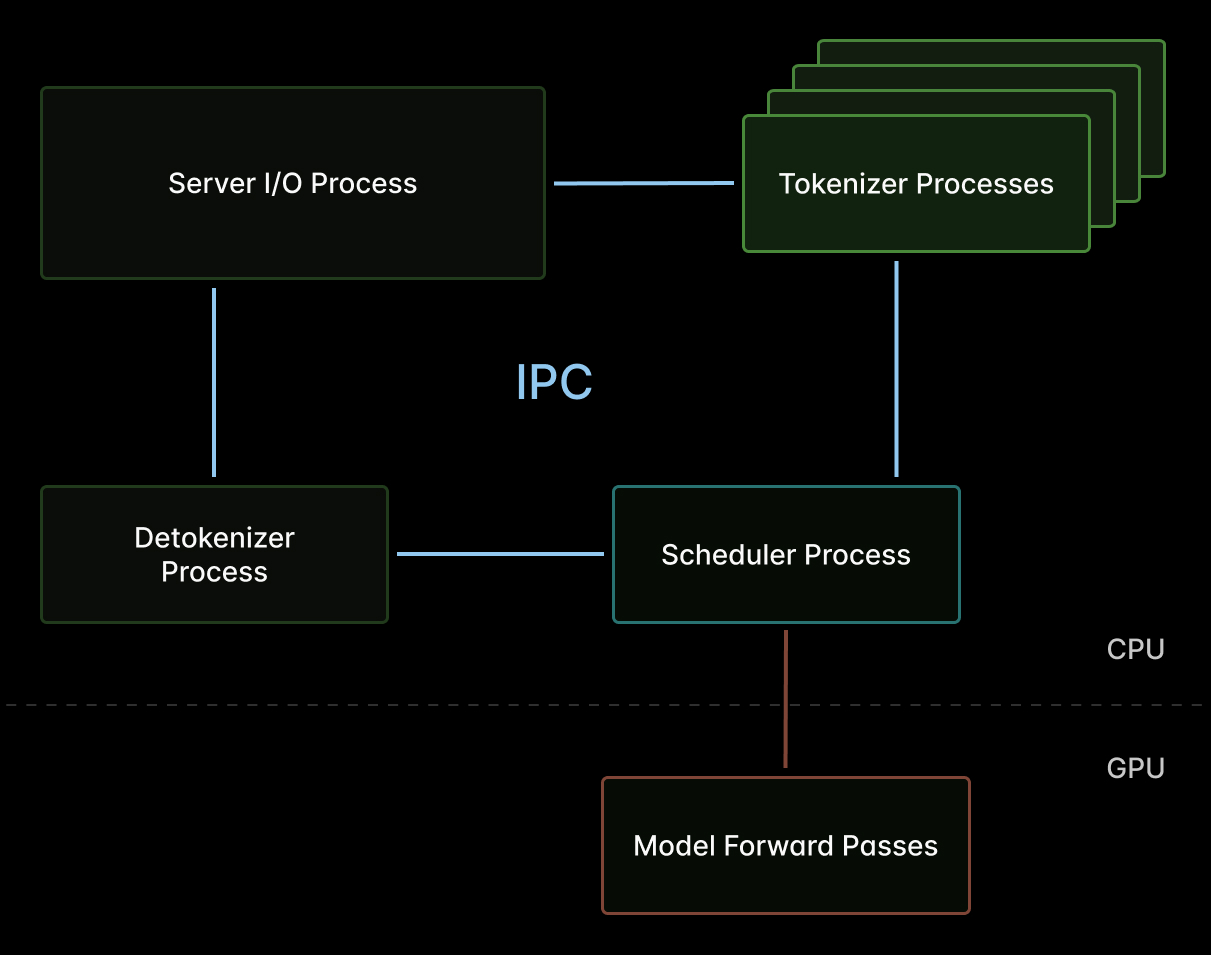
scheduler 中消耗的每一毫秒,都会让 all in-flight requests 的 prefill 和 decode iteration 停顿一毫秒。我们之前说过:host overhead 会毁掉你的 inference efficiency。
用 py-spy 内省 overhead
于是我们把朴素的 Python profiling tool py-spy 挂到一个正在服务 multimodal traffic 的 SGLang scheduler process 上:
我们很喜欢 py-spy——它可以用很低的 overhead,从正在运行的 Python program 中采样 call stack。在持续 30 秒的 multimodal traffic 之后,我们得到了约 3k 个 sample 和一张可用的 flamegraph。
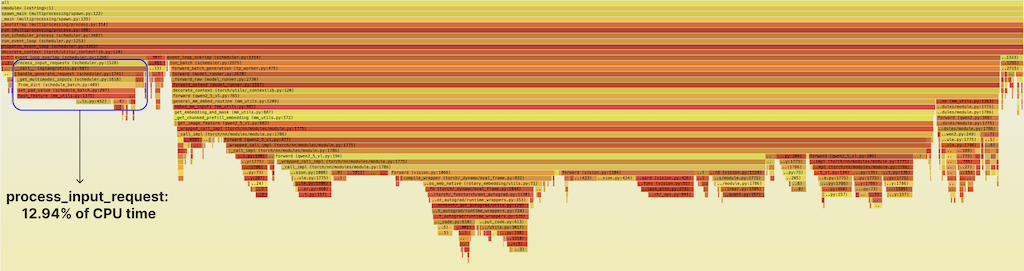
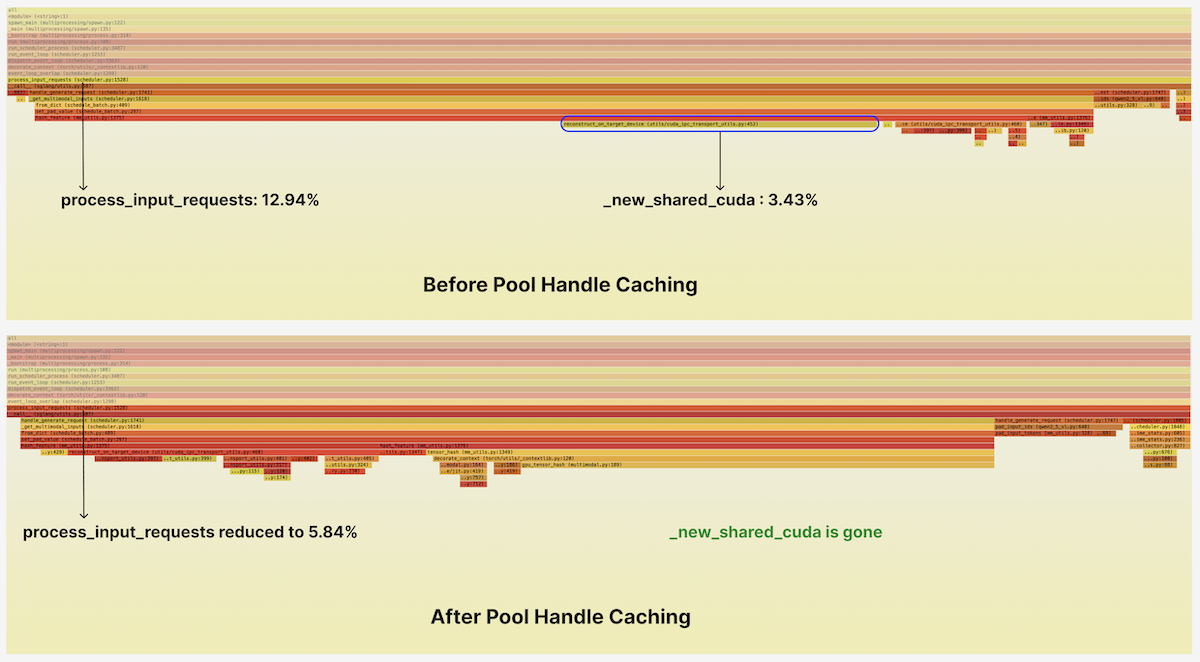
左侧高亮的带状区域是一个名为 process_input_requests 的 function。它会准备传入的 multimodal requests,以便 scheduler 组成 batch 并将其派发给 GPU。它消耗了 scheduler 总 CPU time 的约 13%,在 flamegraph 中像一块可疑的“高地”一样突出。
深入 process_input_requests 后,我们看到大部分时间花在一个名为 hash_feature 的 function 上。它会把输入 image 映射为基于 hash 的 ID,以便在 KV cache lookup 中低成本地识别它们。这是 multimodal inputs 的一条新 code path(text tokens 天然带有 ID,即它们的 vocab index),所以我们判断它很可能还没有获得太多优化关注。
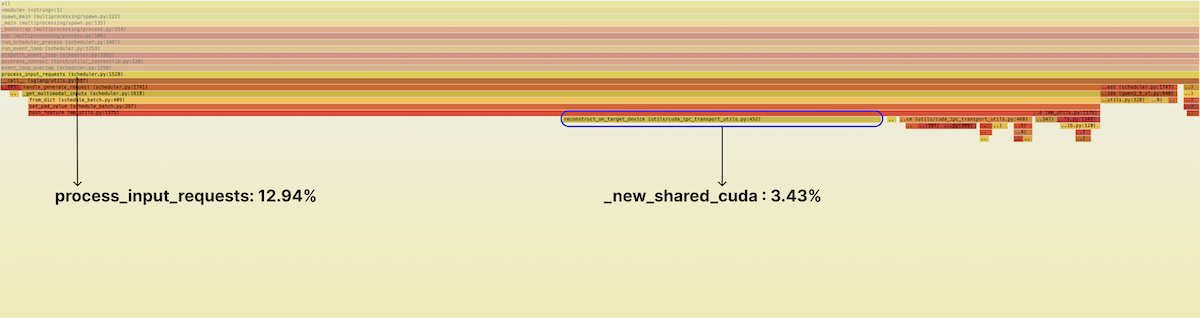
在里面,我们看到一些可疑之处。这个 function 中约 25% 的时间,也就是 scheduler 总 runtime 略高于 3% 的时间,都花在对 reconstruct_on_target_device 的调用上——再往下,则是对 torch.UntypedStorage._new_shared_cuda 的调用。
所以现在要问的是:它在做什么?能不能更快?
用 Python dict 避免 hot path 中的簿记
为什么需要 shared storage?Device memory allocations 在 CUDA 中默认与单个 process 关联,就像 CPU programming 中的 memory allocations 一样。
SGLang 会把工作拆分到多个 process。比如,scheduler 在一个 process 中编排 GPU inference,而一个或多个 tokenizer workers 会在其他 process 中并行地把 raw inputs 预处理成 tensors。
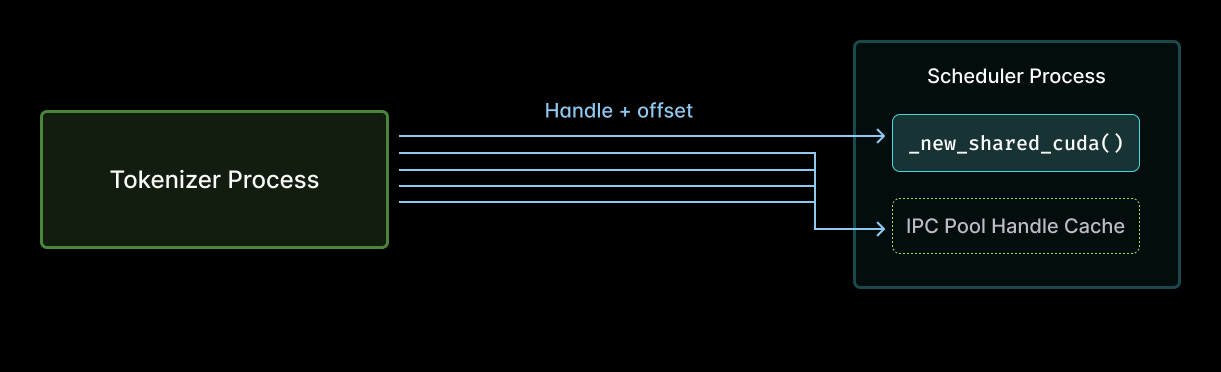
因此这些 tensors 必须跨越 process boundary。对于 SGLang 中的大型 on-device tensors,最快的做法是使用 CUDA Interprocess Communication (IPC),它可以避免 copy。具体到 SGLang,每个 worker 都有自己的 GPU memory pool,每个 tensor 都是该 pool 的一个 slice,而这些 tensors 通过其 pool 的 handle 和 pool 内 offset 来标识。这些 metadata 需要在 tokenizer processes 和 scheduler 之间传递。
结合 flamegraph 审查代码后,我们意识到 scheduler 会对 every tensor 调用 _new_shared_cuda。大致如下:
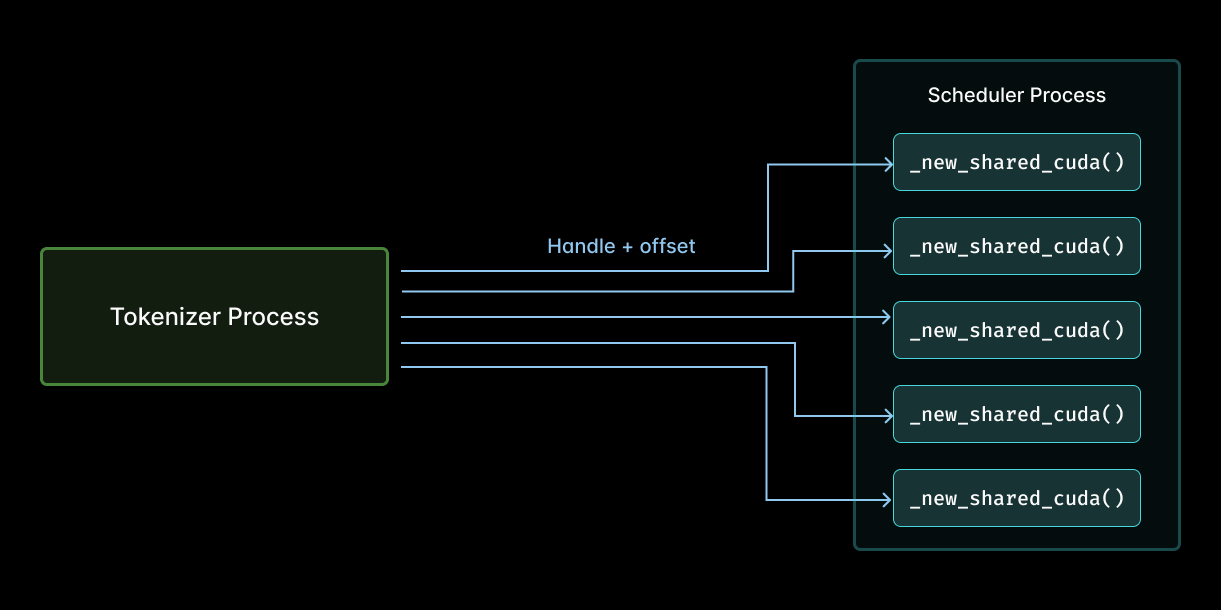
也就是说,在此前的实现中,multimodal feature hashing 期间,tokenizer process(左)和 scheduler(右)之间的 tensor sharing,需要对每个共享 tensor 调用一次 _new_shared_cuda(箭头)。
这意味着 scheduler 会一遍又一遍地重新打开同样少数几个 handle,每次都承担 host-side 簿记 overhead,结果却在 scheduler iteration 结束时把这本“账”丢掉!这项工作的规模会随 pool 中 entry 的数量和 iteration 的数量增长。但实际上,你只需要常数级工作量:每个 pool 调用一次即可。Do it once, but don’t do it again!
这里说的究竟是什么工作?在 CUDA API level,重复 open 的成本很低(reference-counted)。所以大部分 overhead 来自 PyTorch wrapper——新的 StorageImpl、CUDA event recording、GIL interaction,以及 allocator book-keeping。更多细节可见这个 GitHub Issue。
这是对宝贵毫秒的误用,而每一毫秒都很重要!
听起来有些复杂的 “CUDA IPC Pool Handle Cache”,实现上只是一个简单的 Python dict。这些 pool 从不会重新分配,因此不需要 cache invalidation。我们也只在写入 cache 时需要 lock,读取时不需要。而写入非常少见!实现就是:
用另一张 flamegraph 抽查修复效果
我们在相同 load 下重新运行了启用新 cache 的 py-spy profiling。_new_shared_cuda hotspot 从 profile 中消失了,input processing 中的 sample 总数减少了一半以上。
衡量端到端结果:throughput 提升 16%,latency 降低 10%
Flamegraph 很适合调试 performance issue,但它不能保证端到端一定有收益。因此我们回到原来的 benchmark:单张 H100 上的 Qwen2.5-VL-3B-Instruct。下面是加入 pool handle cache 前后的结果。
Request throughput 提升约 16%,mean end-to-end latency 下降约 10%。Tail latency 也有改善!
| Metric | Handle Cache OFF | Handle Cache ON | Improvement |
|---|---|---|---|
| Throughput (req/s) | 22.2 | 25.7 | +16.2% |
| TTFT mean (ms) | 965 | 838 | -13.2% |
| TTFT p99 (ms) | 2058 | 1819 | -11.6% |
| TPOT mean (ms) | 72 | 60 | -17.2% |
| ITL p99 (ms) | 627 | 556 | -11.4% |
| E2E latency mean (ms) | 1979 | 1768 | -10.6% |
| E2E latency p99 (ms) | 4309 | 3666 | -14.9% |
详情见 the PR。
我们的 benchmark 使用的是 Qwen2.5-VL-3B,但该改进适用于任何使用 SGLang CUDA IPC transport 的 multimodal model。收益应当会随 multimodal inputs 总数增加而扩大。
Decode latency 也改善了!
有一个结果乍看有些意外:average time-per-output-token 下降了 17%。Decode 变快了,尽管这个修复完全位于 input/prefill path。为什么会这样?
首先,在启用 mixed-chunk scheduling 时,prefill 和 decode tokens 可以共享一个 batch,因此减慢 prefill batch elements 的 setup,也可能拖慢 decode。
但真正的收益更深一层。别忘了,SGLang 的 scheduler 运行在单个 thread 上——一个 thread 负责处理 incoming requests、组成 batches,并把 batches 派发给 GPU。所以,任何地方慢,都会导致所有地方慢!当所有事情都跑在一个 thread 上时,花在 process_input_requests 上的时间,就是没有用来派发下一个 batch 的时间。
这个 perf improvement 已经在已发布的 SGLang 中。现在就可以试用!
该优化已通过 sgl-project/sglang#21418 upstream,并包含在 v0.5.10 release 中。使用 CUDA IPC 时,你可以通过添加以下 flag 来启用它:
如果你想亲自尝试,我们的在 Modal 上用 SGLang 部署 VLM 的指南可以让你在几分钟内跑起来。
P.S. 如果你喜欢解决这类问题,我们正在招聘。