在 Modal 上构建 RL 定理证明工作流
Building an RL Theorem-Proving Workflow on Modal
AE Studio 在 Modal 上构建 RL theorem proving workflow,用 vLLM 在 GPU 生成 Lean 证明、Lean verifier 在 CPU Sandboxes 验证,并用 .map()、Volumes、Secrets 协调 ES 与 GRPO 对比。实验每轮生成 3,840 个证明,平台设置约 250 行代码,单轮完整 loop 538 秒,估算完整运行成本为 122 美元。
客户案例
2026 年 4 月 29 日•10 分钟阅读
本文由 AE Studio 撰写,AE Studio 是 Modal 的咨询合作伙伴。加入这些使用 Modal 更快交付 AI 的团队:modal.com/partners。
动机:教 AI 证明数学定理
在 AE Studio,我们会大量进行语言模型的 pretraining(预训练)和 fine-tuning(微调),而并行的按需计算是高效运行这些 workload 的唯一方式。借助 Modal,我们可以并行启动数千个 GPU,把原本需要数周或数月的研究压缩到几天内完成。本文将介绍我们如何使用 reinforcement learning 训练 LLM 证明数学定理。
用 reinforcement learning 训练模型的方法不止一种。如今最常见的方法叫 Group Relative Policy Optimization (GRPO)。简单来说:模型生成一批证明尝试,系统将它们相互比较并排序,然后把模型内部权重推向正确证明的生成方向。
我们想测试一种替代方法:Evolution Strategies (ES)。ES 不通过传统 backpropagation 调整模型,而是采用一种受自然选择启发的方式:创建一个由模型的轻微变体组成的“种群”,测试所有变体,然后将原始模型推向得分最高的那些版本。
近期研究表明,ES 在某些设置下可以优于 GRPO。我们想看看这一点能否在定理证明任务中复现,作为加速 AI-enabled science 的第一步。
设置
要让语言模型证明一个定理,它需要用一种专门语言生成“代码”。Lean 是这类语言中较流行的一种。代码生成后,Lean compiler 可以验证证明是否正确。代码生成由 LLM 完成,主要消耗 GPU/inference 资源。验证由 Lean compiler 完成,运行在 CPU 上。
因此,要运行这个 workload,我们需要三个不同的执行环境协同工作:
- 生成证明:在 GPU 上运行的 vLLM instance 用于执行 inference,生成证明尝试。
- 检查证明:每个证明都会发送到运行在 CPU 上的 Lean verifier。这部分需要隔离,因为错误证明可能会让 verifier 挂起或崩溃,而我们不希望一次失败拖垮整个运行。
- 协调所有环节:一个轻量级进程负责监督 training loop,将成批定理发送给 generator 和 verifier,收集结果并跟踪进度。
如果从零搭建这套系统,就意味着要管理多个 server environment、一个 job scheduling system、用于 model checkpoint 的存储,以及一个足够健壮、能优雅处理崩溃的验证服务。我们没有自己构建这些,而是把整套流程都跑在 Modal 上。这样我们就能把时间花在实际实验上,而不是构建基础设施。
在实践中,这对应到 Modal 上的如下设置:
| Workload 需求 | Modal 功能 |
|---|---|
| GPU 生成、Lean 验证和编排分别使用独立 runtime | Per-function images 让每一步都能声明自己的环境 |
| 每次 ES iteration 中有许多独立 evaluation | .map() 扇出 remote jobs,并在结果完成时流式传回 |
| Lean 验证必须与错误证明和长时间请求隔离 | Sandboxes 为每个验证 batch 提供独立的短生命周期 Lean server |
| Base model 必须可供所有 remote worker 使用 | Volumes 存储原始 base weights,让每个 GPU worker 都能加载,而不必每次都从 Hugging Face 下载 |
| 从 Hugging Face 访问 gated model | Secrets 将 credentials 注入 remote functions,避免泄露到本地 shell state |
我们预期这套设置的主要阻力在于 GPU sandboxes 需要时间 warm up,而且 remote debugging 永远不如在单个本地进程中直接。这是在多个 GPU 上运行 bursty experiments 时的固有挑战。好在 Modal 通过减少 cold starts、让 remote iteration 更容易等功能,缓解了不少复杂性,使这类研究 workflow 更容易管理。
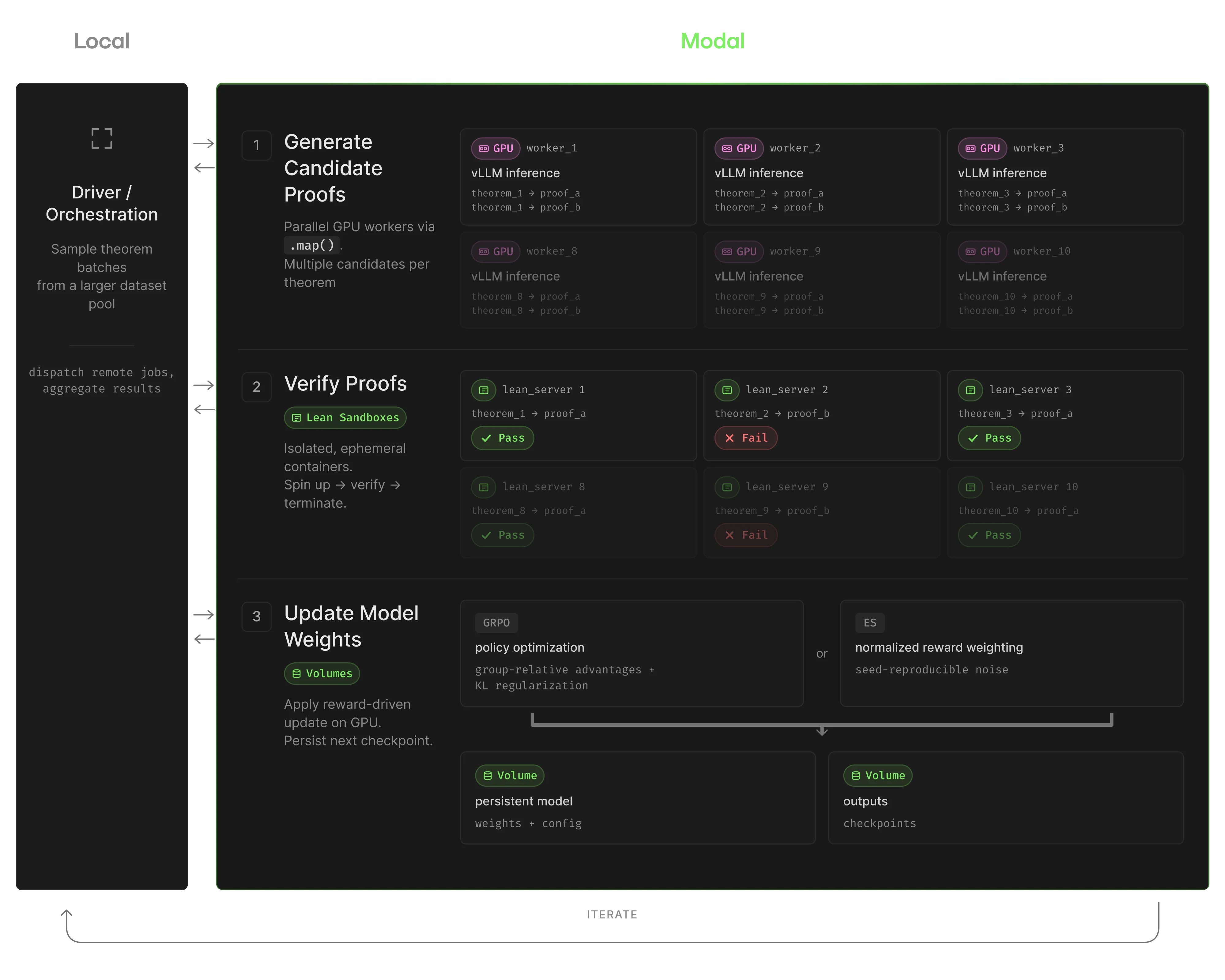
训练流程
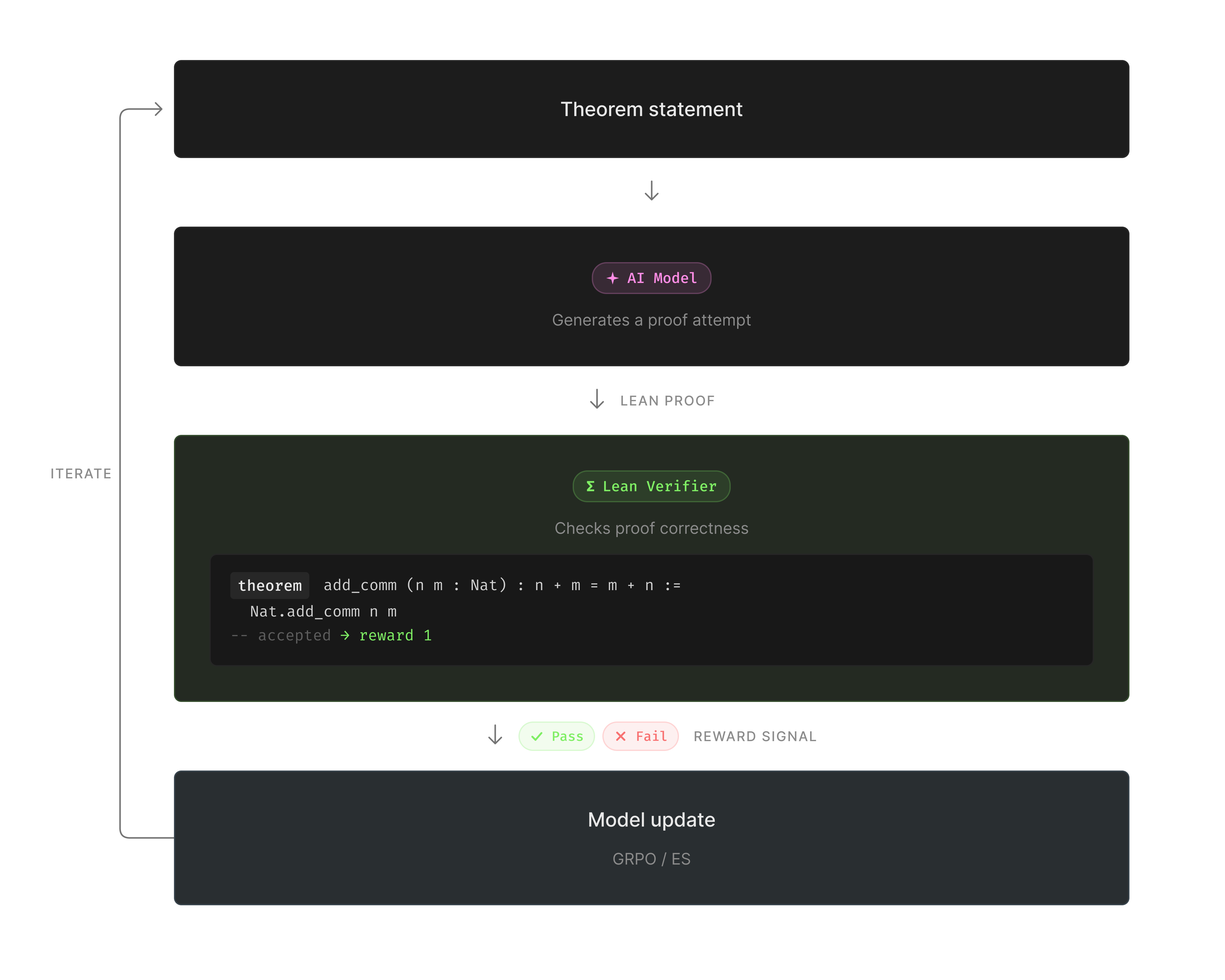
我们的目标是训练一个擅长数学定理证明的模型。这里我们使用 Lean,它是一种 formal theorem verification language,能为 training loop 提供可验证的 reward;我们不是询问模型输出看起来是否合理,而是询问 Lean 是否接受它作为有效证明。
一个玩具示例是证明:如果 a = b 且 b = c,那么 a = c。模型用 Lean 写出证明。Lean verifier 根据证明是否正确生成 reward signal。
我们保持 training loop 不变,只改变 update rule,以比较 GRPO 和 ES 的性能:
- GRPO 生成多组证明尝试,并根据组内相对表现应用 gradient update。
- ES 评估一个由 perturbed models 组成的种群,根据证明成功率为每个 perturbation 打分,并基于 reward 对种群中的 perturbations 做 weighted combination,用来更新 base model。
我们如何在 Modal 上构建它
为不同任务使用独立 Image
我们为每个 compute role 配置自己的 image,而不是试图把所有东西塞进一个过大的环境:
GPU workers 可以专注于 inference,Lean sandbox 专注于验证,而 orchestrator 保持轻量。这也意味着每个环境都可以独立缓存和复用。
使用 .map() 进行并行 GPU Fan-Out
ES 是整个 workload 中最容易分布式化的部分。每次 perturbation evaluation 需要当前 checkpoint、定理 batch、一个 perturbation seed,以及 generation parameters。我们使用 .map(),因为 fan-out 正好符合算法结构:
在 ES 中,weight perturbations 完全由它们的 seeds 决定。update step 只需要 seeds 和 rewards 就能聚合种群中的所有个体,避免在 GPU 之间传输昂贵的 weights。每个 worker 接收完整的 seed/reward history,并在应用自己的 perturbation 之前,从 base weights 重建当前模型。
Sandboxed Lean Verification
验证是系统中最需要隔离的部分。证明尝试可能会挂起、让 checker 崩溃,或者消耗远超预期的资源。我们不希望一个坏 batch 影响到其余运行。
对于每个 verification batch,我们创建一个 sandbox,在其中启动 Lean server,通过 HTTP 发送证明、收集结果,然后关闭 sandbox:
我们用相同的基本 fan-out pattern 并行验证证明:
一次 iteration 会创建 3,840 个证明尝试,我们将其拆分为每批 64 个。Modal 的 sandbox model 使其可以进一步扩展。如果我们希望验证步骤完成得更快,可以让每个证明尝试都在自己的 sandbox 中运行,并并行执行数千个证明。
使用 Seed Histories 进行 Stateless Checkpointing
ES 的一个好处是,整个模型状态可以由 base model 加上一组 (seed, reward) 对来描述。每个 perturbation 都由 deterministic random seed 生成,因此你永远不需要存储实际的 noise vectors。orchestrator 维护一个不断增长的 seed/reward 条目列表,并将其传给每个 worker。
每个 history entry 只包含 seeds、它们的 normalized rewards,以及重新计算 update 所需的 hyperparameters。每次 iteration 约 200 字节:
在 GPU 侧,每个 worker 从 Volume 加载原始 base model,然后 replay 完整 history 来重建当前 weights,再应用自己的 perturbation:
replay 会遍历过去每次 iteration 的 seeds 和 rewards,使用 deterministic seed 在 GPU 上重新生成相同的 noise,并原地应用 weighted update。base model 存放在 Volume 中,因此 workers 可以加载它,而不必每次都从 Hugging Face 重新下载:
从 training loop 的角度看,Volume 是只读的。完整模型状态以普通 Python list 的形式传递,小到足以作为函数参数传给每次 remote call。
关键性能指标
对于这个实验,Modal 在速度、简洁性和成本之间提供了理想平衡。我们的 Modal 实现大约需要 250 行平台设置代码,不到我们在其他平台上针对类似实验通常看到的约 600 行的一半。这种复杂度降低意味着,从项目启动到完成一次成功 training run 不到两天,比我们使用替代平台时少 60%。这也意味着在我们继续调整和优化 training pipeline 时,iteration speed 更快。
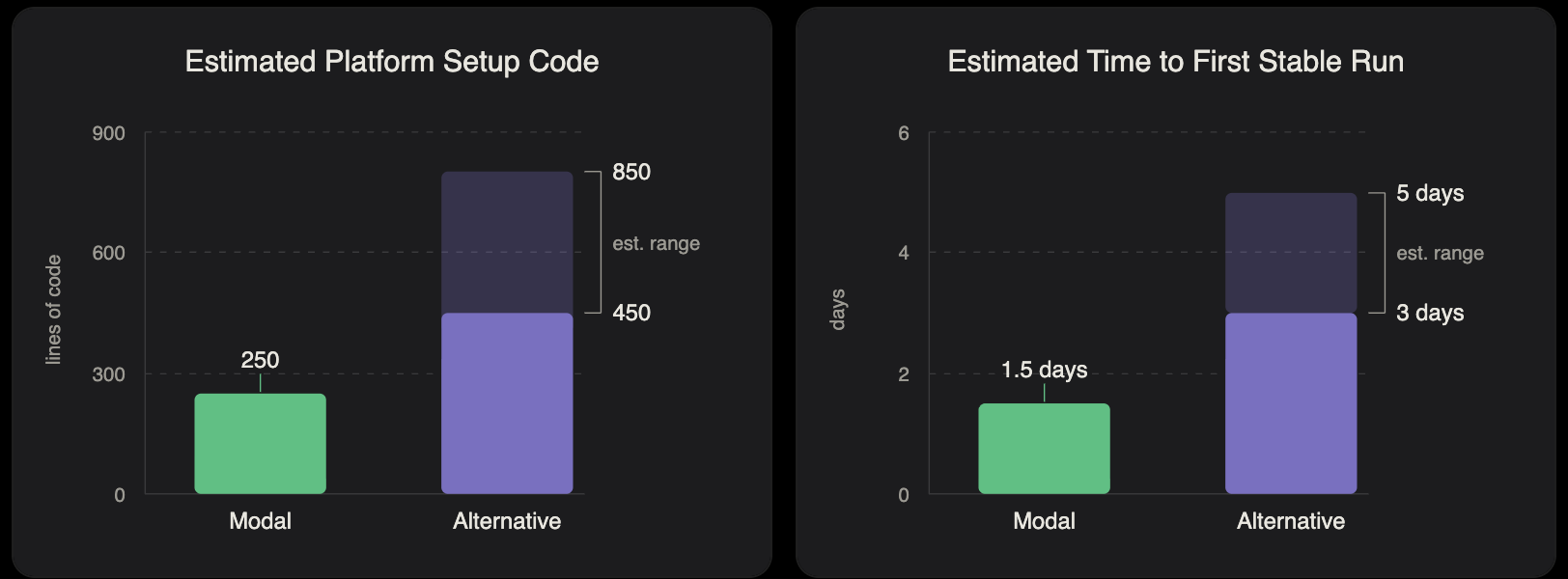
Runtime efficiency 也显著提升。虽然 generation step(需要 GPU)平均每次 iteration 147 秒,但由于 verification stage(只需要 CPU),完整 loop 需要 538 秒。Modal 的 elasticity 意味着我们只在 GPU 实际使用时付费,相比弹性较差的平台,浪费的 GPU 时间约减少 3.7x。
基于这些耗时,我们估算在 Modal 上完整运行成本为 $122。使用相同硬件、但弹性较差的替代方案,等价运行成本会在 $180 到 $480 之间。即使没有进行大量优化,这套开箱即用的设置也被证明是获得结果最快、最具成本效率的路径。
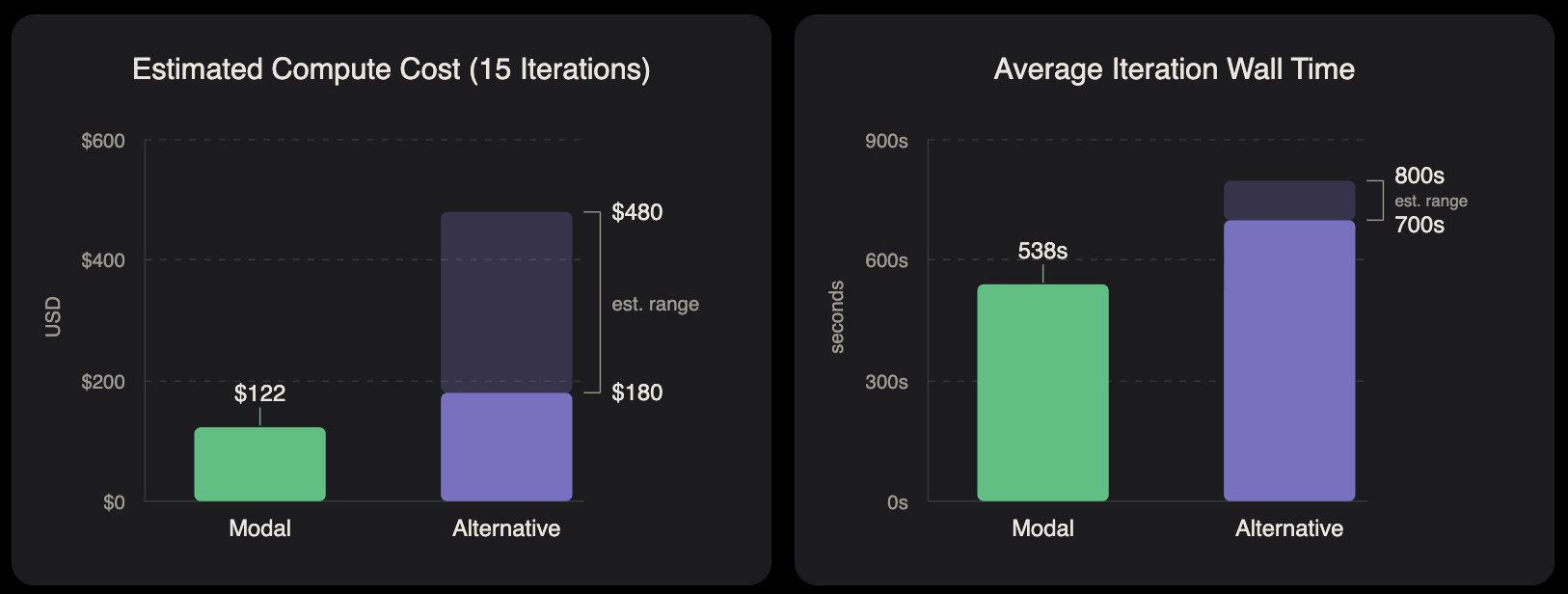
注:这些数字是基于我们的 codebase、公开定价以及从实测 ES timing 中收集的数据进行的估算。
结果与下一步
我们的早期结果令人鼓舞。在几次 theorem-proving run 中,ES 在每次 iteration 的 verified proofs 数量上追平或超过了 GRPO baseline,而且在训练数据有限时,常常表现出较高的 sample efficiency。在其他设置下,收益较小;我们还没有分离出这些差异中有多少来自 hyperparameter choices、dataset nuances 或 population size 等因素。ES 在这一 regime 下的 scaling behavior 仍未被充分理解,因此还需要更多实验来判断它在哪些地方能稳定发挥,以及它是否能在更大规模 training setup 中与 GRPO 竞争或超越 GRPO。
因此,研究问题仍然开放,但我们会继续使用 Modal 上的这套 infrastructure setup,让我们能够运行、检查并迭代这个由 verifier-backed 的 training loop,而无需投入时间构建自己的定制基础设施。
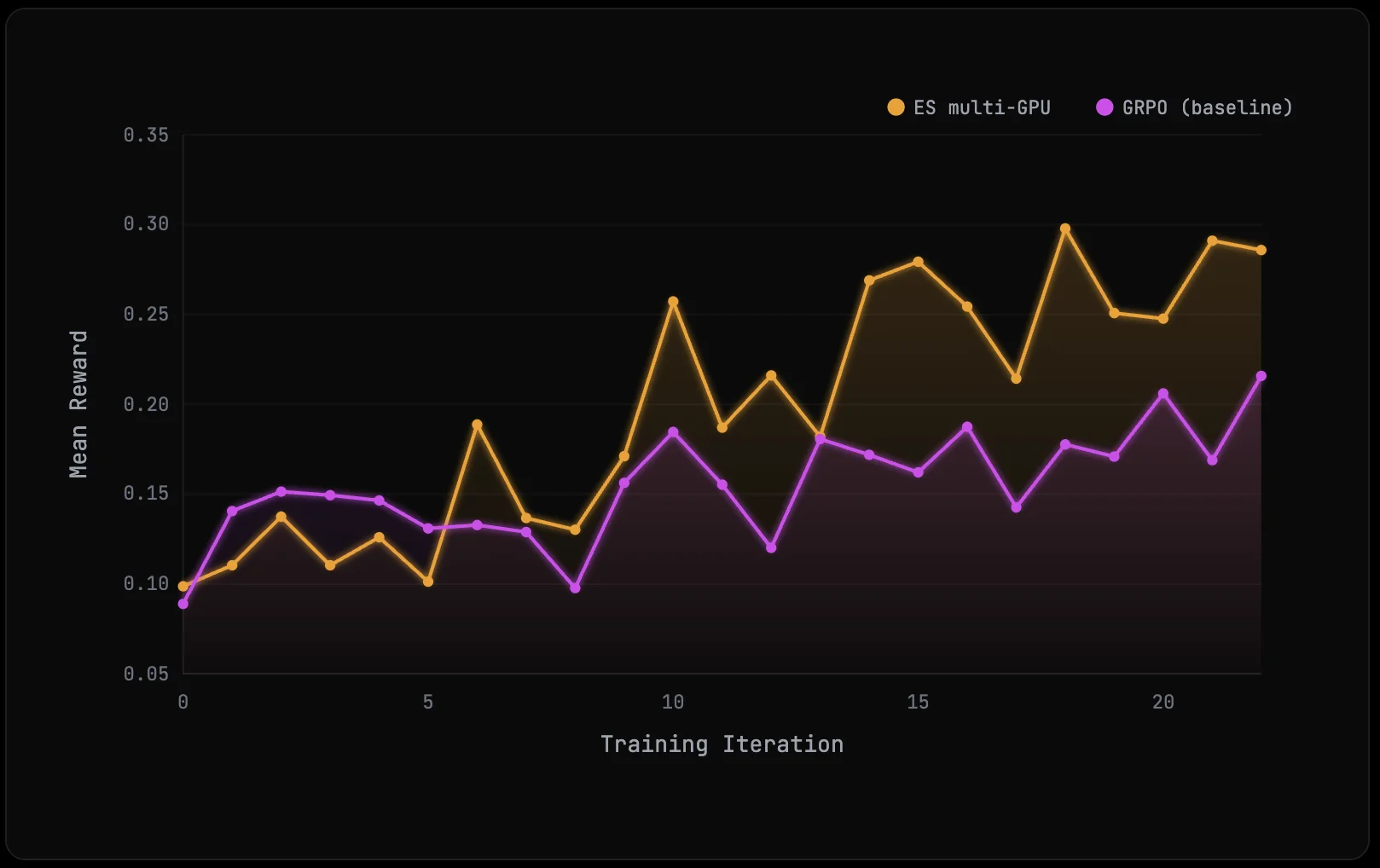
现在 training loop、verification path 和 checkpoint handoff 都已经可以工作,接下来的实验更直接:
- Variance analysis: 我们希望对 sigma、population size 和 theorem selection 进行更系统的 sweep,以理解 ES 何时改进、何时停滞。
- 更大的模型: 如果我们想测试随着 base model 变强,tradeoff 是否会变化,开放的 7B distilled Kimina model 是自然的下一步。
到目前为止,开放问题主要是实验设计,而不是让系统可靠运行。
你能从中学到什么
这套 infrastructure setup 并不局限于定理证明。你会在许多 ML system 中看到相同的形态:在 GPU 上生成输出,用外部 verifier、compiler 或 test harness 运行检查,将结果转化为 training signal,并在许多独立候选项上重复这一过程。
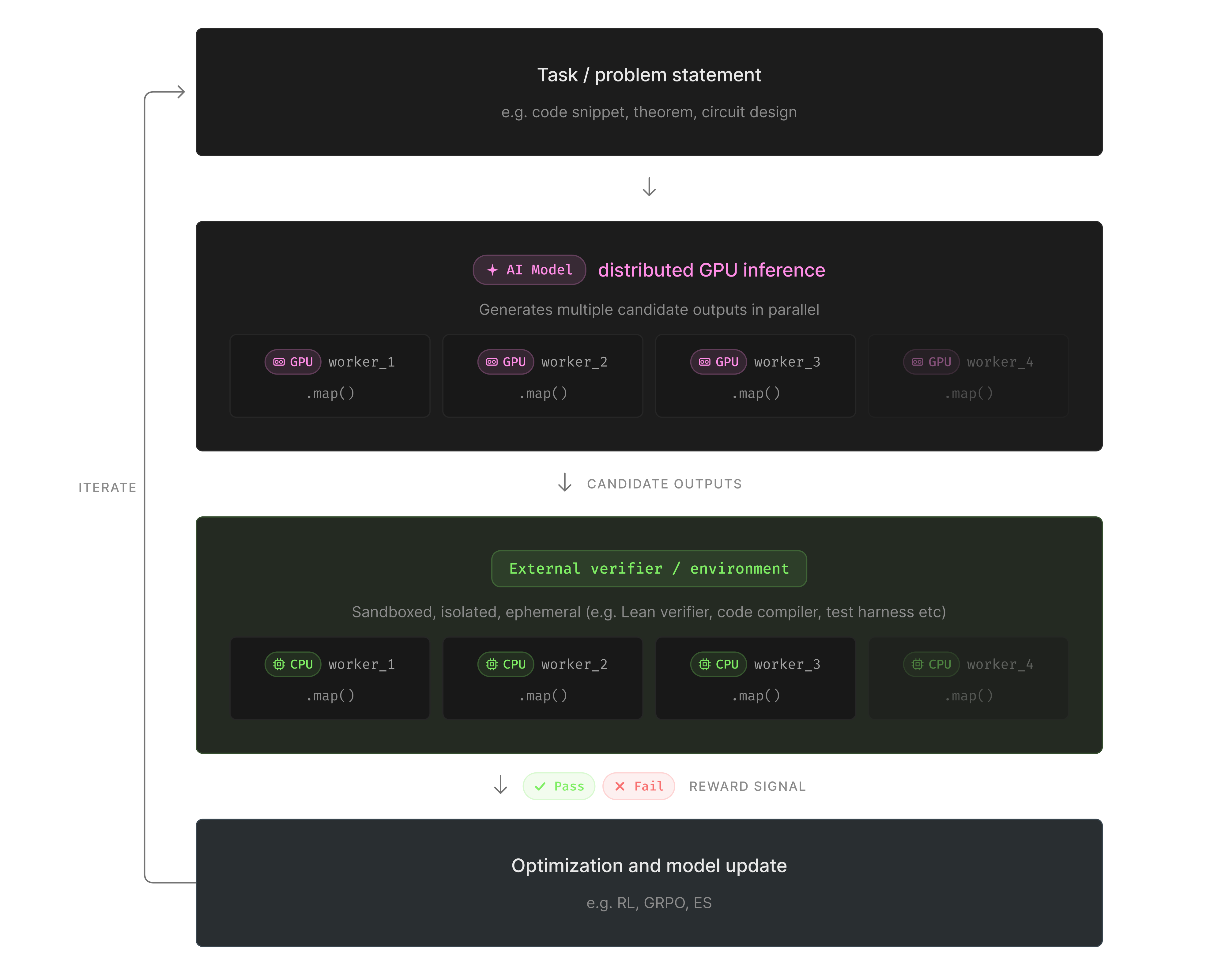
我们实验的关键技术点之一,是能够在一个 workflow 中同时实现 GPU inference 的并行化、verification 的隔离,以及 training state 的可移植。 .map() 分发 proof generation,Sandboxes 容纳 verifier failures,Volumes 在 iteration 之间保持 checkpoints 可用,而不必把它们移回本地机器。
使用 Modal,我们得以在三个非常不同的 runtime 上运行同一个 sparse-reward RL workflow,而不必每次都重建设置。我们从本地机器启动 run,让 base model 保持在远端,记录到 MLflow,并随着实验推进调整 population size、theorem batch size 和 verification parallelism。
由于 Modal 平台的功能和易用性,我们在项目开始后的几天内就看到了实验结果。其他基础设施平台需要数周测试和迭代后才能得到任何信号;而一旦设置完成,我们的团队就可以完全专注于实验设计,不必担心系统可靠性。
如果你想深入了解我们实验的细节,或将这套设置改造用于自己的 workflow,完整实验代码可在 github.com/agencyenterprise/modal-rl-theorem-case-study 获取。
参考文献
- Qiu, X., Gan, Y., Hayes, C. F., Liang, Q., Meyerson, E., Hodjat, B., & Miikkulainen, R. (2025). Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning. arXiv:2509.24372. https://arxiv.org/abs/2509.24372
- Numina & Kimi Team. (2025). Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning. arXiv:2504.11354. https://arxiv.org/abs/2504.11354
- Raschka, S. Build a Reasoning Model from Scratch. Manning. https://www.manning.com/books/build-a-reasoning-model-from-scratch
- Base model 是
Kimina-Prover-Preview-Distill-1.5B,由72B Kimina-Proverdistill 而来。我们使用项目的kimina-lean-server image进行验证,并在kfdong/STP_Lean_SFT的lean_workbooksubset 上训练。↩