强化学习是一个基础设施问题
Reinforcement learning is an infrastructure problem
在 Modal 平台上,使用强化学习(RL)对 LLM 进行后训练的热度上升,团队从研究实验室到企业正构建训练系统以从基础模型中获得成本效益。Modal 分享了大规模运行 RL 后训练的经验,并开源了 Training Gym 库。RL 训练循环分为训练、推理生成(Rollouts)和隔离环境三部分,多节点设置成为基本要求,RDMA 传输速度将训练提升 100 倍。团队常被维护胶水代码、排队等待集群时间和 GPU 利用率不足三个问题困扰。Modal 通过 Clustered Functions、Sandboxes 和 Volumes 等抽象解决这些问题,支持在 GLM 4.7 和 Kimi K2.6 等大型模型上进行 SFT 和 RL,包括低秩适应和全微调。Modal 押注开源训练框架如 slime、miles、verl、OpenRLHF,并已将改进上游。Training Gym 库可在不到 100 行代码内定义训练任务,只需指定奖励函数、模型和环境。
工程
2026年6月1日·10分钟阅读
在 Modal 上,使用强化学习(Reinforcement Learning, RL)对 LLM 进行后训练的热度急剧上升。
我们帮助了各种规模的团队——从研究实验室到成熟企业——构建训练系统,以从基础模型中获得前沿的成本效益。我们意识到,当前 RL 的瓶颈在于基础设施。
今天,我们想分享从大规模运行 RL 后训练中学到的经验,以及我们构建的一个开源库,这样你就不必走弯路了。
问题的形态
一个 RL 训练循环整体分为三个部分,每个部分都是一个独立且困难的基础设施问题。
- 训练:使用能够可靠运行前向传播、反向传播和权重更新的引擎,且规模要覆盖有用的基础模型(数十亿到数万亿参数)。
- 推理生成(Rollouts):来自高性能推理引擎,能够在单块或多块最新 GPU(从一张卡到数百张)上以接近光速的速度服务大模型。
- 隔离环境:你的模型策略可以在其中以与推理生成匹配的稳定速率并发执行操作(数千到数百万个容器)。
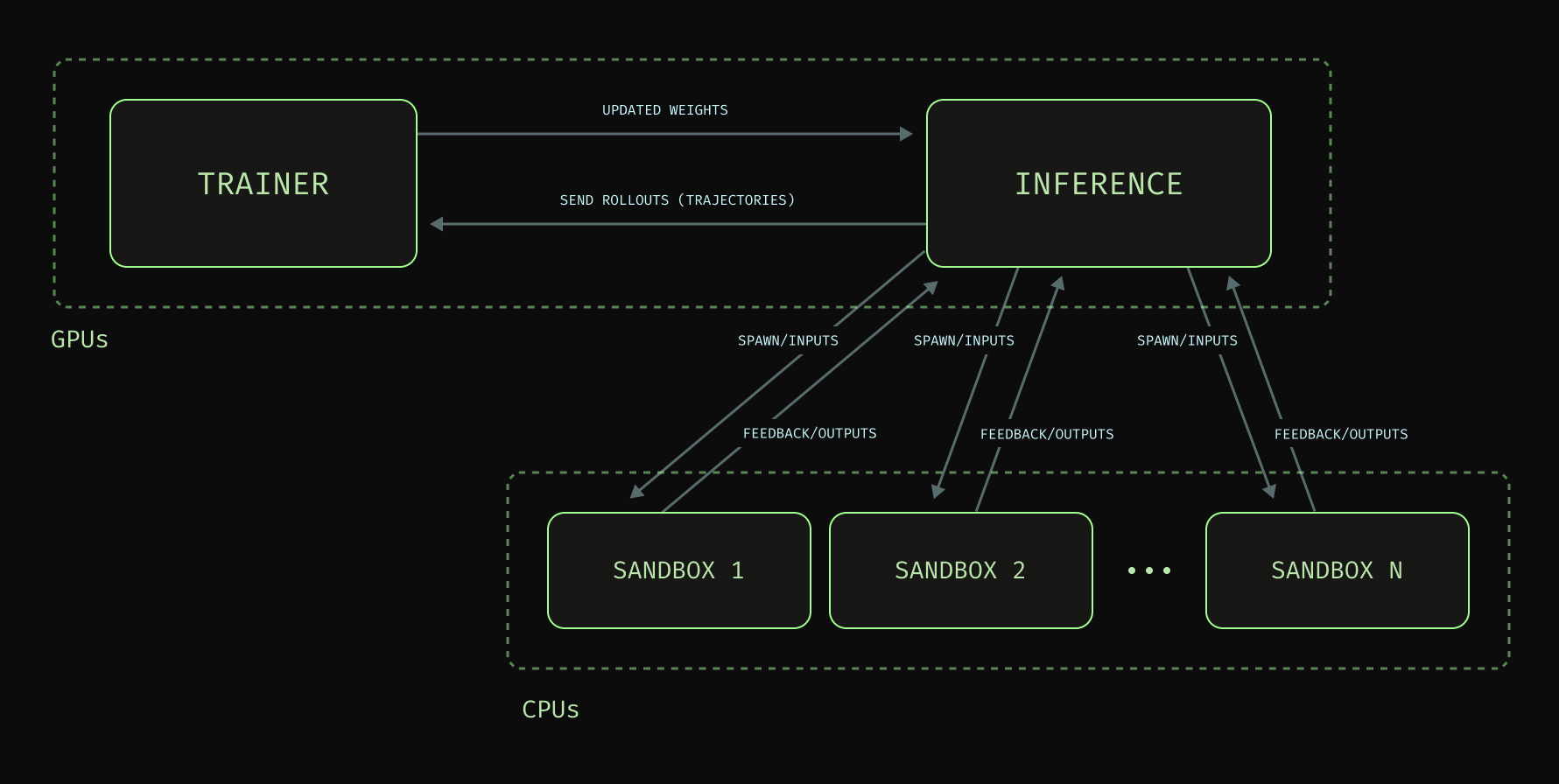
过去一年发生了什么变化:走向多节点
更多团队正在微调开放权重的模型。他们正在将 AI 投入生产,而不仅仅是为高管拼凑一些带有模糊"AI 指令"的演示,而且许多产品正在迅速成熟。与此同时,由于对测试时计算的依赖增加,前沿专有模型的总 token 成本持平或上升。幸运的是,从 NVIDIA 和 Google 到 DeepSeek 和 Kimi,多个组织都在宽松许可下发布了优秀的模型。
虽然小模型(这里指低于十亿参数)仍有很强的微调潜力,但对于更复杂的任务,更大的模型才是方向。它们通常具有更高的能力上限、更好的数据效率,以及更少的灾难性遗忘。代价是需要更多 VRAM 来容纳权重、梯度、优化器状态和 KV 缓存,以及更多带宽来传输它们。
一旦训练跨越多个 GPU 节点,训练器和推理引擎之间的权重同步就成为瓶颈。LoRA、异步 RL 或同地训练-推理生成等技术各自减轻了压力,但各有不同的权衡。即便如此,训练集群成本高昂,因此在大多数情况下,每空闲一秒仍要消耗数美分。
这使得多节点设置成为基本要求。
在同一集群内,RDMA 传输速度将训练提升 100 倍。
| 模型 | 权重更新大小 | 传输速度(NCCL over TCP) | 传输速度(NCCL over RDMA) | 参考 GPU 数量 | 每训练步预估成本节省 |
|---|---|---|---|---|---|
| Qwen3 8B | 16.3 GB (BF16) | 2.62 秒 | 41 毫秒 | 1x8 H100 | $0.21 |
| Qwen3-30B-A3B | 61.1 GB (BF16) | 9.78 秒 | 153 毫秒 | 1x8 H100 | $0.77 |
| Qwen3-30B-A3B LoRA (r=32, shared-outer) | 1.0 GB (BF16) | 160 毫秒 | 2.5 毫秒 | 1x8 H100 | $0.013 |
| GLM 4.7 | 716.7 GB (BF16) | 114.67 秒 | 1.79 秒 | 4x8 B200 | $36.12 |
| GLM 4.7 LoRA (r=32, shared-outer) | 4.7 GB (BF16) | 752 毫秒 | 11.75 毫秒 | 4x8 B200 | $0.24 |
| GLM 4.7 LoRA (r=32, per-expert) | 18.8 GB (BF16) | 3.01 秒 | 47 毫秒 | 4x8 B200 | $0.95 |
| Kimi K2.6 | 595.2 GB (INT4 MoE / BF16 attn) | 95.23 秒 | 1.49 秒 | 16x8 H200 | $119.99 |
| Kimi K2.6 LoRA (r=32, shared-outer) | 9.4 GB (BF16) | 1.50 秒 | 23.5 毫秒 | 16x8 H200 | $1.90 |
| Kimi K2.6 LoRA (r=32, per-expert) | 41.0 GB (BF16) | 6.56 秒 | 102.5 毫秒 | 16x8 H200 | $8.27 |
假设 TCP 为 50 gbps,RDMA 为 3.2 tbps。
当进行分离式 RL 时,由于 RDMA 未连接,模型权重更新时间较慢,但使用 delta 压缩也可以改善体验。
| 模型 | 大小 | 完整权重传输时间 | Delta 压缩 |
|---|---|---|---|
| Qwen3 8B | 16 GB (BF16) | 12.8 秒 | 0.26 秒 |
| Qwen3 30B-A3B | 60 GB (BF16) | 48 秒 | 0.96 秒 |
| GLM 4.7 (~355B) | 357 GB (BF16) | 285.6 秒 | 5.73 秒 |
| Kimi K2.6 (~1T) | 595.2 GB (INT4, MoE / BF16 attn) | 480 秒 | 9.6 秒 |
假设 WAN 互联网链路为 10 gbps,且 Delta 压缩节省了 98% 的权重更新量。
团队卡住的地方
我们发现团队被同样的三个问题困扰:
- 维护胶水代码
- 排队等待集群时间
- GPU 利用率不足
这些问题都不是你在最喜欢的 RL 教科书中能找到的。它们都通过更好的基础设施来解决。
维护胶水代码
要构建一个好的训练设置,你必须做大量的基础设施管理工作。随之而来的是,你的训练代码中越来越多的部分变成了胶水代码(或者更糟,YAML)。
你将在哪里获取和准备训练器节点?如何在其上引导训练框架?沙箱缓冲区和推理生成缓冲区放在哪里?当 [已编辑的推理引擎] 使你的推理生成节点崩溃时会发生什么?尽管训练中的故障代价高昂,但你的典型训练代码库对这些问题的回答很糟糕,训练运行既充满错误又难以调试。
幸运的是,Modal 将基础设施和代码捆绑在一起。例如,在 Modal 上,客户只需几行代码就可以启动一个 RDMA 连接、GPU 加速的训练集群,并内置可观测性、容错(重试、GPU 健康)和自动扩缩。看,妈妈,没有胶水!
单个布尔值 rdma=True 关键字参数为模型训练器隐藏了一个复杂的陷阱。本该如此!"抽象的目的_不是_为了模糊,而是为了创建一个新的语义层,在这个层面上可以做到绝对精确。"
同样的清晰抽象也构成了我们其他组件的产品,例如用于环境执行的 Sandboxes。但也许你已经构建了这些组件之一?Modal 是一个模块化平台,因此如果你愿意在胶水代码的泥潭中冒险,你可以自带训练循环中的任何组件。
排队等待集群时间
拥有必要的脚手架代码只是能够执行训练运行的第一步。
我们正处于计算资源短缺之中。但你不需要听 Dwarkesh Podcast 或购买 SemiAnalysis 的市场模型就能看到这一点。你有多少次启动一个训练任务,却要排队数小时?
然后,当你终于被调度时,运行立即失败,因为你配置错了 NCCL 或忘记设置某个 YAML 值。队列扼杀了迭代速度,进而扼杀了工程速度(对人类和对 agent 都是如此)。
8cp59fsi_89c4ec12.webp)
我们有容量。我们能够以极高的效率管理它,并利用多租户的优越经济性。借助我们的快速容器启动技术,我们的用户能够在几分钟内从零启动到 B200 集群——而不是几小时,更不用说其他平台需要的几天了。
GPU 利用率不足
所以你构建了意大利面条脚手架,并且有了容量。现在你遇到了最后一个障碍:环境成为 GPU 的瓶颈。
你为整个 GPU 付了钱。你必须使用整个 GPU。你必须 永远不要阻塞 GPU。
要做到这一点,你需要正确设置沙箱缓冲区的大小——一个预先准备好环境、随时可用于推理生成的沙箱池。如果你随意定义一个过大的沙箱缓冲区,你会浪费空闲计算的成本。如果你维持一个过小的缓冲区,你会因为每个推理生成的沙箱启动时间而阻塞 GPU。
Modal Sandboxes 在几百毫秒内启动,所以有时我们的客户会忘记缓冲区大小是可以优化的,但每一毫秒都很重要。
那么,如何确定缓冲区大小?一个经验法则是,在每个推理步骤中,_最多_有 batch size 数量的新动作,通常少得多。因此,你只需要为每个 episode/rollout 维护至少一个沙箱,以便动作立即被处理,无需排队。你还应该考虑错误率:运行许多环境意味着你会观察到更多的故障模式,对于长时间运行的任务,故障代价更高。
我们将 Modal Sandboxes 设计为具有每秒启动数千个沙箱并同时保持多达一百万个并发的规模。这意味着你可以并发评估所有推理生成,加速训练并保持 GPU 满载。
为了说明并发沙箱数量对步骤持续时间的影响,让我们考虑以下场景。
Video 4 一个步骤请求 10,000 个推理生成。每个沙箱负责执行一个简单的动作(例如代码执行),该动作完成端到端的上限时间为 10 秒。
你还可以使用诸如快照之类的功能来跳过沙箱创建时的设置工作、检查点 agent 动作等。
你不应该独自担心所有这些!
所有这一切——维护训练集群、争夺容量、管理推理生成和沙箱——对于一个团队来说变得非常繁重。
这就是为什么我们发现团队正在转向 Modal 来抽象掉许多棘手的细节,这样他们就可以专注于真正重要的事情:改进他们的环境、奖励计算和训练算法,以在损失函数和产品层面取得更好的结果。
为什么我们押注开源
我们还想强调最后一点:我们看到今天在 RL 上取得成功的团队几乎普遍从开源训练框架开始——slime、miles、verl、OpenRLHF——而不是自己从头构建。
有一个很好的理由:这些框架已经针对真实的前沿规模训练运行进行了验证。它们以经过数十万 GPU 小时压力测试的方式处理 RL 的微妙部分(优势估计、KV 缓存重用、分布式权重同步)。
借助这些框架,Modal 目前支持我们的客户在 GLM 4.7 和 Kimi K2.6 等大型模型上进行 SFT 和 RL,包括低秩适应和全微调。我们做了很多工作来改善这种体验,例如为 slime 添加 delta 压缩。我们所有的改进都将上游到这些开源框架,以帮助每个人——不仅仅是我们的用户——成功训练大型模型——就像我们开源我们对内核的改进(如 FlashAttention 4)以及我们对推理引擎(如 SGLang)的改进一样。
我们本可以像许多其他人一样,构建一个闭源的、托管的训练服务。但我们选择不这样做。我们的客户在我们的基础设施之上使用开源模型和开源训练框架,原因有二:
- RL 生态系统发展太快,任何单一供应商都无法跟上。新的算法、基础模型、环境模式和想法每周都会出现,一个静态产品在一个季度内就会过时,一年内就会被淘汰。控制训练框架代码意味着你(或你的 agent)可以直接实现你需要的功能,而不是在别人的任务跟踪器中创建工单。
- Modal 的价值不在于拥有你的训练循环然后将其劣化。而在于为你提供从 Python 文件到数千个 GPU 的最清晰路径,而不会让你不关心的事情妨碍你。
有了 Modal,任何人都可以训练任何东西。我们将继续构建更多基础设施,以更好地赋能我们的用户。
那么,接下来是什么?
我们的用户创建训练任务,在 RDMA 连接的 Clustered Functions 上运行经过验证的框架,在数千个并发 Sandboxes 中编排环境,并将权重存储在分布式 Volumes 中,用于下游评估和推广到生产环境。他们可以在 Modal 上安心地迭代训练,确信基础设施不会拖累他们。但拼图中还有最后一块:上手和采用这些框架和工具本身就是一件令人头疼的事。
像 slime 这样的工具和框架通常是为希望暴露所有旋钮的研究人员构建的,这意味着将模型微调到输出 "hello world" 到文件通常需要 2000 行配置和另一堆胶水代码。
我们合作的每个团队都在反复做大致相同的脚手架工作:连接多节点集群、搭建环境、构建更多可观测性。
因此,我们决定抽象掉最后一块胶水基础设施。
介绍 Modal Training Gym
在过去的一个月里,我们构建了一个实验性库,其中包含我们的客户关心的通用抽象。
为了致敬先驱者,我们将其命名为 Modal Training Gym,你可以在 GitHub 上这里访问它。使用这个库,你可以在不到 100 行代码内定义一个训练任务。你只需要指定和配置你关心的东西:一个奖励函数、一个模型和一个环境。
Training Gym 是我们作为训练用户自己想要的、位于 Modal 之上的抽象层。它带有内置的训练可观测性、一组 RL 教程和出色的 agent 开发体验。下载它,告诉你的编码 agent "训练一个用 Y 做 X 的模型",然后让它自由发挥。
我们将在未来几个月内快速添加功能,并且我们正在积极寻找设计合作伙伴。如果你对此感兴趣,请来与我们交流。
让我们一起定义 Modal 上开源训练的未来形态。