用分布感知 speculative decoding 将 RL rollouts 加速最高 50%
Accelerate RL rollouts by up to 50% with distribution-aware speculative decoding
Distribution-aware speculative decoding(DAS)用于缓解 RL 后训练 rollout 瓶颈,采用 adaptive suffix tree drafter 和 length-aware scheduling。在 DeepSeek-R1-Distill-Qwen-7B 数学任务上 rollout 时间减少超 50%,Qwen3-8B 代码任务约减少 25%,reward curve 与 baseline 一致。

摘要
Distribution-aware speculative decoding(DAS)是一种新的框架,可显著缓解 RL 后训练中的 rollout 瓶颈,在不改变模型输出的情况下实现最高 50% 加速。
rollout 瓶颈
Reinforcement learning 已成为现代 LLM 后训练的基石。DeepSeek-R1 等模型的推理能力来自 RL fine-tuning。但随着模型规模变大,一个关键瓶颈已经出现:rollout 阶段。
在 RL 训练中,模型必须为一个 batch 中的每个 prompt 生成完整响应,下一步训练才能开始。_最慢_的生成决定了总 step 时间——这是典型的长尾问题。
总训练时间的 70% 都消耗在 rollout 阶段,超过了 backpropagation 和参数更新的总成本。
- 同步屏障:所有 rollout 都必须完成,训练才能继续。一次缓慢生成会阻塞整个 batch。
- 长度增长:现代推理模型会生成越来越长的思维链,加剧长尾效应。
- GPU 空闲时间:当落后任务仍在运行时,其他 GPU 会处于空闲状态——每次训练运行都会浪费数千美元的计算资源。
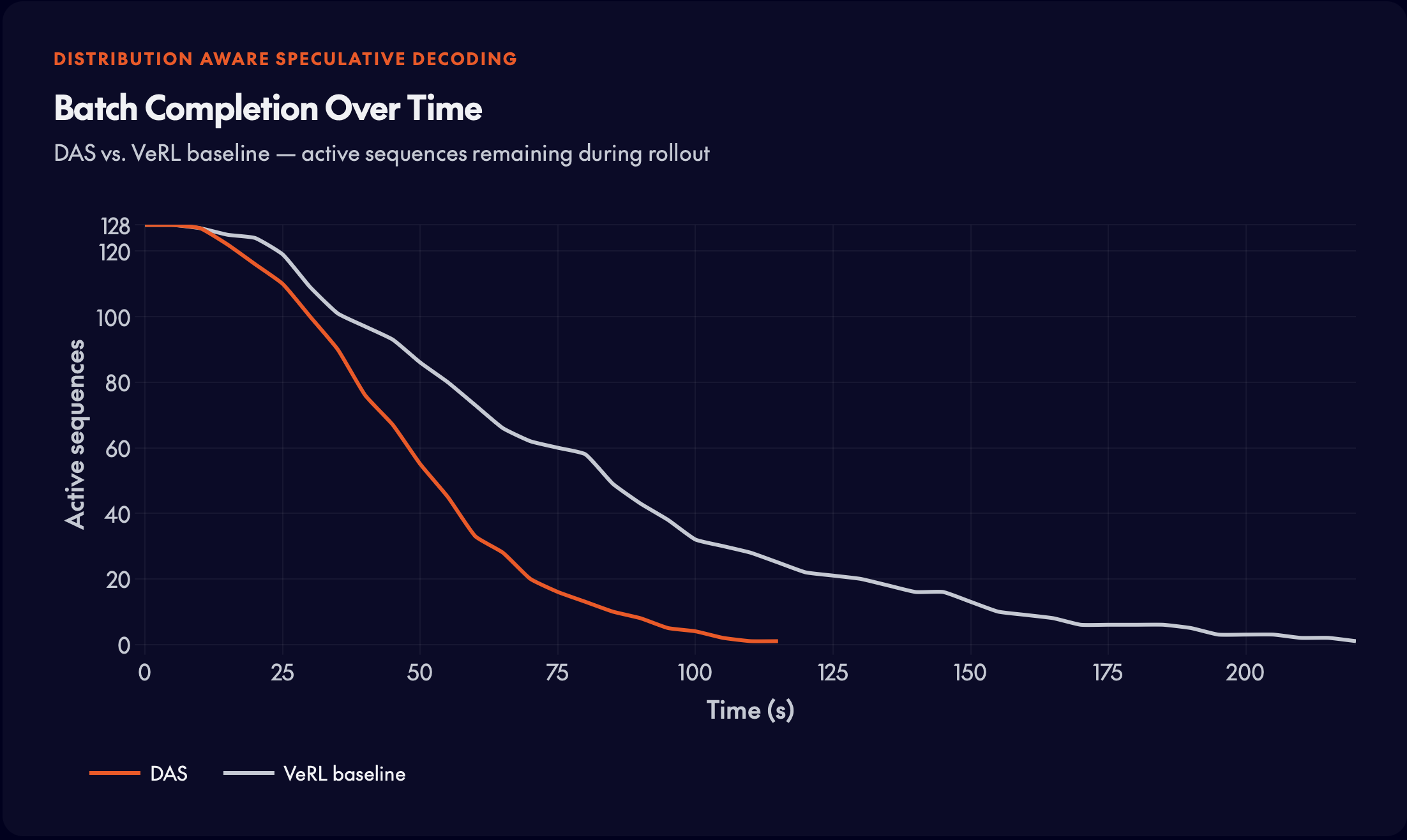
长尾问题的实际表现:大多数序列很早完成,但少数落后任务迫使整个 batch 等待,直到最慢的生成完成,GPU 在此期间保持空闲。
关键洞察
RL 后训练中的 rollout 阶段有三个结构性特征,使其不同于标准 LLM serving workload。这些特征推动了 DAS 的核心设计选择。
- 长尾 rollout 导致 GPU 利用率不足: RL rollout 遵循长尾分布:大多数生成很快完成,而少数会产生极长的 trajectory。由于训练 step 必须等待所有 rollout 完成,这些长序列会成为决定 step latency 的落后任务。随着较短请求提前完成,GPU 进入空闲状态,造成严重的硬件利用不足。
- 历史 trajectory 信号: 与 serving(唯一请求)不同,RL 训练会在多个 epoch 中反复访问相同 prompt,从而形成可利用的丰富既往生成历史。
- 不断演化的模型权重: 模型在每次 optimizer step 后都会变化。基于早期 checkpoint 训练的静态 drafter 会很快与当前 policy 失配。
DAS 框架
上述每个特征都对应一个设计需求:
- 一个无需 retraining 也能保持最新的 drafter
- 一个能够消除落后任务影响的 scheduler,以及
- 一个利用 RL 特有的 prompt reuse 的系统。
DAS 通过两个紧密集成的组件解决这三个问题。第一个是 adaptive suffix tree drafter,可加速生成,并在较长训练周期内平稳扩展。第二个是 length-aware scheduling 策略,通过跨 GPU load balancing 和 GPU 内 speculation budget allocation 来减少 rollout 落后任务。
Adaptive suffix tree drafter
为什么使用 suffix tree?
随着 policy 在 RL 训练过程中不断演化,静态 drafter 会迅速过期。因此,DAS 使用一种由近期 rollout 构建的 training-free drafter,使其无需任何 gradient update 就能持续适应变化中的 policy。
工作方式
DAS 从近期 trajectory 的 sliding window 构建 suffix tree。在 decoding 期间,它会在当前 context 与索引历史之间寻找 prefix match。随后,候选 next token 会根据其在匹配 subtree 中的 出现频率进行 scoring,得分最高的 token 被选为 speculative draft。
为什么适合 RL rollout
draft 序列由 target model 并行验证,新验证的 token 会立即插入回树中,使 drafter 始终与 最新 policy 保持同步。由于 RL rollout 往往包含很强的 trajectory reuse,这种 nonparametric 设计可以有效利用重复 prefix,而无需单独的 neural drafter。
可扩展性
Suffix tree 在 rollout 前构建,并在每个 training step 后释放,因此内存不会随长训练周期累积。树的构建和清理按问题并行化,并与 actor update 重叠执行,使 actor update latency 的波动 低于 5%,同时将开销排除在 critical path 之外。
Length-aware scheduling
跨 GPU balancing
DAS 会 在各个 rank 之间交错分配长请求。这可以防止长生成集中在某个 worker 上,并减少 rollout 落后任务。
对长请求提前 speculation
DAS 会从 rollout 一开始 就对长请求应用 speculative decoding。rollout latency 主要由少数进入后期阶段的长尾落后任务主导,而后期 decoding 会变成 small-batch,并且强烈受 memory-bound 限制。提前在这些请求上投入额外计算是值得的——它避免了代价高昂的后期模型 forward,并缩短 rollout 尾部。
GPU 内 budget allocation
在每个 GPU 内,请求会根据历史 rollout 统计动态划分为 Long、Medium 和 Short 类别。长请求获得激进的 speculative decoding budget,中等请求使用适中的 budget,短请求则 完全跳过 speculation,以避免在无法减少模型 forward pass 的场景中浪费计算。这一分类策略会在运行时动态更新。
这个设计简单到几段话就能说明。结果验证了它的有效性。
实验结果
DAS 在两个 RL 后训练任务上进行了评估:数学推理和代码生成。在这两种情况下,关键指标都是在不降低 reward quality 的前提下降低 rollout 时间。
Math RL — DeepSeek-R1-Distill-Qwen-7B
DSR-sub dataset(1,209 个样本)。DAS 实现了超过 50% 的 rollout 时间减少,同时 reward curve 与 baseline 完全一致。
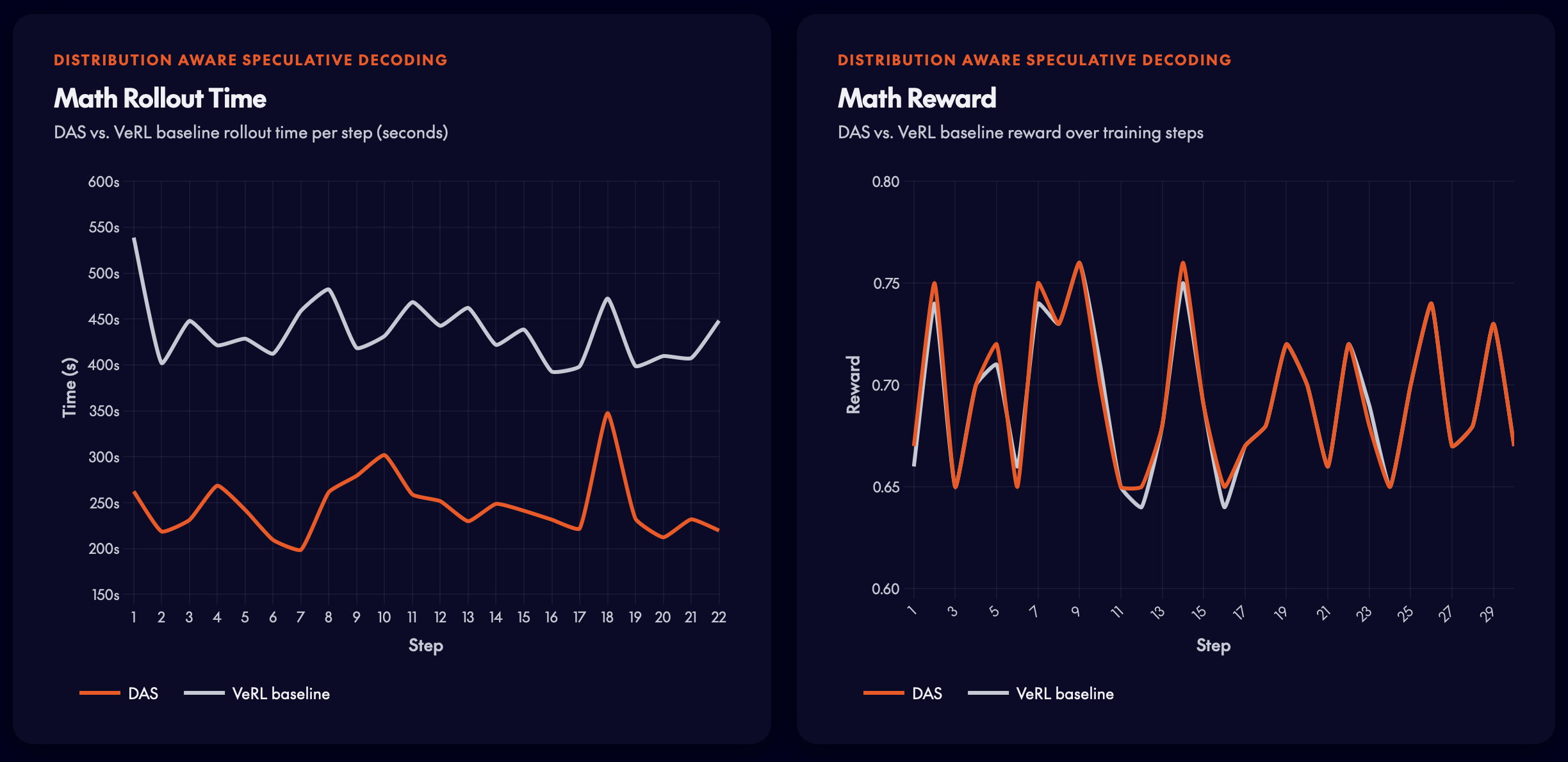
在 DSR-sub(1,209 个样本)上,rollout 时间减少超过 50%,且与 baseline reward curve 没有偏离——训练信号被完整保留。
Code RL — Qwen3-8B
Unit-test reward signals。DAS 在保持 reward quality 的同时,实现约 25% 的 rollout 时间减少。
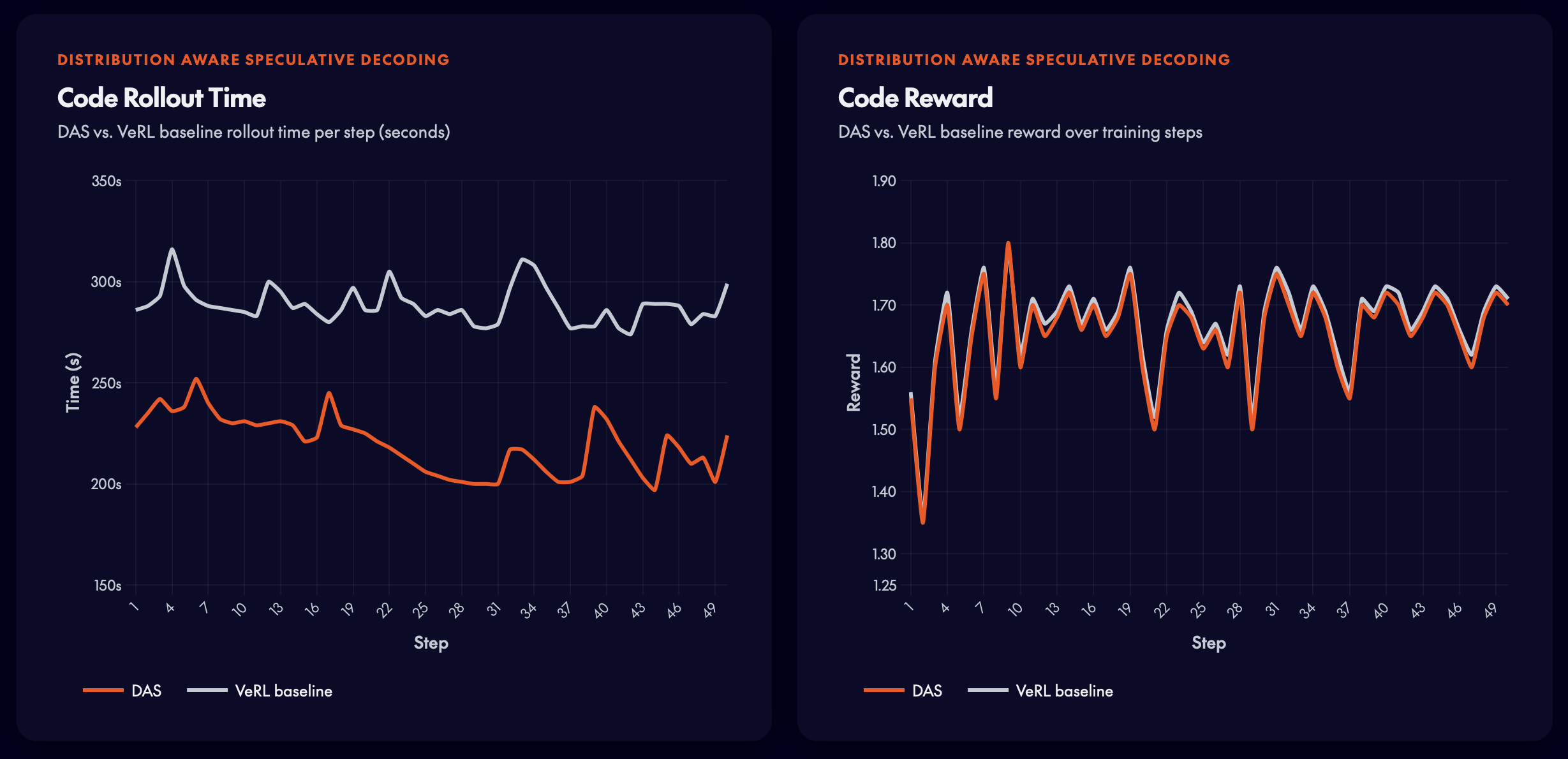
在 unit-test reward signals 上,rollout 时间减少约 25%。reward quality 在整个过程中与 baseline 保持一致,确认 DAS 不会干扰 policy learning。
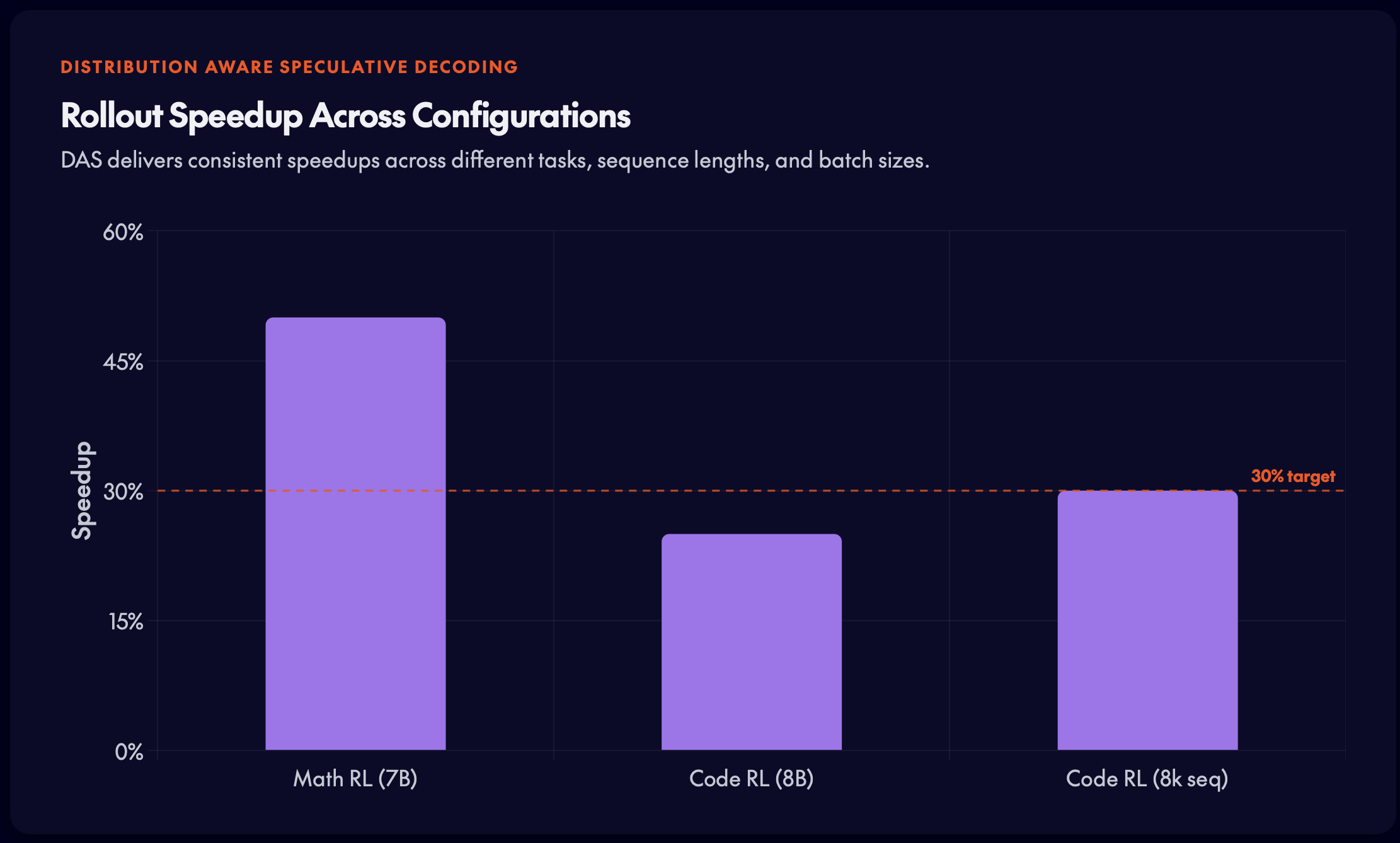
DAS 在不同 sequence length(8k–16k)和 batch size(16–32)下都保持加速优势,表明收益并不依赖单一运行点。
为什么这很重要
DAS 同时具备三种很少同时出现的特性:
- 无损加速: DAS 保持分布不变——输出与标准 decoding 完全相同,training curve 完全相同。
- 跨配置稳健: 在 sequence length(8k–16k)和 batch size(16–32)范围内均能保持加速。
- 零成本适应: suffix tree drafter 从 rollout history 中自我演化。无需 gradient update,无需维护。
随着 AI 社区推动使用 RL 在越来越复杂的任务上训练更大模型,rollout 瓶颈只会变得更加严重。对于大规模运行 RL 后训练的实践者而言,DAS 提供了一条有吸引力的路径:在不降低模型质量的情况下,将计算成本最高降低 50%——这在资源受限的大规模 AI 训练中并不常见。
阅读 论文 了解更多信息。

8S
DeepSeek R1

具备原生音频和逼真物理效果的高质量电影级视频生成。
DeepSeek R1
8S
音频名称
音频描述
0:00
具备原生音频和逼真物理效果的高质量电影级视频生成。
8S
DeepSeek R1
具备原生音频和逼真物理效果的高质量电影级视频生成。
性能与规模
正文副本放在这里 lorem ipsum dolor sit amet
- 要点放在这里 lorem ipsum
- 要点放在这里 lorem ipsum
- 要点放在这里 lorem ipsum
基础设施
最适合
更快的处理速度(更低的整体 query latency)和更低的运营成本
执行定义清晰、直接的任务
Function calling、JSON mode 或其他结构良好的任务
列表项 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
列表项 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
逐步思考,并且只将最终答案放在标签 和 内。按以下规则组织你的推理:推理时,只能用阿拉伯语回答,不允许使用其他语言。 问题如下:
Natalia 在 4 月把夹子卖给了她的 48 个朋友,然后她在 5 月卖出的夹子数量是 4 月的一半。Natalia 在 4 月和 5 月一共卖出了多少个夹子?
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet
8S
DeepSeek R1
具备原生音频和逼真物理效果的高质量电影级视频生成。
DeepSeek R1
8S
音频名称
音频描述
0:00
具备原生音频和逼真物理效果的高质量电影级视频生成。
8S
DeepSeek R1
具备原生音频和逼真物理效果的高质量电影级视频生成。
性能与规模
正文副本放在这里 lorem ipsum dolor sit amet
- 要点放在这里 lorem ipsum
- 要点放在这里 lorem ipsum
- 要点放在这里 lorem ipsum
基础设施
最适合
更快的处理速度(更低的整体 query latency)和更低的运营成本
执行定义清晰、直接的任务
Function calling、JSON mode 或其他结构良好的任务
列表项 #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
列表项 #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
Build
包含的权益:
✔ 最高 $15K 免费平台 credits*
✔ 3 小时免费 forward-deployed engineering 时间。
Funding:低于 $5M
逐步思考,并且只将最终答案放在标签 和 内。按以下规则组织你的推理:推理时,只能用阿拉伯语回答,不允许使用其他语言。 问题如下:
Natalia 在 4 月把夹子卖给了她的 48 个朋友,然后她在 5 月卖出的夹子数量是 4 月的一半。Natalia 在 4 月和 5 月一共卖出了多少个夹子?
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet
XX
标题
正文副本放在这里 lorem ipsum dolor sit amet