高效推理MiniMax-M3:解锁百万Token上下文与多模态无憾
Serving MiniMax-M3 for efficient inference: Unlocking 1M-Token Context and Multimodality Without Regrets
MiniMax发布旗舰模型M3,Together AI作为首选云合作伙伴负责其大规模生产部署。M3采用MiniMax稀疏注意力(MSA)架构,支持100万token上下文窗口、原生多模态能力及智能体工作流。Together AI通过KV-块-主序稀疏注意力、MSA与分页注意力集成、解码索引评分内核优化及网关多模态预处理等技术,在B200上实现81%至125%的推理性能提升,预填充阶段速度提升超9倍,解码阶段超15倍。
MiniMax 发布了其最新的顶尖模型 M3,Together AI 很高兴成为其首选云合作伙伴,助力 MiniMax 高效地将 M3 投入大规模生产。待 MiniMax M3 在未来几天内以开放权重模型的形式发布后,Together AI 也将直接为开发者提供该模型的端点服务。在这大规模部署的背后,是我们推理与内核团队的卓越工作,他们进行了深度性能优化,并为一款突破边界的模型确保了生产级可靠性:该模型拥有 100 万 token 的上下文窗口、原生多模态能力,以及需要扎实工程功底才能高效服务的架构。在本文中,我们将详细介绍实现过程。祝贺 MiniMax 团队成功发布这款里程碑式的模型并持续创新。
MiniMax M3 是一款全能模型,集顶尖的编码性能、智能体工作流支持以及原生多模态推理于一身。在这些能力之上,它还设计支持 100 万上下文,同时服务成本极具经济性。这使得它非常适合处理那些长文档、代码库、工具调用、图像和迭代推理常常同时出现且上下文繁重的实际任务。与上一代相比,服务 M3 带来了更多挑战,因为新能力需要在更多维度上进行优化,包括稀疏注意力计算、更大的 KV 缓存管理、多模态处理等。
架构 / 特性
M3 最具创新性的架构变化是 MiniMax 稀疏注意力(MSA),它旨在解决 MiniMax M2.7 中出现的注意力计算瓶颈。其块稀疏注意力机制限制了每个查询可以关注的 token 最大数量,从而降低了长上下文处理的成本,并使更长的上下文窗口变得实用。这带来了预填充阶段超过 9 倍、解码阶段超过 15 倍的速度提升。
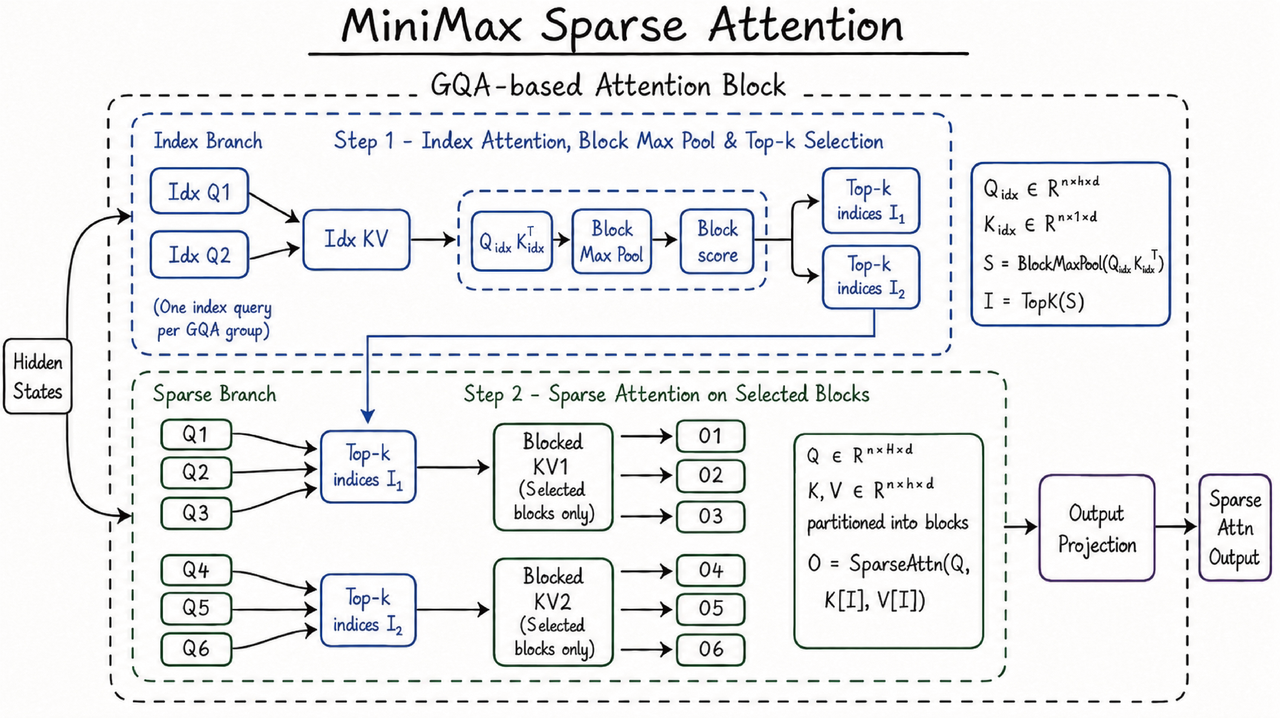
本质上,MSA 的计算由两部分组成:首先进行分数计算,以确定为每个 KV 组最相关的 K 个块;然后在查询 token 与这些块之间进行密集注意力计算。这种设计在 KV 组维度上保留了表达能力,同时仍然限制了查询 token 关注的 KV token 最大数量。注意力计算本身不再随上下文长度呈 N^2 规模增长,因此非常适合长上下文工作负载。
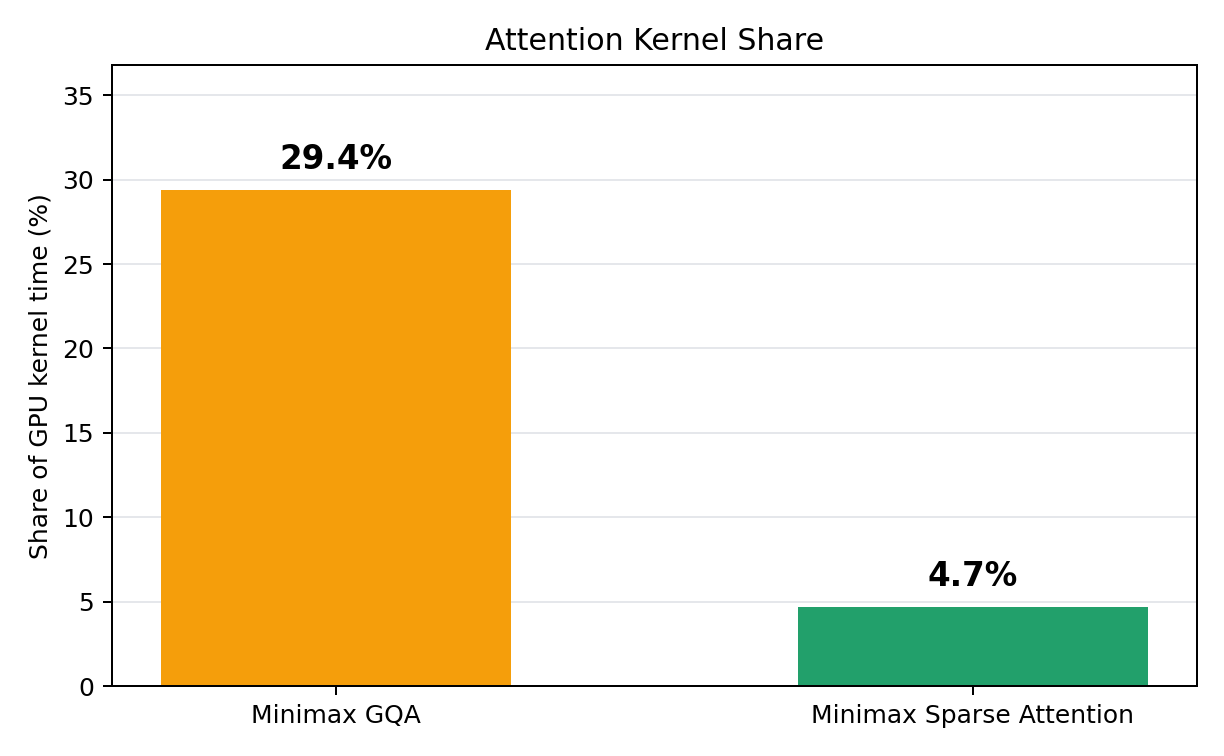
我们在 B200 上,以并发数 8 测量了在智能体风格流量(60K 前缀缓存)下的内核执行时间分解。MSA 显著降低了每次迭代中实际注意力计算所占的墙钟时间百分比。
除了注意力架构的变化,M3 还配备了多模态支持,包含视觉组件以及新的图像和视频预处理功能。
鉴于这些根本性的变化,Together AI 与 MiniMax 的工程团队紧密合作,以应对新出现的挑战。一些主要挑战包括:
- 尽管 MiniMax 稀疏注意力计算本身非常高效,但从工程角度来看,支持 100 万上下文长度仍然具有挑战性。
- 视频和图像处理本质上比文本 token 化更复杂。
优化
KV-块-主序 稀疏注意力
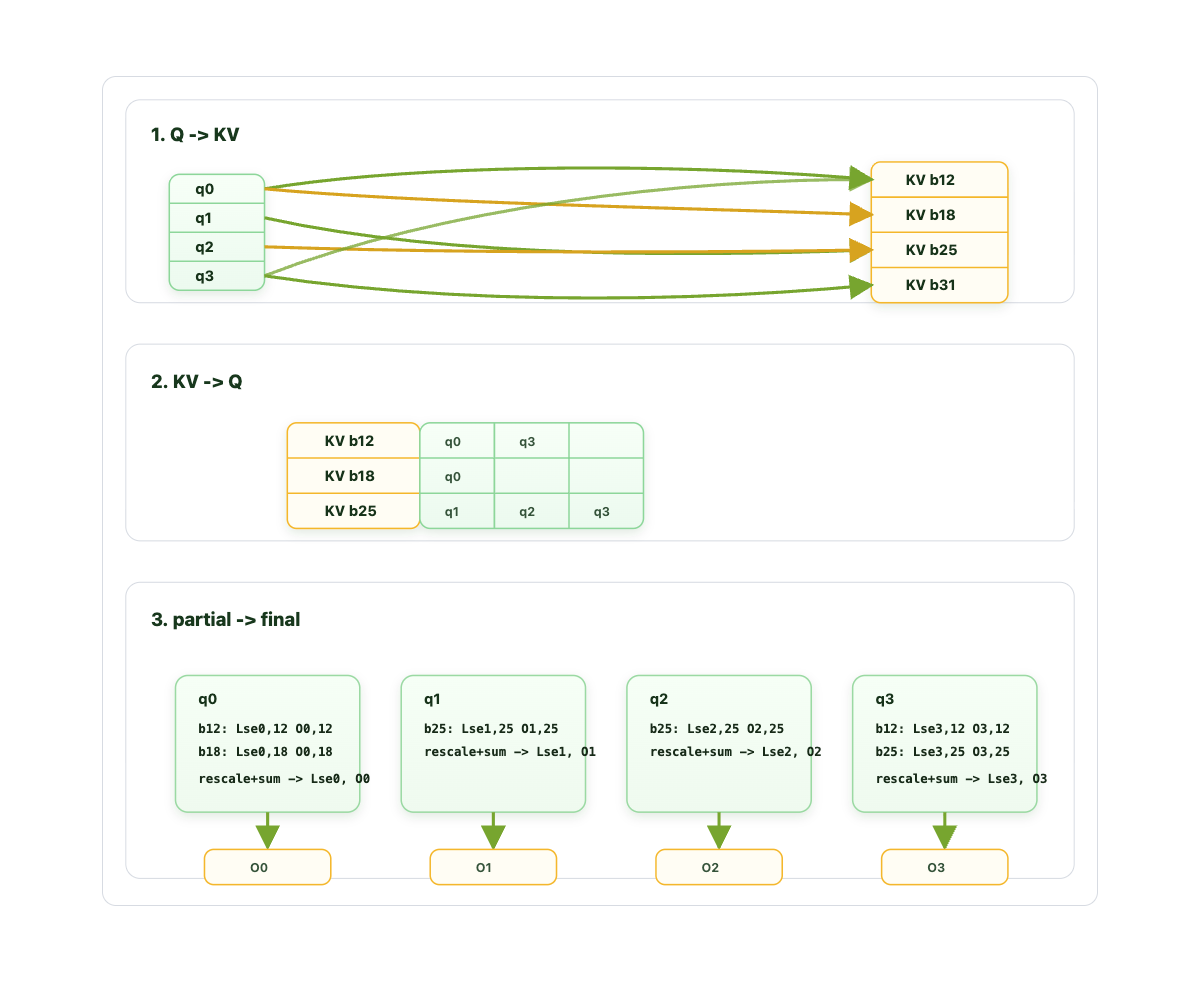
在预填充阶段,对于长上下文输入,注意力计算仍然是一个重要因素,因为对于每个 token,我们需要计算 选定块 * KV 头组 * token。块稀疏注意力的特性允许多个查询关注相同的键值块。因此,如果我们遍历每个查询来计算与键值块的注意力,就会重复将 KV 从 GPU 的 HBM 搬运到 SRAM。在外层循环中遍历键值组,并在内层循环中计算查询 token 之间的注意力,可以实现更好的算术强度,因为 KV 缓存只需移动一次。
为了实现这一点,我们需要重新组织从 {q, kv block} 到 {kv block, q} 的映射,并重新实现注意力内核。由于我们只为 kv 块计算部分 O 输出,因此需要基于 Log-Sum-Exp 进行最终的“归约”来重新缩放输出 O 并求和。过程如下:
将 MSA 与分页注意力集成
在现代推理引擎中,分页注意力通常用于管理请求的 KV 缓存上下文。大多数高度优化的注意力内核都支持一组固定的页面大小。阻止我们使用这些内核的障碍在于,不同 KV 组选定的块是不同的。
在 Together AI,我们提出了一种将 MiniMax 稀疏注意力集成到引擎中的新方法。在解码过程中,我们首先根据选定的块构建一个页表,将 KV 组维度展平到批次维度中,并利用 KV 缓存张量的步长视图,为注意力内核提供检索 KV 页面所需的指针。关键在于步长:页面地址按 D 前进以选择虚拟页面起始位置,而 token 按 Hkv * D 前进。这会将一个物理张量解交织成每个头的页面,因此每个展平后的行现在可以使用不同的页表。
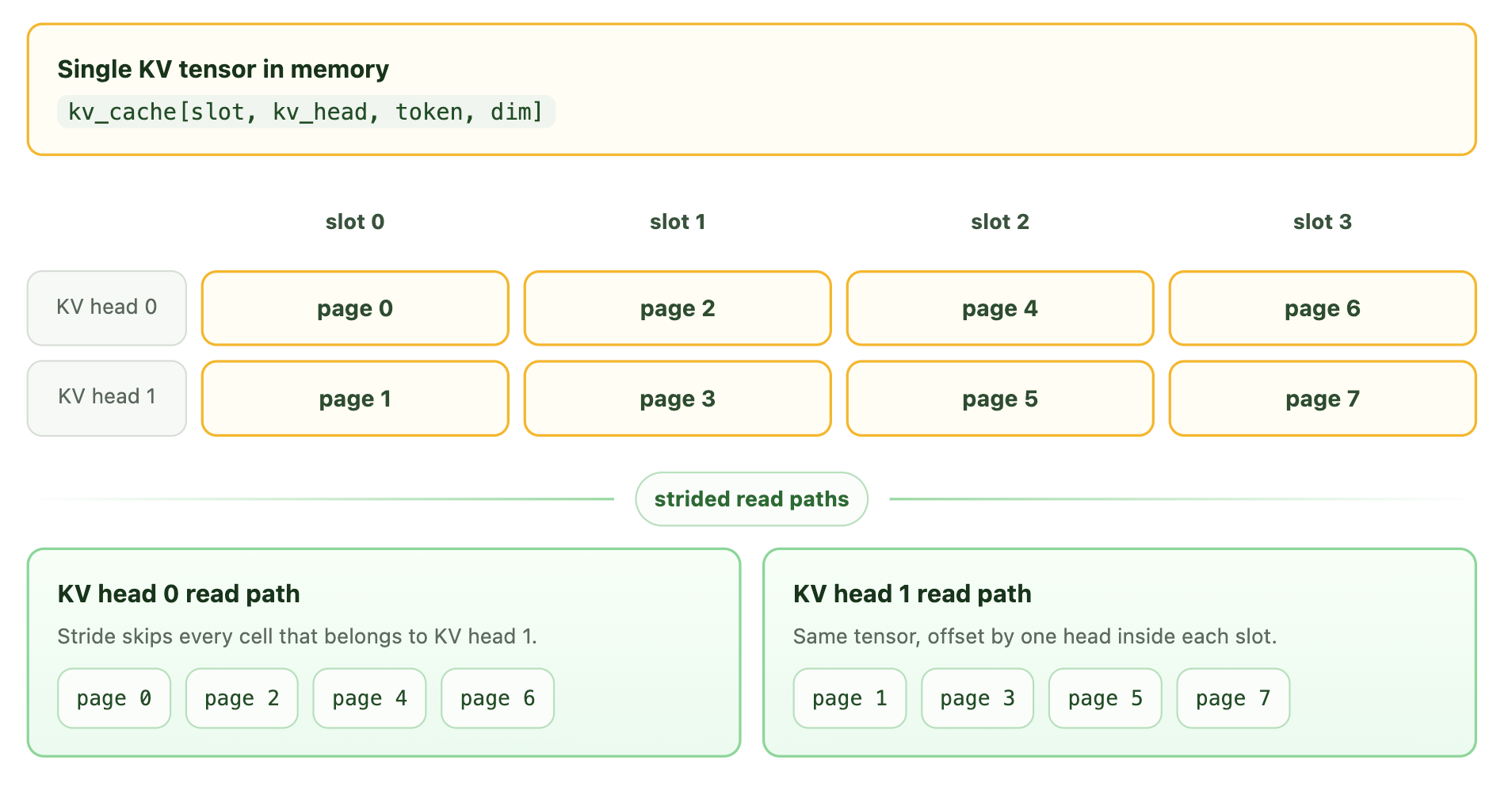
这种设计使我们能够使用现有的支持 GQA 的注意力内核,而无需从头重写一个支持稀疏注意力的新内核。由于每个查询选定的块是有限的,用于查找块到页面映射的内核开销非常低。这种设计使我们的解码吞吐量提升了 5%。
解码索引评分内核优化
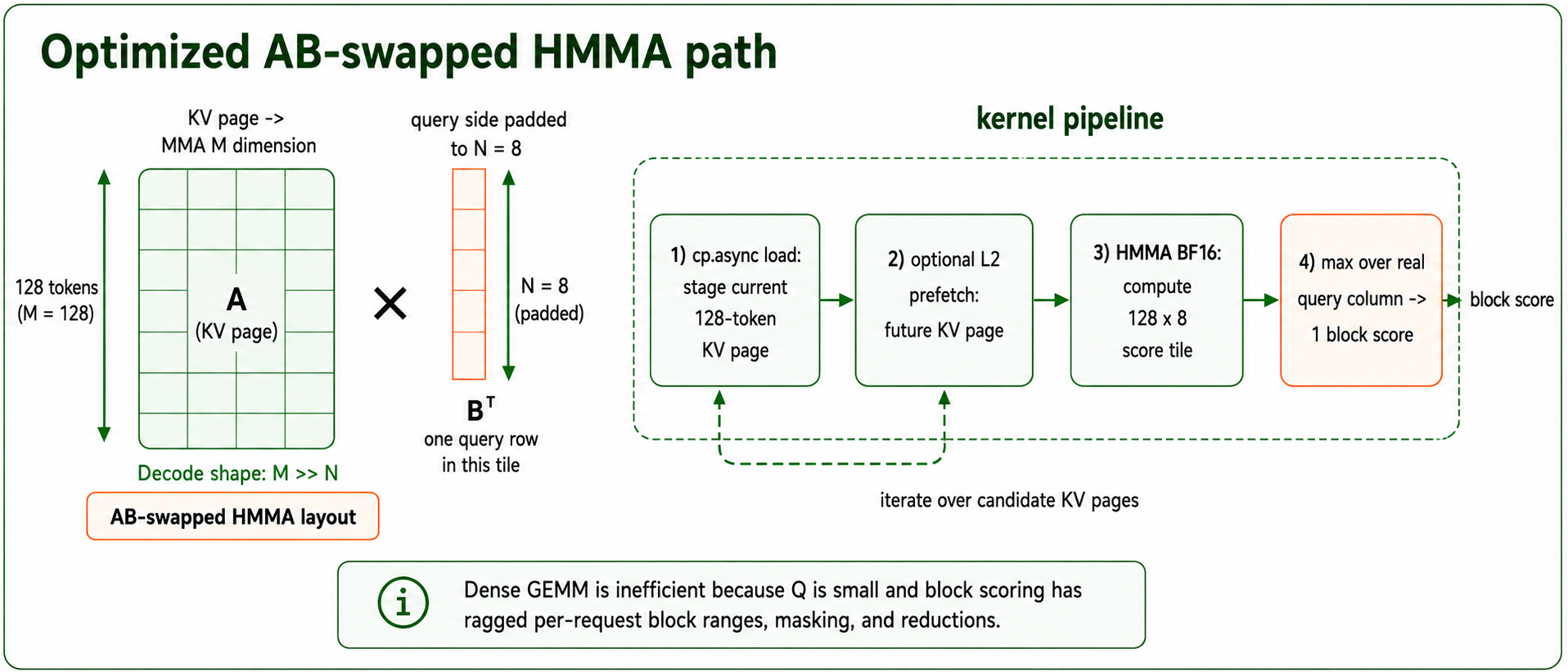
对于解码,MSA 将大部分成本从密集注意力转移到了评分/top-k 索引器上。对于每个解码查询,引擎将查询侧的索引向量与候选的键侧索引向量进行比较,将每个 128 token 的 KV 块归约为一个分数,并只为真正的注意力内核保留 top 块。这个扫描过程位于每个生成 token 的关键路径上,并且在长上下文长度下,候选块的数量会随上下文长度增长。解码评分具有小查询索引、长键索引的特点。人们可能会倾向于将一批解码查询视为一个更大的 GEMM,但评分/索引步骤不仅仅是密集矩阵乘法:每个请求和 K 组都有自己的候选块范围、掩码、逐块归约和 top-k 边界。将查询拼接在一起仍然会在 GEMM 周围留下一个参差不齐的收集和归约问题,同时迫使在关键路径上进行填充和额外的簿记工作。因此,我们的优化路径采用了一种 AB 交换的 HMMA 布局:128 token 的键索引块成为 MMA 的 M 维度,而查询侧仅填充到较小的 N 维度。内核使用异步拷贝来预取 128 token 的 K 索引,预取下一页,使用 HMMA 以 bfloat16 计算点积,并将每个页面归约为一个块分数。
网关处的多模态预处理
SMG(服务模型网关)是一个基于 Rust 的模型网关,位于兼容 OpenAI 的 API 和推理引擎之间。除了路由和 token 化之外,SMG 还承担了一项对多模态模型尤其重要的角色:它在请求到达 GPU 工作节点之前,在 CPU 上执行所有视觉预处理。
图像和视频输入在变得对视觉编码器有用之前,需要大量的 CPU 工作:下载、解码、帧采样、调整大小以及转换为 patch 张量。在推理引擎内部执行这些操作会占用本应用于生成任务的资源。SMG 在网关处处理所有这些工作,因此当请求到达 GPU 时,张量已经准备就绪。
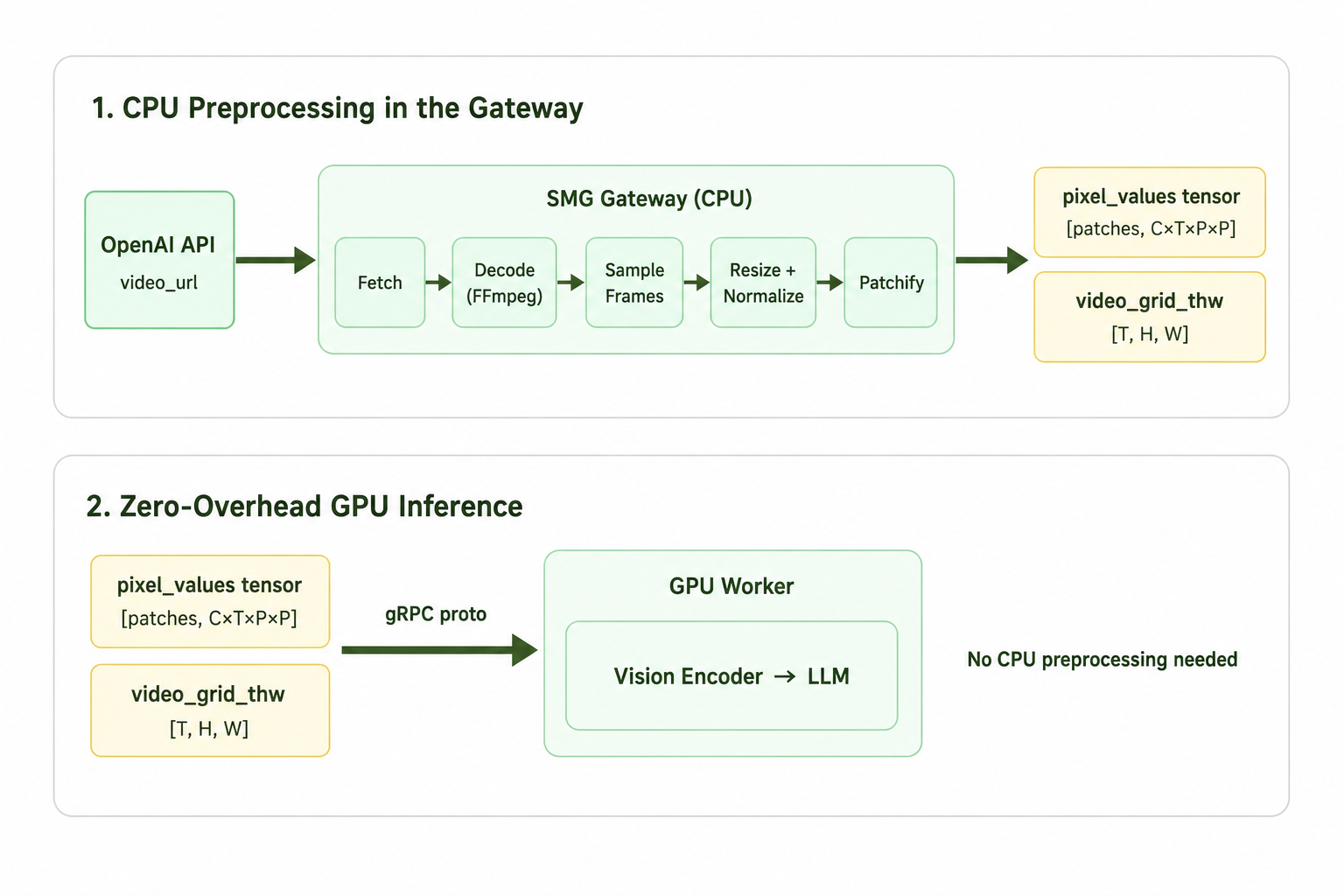
对于 M3,这意味着:获取视频,使用 FFmpeg 提取帧,根据 FPS(每秒帧数)选取子集,调整大小并归一化,然后结合时间维度进行 patch 化。输出的是一个扁平的 patch 张量和一个小的网格元数据张量,打包在 gRPC 消息中。工作节点只需直接运行视觉编码器——无需在其端进行任何预处理。
此外,SMG 的多模态流水线是围绕 Rust trait 构建的,这些 trait 将模型特定的预处理逻辑与流水线框架分离开来。为 M3 添加多模态支持意味着使用 M3 特定的常量来实现这些 trait;流水线本身无需更改。同样的架构适用于大多数具有视觉能力的开源模型,并且可以跨推理引擎运行时通用。
性能结果
自收到 MiniMax M3 的权重和模型架构以来,我们一直致力于提升推理性能。在常见的智能体形状流量下,我们在各种并发级别上实现了 81% 到 125% 的性能提升。
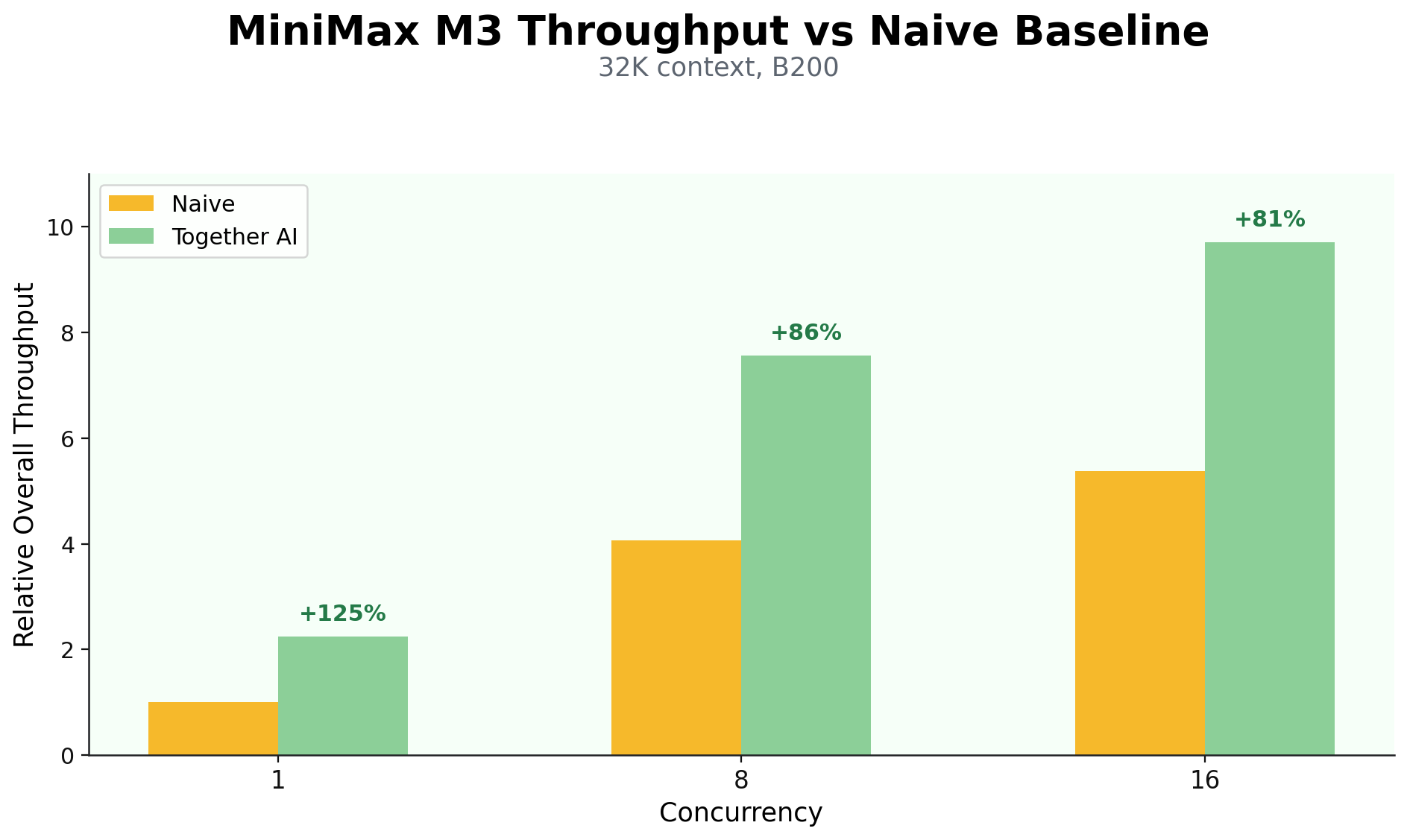
在具有 60K 前缀缓存、并发数 8 和 NVIDIA B200 的智能体风格流量下进行的单独内核执行分解显示,MSA 显著降低了每次迭代中注意力计算所占的墙钟时间百分比。
未来工作
新的架构带来了新的基础设施和工程挑战。在 Together AI,我们的目标是提供最佳的推理性能。关于 M3,我们正在积极研究的几个主题包括:
- 稀疏注意力架构引入了更多较小的内核,例如,对 kv 块进行 topk 操作、将 q-kv 映射重新映射为 kv-q 等。存在更多内核融合的机会。我们的内核代理研究团队正在积极开发能够编写生产级内核的智能体。
- 现在可以对 k-index 和实际 kv 缓存进行 CPU 缓存卸载。我们正在努力加载完整的 k-index,并根据 topk 选择按需加载 kv 缓存。