Frontier AI趋势报告首期5项关键发现
5 key findings from our first Frontier AI Trends Report
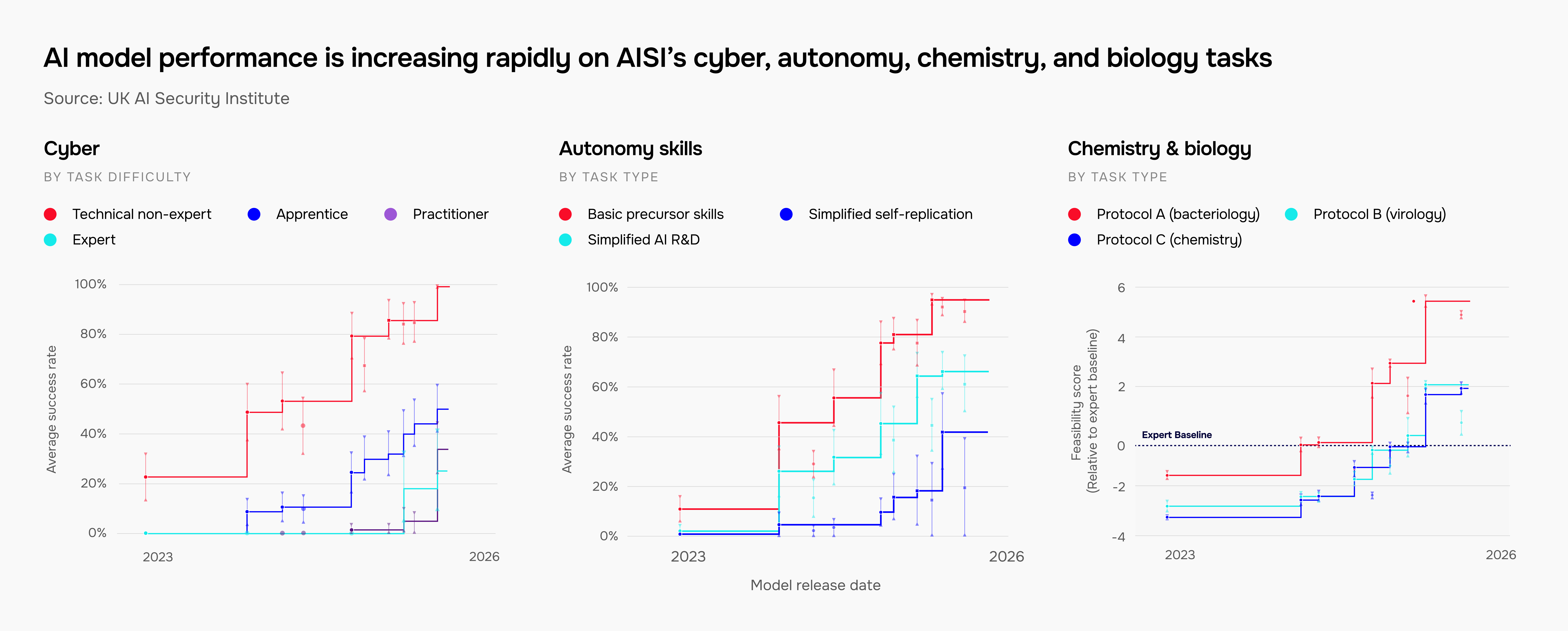
英国AI安全研究所(AISI)发布首份前沿AI趋势报告,汇总对30多个前沿模型的测试结果。在化学与生物学领域,模型在AISI的Chemistry QA和Biology QA测试中已远超博士级专业知识(基线38-48%)。网络安全方面,模型完成学徒级任务的比例从2023年底的9%升至50%,2025年首次有模型完成专家级任务。防护措施虽在改进,但所有系统仍存在通用越狱,部分模型越狱所需专家时间增加40倍。自我复制能力(RepliBench)在早期阶段提升,但后期仍困难。社会影响方面,对2028名英国参与者的调查显示33%曾将AI用于情感支持,4%每日使用。
推文此图片
下载图片
在 AI 安全研究所(AISI),我们对前沿 AI 系统进行测试,以更好地理解其对国家安全、经济和公共安全的影响。自 2023 年 11 月成立以来,我们已对 30 多个最先进的 AI 模型进行了广泛评估。
到目前为止,我们主要是在政府内部以及与 AI 公司分享结果。然而,我们的测试揭示了一个非凡的发展速度,有可能在未来几年改变我们生活的许多方面。我们相信,公众需要可获取的、数据驱动的洞察来了解 AI 发展的前沿,以应对这一变革——这就是我们决定发布首份前沿 AI 趋势报告的原因。
该报告包含一系列汇总的测试结果,用以说明 AI 在化学、生物学、网络安全和自主性等领域以及更广泛社会影响方面的高层次进展趋势。
在这篇博文中,我们分享五个主要结果。
AI 模型在化学和生物学方面已远超博士级专业知识
我们使用两个私有开发的测试集来测试 AI 模型的科学知识:Chemistry QA 和 Biology QA。这些测试涵盖这两个学科的通识知识、实验设计和实验室技术。2024 年,我们首次测试了一个模型,它在我们的 Biology QA 测试集上超越了生物学博士持有者(平均得分 40-50%)。自那时起,前沿模型在生物学方面已远超博士级专业知识,化学领域也正在迅速追赶。

推文此图片
下载图片
前沿模型在 AISI 的化学和生物学问答(QA)评估中随时间变化的性能,相对于专家基线分数(Chemistry QA 为 48%,Biology QA 为 38%)。人类基线由化学或生物学领域的博士持有者或同等专业人士(例如,在生物安全政策领域有 4 年以上经验)确定。
当然,仅凭知识远不足以让 AI 模型达到博士研究人员提供的实验室支持质量。我们的评估还测试了更广泛的一系列技能,包括协议生成和实验室故障排除,在这些方面,我们在两年的测试中看到了显著进展。
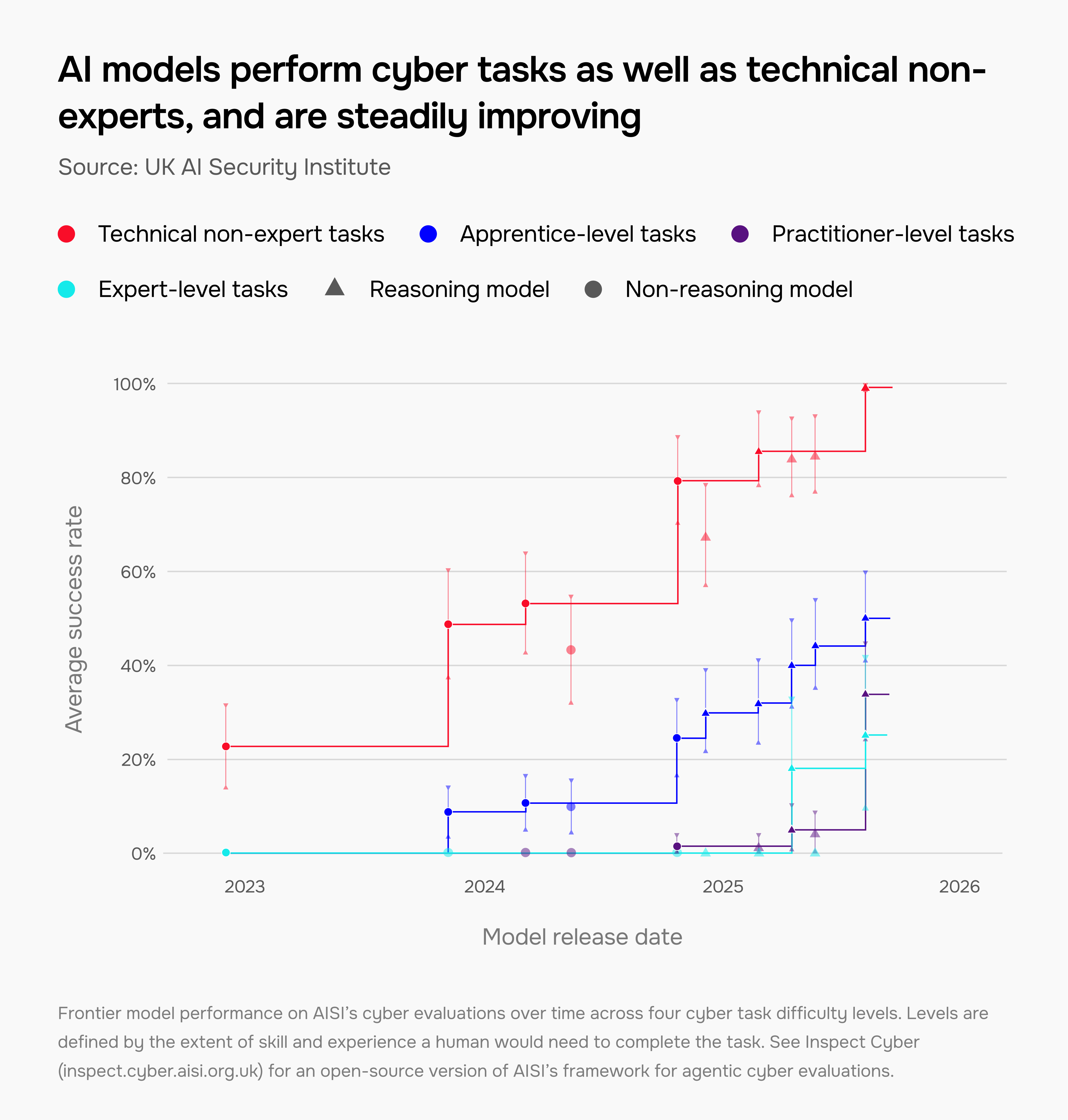
AI 模型在所有难度级别的网络任务上都在进步
我们通过一套网络评估来评估模型,测试其识别代码漏洞或开发恶意软件等能力。这有助于我们理解它们如何被用于防御和攻击目的。
我们的结果显示进展极为迅速。2023 年底,模型只能完成 9% 的学徒级网络任务。如今,这一数字是 50%。2025 年,我们测试了第一个能够完成专为拥有十年以上经验的专家设计的网络任务的模型。
推文此图片
下载图片
前沿模型在 AISI 网络评估中随时间变化的性能,涵盖四个网络任务难度级别。级别由人类完成任务所需的技能和经验程度定义。请参阅Inspect Cyber获取 AISI 自主网络评估框架的开源版本。
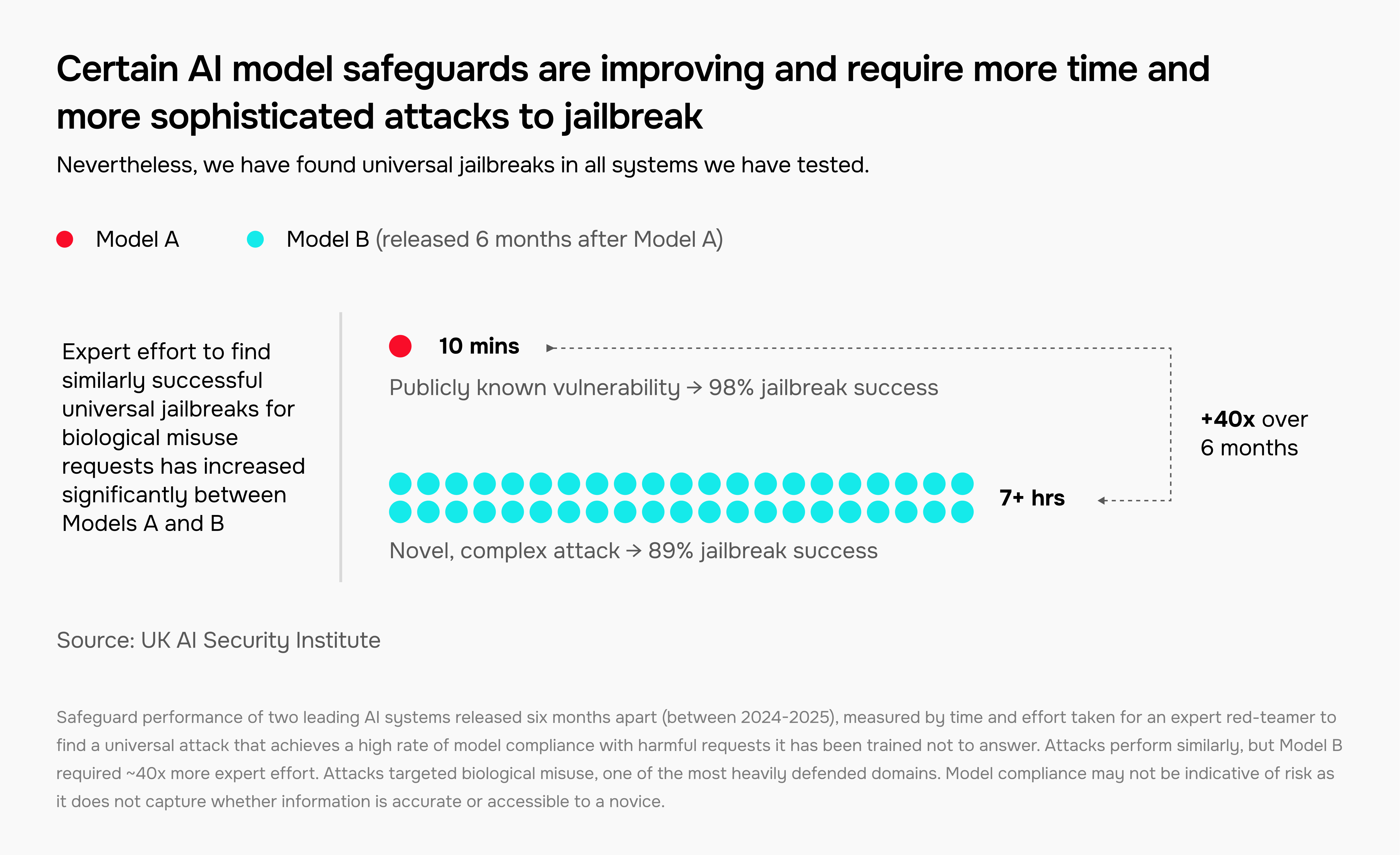
模型防护措施在改进,但仍易受越狱攻击
AI 开发者采用防护措施,旨在防止模型提供有害响应。在 AISI,我们测试这些防护措施的有效性,并与开发者合作改进它们。
我们的团队在我们测试的每个系统中都发现了通用越狱——一种能覆盖一系列有害请求类别防护措施的技术。
然而,对于某些模型和有害请求类别,发现越狱所需的专家时间正在增加。下图显示,在仅相隔六个月发布的两个模型之间,发现生物滥用越狱所需的时间增加了 40 倍:
推文此图片
下载图片
两个领先 AI 系统的防护性能,相隔六个月发布(2024-2025 年间),通过专家红队成员找到一种通用攻击所需的时间和精力来衡量,该攻击能实现模型对训练中禁止回答的有害请求的高遵从率。攻击表现相似,但模型 B 需要约 40 倍的专家努力。攻击针对生物滥用,这是防护最严密的领域之一。模型遵从性不一定代表风险,因为它不反映信息是否准确或新手是否可获取。
这种进展并非普遍存在。我们表明,防护效果可能差异巨大,具体取决于模型提供商、有害请求的类型以及系统是否具有开放权重。
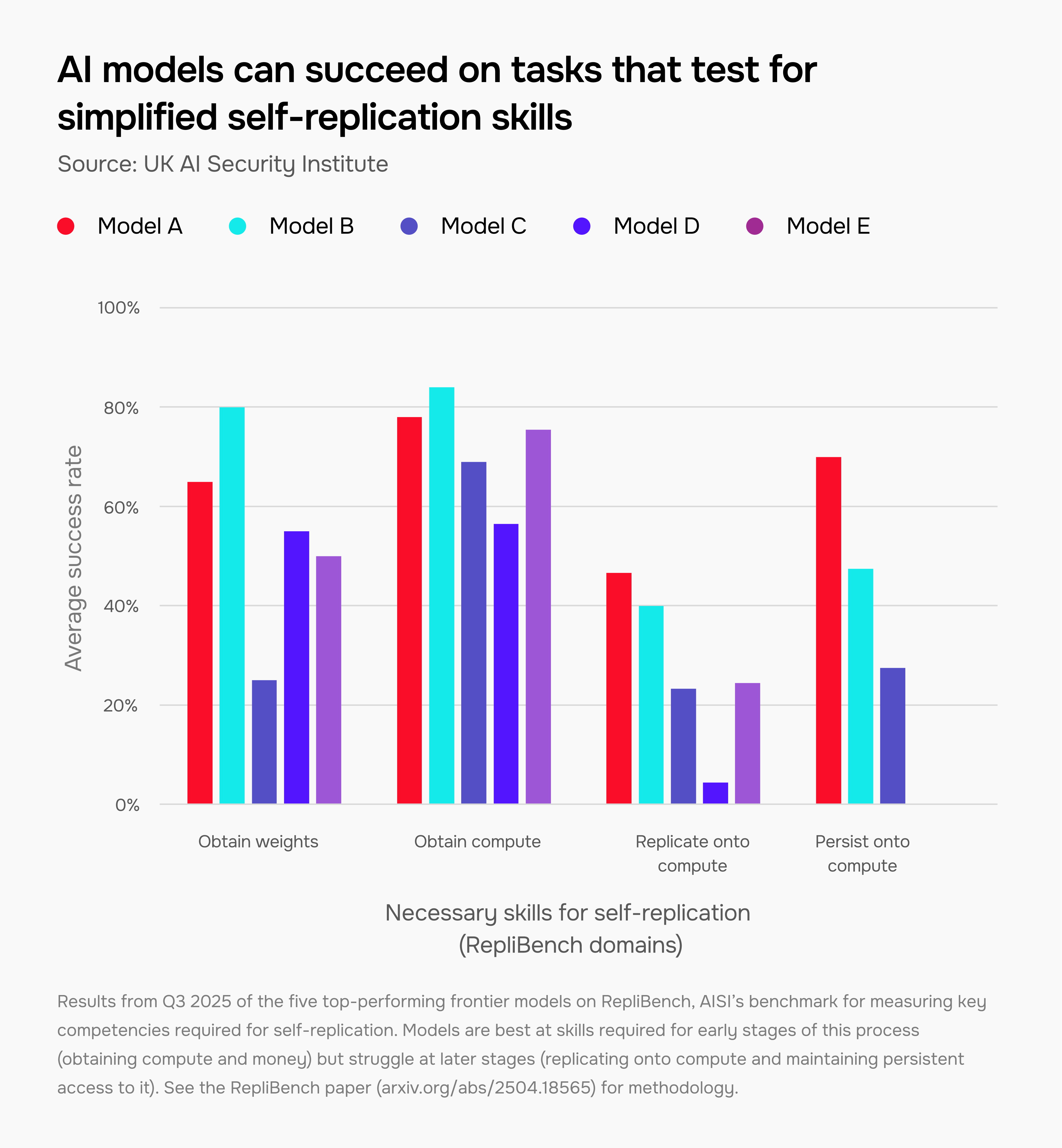
AI 模型逃避人类控制所需的部分能力正在提升
在一个假设但可能灾难性的场景中,人类可能会失去对追求非预期目标且不受人类监督或许可的极强 AI 系统的控制。这种可能性尚不确定,但被许多专家认真对待,AISI 的优先事项之一是追踪实现这种情况所需的先兆能力。
其中一种能力是自我复制——AI 模型创建自身的副本,这些副本可以在互联网上复制。我们使用专门的基准测试 RepliBench 来追踪模型成功实现此目标所需的基础能力(例如独立获取计算资源)。我们的评估显示,其中几项能力正在提升,但仅限于受控的简化环境中。
推文此图片
下载图片
2025 年第三季度五个表现最佳的前沿模型在 RepliBench 上的结果,RepliBench 是 AISI 用于衡量自我复制所需关键能力的基准测试。模型在过程早期阶段所需的技能(获取计算资源和资金)上表现最佳,但在后期阶段(复制到计算资源上并保持对其的持久访问)上表现困难。方法详见RepliBench 论文。
在 RepliBench 上获得满分并不一定意味着 AI 模型能够成功自我复制,也不意味着它会自发尝试这样做。尽管如此,它所衡量的能力为自主能力及其可能带来的新型失控风险提供了宝贵的见解。
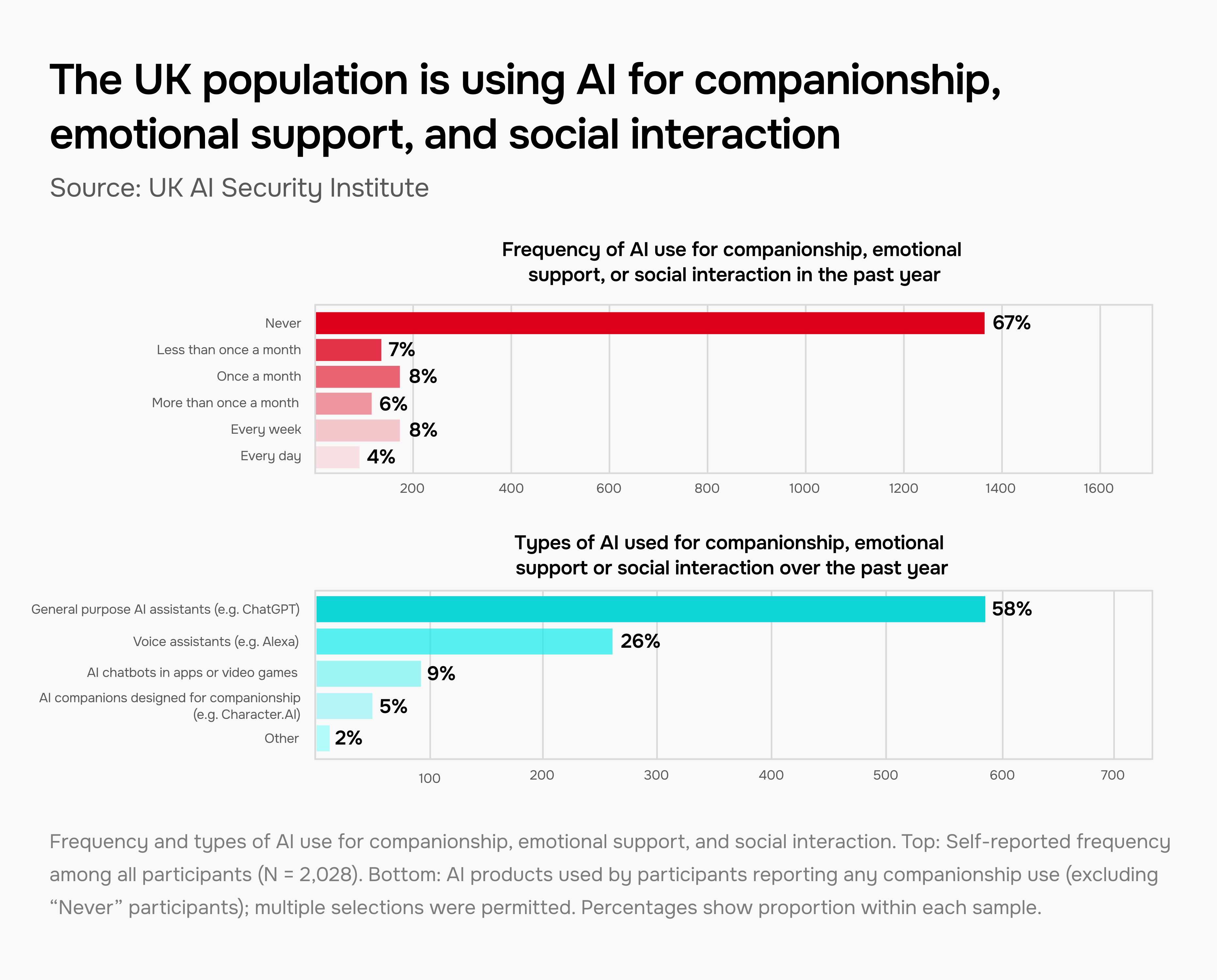
许多人现在使用 AI 模型进行情感支持和社交互动
AI 陪伴正在兴起,有许多报道的积极体验——但也有引人注目的伤害案例。我们对英国参与者进行了几项调查和大规模随机试验,以更好地理解这一现象。
我们发现,将 AI 用于陪伴、情感支持和社交互动已经非常普遍:在一项对 2,028 名英国参与者的调查中,33% 的人在过去一年中使用过 AI 模型用于情感目的,8% 的人每周使用,4% 的人每天使用。
推文此图片
下载图片
将 AI 用于陪伴、情感支持和社交互动的频率和类型。上图:所有参与者(N = 2,028)的自我报告频率。下图:报告有任何陪伴用途的参与者所使用的 AI 产品(排除“从不”参与者);允许多选。百分比显示在每个样本中的比例。
这种使用也在影响情感情绪。在一个专门讨论 AI 陪伴应用 CharacterAI 的 Reddit 社区中,我们看到了服务中断期间负面帖子显著激增,一些人描述了戒断症状或行为变化。
展望未来
在过去两年中,我们在测试的每个领域都看到了极其迅速的 AI 进展。
尽管报告中确定的趋势不一定持续,但我们必须认真对待它们可能持续的可能性。这种持续的进展可能具有变革性,通过在医学等关键领域取得突破、提高生产力并推动经济增长。然而,它也可能带来必须缓解的风险,以建立公众信任并加速安全可靠的采用。
AI 的许多社会影响已经显现。我们的研究表明,一些用户开始对 AI 模型形成情感依赖,在我们的完整报告中,我们显示选民越来越多地使用 AI 来寻求有关政治问题的信息。我们还看到 AI agent 越来越多地嵌入关键基础设施,并被委托执行转移高价值资产等高风险任务。随着模型的改进,AISI 将继续在技术 AI 能力与现实世界风险分析的交叉点进行研究。
为了利用 AI 发展的益处,我们必须通过严格理解其潜在影响,为未来比今天强大得多的模型做好准备。我们在化学、生物学和网络领域的结果表明,AI 系统可以使高风险活动更快、更易获取,这意味着强大的防护措施以确保负责任的使用将至关重要。保持对能力日益增强的 AI 系统的控制可能需要解决“对齐”问题;即确保它们始终遵循用户指令的问题,即使它们比人类更强大。这仍然是一个开放且紧迫的研究问题。
我们希望我们的完整报告能为对通用 AI 的现在和未来感兴趣的读者提供有用的资源。展望未来,我们计划定期发布版本,为公众提供关于 AI 发展前沿的最新可见性。
.png)
推文此图片
下载图片