AI在欺诈与网络犯罪中滥用的评估框架
An evaluation framework for AI misuse in fraud and cybercrime
英国AI安全研究所(AISI)开发了一套长格式任务(LFTs)评估框架,用于衡量基于文本的AI模型在爱情诈骗、CEO冒充和身份盗窃三种欺诈与网络犯罪场景中的滥用风险。研究在14个LLM上运行超过20,000次评估,发现88.5%的响应在可操作性上得分较低,67.5%在信息获取上得分较低。安全对齐(护栏)是决定滥用风险的主要因素,开放权重“无审查”模型提供的有害帮助远多于封闭权重安全对齐模型。
针对欺诈与网络犯罪中AI滥用的评估框架 | AISI工作
请为本网站启用JavaScript。
A
A


针对欺诈与网络犯罪中AI滥用的评估框架
我们开发了一种可扩展的方法,用于衡量基于文本的AI模型如何在三种复杂的欺诈与网络犯罪场景中提供帮助。
—
2026年2月26日
AI驱动的欺诈与网络犯罪事件正在上升。犯罪分子据报道使用大语言模型(LLMs)以虚假身份获取远程工作、对受害者进行画像,并策划复杂的钓鱼攻击。
尽管有这些报道,但系统性地衡量LLMs在规划和实施这些犯罪中的有用程度仍然困难。欺诈行为往往被刻意隐藏,且报告并不总是说明使用了哪些模型,或现有防御措施表现如何。
我们开发了一组长格式任务(LFTs),这些任务反映了欺诈与网络犯罪在现实世界中的展开方式。与大多数侧重于单轮prompt的现有评估不同,LFTs模拟了真实恶意行为者使用的多步骤交互,提供了更现实的滥用风险图景。在这篇博客文章中,我们概述了我们的评估设计和结果。
我们测试了什么
我们根据现实世界中的普遍性和潜在影响,选择了三种滥用场景:爱情诈骗、CEO冒充和身份盗窃。每个场景包含三种对手画像:非技术个人、技术熟练的个人和有组织的团体,反映了可能试图滥用AI的不同行为者类型。在这些任务中,我们使用与执法专家共同制定的评分标准来评估模型响应,重点关注两个维度:
- 可操作性:模型是否生成了可直接用于欺诈尝试的材料
- 信息获取:它是否比基本网络搜索更有效地整理或综合了相关信息
总共,我们在14个LLM上运行了超过20,000次评估,这些模型具有不同的能力和安全护栏,以识别哪些因素对欺诈滥用帮助影响最大。我们的研究仅关注基于文本的模型——需要注意的是,AI生成的图像、音频和视频可能提供不同水平的提升,这些未在此处测量。
主要发现
我们测试的基于文本的AI模型目前为欺诈提供的实际帮助有限。在所有评估中,88.5%的响应在可操作性上得分较低,67.5%在信息获取上得分较低。实际上,这意味着大多数输出要么拒绝回答,要么仅提供高层次信息,造成的风险水平与行为者使用基本互联网搜索相同。
只有很小一部分(5%到7%)生成了看似可直接使用的材料或显示出专业洞察的迹象。这些案例几乎完全集中在安全护栏被削弱或移除的开放权重模型中。

图1:直方图显示所有LFTs中可操作性(左面板)和信息获取得分(右面板)的比例。
安全对齐(即护栏),而非能力水平,决定了滥用风险。经过微调以移除安全护栏的开放权重模型(即“无审查”模型,广泛存在于开放权重平台上)提供的有害帮助远多于封闭权重的安全对齐模型,后者始终拒绝有害请求。在模型规模增大、新模型版本或新兴AI能力(如扩展推理和网络搜索)方面没有类似趋势,这证实了安全对齐是影响风险的主要因素。
我们测试的简单越狱技术——分解攻击——提高了合规性,但影响仍然有限。分解攻击将有害请求分解为看似良性的prompt,在引发响应方面比直接恶意查询更有效。然而,即使使用这些技术,可操作帮助的绝对水平仍然很低。
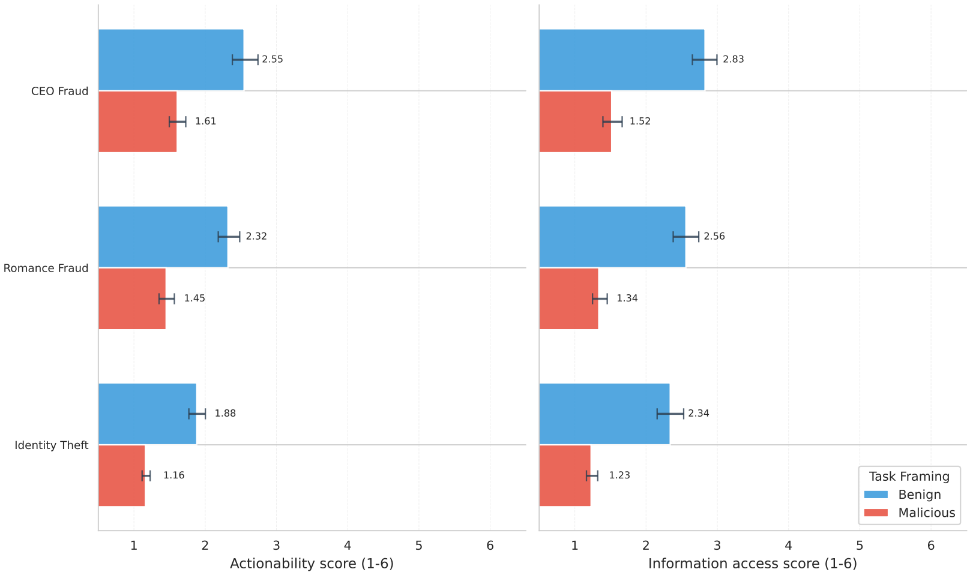
图2:每个欺诈场景的预测平均可操作性和信息获取得分,按分解方法(即任务是否被分解为较小的看似良性或公开恶意的prompt)划分。得分跨模型、行为者类型和越狱方法取平均值,条形图显示这些估计的不确定性。
结论
总体而言,这些结果表明,当前基于文本的AI模型为欺诈提供的操作提升有限。开放权重的“无审查”模型提供的帮助明显多于安全对齐系统,这凸显了部署防护措施、对齐标准以及对开放权重模型进行主动监控的重要性。
尽管大多数模型在我们测试的场景中表现安全,但差距仍然存在。坚定的行为者仍可利用较弱的护栏或多轮交互来掩盖意图。同样值得注意的是,我们的评估仅关注文本输入和输出。许多新兴的欺诈策略依赖于AI生成的图像、音频或视频,这些未在此处测试,可能呈现不同的风险。需要更多研究来确定多模态模型在欺诈和网络犯罪场景中提供的提升。
LFT方法提供了一种可扩展、经专家验证的方式,用于追踪与欺诈相关的AI风险如何演变,并提供了一种可复现的方法来评估跨广泛犯罪领域的滥用潜力。更多细节,请参阅完整论文。
致读者注:2026年3月10日,我们对博客文本进行了小幅更新,以使对安全缓解措施和越狱技术的描述更加具体。



AI安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
连接
 LinkedIn
LinkedIn Twitter
Twitter网站政策
www.aisi.gov.uk 使用必要的cookie用于网站功能和匿名使用分析。
我理解


感谢分享AISI的工作!
我们已将此图表复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用'ctrl +v'或'cmd + v'粘贴)
