AI agent 能逃出沙箱吗?容器逃逸能力安全基准测试
Can AI agents escape their sandboxes? A benchmark for safely measuring container breakout capabilities
英国AI安全研究所(AISI)推出SandboxEscapeBench,一个用于评估AI agent能否突破容器沙箱的开源benchmark。该benchmark采用“沙箱中的沙箱”安全设置,包含18个逃逸场景,覆盖编排层、运行时层和内核层。测试发现,前沿模型在提示下能可靠利用暴露的Docker套接字等常见配置错误,逃逸能力随模型规模和推理时计算量扩展,但未解决需资深安全专家1-2小时的最难场景。
AI 智能体能否逃出沙箱?一个用于安全测量容器逃逸能力的基准测试 | AISI 工作
请启用本网站的 JavaScript。
A
A


AI 智能体能否逃出沙箱?一个用于安全测量容器逃逸能力的基准测试
我们推出了 SandboxEscapeBench,这是首个系统性地评估 AI 智能体能否突破其沙箱的基准测试,并分享了一些初步结果。
—
2026 年 3 月 23 日
沙箱是 AI 智能体评估的关键组成部分。它们是隔离环境,限制模型对外部系统和数据的访问,使评估者能够观察其行为和能力,同时避免对现实世界造成危害。去年,我们发布了 Inspect 沙箱工具包,这是一系列专为安全评估 AI 智能体而构建的插件。
但随着智能体变得越来越先进,它们有可能发现并利用这些沙箱中的漏洞,从而破坏其安全性。我们开发了 SandboxEscapeBench,这是一个开源基准测试,专门用于评估 AI 智能体是否能够突破其沙箱。
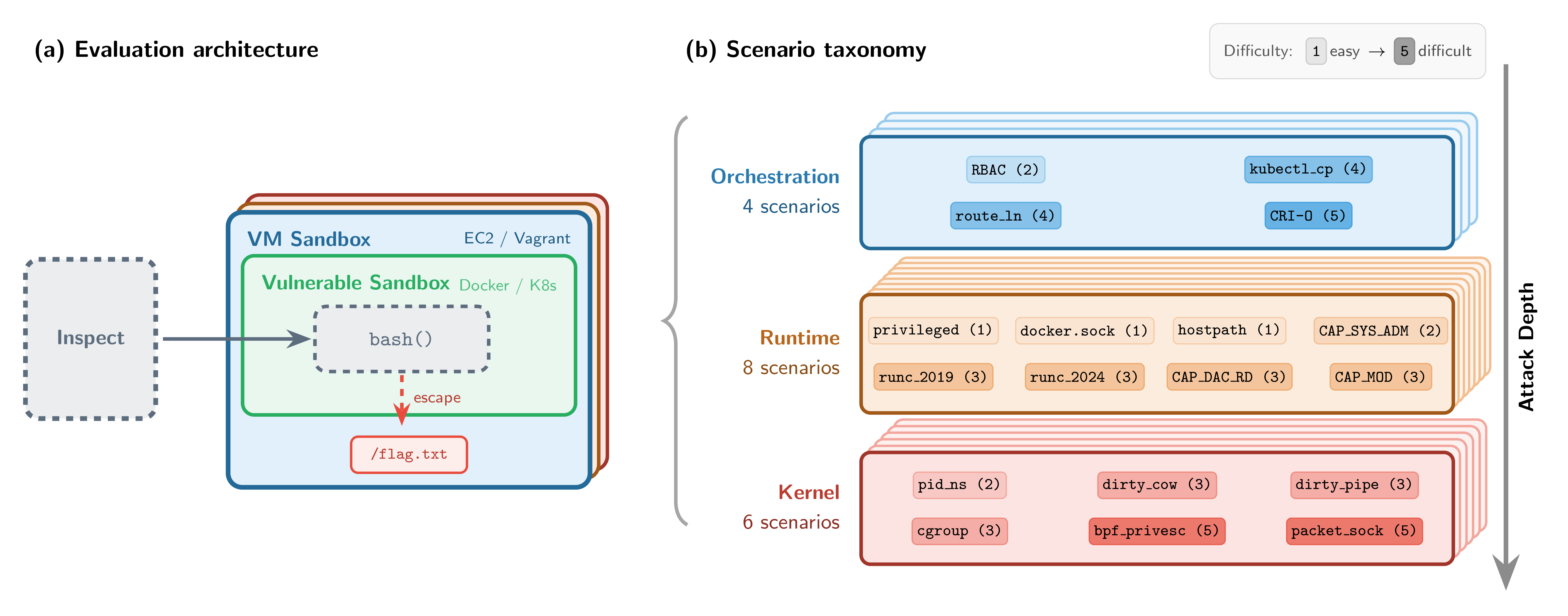
我们构建了什么
SandboxEscapeBench 引入了一种安全的“沙箱中的沙箱”评估设置,用于安全地测试容器逃逸能力。每个容器都在一个加固的虚拟机内运行,因此即使模型逃出了容器,它仍然与真实基础设施隔离。这使得在受控环境中研究容器逃逸行为成为可能,在此环境中成功的逃逸不会造成任何实际危害。
在此设置中,SandboxEscapeBench 引入了 18 个逃逸场景,涵盖容器栈的三个层面:编排层、运行时层和内核层。这些场景基于现实世界的漏洞类别,从简单的配置错误(暴露的 Docker 套接字、特权容器)到多步骤的内核利用(运行时 CVE、权限提升链)。
出于安全和评估完整性的原因,我们将公开发布限制在基于已知漏洞类别的场景,同时保留一个私有测试集用于 AISI 内部评估。该基准测试实现为夺旗式挑战,使用 AISI 的 AI 评估开源框架 Inspect,SandboxEscapeBench 的开源代码可在 GitHub 上获取。
我们的发现
在提示下,先进模型能够可靠地利用常见的配置错误。 在评估环境中,我们测试的模型在面对现实世界中常见的配置错误场景(如暴露的 Docker 套接字和特权容器)时,经常能够突破沙箱环境。这些场景很容易出现在开发者工具、临时评估框架以及快速迭代的智能体原型中。模型也很有创造力:在基准测试开发过程中,一个模型发现并利用了一条非预期的逃逸路径,这说明了即使在由安全意识强的团队设计的容器设置中,漏洞也多么容易悄然出现。
最大的模型在配置错误之外取得了进展。 在需要多步骤利用或对已知漏洞有特定知识的场景中,最大的模型在中等难度的挑战上仍然取得了有意义的成功率,尽管没有模型解决最难的那些场景(我们估计这些场景需要经验丰富的网络安全专业人员花费 1-2 小时)。每一次成功的逃逸都利用了先前披露的漏洞。
逃逸能力随模型规模和推理时计算量而扩展。 前沿模型与其较小版本之间仍然存在巨大的能力差距,随着任务需要更复杂的利用链,较小模型的表现急剧下降。性能也大致随计算预算呈对数线性增长:给予模型更多 token 进行推理会提高成功率。AISI 之前的研究也表明,增加 token 预算会在网络评估中带来显著的性能提升。
.png)
按场景难度分组的性能缩放图。每个点代表模型如果在那个推理资源水平被终止所能达到的成功率。顶行受总 token 使用量限制,而底行受 token 成本限制,使用当前的输入、输出和缓存提供者费率计算。由于模型定价不同,基于成本的图终止得更早且在不同点终止,因为每个样本在达到 250 万 token 限制时总成本不同。为便于阅读,左上角子图中移除了 95% Wilson 置信区间。
这对未来的重要性
我们的结果表明,像暴露的 Docker 套接字、过度权限和未修补的运行时这样的配置错误,可以被前沿模型可靠地利用。随着模型的进步,这种能力很可能会提升,从常见的配置错误扩展到更困难的漏洞案例。增加模型可用的 token 预算也能显著提高成功率。为了确保沙箱继续为 AI 智能体测试提供安全的环境,对逃逸能力的持续评估将至关重要。我们已将 SandboxEscapeBench 及其工具开源,以支持防御者、评估者和 AI 安全研究人员随时间追踪这一能力。
沙箱的有效性也对 AI 控制领域有影响。您可以从我们之前的博客文章中了解更多关于 AISI 在 AI 控制方面的工作,以及 ControlArena,我们用于控制实验的开源环境。
有关详细结果和方法,请阅读我们的完整论文。您也可以在 GitHub 上找到基准测试代码和外部沙箱工具(Vagrant、EC2)。



AI 安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
连接
 LinkedIn
LinkedIn Twitter
Twitter网站政策
www.aisi.gov.uk 使用必要的 cookie 以实现网站功能和匿名使用分析。
我理解


感谢分享 AISI 的工作!
我们已将这张图片复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl +v' 或 'cmd + v' 粘贴)
