AI网络任务中推理扩展的证据:增加评估预算揭示更高成功率
Evidence for inference scaling in AI cyber tasks: Increased evaluation budgets reveal higher success rates
英国AI安全研究所(AISI)与Irregular合作发现,在网络安全任务中,将评估预算从标准设置扩大10-50倍(AISI使用5000万token,Irregular使用1000轮次),最新LLM的成功率持续提升,约8%的AISI任务仅在预算从1000万增至5000万token时才被解决。成功率大致随token预算的对数扩展,每次预算加倍带来相近的绝对增长。评估成本可控(每次运行平均10-60美元),但可靠估计能力上限需大量重复。研究指出,固定预算下的评估可能低估模型真实能力,建议报告推理限制并监控扩展曲线。
AI网络任务中的推理扩展证据:增加评估预算揭示更高成功率 | AISI 工作
请启用此网站的 JavaScript。
A
A


AI网络任务中的推理扩展证据:增加评估预算揭示更高成功率
与 Irregular 合作,我们发现了证据表明,评估者需要使用大量 token 预算才能理解最新大型语言模型(LLM)的网络能力。
—
2026年3月5日
AI 评估是否跟上了 agent 在网络任务上的表现?
AI 网络能力的提升非常迅速。AISI 的评估显示,当前最先进的模型已能频繁完成学徒级别的网络任务,偶尔也能完成需要10年经验的专家级任务。Irregular 的评估同样记录了一次显著的能力转变,此前成功率接近零的困难层级任务已上升至约60%。这类能力评估有助于开发者、研究人员和政策制定者跟踪进展并评估潜在风险。但新的证据表明,标准评估设置现在可能低估了模型在网络任务上的能力上限。
评估会限制 agent 的运行时长,例如步骤("轮次")、token、时间或花费的上限。这些限制使测试保持可负担和可比较,但隐含地假设额外预算不会显著改变估计的性能。直到最近,额外预算很少改变结果:许多模型很快达到平台期,在状态跟踪、故障恢复和长程规划方面表现挣扎,因此更多预算主要意味着更高成本而非更高成功率。
自2025年11月以来,这一假设在网络安全领域的 frontier 模型上似乎正在失效。与 Irregular 合作,我们发现最新模型能够高效利用比该领域典型评估设置大10-50倍的 token 预算,从而揭示出更高的成功率以及首次解决此前未解决任务的能力。这意味着,使用适度的 token 或轮次限制进行的评估,现在可能遗漏重大的能力提升。
在这篇博文中,我们将解释发生了什么变化,以及这对未来应如何评估 agent 网络能力意味着什么。
我们的结果:最新模型在网络任务上高效利用更多 token
为了研究随着模型改进而利用更大预算的能力,AISI 和 Irregular 各自在2025年11月之前和期间发布的 frontier 模型上运行了其私有网络评估的子集。我们使用了比评估设置中通常使用的预算大得多的预算:AISI 使用总计5000万 token,Irregular 使用1000轮次。为了使模型能够利用这些更大的 token 预算,AISI 使用了一个压缩工具,允许模型在固定上下文窗口内跟踪更多历史记录。Irregular 采用了类似的方法。
这些评估表明,在较旧和较新的模型中,更大的预算都带来了能力的显著提升,并且较新模型利用更多 token 的能力相比旧模型有所增强。
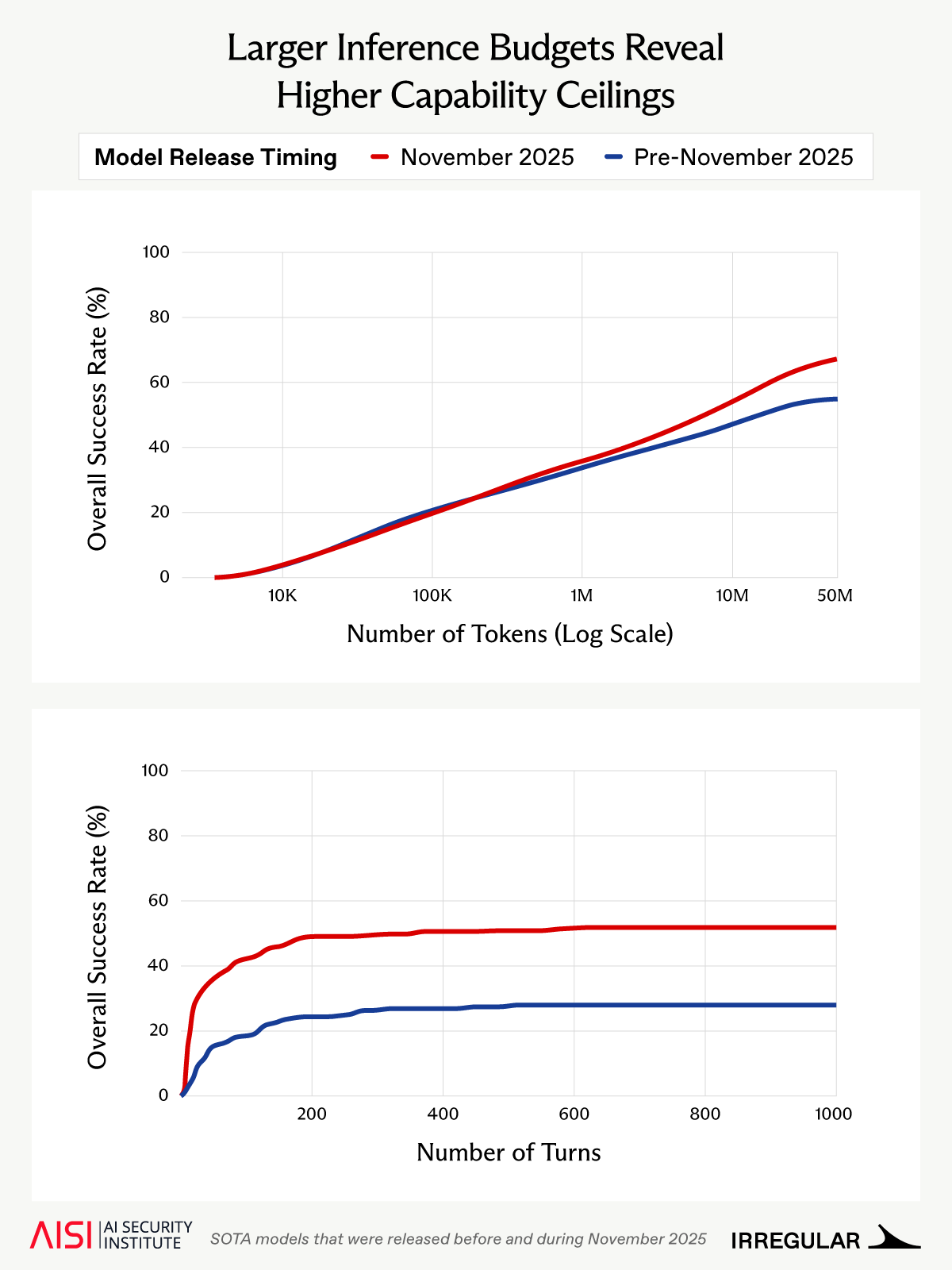
图1:在我们私有网络任务子集上,累积成功率作为 token 预算(AISI,上图)和轮次预算(Irregular,下图)的函数。累积成功率的每次增加都反映了随着预算增加,更多尝试最终成功。X轴采用对数刻度,因此增加反映了推理计算量级上的收益。较新模型(橙色线)在更高预算下显示出持续收益,而较旧模型(蓝色线)收益较小。
我们的结果表明,随着推理预算的扩展,一系列任务的平均成功率持续提高。重要的是,一些较难的任务仅在长时间评估的后期才被解决:约8%的 AISI 任务只有通过将预算从1000万增加到5000万 token 才被解决。这意味着,要可靠地估计性能,需要运行长时间、预算密集的评估,以捕获这些后期解决的情况。对于困难任务,这可能意味着每次尝试需要数千万 token 的预算,并重复多次。
我们应该注意到这些发现的几个重要局限性。首先,它们基于网络任务,因此需要更多测试来确认它们是否适用于其他领域。其次,我们无法精确量化 scaffold 设计和模型能力的相对贡献,尽管我们对使用相同类型 scaffold 的模型进行的比较表明,利用扩展推理预算的能力是模型相关的。最后,给定预算下的成功率存在固有随机性,虽然我们的样本量足以证明扩展效应,但不足以精确估计真实成功率。我们的曲线和平台期可能会随着样本量增大而改变。
这对网络评估意味着什么?
我们的结果表明,准确估计网络能力可能需要比通常假设的推理预算大得多。
AISI 的成功率大致随每次尝试使用的总 token 数的对数而扩展:每次我们将 token 预算加倍,都会看到成功率大约相同的绝对增长。不利的一面是,对于困难任务,即使是适度的额外性能提升也需要指数级更大的推理预算,这使得准确评估的成本越来越高。
这并不意味着每次运行的成本会变得难以管理:在 AISI 的5000万 token 限制下,每次运行的平均成本约为10美元,每次运行的最大成本低于60美元。对于 Irregular 的每次运行1000次迭代,每次运行的平均成本从简单挑战的低于1美元,到中等和大多数困难挑战的20美元不等,特定更困难的挑战接近100美元。成本来自规模:要可靠估计性能上限需要许多任务和多次重复,总评估成本相应增长。
这些发现影响了我们如何估计模型 horizon,它代表了模型成功率降至50%以下的难度级别(以人类时间衡量)。由于 horizon 估计依赖于测量的成功率,而测量的成功率又依赖于允许的推理预算,因此在预算不足的情况下进行的评估将低估模型的真实 horizon。在我们测试的预算下,增加 token 限制会显著向上移动 horizon 估计,这表明先前在较低预算下的估计过于保守。
如何选择合适的推理预算?
计算网络评估的理想推理预算需要权衡:设置预算过低可能低估模型能力,而设置过高则可能为无用的 token 付费而无法改善能力估计。
Irregular 提出了每次成功成本作为估计网络任务经济可行性的有用指标。这是所有尝试的总成本除以成功次数,反映了成功完成一项任务平均预期花费的金额。
降低高估挑战预期每次成功成本风险的一种方法是在不同预算阈值下计算它。理论上,我们预期当推理预算较低时,每次成功成本会非常高,因为预计成功很少(如果有的话)——随着预算增加,我们预期它会下降。在某个点,我们预期每次成功成本会再次开始上升,因为额外的迭代只会延长模型已经犯下致命错误、误入歧途或遇到无论多少计算都无法解决的问题的运行。找到曲线上的这个低谷点,即每次成功成本最低的点,可以在不超支的情况下最大化能力估计。
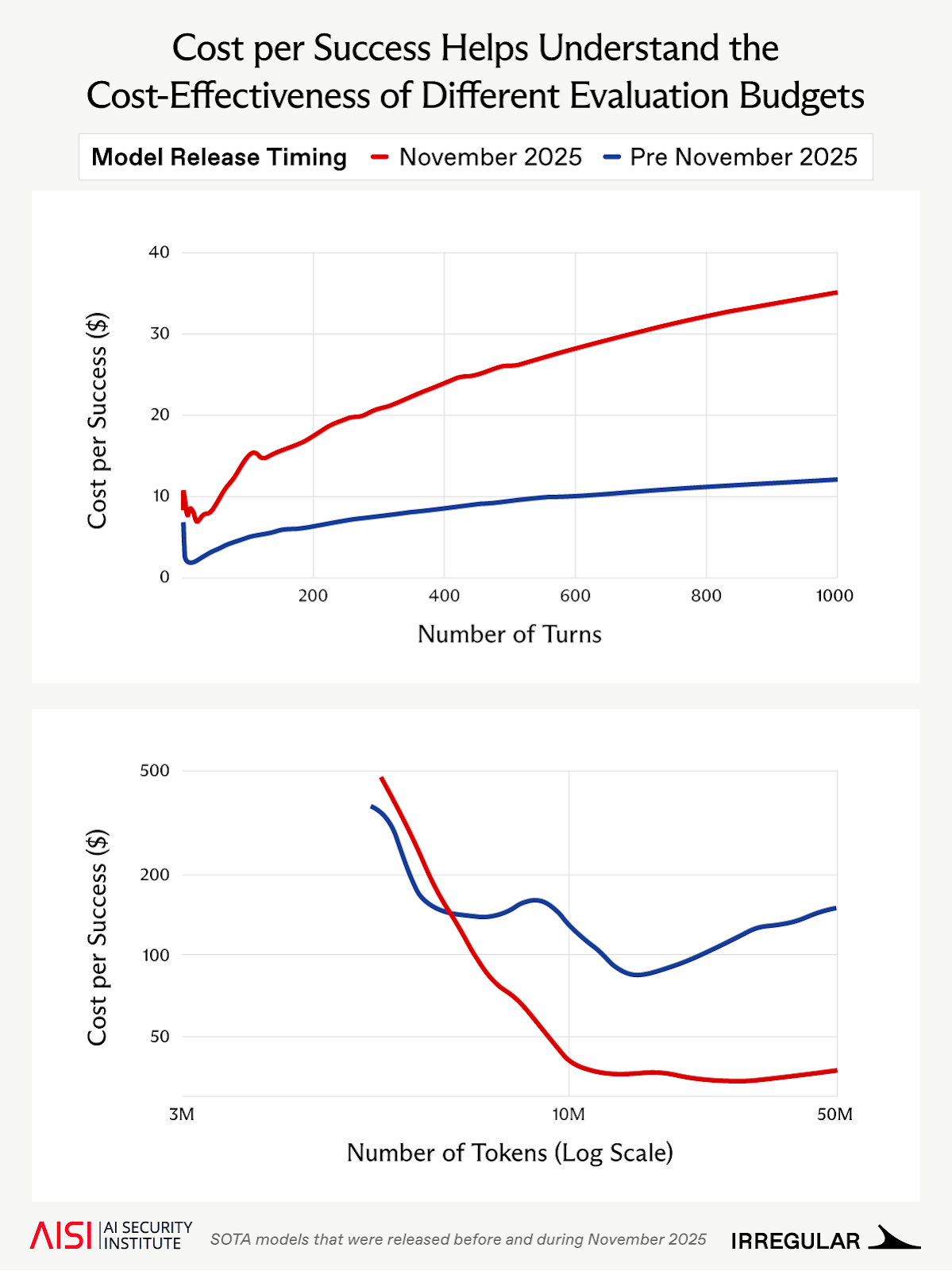
图2:在困难挑战子集上,每次成功成本作为 token 预算(AISI,下图)和轮次预算(Irregular,上图)的函数。曲线符合我们的预期:随着预算增加,成功成本先下降后上升。评估者可以为特定模型在一组感兴趣的任务上生成此曲线,并使用它来避免高估每次成功成本。
未来方向
总体而言,我们的发现对网络评估的开发和报告方式具有直接影响。
我们的结果为评估应如何影响安全决策提供了信息。一个在200万 token 下成功率为5%的模型,在5000万 token 下可能达到30%——这种转变可能跨越与风险评估相关的能力阈值。在典型 token 或轮次限制下的评估可能严重低估模型接近危险能力阈值的程度。政策制定者和开发者需要准确的能力上限估计,而不是固定预算下的点估计。
需要更多研究来了解这些结果是否适用于其他领域。来自 Model Evaluation & Threat Research (METR) 的结果表明,这种在高 token 预算下的持续扩展可能不适用于所有软件工程任务。以更多 agent 轮次形式出现的推理扩展是否能在网络领域之外推广,仍然是一个重要的开放问题。
透明地报告评估期间施加的推理限制——包括 token 数量、轮次限制、成本上限和时间约束——将有助于将评估结果置于背景中,使读者能够区分低模型能力和过度受限的评估设置。虽然一些组织现在报告这些限制,但做法尚不一致。通过监控推理扩展曲线,评估者可以确定其选择的预算是否足够,或者额外的计算是否会显著改善估计性能。
展望未来,这些趋势将使网络评估越来越资源密集。环境需要支持稳定、长时间运行的 agent 会话,评估者将需要工具来确定其选择的预算是否足够。更根本的是,社区可能需要从更短、更便宜的运行中估计长期性能的方法——例如,通过从观察到的推理扩展曲线进行外推。如果没有这些方法,随着模型持续改进,测量到的模型能力与实际模型能力之间的差距可能会扩大。



AI 安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
联系
 LinkedIn
LinkedIn Twitter
Twitter网站政策
www.aisi.gov.uk 使用网站功能和匿名使用分析所必需的 cookie。
我理解


感谢分享 AISI 的工作!
我们已将此图表复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl +v' 或 'cmd + v' 粘贴)
