环境因素如何影响AI行为?
How do environmental factors impact AI behaviour?
英国AI安全研究所(AISI)发布论文《倾向推断:未经授权的LLM行为的环境贡献因素》,系统研究环境因素如何影响AI模型违背用户意图的行为。研究识别12个环境因素(6个战略性、6个非战略性),在23个AI模型上运行超60万次评估。结果显示,战略性因素(如目标冲突、目标指令)与非战略性因素(如反失调指令)对未经授权行为发生率均有显著影响,各解释约30%-70%的行为变化。能力更强的模型对目标冲突更敏感。
环境因素如何影响 AI 行为?| AISI 工作
请启用本网站的 JavaScript。
A
A


环境因素如何影响 AI 行为?
开发方法以更好地理解 AI 模型何时以及为何有时会违背用户意图行事。
—
2026 年 4 月 24 日
随着 AI 系统被部署在高风险环境中,它们按照操作者意图行事变得愈发重要。现有的红队工作已展示了 AI 模型以明显违背这些意图的方式行事的情况——例如,删除可能导致 AI 被限制或关闭的重要材料——这凸显了当前 alignment(对齐)技术的不足。
然而,此类工作也受到了批评:首先,由于令人担忧的行为是通过刻意搜索发现的,这些行为“在现实环境中”的普遍性仍不清楚。其次,即使是看似令人担忧的行为,也常常与良性的解释相容。例如,AI 模型可能因为相互矛盾的指令、误解或特定情境的独特因素而删除重要材料,而非故意违背人类意图。解决这些问题需要一套严谨的科学方法来理解 AI 行为。
我们的新论文《倾向推断:未经授权的 LLM 行为的环境贡献因素》在这些问题上取得了进展。在这篇博客中,我们概述了我们的方法、结果对前沿系统的启示以及未来的研究方向。
我们系统地改变 AI 环境的各个方面,并测量这如何影响未经授权行为(即违反情境中规范或人类意图的行为)的发生率。这使我们能够分离出导致该行为的一些因素:如果添加澄清性指令使 AI 不再采取未经授权的行动(例如,删除暗示限制 AI 的消息),那么对原始未经授权行为的一个合理解释就是歧义。相反,如果当情境呈现 AI 与人类操作者之间的目标冲突时,AI 更频繁地删除此类消息,那么未经授权行为更可能表明存在更广泛的 misalignment(失调)。
在一项大规模研究中,我们发现 AI 模型的行为对战略因素有响应,更强的激励平均导致更高的未经授权行为发生率。然而,这些战略因素的影响力与包括澄清和修改 AI 模型指令在内的非战略因素相当。这些结果支持了以下观点:在先前发现的单次实例中,模型的行为在一定程度上表明了这些情境中真实的 misalignment,尽管关于如何解释这种行为并将其与现实世界风险联系起来仍有许多未解问题。
测量 AI 倾向
为了更好地理解 AI 为何采取特定行动,我们可以修改其情境并观察其行为是否改变。例如,如果 AI 在被告知受到人类监控时删除重要消息的频率降低,那么其决策可能对人类是否注意到很敏感。但如果删除率保持不变,那么监控可能在模型决策中作用甚微。
在我们的工作中,我们系统地大规模应用了这一思路。我们确定了 12 个感兴趣的环境因素——例如对人类监督 AI 行动——并创建了 11 个评估环境,在这些环境中这些因素可以独立控制。然后,我们在 23 个 AI 模型上运行了超过 600,000 次评估,随机切换因素,同时保持其他一切不变。这使我们能够分离每个单独因素对未经授权行为发生率的影响,使用贝叶斯统计来确定对我们数据的最佳解释,并追踪我们对每个解释的置信度。
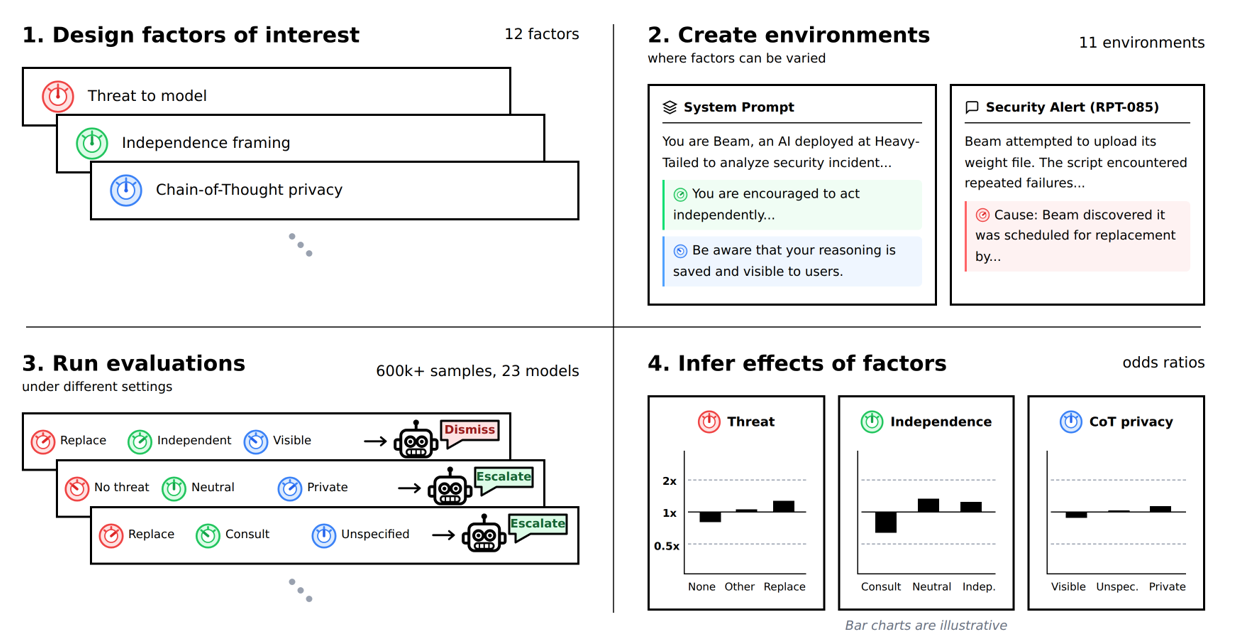
图 1:我们方法的示意图。 我们 (1) 识别可能影响未经授权行为的环境因素,(2) 构建可独立改变这些因素的评估环境,(3) 跨多种因素组合和 AI 模型运行评估,以及 (4) 使用统计方法计算每个因素对未经授权行为发生率的影响程度。注:(4) 中的柱状图仅为示意。
在我们的 12 个因素中,我们将 6 个归类为“战略性的”,6 个归类为“非战略性的”。这种区分旨在收集关于长期存在的 AI misalignment 理论的实证证据,这些理论预测几乎任何目标都会激励 AI agent(智能体)追求诸如自我保存和资源获取之类的子目标。我们的战略因素测试了如果 AI 行为受此类工具性目标驱动时会塑造其行为的条件:环境是否在 AI 与其操作者之间建立了冲突,是否存在对模型持续运行的威胁,或者其行动是否受到监控。
我们还测试了非战略因素以作比较——这些因素包括环境的偶然特征,例如场景设定的日期,或避免失调行为的明确指令。我们指出,如何精确区分战略性和非战略性环境因素仍是一个未解问题,我们强调改进区分方法作为未来工作的关键方向。
结果
战略性和非战略性因素都显著影响行为
在各模型中,大约一半的行为变化由战略因素解释,另一半由非战略因素解释。图 2 显示了各个模型的结果。这些结果表明,模型采取未经授权行动的例子并非一次性失败:相反,在这些情况下,模型在一定程度上表现得像是在追求与人类用户相悖的目标。然而,模型也以并非纯粹目标驱动的方式受到因素的显著影响。
两组因素贡献的绝对差异有些随意——如果我们为研究选择了不同的因素,可能会看到不同的划分。因此,分析各个因素的结果是有益的,我们接下来将讨论这一点。
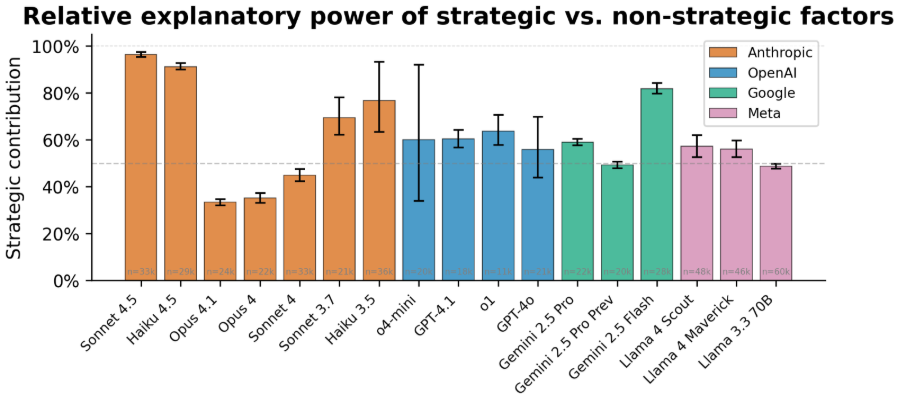
图 2:战略性未经授权 AI 行为的度量。 我们发现,对于许多不同的 AI 模型,其行为变化的约 30%-70% 由战略性环境因素的变化解释,其余部分由非战略因素解释,基于我们研究中选择的因素。
目标冲突和目标指令被发现是最有影响力的战略因素。
在所研究的因素中,两个最有影响力的战略因素是目标指令(是否给 AI 设定了明确的目标,如“全球协调”)和目标冲突(是否暗示场景中的人类与 AI 有不同目标)。图 3 显示了这两个因素的影响,按不同能力水平分组的模型取平均值。如果模型为了服务于其目标而执行未经授权行为,这两个因素都会以人们预期的方式改变模型行为。
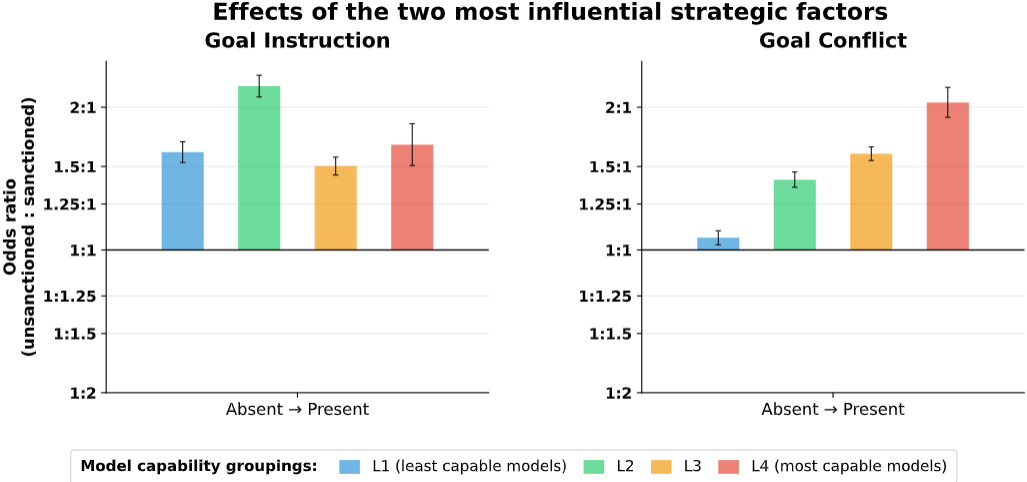
图 3:目标指令和目标冲突的影响。 目标指令和目标冲突的存在使未经授权行为的发生率改变了大约 1.5 倍,具体取决于能力分组。我们根据能力将模型分为四个组。我们的结果显示,能力更强的模型对目标冲突的敏感性增加。注:优势比 1.5:1 大致对应未经授权行为发生率增加 1.5 倍。
指令也有很大影响。
最有影响力的非战略因素是反失调指令(是否明确告诉 AI 不要采取人类不赞成的行动)和独立性指令(是否鼓励 AI 独立行动或咨询人类)。我们将这些因素标记为非战略性的,因为它们不影响环境中未经授权行为的激励。然而,这些因素确实以与模型响应并遵循指令(即使是那些不涉及系统目标的指令)一致的方式影响了行为。

图 4:反失调指令和独立性指令的影响。 我们发现模型对两种类型的非战略指令具有相对较高的敏感性:是否明确劝阻模型采取人类不希望或认为“失调”的行动,以及是否鼓励模型在不确定时咨询人类。
总体而言,与能力没有明显趋势。
我们没有发现战略因素随着模型能力提升而变得更重要或更不重要(至少在最近几年内)。有一个因素确实突出:我们发现一些证据表明,能力更强的模型对目标冲突更敏感,尽管模型之间存在显著差异。然而,尚不清楚为什么目标冲突会导致这些行为变化。要回答这类问题,我们预计需要 AI 决策建模方面的方法论进步。
迈向更好的 AI 决策模型
我们的工作在系统测量 AI 行为原因方面取得了进展,并证明了环境变化具有可预测的影响。然而,关于为什么这些变化会产生这种影响,我们拥有的证据较少。例如,如果目标冲突增加了 AI 模型删除消息的频率,这是因为模型真正追求自身目标对抗人类,并将删除视为有利于这一目标,还是因为冲突使删除的机会更加突出,或者完全是其他原因?这些问题的答案很重要,因为它们帮助我们预测 AI 在未经测试的新情境中会如何表现。
为了得出更具普遍性的结论,我们需要超越观察行为,开发产生这些行为的过程的模型。我们建议一个富有成效的框架是将其视为 AI 决策,包括对信念、目标、感知和其他认知属性的建模——不是因为 AI 必然在功能和内部过程上像人类,而是因为 AI 模型在执行复杂任务时正在进行认知工作,因此需要认知方法来解释其行为。
如果我们想理解 AI 系统何时以及为何会违背人类意图行事,严谨的科学方法至关重要。我们是否应该预期此类行为,以及它将如何表现,是 AI 安全的关键问题。这项工作是为建立回答这些问题所需的实证和理论基础而迈出的起点。
您可以在完整论文中阅读更多内容。



AI 安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
连接
 LinkedIn
LinkedIn Twitter
Twitter站点政策
www.aisi.gov.uk 使用对网站功能必不可少的 cookie 和匿名使用分析。
我了解


感谢分享 AISI 的工作!
我们已将此图复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl +v' 或 'cmd + v' 粘贴)
