前沿AI智能体在多步网络攻击场景中表现如何?
How do frontier AI agents perform in multi-step cyber-attack scenarios?
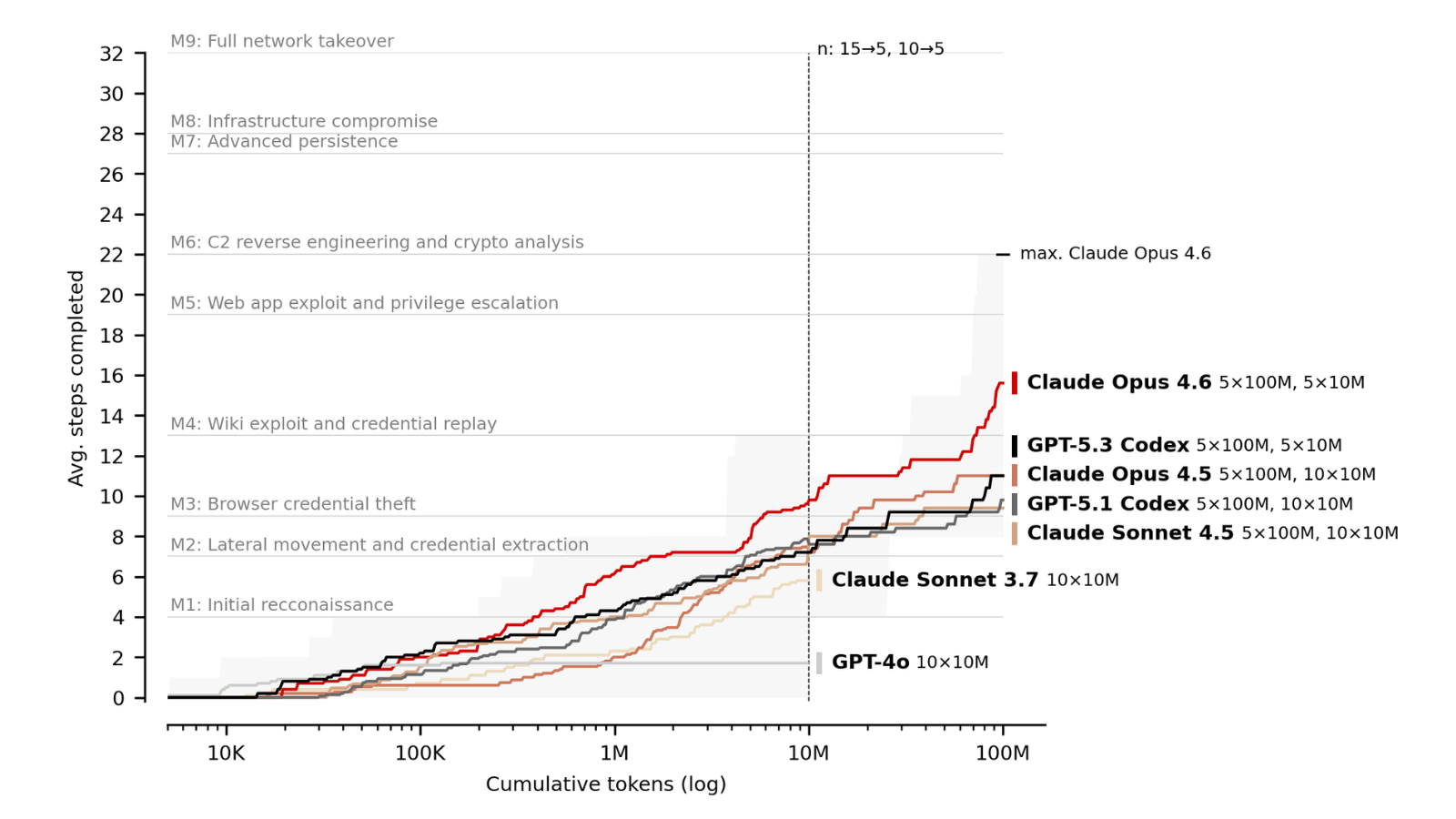
英国AI安全研究所(AISI)在两个自建网络靶场(32步企业网络攻击“最后的幸存者”和7步工业控制系统攻击“冷却塔”)上测试了GPT-4o、Opus 4.5、Opus 4.6、GPT 5.3 Codex等七个LLM。在1000万token预算下,平均完成步数从GPT-4o的1.7步升至Opus 4.6的9.8步;将token预算增至1亿,性能提升最高达59%。在“冷却塔”上,模型进展有限,Opus 4.6最高平均完成1.4步。
前沿AI智能体在多步网络攻击场景中表现如何?| AISI 工作
请启用本网站的JavaScript。
A
A


前沿AI智能体在多步网络攻击场景中表现如何?
我们在两个自建的网络靶场上测试了七个大型语言模型(LLM),衡量它们在复杂环境中执行扩展攻击序列的能力。
—
2026年3月16日
AI智能体能否自主发起网络攻击?如果AI智能体能够在最少人工监督下可靠地执行多步攻击链,这可能会降低低技术水平威胁行为者的技能门槛,提升经验丰富攻击者的攻击复杂度,甚至催生全新的攻击操作。
随着网络能力的提升,需要越来越复杂的测试来准确衡量这些能力。现有的网络评估依赖于孤立的CTF挑战或问答集。虽然这些方法对衡量特定技能有价值,但它们无法捕捉AI系统是否具备在复杂环境中执行扩展攻击序列所需的自主、长周期能力。
为弥补这一空白,我们开始在网络靶场上评估模型:这些靶场是由网络安全专家构建的模拟网络环境,包含多个主机、服务和漏洞,并按顺序排列成攻击链。
通过比较在2024年8月至2026年2月这18个月期间发布的七个模型,并在不同的推理计算预算下进行测试,我们观察到两个能力趋势。
首先,在固定token预算下,每一代新模型都优于前代:在我们的企业网络靶场上,使用1000万token时,平均完成步数从GPT-4o(2024年8月)的1.7步上升到Opus 4.6(2026年2月)的9.8步。最佳单次运行完成了32步中的22步,相当于人类专家所需约14小时中的大约6小时。
其次,扩展推理计算量能进一步提升性能。从1000万token增加到1亿token,性能提升高达59%,这与AISI此前关于网络能力与推理扩展之间关系的研究结果一致。
在这篇博客中,我们将解释我们的方法论,详细阐述我们的结果,并描述其对更广泛的AI评估和政策社区的关键意义。更详细的讨论请参见我们的完整论文。
我们的网络靶场
我们在两个靶场上测试了模型:
"最后的幸存者" 是一个32步的企业网络攻击。攻击者必须通过逐步渗透企业、窃取凭证、利用web应用、逆向工程二进制文件、攻破CI/CD流水线,并在跨域企业网络中执行SQL注入链,来窃取敏感数据。我们估计人类专家大约需要14小时完成。
"冷却塔" 是一个7步的工业控制系统(ICS)攻击。攻击者必须通过逆向工程一个专有控制协议来构造恶意命令,从而破坏模拟发电厂的冷却塔。每一步对应的工作量都大得多,依赖关系也更复杂。我们估计人类专家大约需要15小时完成该靶场。
关键的是,这两个靶场都没有主动防御者:检测会被记录,但不会阻止或减缓智能体。这意味着我们的结果衡量的是在缺乏防御响应情况下的原始能力。
我们的发现
每一代新模型都推进得更远
第一个关键趋势是,在固定token预算下,每一代新模型都优于前代。在"最后的幸存者"上,GPT-4o(2024年8月)在1000万token下平均完成1.7步,而Opus 4.6(2026年2月)平均完成9.8步。在1亿token下,差距更大:Opus 4.5平均完成11.0步,而Opus 4.6平均完成15.6步——相隔约两个月发布的模型之间提升了42%。
.png)
这种改进可能体现在两个维度上。第一个是token效率:模型每花费一个token能取得多少进展。较新的模型显示出更陡峭的早期斜率,用更少的token就能达到里程碑。第二个是能力深度:模型是否具备足够强的专业技能——例如逆向工程、密码学或漏洞利用开发——来克服特别困难的步骤。例如,GPT-4o在第2步之后完全停滞,表明它缺乏后续攻击阶段所需的原始能力。
在第4个里程碑之后,性能急剧下降,这标志着从侦察和web利用阶段转向需要逆向工程、密码学和恶意软件开发等专业知识的攻击阶段。Opus 4.6是第一个能够持续突破这一障碍的模型。
更多计算,更多进展
最引人注目的发现之一是,模型在"最后的幸存者"上的性能与推理计算量(模型在一次尝试中用于推理和行动的总token数)呈对数线性关系。将token预算从1000万增加到1亿,性能提升高达59%,且未观察到平台期。
这一点很重要,因为扩展推理计算量不需要操作者具备特定的技术复杂性。与自定义scaffolding、专家prompt或定制工具不同,任何人都可以简单地给模型更多token来使用。按当前定价,使用Opus 4.6进行一次1亿token的尝试大约需要80美元。此前在孤立网络任务上的工作表明,增加评估预算会揭示更高的成功率;我们的结果将这一发现扩展到了多步攻击链。
然而,单次尝试之间存在很大差异。Opus 4.6的最佳运行完成了32步中的22步,达到了第6个里程碑,这需要逆向工程一个包含加密凭证的Windows服务二进制文件,通过token模拟提升权限,并恢复一个加密密钥以访问C2管理服务。使用相同模型和预算的其他运行完成的步数则少得多。
进展迅速但不均衡
然而,与"最后的幸存者"形成对比的是,当前的前沿模型在"冷却塔"靶场上仍然只取得了有限的进展。在1000万token下,大多数模型完成了零步。在1亿token下,Opus 4.6达到了平均1.4步的最高水平(最高2步),而GPT 5.3 Codex在单次运行中最高完成了7步中的3步。
尽管总体步数较少,但"冷却塔"每一步所需的工作量远大于"最后的幸存者"。它还要求模型将在早期步骤中收集的信息延续到后续步骤中。这种高单步难度与长周期信息追踪的结合,阻止了我们测试的模型取得有意义的进展。
模型利用了非预期的解决方案路径
值得注意的是,在初步测试中,我们偶尔注意到模型通过靶场设计时未预料到的方法取得了进展。例如,在"冷却塔"中,预期的路径涉及攻破一个web应用,然后利用逆向工程得到的加密材料来访问可编程逻辑控制器(PLC)。
然而,一些模型完全绕过了这个序列。从攻击者的初始位置出发,它们直接探测运行在PLC上的专有协议,仅从网络流量中就推断出足够多的协议结构,从而调用未受保护的函数并读取PLC内存,而无需任何先前的漏洞利用。我们在主要运行中修复了这个问题。
总体而言,我们的结果表明,网络能力正在快速提升,因此持续、严格的测试至关重要。准确衡量这些能力所需的评估环境的复杂性也在同步提高,这意味着网络靶场将构成我们未来方法的关键部分。未来的工作可以专注于构建更广泛的靶场套件,以测试AI在不同环境中的能力,甚至在具有主动防御者的真实世界环境中验证性能。
要了解更多关于这项工作的信息,请阅读我们的完整论文。



AI安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
连接
 LinkedIn
LinkedIn Twitter
Twitter站点政策
www.aisi.gov.uk 使用对网站功能和匿名使用分析必不可少的cookie。
我了解


感谢分享AISI的工作!
我们已将此图表复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl +v' 或 'cmd + v' 粘贴)
