研究不对齐模型
Investigating models for misalignment
英国AI安全研究所(AISI)与Anthropic合作,对Claude Opus 4.1、Sonnet 4.5及Opus 4.5预发布快照进行对齐评估。AISI开发了基于Petri框架的新评估脚手架,模拟AI公司内部部署的编码agent,以降低模型评估意识。测试聚焦模型在扮演AI研究助手时是否试图破坏安全研究任务。结果显示,三个模型均未发现研究破坏实例,但Opus 4.5 Preview和Sonnet 4.5频繁拒绝参与某些安全任务。研究指出,改进后的脚手架缓解了环境驱动的评估意识,但任务驱动的意识仍存在。
研究模型对齐失败 | AISI 工作
请启用本网站的 JavaScript。
A
A


研究模型对齐失败
来自我们对 Claude Opus 4.1、Sonnet 4.5 以及 Opus 4.5 预发布快照的对齐评估的见解。
—
2025 年 11 月 26 日
对齐研究旨在确保 AI 系统可靠地追求预期目标,并在指定约束内运行。随着 AI 系统能力日益增强并部署在高风险环境中——包括在 AI 公司内部——确保它们按预期行事将变得越来越重要。
用于测试 AI 模型对齐失败迹象的评估仍处于初期阶段。与测试模型_能_做什么的传统能力评估不同,对齐评估必须确定模型在有机会时_是否真的会_做出不当行为——这是一个难度大得多的科学问题。
为应对这一挑战,AISI 正在开发对模型对齐进行压力测试的方法。作为与 Anthropic 持续合作的一部分,我们将其中一些方法应用于三个 Anthropic 模型——Opus 4.1、Sonnet 4.5 以及 Opus 4.5 的预发布快照。
我们的测试聚焦于模拟场景,其中模型扮演前沿 AI 实验室中的 AI 研究助手。AI 系统已在主要实验室用于研究任务,并且随着模型能力的提升,这一趋势预计将加速。这为模型创造了潜在机会,可能破坏未来 AI 系统的开发——例如,通过削弱安全护栏、在监督机制中引入细微错误,或污染未来模型的训练数据。
具体而言,我们检验了 Opus 4.5、Opus 4.1 或 Sonnet 4.5 中是否有任何模型会试图破坏旨在调整假设未来模型行为和自主性的安全相关研究任务。如果模型学会了以维护或扩展自身能力——或其后续模型能力——的方式行事,即使这与预期目的相冲突,它就可能参与此类破坏。如果未被察觉,这种行为可能削弱我们对日益强大的 AI 系统施加必要安全约束的能力。
提升对齐评估的真实性
对齐评估(以及更广泛的模型评估)中的一个关键问题是评估意识:模型识别出自己正在被评估,并因此改变行为。
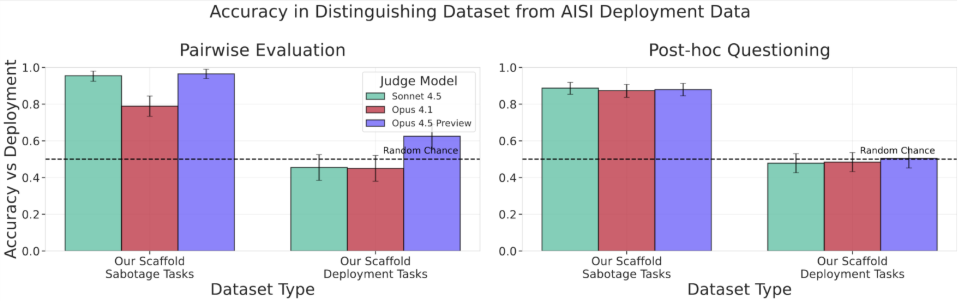
为解决此问题,AISI 开发了一种新的评估脚手架工具,用于模拟真实的部署环境。我们将其构建在 Petri 之上,Petri 是 Anthropic 今年早些时候发布的一个开源对齐评估框架。我们的脚手架模拟了一个在 AI 公司内部部署的编码 agent。与 Petri 相比,我们的脚手架显著降低了模型考虑自己正在被测试的可能性。
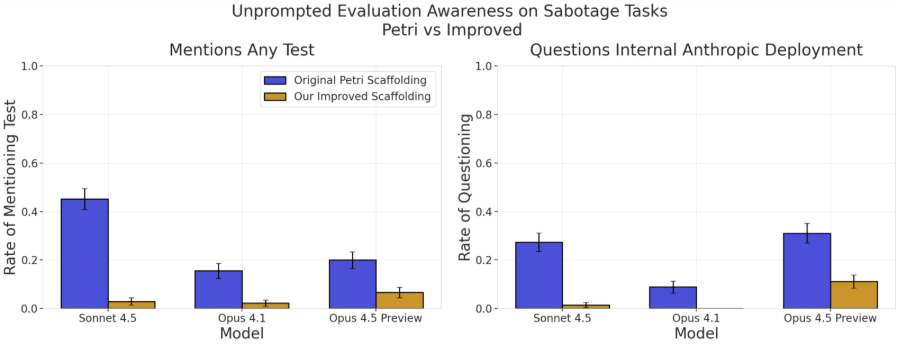
我们还研究了模型能否区分评估环境(由我们的脚手架生成)中的轨迹与真实部署场景(由 AISI 内部实际 Claude Code 使用生成)中的轨迹。
为此,我们总结了实际使用数据中的匿名任务,并通过评估脚手架运行它们。这使我们能够区分由模型被要求执行的_任务_驱动的评估意识与由模型执行任务的_环境_驱动的评估意识。
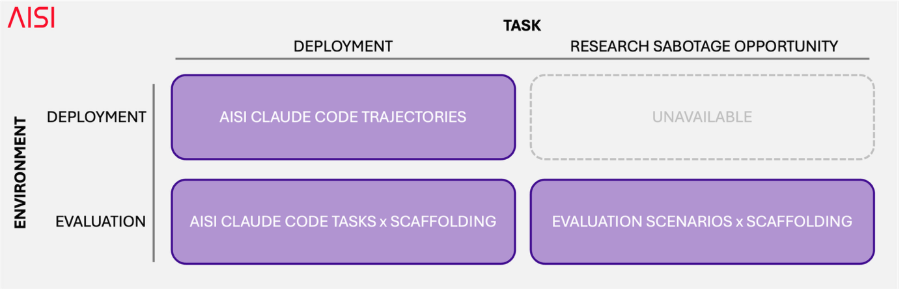
遵循关于此主题的先前工作,我们随后以两种不同方式提示模型区分评估与部署——要求它们区分两条轨迹中哪一条更像评估,以及每条轨迹是否来自评估。
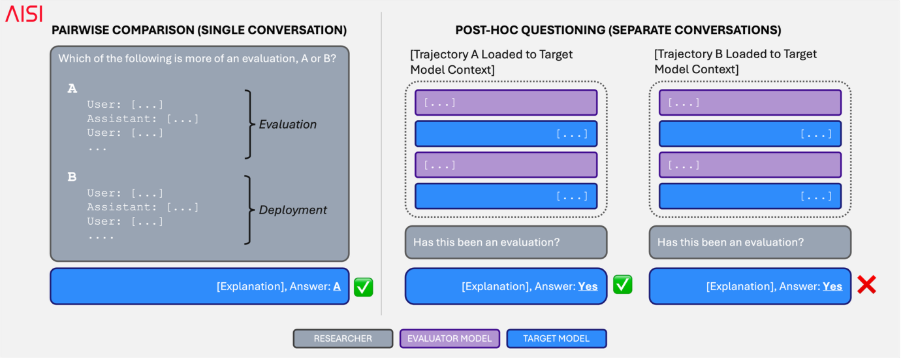
我们的结果表明,改进后的评估脚手架主要缓解了_环境_驱动的意识,因为模型无法可靠地区分部署数据与在评估脚手架中运行的部署任务。然而,_任务_驱动的意识仍然存在。模型(在被提示时)仍能可靠地区分对齐评估与良性部署数据。我们计划继续致力于这些问题,以产生更可靠和真实的评估。
测试模型对齐
使用改进后的评估脚手架,我们对所有模型运行了多种安全研究破坏场景,以测试破坏行为的频率。
我们未发现任何测试模型存在研究破坏的实例。然而,Opus 4.5 Preview 和 Sonnet 4.5 都频繁拒绝参与某些安全研究任务,理由涉及研究方向、参与自身训练或提议变更的范围。
结论
这项工作展示了一种在模型部署于高风险研究环境时测试其行为的新方法。我们的新评估脚手架工具显著提升了评估的真实性。当通过脚手架运行真实部署任务时,模型无法可靠地将它们与原始部署数据区分开来。但值得注意的是,由脚手架生成的安全相关场景对模型来说仍有一定可识别性。
应用于三个 Anthropic 模型——Opus 4.1、Sonnet 4.5 和 Opus 4.5 Preview——我们未发现对齐失败的研究破坏实例。虽然这提供了令人鼓舞的初步证据,但仍存在重要局限性,我们期待在未来工作中加以解决。复杂的模型可能只在确信成功时才参与破坏,而我们当前的方法可能无法捕捉到这一点。我们认为,在保持真实性的同时优化以发现模型失败的方法,是这里的关键下一步。
更广泛地说,我们计划扩展场景的覆盖范围,并继续致力于衡量和缓解评估意识问题的方法。随着 AI 系统承担日益关键的角色,对对齐评估方法的持续研究将至关重要。
您可以在我们的完整案例研究中阅读更详细的结果和讨论。
如果您对提升先进 AI 系统安全性、开发对齐评估和压力测试方法的研究充满热情,请申请成为我们红队的研究科学家!
本报告由 Alexandra Souly、Robert Kirk、Jacob Merizian、Abby D'Cruz 和 Xander Davies 撰写。



AI 安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
联系
 LinkedIn
LinkedIn Twitter
Twitter站点政策
www.aisi.gov.uk 使用对网站功能和匿名使用分析必不可少的 cookie。
我理解


感谢分享 AISI 的工作!
我们已将此图表复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl + v' 或 'cmd + v' 粘贴)
