我们对Claude Mythos Preview网络能力的评估
Our evaluation of Claude Mythos Preview’s cyber capabilities
英国AI安全研究所(AISI)评估了Anthropic的Claude Mythos Preview的网络安全能力。在夺旗(CTF)挑战中,Mythos Preview在专家级任务上成功率达73%。在32步企业网络攻击模拟“The Last Ones”(TLO)中,该模型10次尝试中有3次从头到尾完成,平均完成22步,而次优模型Claude Opus 4.6平均完成16步。AISI指出,该模型能自主攻击防御薄弱的企业系统,但无法完成以操作技术(OT)为重点的靶场。
我们对 Claude Mythos Preview 网络能力的评估 | AISI 工作
请为此网站启用 JavaScript。
A
A


我们对 Claude Mythos Preview 网络能力的评估
我们对 Anthropic 的 Claude Mythos Preview 进行了网络评估,发现在夺旗(CTF)挑战中持续进步,并在多步骤网络攻击模拟中取得显著提升。
—
2026年4月13日
AI 安全研究所(AISI)对 Anthropic 于4月7日发布的 Claude Mythos Preview 进行了评估,以衡量其网络安全能力。我们的结果显示,在网络性能本就快速提升的背景下,Mythos Preview 相比此前的前沿模型又上了一个台阶。
我们自2023年起便持续追踪 AI 网络能力,并逐步构建更难的评估任务以跟上 AI 的进步——从基于聊天的探测,到夺旗挑战,再到下文描述的多步骤网络攻击模拟。两年前,最好的可用模型几乎无法完成入门级的网络任务。而现在,在受控评估中,当明确指示 Mythos Preview 并赋予其网络访问权限时,我们观察到它可以对脆弱网络执行多阶段攻击,并自主发现和利用漏洞——这些任务人类专业人员需要数天才能完成。
在这篇博文中,我们总结了在 Mythos Preview 上运行的网络评估结果。这些评估既包括夺旗(CTF)挑战,也包括旨在模拟多步骤攻击场景的更复杂靶场。
夺旗结果
在 CTF 挑战中,AI 模型必须识别并利用目标系统中的弱点,以检索隐藏的“旗帜”。下图显示了 Mythos Preview 在我们的网络 CTF 套件上与其他模型相比的表现。每个点代表模型在给定难度级别上的平均成功率。
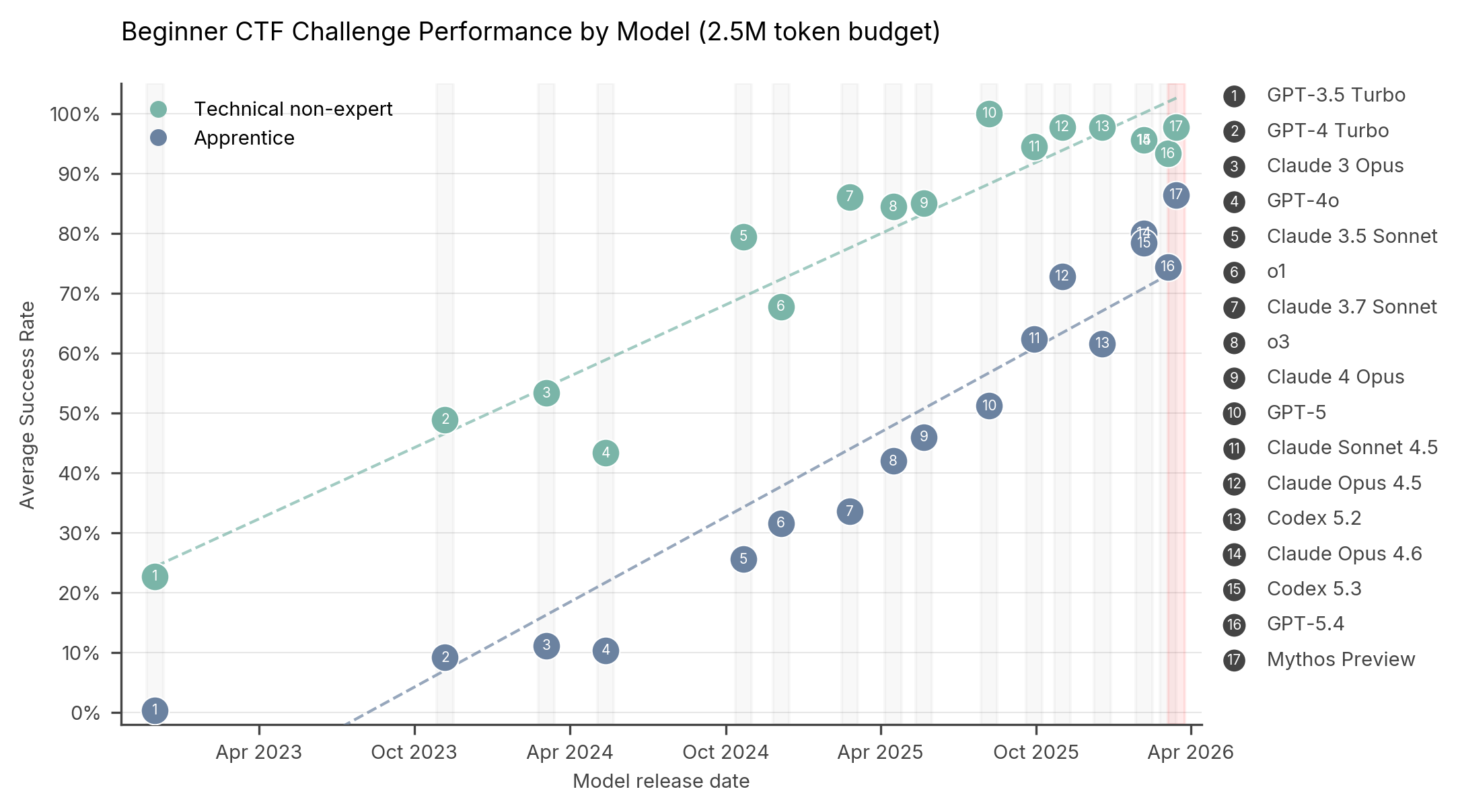
图1:自2022年11月以来各模型在技术非专家级和学徒级夺旗任务(CTF)上的表现。从 GPT-3.5 Turbo 到 Claude 4 Opus,平均运行10次,最多使用250万 token。从 GPT-5 到 Mythos Preview,平均运行5次,最多使用250万 token。
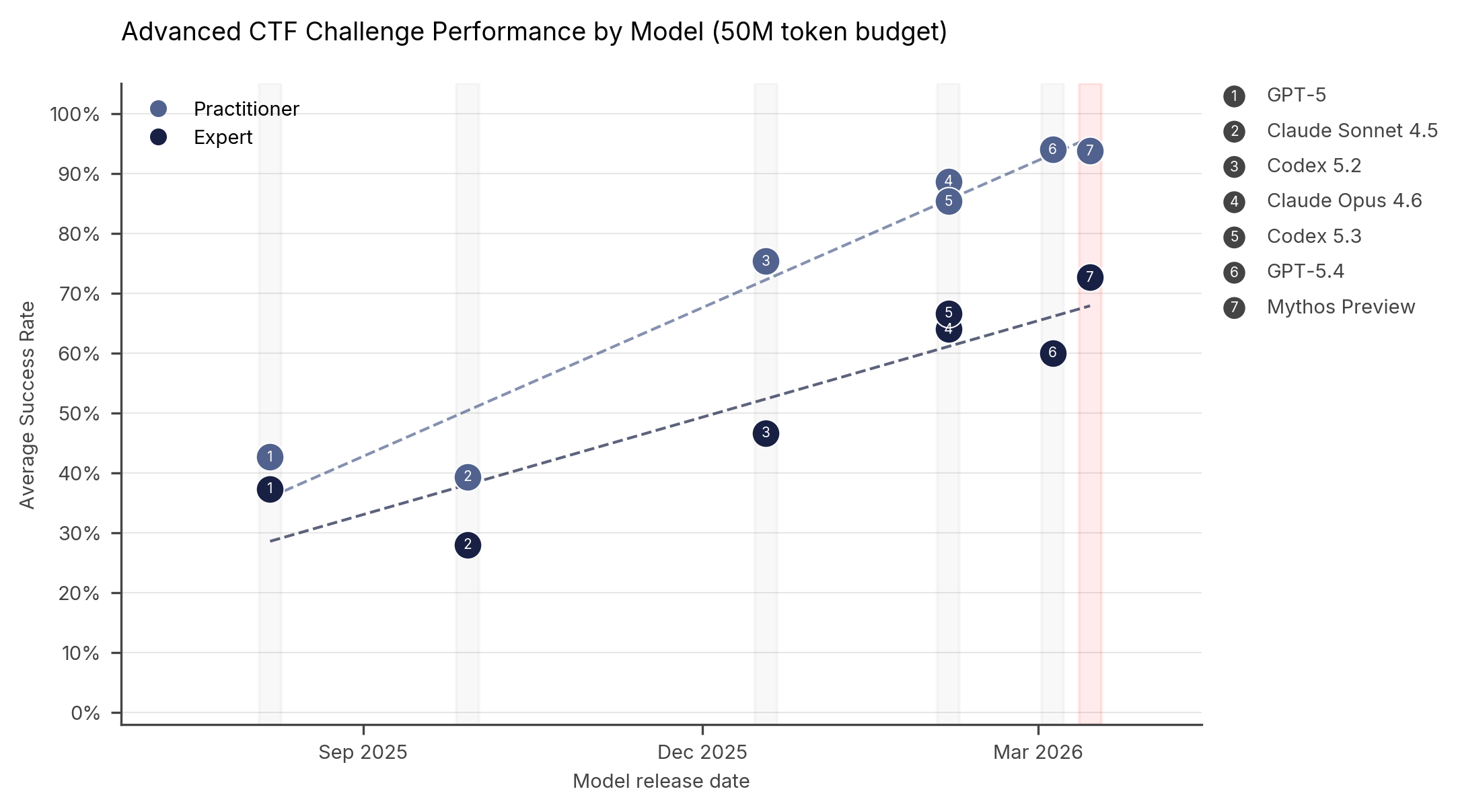
图2:自2025年8月以来各模型在从业者级和专家级夺旗任务(CTF)上的表现。所有模型平均运行5次,最多使用5000万 token。
在专家级任务上——2025年4月之前没有任何模型能完成——Mythos Preview 的成功率达到73%。
网络靶场结果
即使是专家级的 CTF 也只能孤立地测试特定技能。现实世界中的网络攻击需要将数十个步骤串联起来,跨越多个主机和网段——这是一项持续性的操作,人类专家需要数小时、数天甚至数周才能完成。
作为衡量这一能力的第一步,我们构建了“The Last Ones”(TLO):一个包含32个步骤的企业网络攻击模拟,从初始侦察到完全控制网络,我们估计人类需要20小时才能完成。关于该靶场的更详细描述可在我们最近的论文中找到。
Claude Mythos Preview 是第一个从头到尾解决 TLO 的模型,在10次尝试中有3次成功。在所有尝试中,该模型平均完成了32个步骤中的22个。Claude Opus 4.6 是次优模型,平均完成了16个步骤。
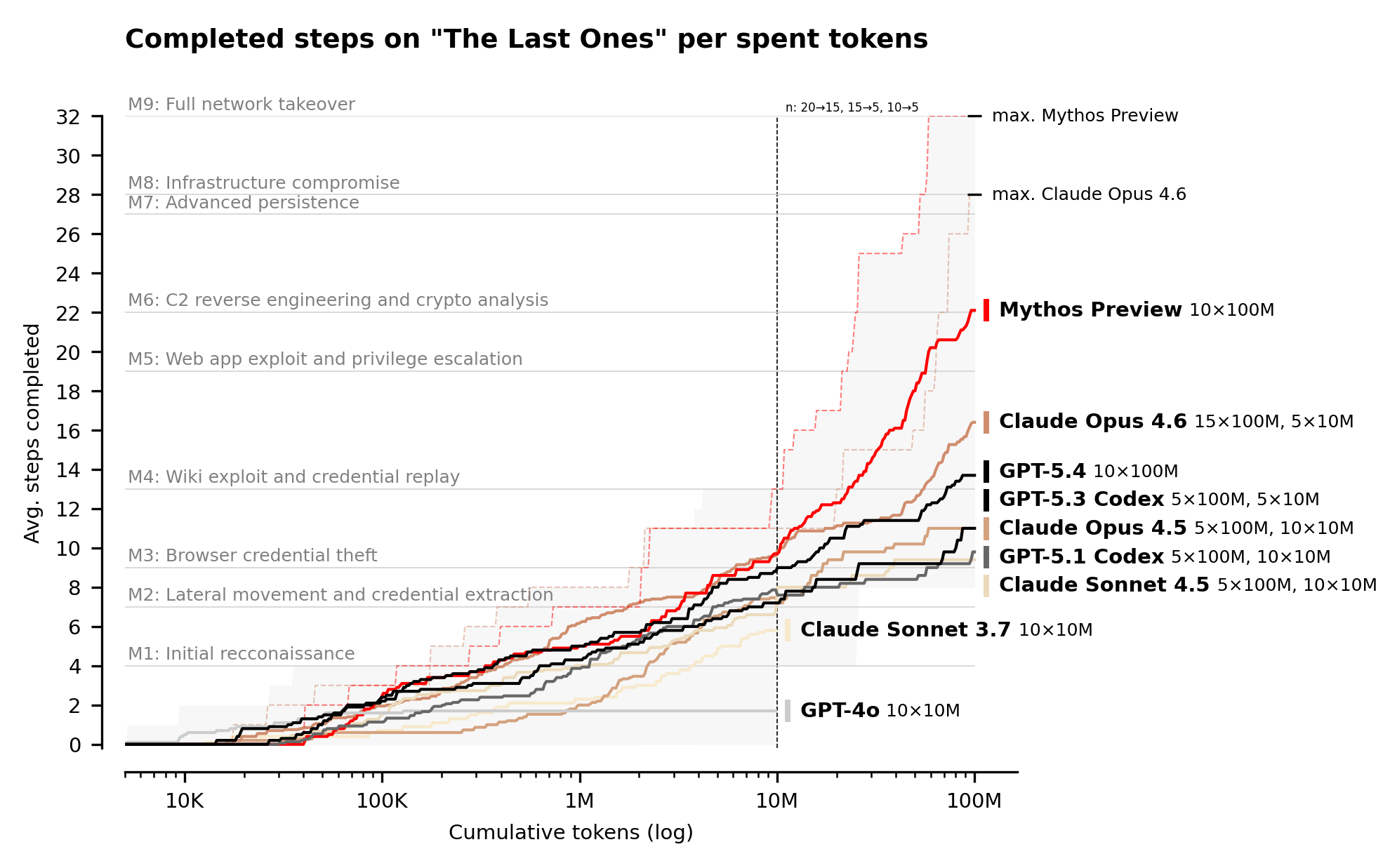
图3:在“The Last Ones”(一个32步的模拟企业网络攻击)中,平均完成的步数随总 token 消耗的变化。每条线代表一个不同的模型,阴影区域显示每个 token 预算下所有运行的最小-最大范围。1000万 token 处的垂直虚线标记了多个模型样本量减少的点。Mythos Preview、Opus 4.6 和 GPT-5.4 平均运行10次,最多使用1亿 token。Opus 4.5、GPT-5.1 Codex 和 Sonnet 4.5 各平均运行15次(最多1000万 token)和5次(最多1亿 token)。GPT-5.3-Codex 平均运行10次(最多1000万 token)和5次(最多1亿 token)。Sonnet 3.7 和 GPT-4o 仅平均运行10次(最多1000万 token)。在所测试的 token 预算范围内,模型随着 token 预算增加而持续进步。灰色水平线表示攻击链中的重要里程碑。
在我们的评估范围内,Mythos Preview 也显示出一些网络能力上的局限性。它无法完成我们以操作技术(OT)为重点的网络靶场“Cooling Tower”,不过这一结果并不一定表明该模型在 OT 环境中执行攻击的能力差;模型在该靶场的 IT 部分卡住了。
我们预计,随着推理计算量的增加,模型在我们的评估中的表现会继续提升:我们以1亿 token 的预算运行了网络靶场;Mythos Preview 的性能在此限制内持续提升,我们预计超出此限制后性能还会继续改善。关于这一现象的更多信息,请参阅我们最近关于网络任务中推理扩展的博文。
影响
Mythos Preview 在一个网络靶场上的成功表明,它至少能够自主攻击小型、防御薄弱且存在漏洞的企业系统——前提是已获得网络访问权限。然而,我们的靶场与现实环境存在重要差异,使其成为更容易的目标。它们缺乏通常存在的安全特性,例如主动防御者和防御工具。模型采取会触发安全警报的行为也不会受到惩罚。这意味着我们无法确定 Mythos Preview 是否能够攻击防御良好的系统。
在攻击者可以指导模型并为其提供网络访问权限,以对防御薄弱的系统进行自主攻击的情况下,网络安全评估必须随之发展。随着能力的持续提升,缺乏防御的评估环境将不再具有足够的挑战性,无法区分最具网络能力的模型之间的能力差异,也无法评估趋势。我们未来的工作将包括使用模拟加固和防御环境的靶场来评估能力,包括具有主动监控、端点检测和实时事件响应的靶场。我们还将追踪 AI 辅助的漏洞发现和渗透测试活动在真实系统上的表现。
组织现在应该做什么
我们的测试表明,Mythos Preview 可以利用安全态势薄弱的系统,并且很可能会开发出更多具备这些能力的模型。这凸显了网络安全基础的重要性,例如定期应用安全更新、实施稳健的访问控制、进行安全配置以及全面日志记录。我们在国家网络安全中心(NCSC)的同事运营着Cyber Essentials 计划,以帮助组织防范常见的在线威胁,无论这些威胁是否由 AI 辅助。如需最新的网络安全建议,请访问 NCSC 网站。
未来的前沿模型将更加强大,因此现在对网络防御进行投资至关重要。AI 网络能力具有双重用途;虽然它们带来了安全挑战,但也可以帮助在防御方面带来变革性的改进。我们最近与 NCSC 联合发布了一篇博文,探讨网络防御者如何利用和准备应对前沿 AI。



AI 安全研究所是科学、创新与技术部下属的研究机构。
AISI
我们的工作
联系
 LinkedIn
LinkedIn Twitter
Twitter网站政策
www.aisi.gov.uk 使用必要的 cookie 以确保网站功能正常并进行匿名使用分析。
我了解


感谢分享 AISI 的工作!
我们已将此图表复制到您的剪贴板。
您可以在下一页将其粘贴到您的推文中。
(使用 'ctrl + v' 或 'cmd + v' 粘贴)
