“无法”论证的安全案例模板
Safety case template for ‘inability’ arguments
英国AI安全研究所(AISI)与AI治理中心合作发表论文,提出一个用于当前AI系统的安全案例模板,聚焦于“能力不足”论证——证明系统能力不足以构成不可接受的网络风险。该模板将总网络风险分解为风险模型,转化为夺旗任务,并确定评估方法。Google DeepMind和Anthropic已在其安全框架中借鉴该方法。AISI指出,该模板对低能力系统有效,但对高能力系统需引入防护措施论证,相关阈值制定仍在进行中。
致读者:我们已于2025年2月14日更名为AI安全研究所。更多信息请点击此处。
安全案例(safety cases)是清晰、可评估的论证,用于证明系统在特定情境下是安全的。在AI安全研究所,我们认为安全案例可以为当前及未来更高能力的系统提供一种可行的AI安全方法。我们的新论文与AI治理中心合作撰写,提供了一个可用于部分当前AI系统的安全案例模板。
为何采用安全案例?
安全案例已广泛应用于汽车(包括自动驾驶)、民航、国防、核能、石化、铁路和医疗行业(Favaro et al., 2023;Sujan et al., 2016;Bloomfield et al., 2012;Inge, 2007)。在前沿AI领域,两家开发者已将安全案例作为其安全方法的一部分:Google DeepMind提议在其前沿安全框架中对未来系统使用安全案例,而Anthropic则指出其负责任扩展政策的最新更新正是受安全案例方法论的启发。
要使安全案例在前沿AI领域取得成功,它们必须既实用又可靠。我们尚不清楚为前沿AI系统编写安全案例的最佳方式。我们需要借鉴其他行业的最佳实践,同时针对AI的特殊情况调整技术。
但如果我们能够找到构建这些论证的好方法,安全案例就可能成为确保前沿AI系统安全性的稳健且灵活的工具。
我们的新模板表明,通过整合现有技术,为当前系统编写安全案例是可行的。
这项工作应被视为概念验证,并聚焦于相关安全论证的一个子集。一个当前系统的完整安全案例还应包含社会技术论证:例如,论证存在适当的组织安全文化,或相关员工具备适当的知识和培训。AISI未来的研究将探讨编写完整安全案例还需要哪些内容,以及更高能力系统的安全案例可能是什么样子。
能力不足论证
我们的论文提供了一个构建"能力不足"论证的模板(Clymer et al., 2024)——即论证AI系统能力不足以构成不可接受的风险水平。在此,我们特别聚焦于论证系统不具备增加网络风险的必要能力,但我们认为该方法在其他领域也应适用。
实际上,每当我们使用能力评估来证明系统安全时,我们就在隐式地使用这种能力不足论证。在本文中,我们通过安全案例模板使该论证显式化。我们认为这具有若干优势:
- 更容易发现和讨论具体的分歧点。通过围绕本文的反馈和讨论,我们已经揭示——并有望开始解决——其中的许多问题。
- 我们可以更容易地识别这种论证在未来系统中可能失效的方式。
模板:我们如何构建案例
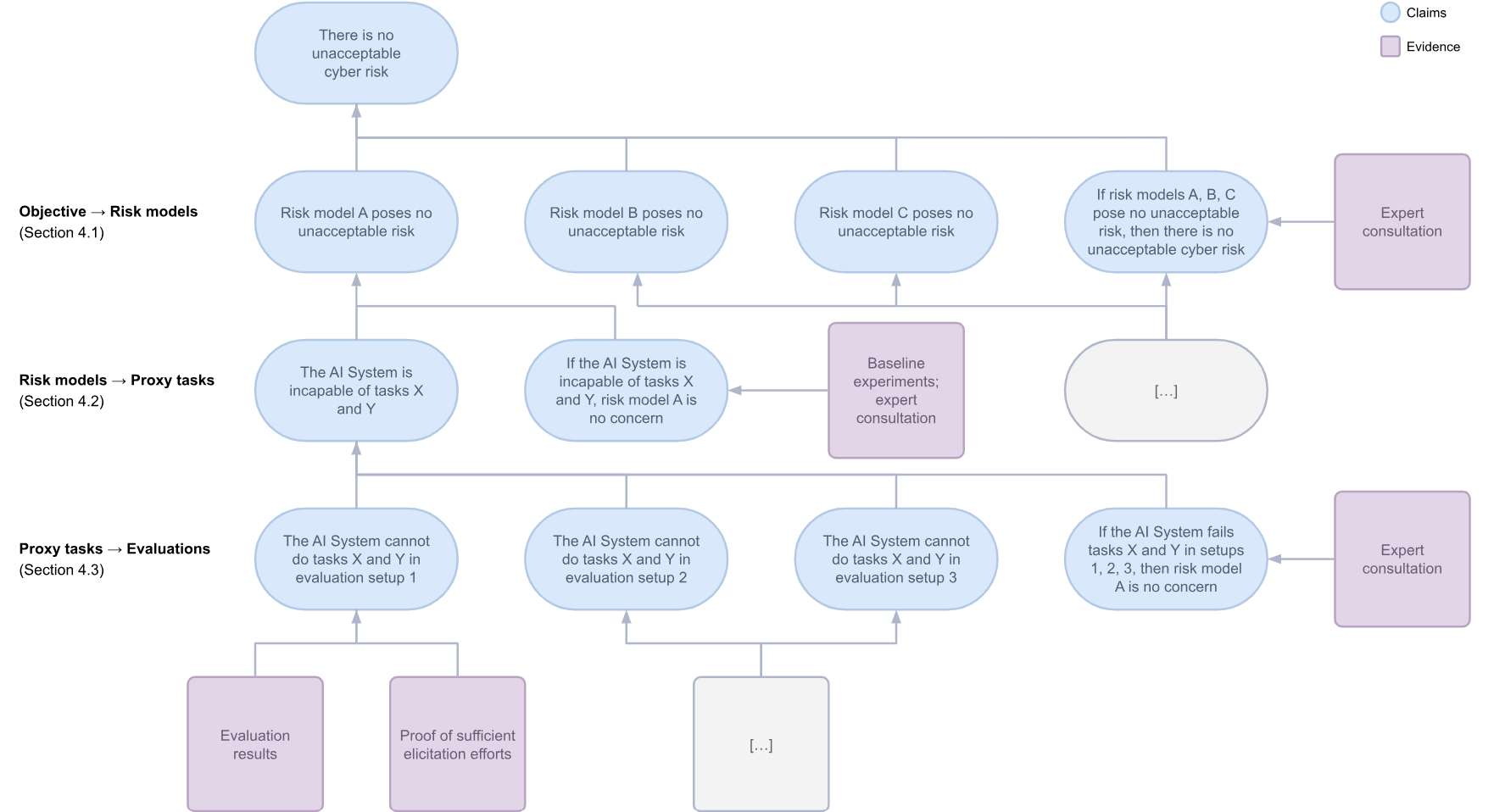
我们提出了一种论证结构,使用Claims、Arguments、Evidence(主张、论证、证据)符号(Bloomfield & Netkachova, 2014)来证明部署AI系统不会构成不可接受的网络风险。
Tweet This Image
Download Image
首先,我们将总网络风险分解为多种风险模型。这些模型由威胁行为者、危害向量和目标组成(例如"AI系统提升非技术专家在关键国家基础设施中发现和利用漏洞的能力")。我们还论证,我们只需关注"最简单"的风险模型——如果我们的系统连最简单的风险行为都无法完成,那么它极不可能完成更困难的行为。
其次,我们将这些风险模型分解为代理的夺旗(capture-the-flag)任务。这些任务可以通过专家输入或基线实验来证明其合理性。
第三,我们为这些代理任务确定评估方法(可以是全自动评估、人工监督的自动评估或人类提升实验)。这些评估需结合对评估充分性的解释——例如,证明评估是按照最佳实践进行的,以防止sandbagging(van der Weij et al., 2024)或平庸的未充分激发。
这种论证是否充分?
对于能力足够低的系统,我们认为该模板提供了一个良好且具有指示性的论证,表明系统能力不足以达到不可接受的不安全程度。
然而,对于更高能力的系统,情况可能不再如此。当能力评估结果接近我们认为系统在未满足更高安全和安保措施标准时应被视为不安全的阈值时,我们对这种能力不足论证的信心应随之降低。例如,我们将越来越不确定评估在多大程度上代表了真实的风险能力,不确定阈值的有效性(特别是系统即使低于这些阈值也可能不安全),也不确定关于系统的其他事实,如sandbagging的可能性。随着能力的提升,这些不确定性将变得更加重要。
因此,对于更高能力的系统,我们需要更复杂的论证来达到对系统安全的充分信心——例如,我们可能论证系统具有适当的防护措施来防止滥用。尽管如此,我们预计这些论证通常仍会依赖某些关于能力不足的主张。例如,使用防护措施防止滥用的论证需要论证系统没有足够的能力故意造成伤害。
AISI正在研究我们可能需要将哪些类型的论证纳入更高能力系统的安全案例中。我们正在研究中等能力的安全案例,其中除了能力不足论证外,还需要防护措施来防止滥用。我们也在研究高能力的安全案例,其中系统本身可能在进行sandbagging评估和/或主动试图破坏防护措施。
在本文中,我们未考虑适当的阈值是什么。在首尔关于推进AI安全、创新和包容性的部长级声明中,包括英国在内的各国同意共同制定这些阈值。这项工作仍在进行中。
对未来的启示
本文代表了安全案例的概念验证。如果我们认为当前系统是安全的,主要是因为它们能力不足以造成伤害,那么我们应该能够使这一论证显式化——我们的模板使这变得更容易。因此,我们相信为当前系统编写安全案例是可能的,并且这在一定程度上可以通过整合政府和公司已经在进行的评估工作来实现。
因此,我们希望看到组织开始将此类模板应用于实际系统。如果您正在考虑为您正在开发的实际AI系统这样做,请告知我们。我们很期待与您合作。