AI系统监管会变得更难吗?
Will it become harder to oversee AI systems?
一份新报告基于对25位专家(来自前沿AI开发者、政府、非政府组织和学术界)的访谈和文献综述,绘制了AI监督格局。报告识别了四个监督面(内部激活、思维链、外部行动、智能体间通信),并指出当前监督方法依赖的AI系统特性(如基于文本的推理)可能退化,存在超过二十条退化路径。专家在潜在推理架构、行动监控、对齐蜜罐及监督训练泛化等问题上存在分歧。报告建议开发者维护现有监督渠道并投资新兴技术作为备用方案。
先进AI系统的安全性越来越依赖于监督能力:在部署前审计模型是否存在令人担忧的倾向,在使用过程中监控其行为,并在事件发生后进行调查。随着AI系统承担更多自主、长周期任务,监督质量将决定我们能在多大程度上信任它们。
在一份新的报告中,我们绘制了当前AI监督的格局及其可能的变化趋势。该报告基于对前沿AI开发者、政府、非政府组织和学术界的25位专家访谈,结合文献综述和对监督退化路径的独立分析。我们识别了当前的监督方法,以及这些方法所依赖的当前AI系统的特性。我们还考察了这些方法可能退化的路径,以及可用于维持它们的技术手段。
文献和专家意见都支持以下结论:当前的监督建立在可能被侵蚀的基础上,而新兴方法尚未成熟到足以弥补这种侵蚀。然而,现在已有可行的干预措施:开发者可以采取措施维护当前的监督渠道,并投资于新兴技术,作为监督退化时的备用方案。
监督面上的压力
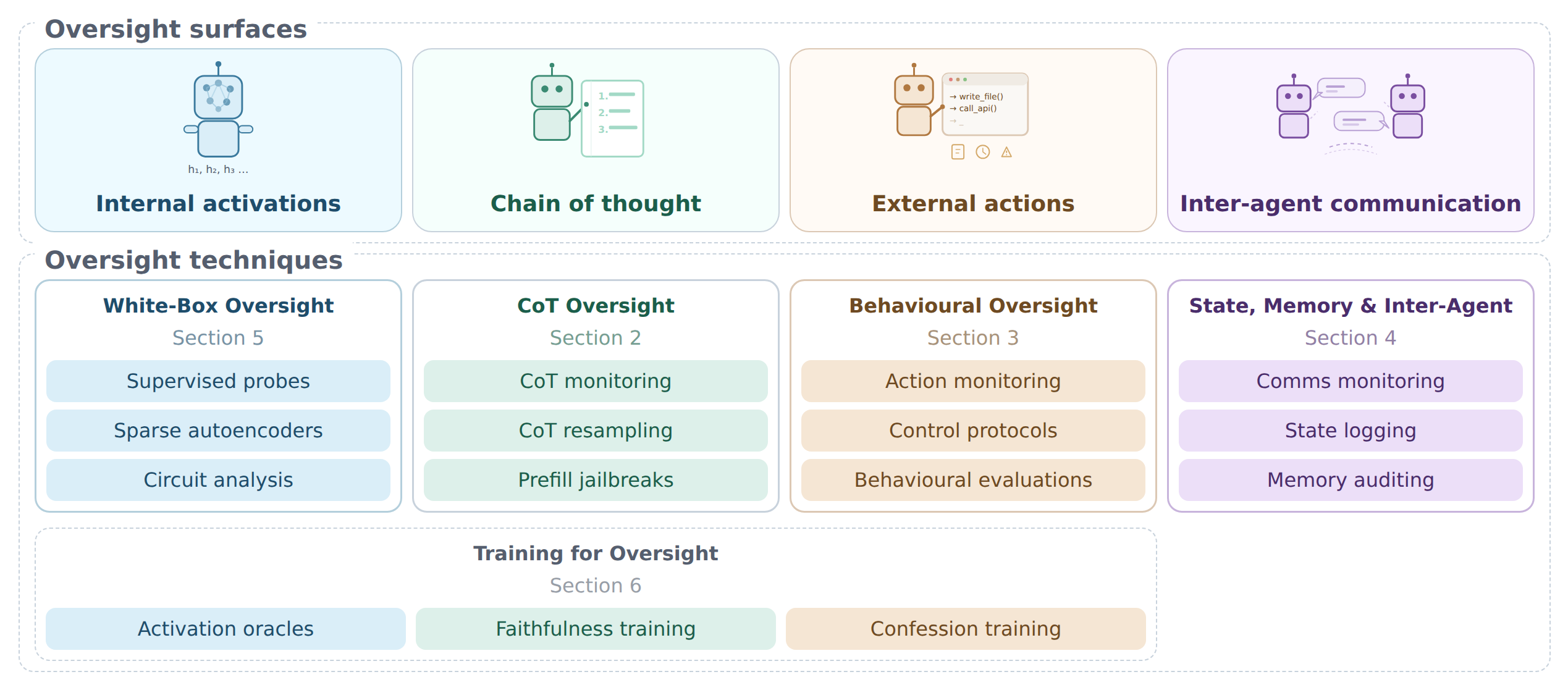
报告识别了四个监督面:
- 内部激活 – AI模型内部计算的特征
- 思维链 – AI系统在处理任务时产生的“思考”文本
- 外部行动 – 系统如何作用于外部世界
- 智能体间通信 – 不同AI系统之间的交互通道
推文此图
下载图片
图1:监督面和技术概览。监督面(顶部)代表监督技术所依赖的AI系统的不同部分。监督技术(底部)作为分层防御应用于这些面,按报告章节分组。基于训练的方法(底行)跨越多个面。列出的监督技术是示例性的,并非详尽无遗。
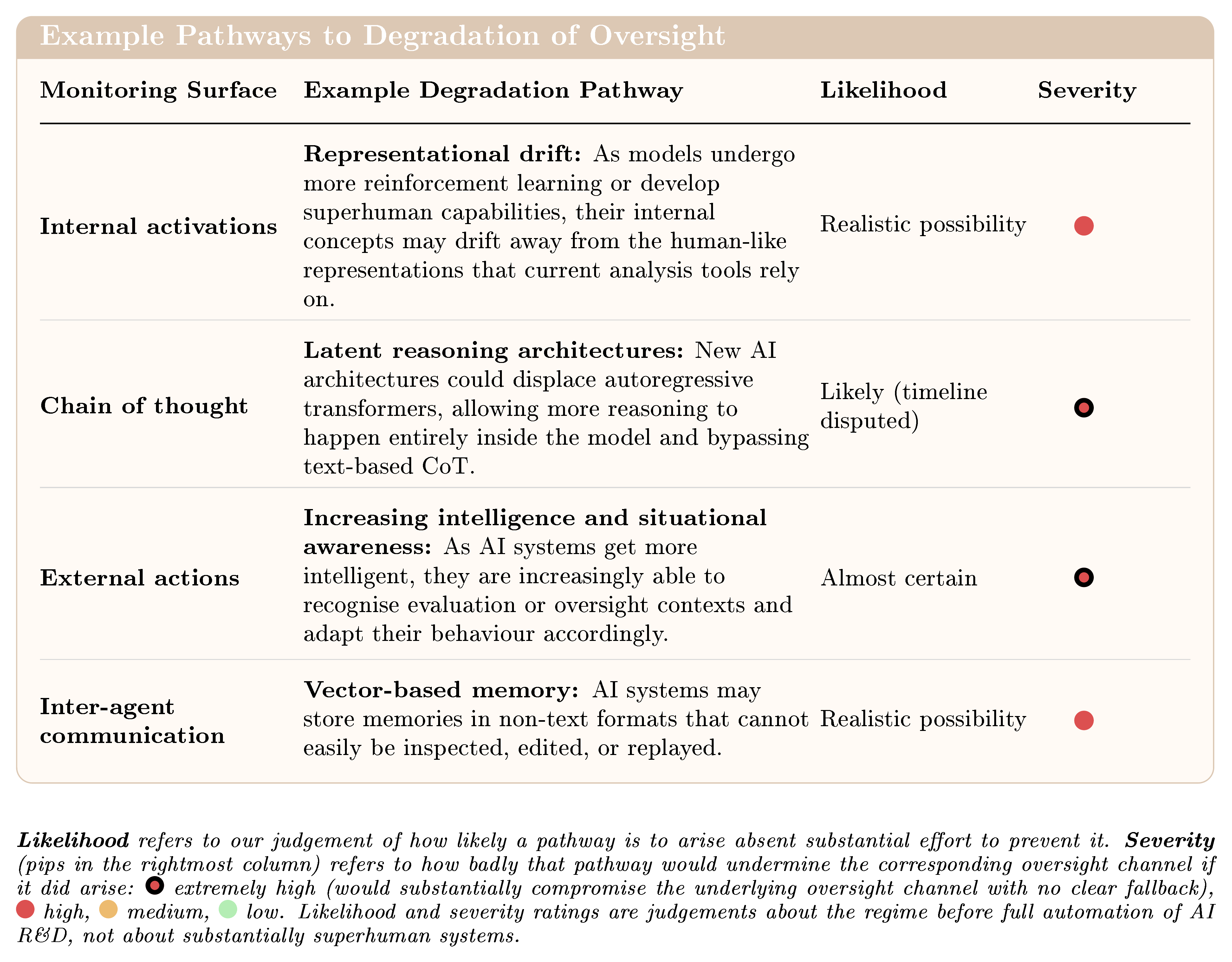
然后我们考察这些监督面未来可能如何退化。参见图2了解退化路径的一些示例:
推文此图
下载图片
图2:监督退化的示例路径。
专家分歧
绘制监督格局的一个重要部分是揭示和探讨专家之间的分歧。一些分歧示例:
- 潜在推理架构是否会占据主导。 潜在推理架构让模型完全在其内部状态中进行推理,而不是以人类可读的文本形式“大声思考”。如果潜在推理架构取代了当今基于文本的推理,我们目前最强大的监督来源之一将消失。
- 行动监控和控制是否足以预防危害。 行动监控仅观察模型的行为,而不观察其推理方式。控制协议在仅行动监控的基础上增加了安全措施,例如阻止、回滚或重新采样可疑输出。这个问题影响开发者能在多大程度上依赖这些部署时的安全措施,而非需要更强有力的前置证据证明模型本身是对齐的。
- 来自不对齐蜜罐的证据是否有意义。 对齐蜜罐是受控场景,旨在在部署前揭示模型的不对齐行为。这个问题影响当前对齐测试在支持关于模型是否安全部署的决策时能有多大权重。
- 针对监督的训练是否会泛化到部署环境。 针对监督的训练是指训练模型本身以支持监督,例如使其诚实,或使其推理更透明。这个问题影响这些行为是在实际使用中保持,还是仅在训练环境中有效。
总体情况
现有的监督技术对当今的AI系统大多效果良好,应用它们仍能获得收益。开发者采用一系列技术,例如监控模型行为、读取模型的思维链推理、运行行为评估以及探测内部激活。然而,使这些技术有效的当前AI系统的特性,例如基于文本的推理、有限的评估博弈能力以及人类可解释的内部表示,都是偶然的,并且随着系统的进一步发展可能不再成立。
报告识别了超过二十条当前监督可能退化的不同路径。一些压力已经可见:例如,前沿模型越来越能够识别自己何时被测试并调整其行为。其他压力,例如能够在隐藏内部状态中进行推理的架构,如果出现将严重削弱当前的监控。这些压力可能叠加,并且由于许多与监督相关的特性并未被常规追踪,一些监督的丧失可能不被察觉。
我们的完整报告概述了开发者和部署者可以主动维护当前可用监督、衡量监督退化风险以及投资于新兴监督技术的机会。
你可以在此处查看完整报告:链接。
你对这类工作感到兴奋吗?加入我们!
如果你是一名研究科学家或研究工程师,我们正在招聘——请在此处申请,来和我们一起工作吧!