VeRL-Omni 发布:扩散与全模态模型的简易、快速、稳定 RL 训练
Announcing VeRL-Omni: Easy, Fast, and Stable RL Training for Diffusion and Omni-Modality Models
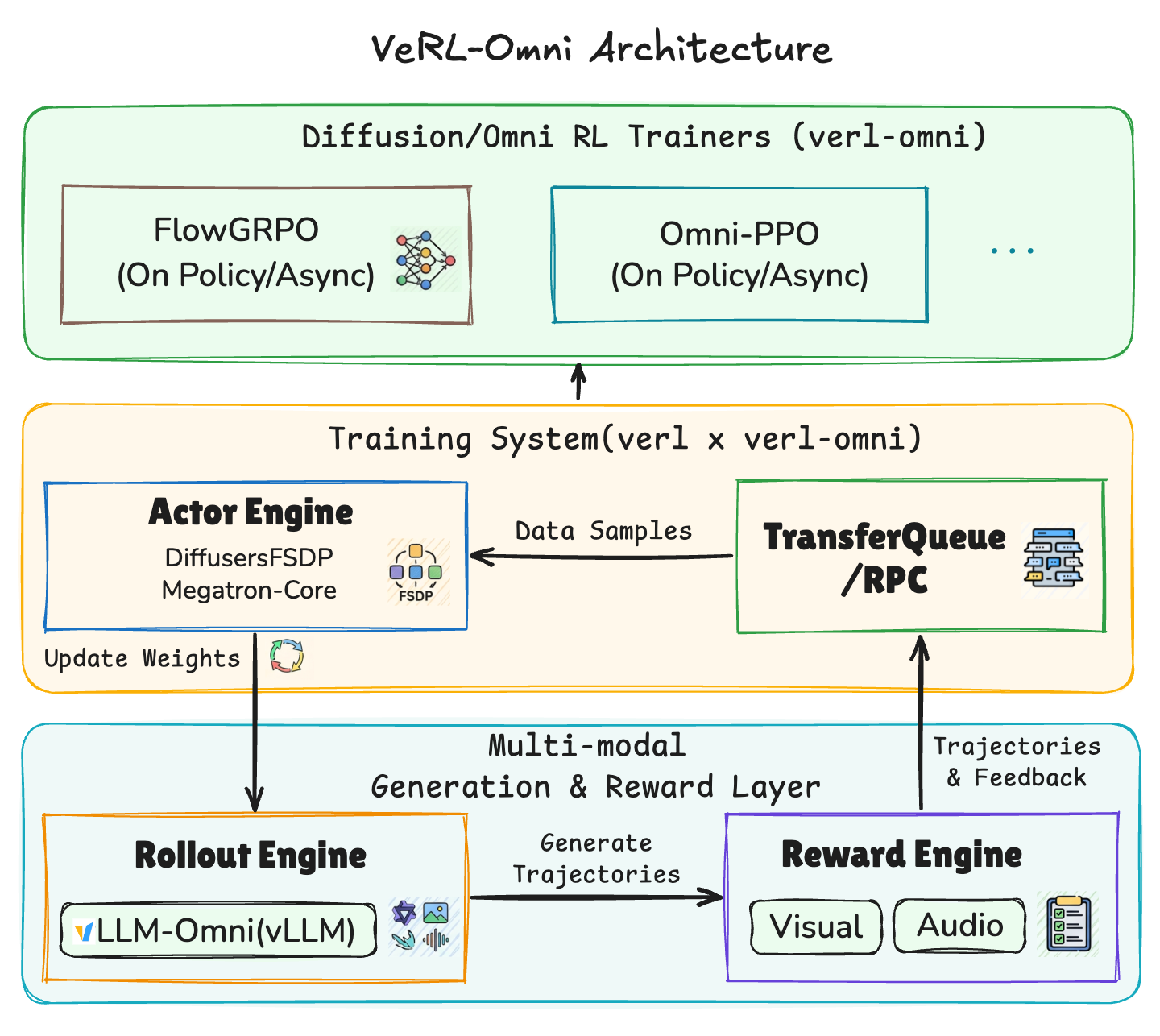
VeRL-Omni 是一个基于 verl 和 vllm-omni 构建的多模态生成模型通用强化学习(RL)后训练框架,支持 diffusion 和全模态模型(如 Qwen-Image、BAGEL、Qwen3-Omni-Thinker)的 RL 训练。其关键特性包括高效的多模态 rollout(集成 vLLM-Omni)、灵活的奖励引擎(支持基于规则和 VLM-as-judge 的模型奖励)、模块化训练后端(DiffusersFSDP/Megatron/VeOmni)以及 NVIDIA GPU 和 Ascend NPU 硬件兼容性。在 4×H200 GPU 上,Qwen-Image 全模型微调达到 0.510 图像/GPU/秒,异步奖励将每步时间减少约 14%。
我们很高兴地宣布 VeRL-Omni 的预发布版本,这是一个基于 verl 和 vllm-omni 构建的、专注于多模态生成模型的通用强化学习(RL)后训练框架。
为什么需要 VeRL-Omni?
RL 已成为将大型生成模型与人类偏好及下游任务奖励对齐的强大方法。虽然 LLM RL 技术栈在过去一年中快速发展,但多模态生成 RL(涵盖用于图像/视频/音频理解与生成的 diffusion 和全模态模型)面临着关键需求:
- Diffusion 和全模态扩展: 将 verl 卓越的灵活性和性能扩展到多模态和非自回归 RL 训练领域,覆盖 diffusion transformer 骨干(Qwen-Image)、混合 AR-DiT 架构(Qwen-Omni)以及统一理解与生成模型(BAGEL、HunyuanImage3.0)。
- 异构 rollout 流水线: Rollout 是连续潜在空间中的_去噪轨迹_,而非 token 序列,并且单个 rollout 可能调用多个异构模型组件和多阶段流水线(例如,文本编码器 → DiT → VAE)。
- 复杂的工作负载调度: 编排复杂的多模态 RL 训练工作流,其中奖励函数本身就是多模态模型(VLM 评判器、OCR 评分器等),并且多模态生成 rollout 相比文本生成具有更高的内存峰值。
关键特性
- 高效的多模态 rollout: 我们集成了 vLLM-Omni,用于高吞吐量的异步多模态生成服务,同时保持与 diffusers 相当的准确性。VeRL-Omni 与 vLLM-Omni 协同工作,通过逐步连续批处理、embedding 缓存等方式持续优化 rollout 效率。
- 灵活的奖励引擎: 涵盖基于规则的奖励和基于模型的奖励(例如,用于 OCR 的 VLM-as-judge)。集成了 vLLM 用于高效的 VLM 和 LLM 奖励模型推理。奖励计算与正在进行的 rollout 和训练过程重叠,以减少端到端延迟。
- 模块化训练后端: 提供多种训练器(DiffusersFSDP/Megatron/VeOmni),内置针对 diffusion 和全模态模型的优化,允许轻松集成不同的并行策略(FSDP/USP/TP)。
- 广泛的硬件兼容性: 支持 NVIDIA GPU 和 Ascend NPU,允许跨不同硬件后端灵活部署。
- 端到端训练配方和基准测试: 提供参考性能结果,得益于上述特性,可实现高训练吞吐量。
算法和模型支持
| 模型 | 架构 | 模态 | 算法 | 状态 |
|---|---|---|---|---|
| Qwen-Image | DiT | 文本 → 图像 | FlowGRPO, MixGRPO, GRPO-Guard | 已发布 |
| BAGEL | 统一理解 + 生成 | 文本 + 图像 | FlowGRPO | PR 就绪 |
| Qwen3-Omni-Thinker | AR | 文本 / 图像 / 视频 / 音频 | GSPO | PR 就绪 |
| Wan2.2 | DiT | 文本 → 视频 | DanceGRPO | 进行中 |
| SD3.5 | DiT | 文本 → 图像 | DPO | 进行中 |
| HunyuanImage-3.0 | 统一理解 + 生成 | 文本 + 图像 | MixGRPO, SRPO | 计划中 |
快速开始
安装
详情请查看我们的安装文档。
训练 diffusion 模型
请查看我们的示例目录,获取用于启动图像/音频/视频理解和生成任务的不同 RL 算法训练器的具体脚本。您可以通过 wandb 跟踪训练性能和结果。
演示:Qwen-Image FlowGRPO 后训练
在 flowgrpo 示例中,我们使用 OCR 奖励任务训练 Qwen-Image。奖励模型是 Qwen3-VL-8B-Instruct,通过读取渲染文本并与数据集真实值进行比较来对生成的图像进行评分。
算法回顾
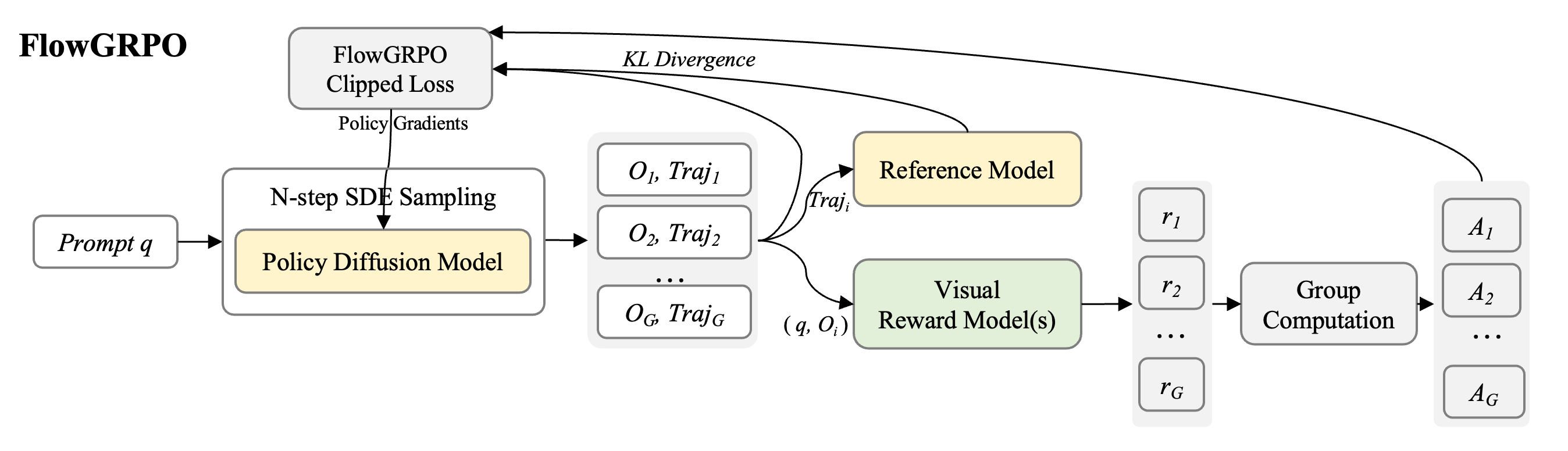
FlowGRPO 算法
FlowGRPO 演示
FlowGRPO 是一种用于 flow-matching 模型的在线策略方法。它采用多步 SDE 采样和 diffusion 策略模型来实现有效的 RL 探索,并使用基于模型的奖励来评估生成质量。训练工作流主要由四个关键阶段组成:
- Rollout 生成: diffusion 策略模型生成样本 rollout,收集对数概率和生成图像的轨迹。
- 奖励模型评分: 奖励模型对每个生成的样本进行评分,从而可以计算轨迹优势。
- 策略优化: 使用 FlowGRPO CLIP 风格损失更新策略,利用计算出的优势优化以获得更高奖励。
- 权重同步: 定期将训练器中的最新策略权重同步到 rollout 工作节点,确保生成的样本反映最新的策略。
LoRA 微调
在 NVIDIA H800 GPU 上的训练吞吐量如下。
| 模式 | # GPU | Actor | Rollout | 异步奖励 | 吞吐量 (图像/GPU/秒) | 每步时间 (秒) |
|---|---|---|---|---|---|---|
| FlowGRPO 共置训练 | 4 | 4 | 4 | 0 (同步) | 0.305 | 420 |
| FlowGRPO 带异步奖励 | 5 | 4 | 4 | 1 (异步) | 0.280 | 360 |
将奖励模型移至其专用 GPU,通过将奖励评估与策略训练重叠,将每步的挂钟时间减少了 ~14%。
全模型微调
我们还在 4 × NVIDIA H200 GPU 上验证了非 CFG 全模型 Qwen-Image OCR 训练,在约 250 秒/步时达到了 0.510 图像/GPU/秒。
如下所示,在 120 个训练步骤中,生成图像的文本渲染质量得到了大幅提升。
| 提示 | 训练步骤 0 | 训练步骤 120 |
|---|---|---|
| 茂密森林中的木质步道标记,木头上刻有 "Hidden Trail",周围环绕着苔藓和树叶。 |  Hidden Trail — 步骤 0 Hidden Trail — 步骤 0 |
 Hidden Trail — 步骤 120 Hidden Trail — 步骤 120 |
| 生日贺卡内部,用草书写着 "Make A Wish",周围环绕着闪烁的蜡烛和五彩纸屑。 |  Make A Wish — 步骤 0 Make A Wish — 步骤 0 |
 Make A Wish — 步骤 120 Make A Wish — 步骤 120 |
以下是来自我们参考运行的奖励和训练曲线。在训练过程中,评判奖励和验证奖励都稳定收敛。
有关训练指标的详细概述,请参阅我们的训练指标文档。
未来路线图
VeRL-Omni 正在积极发展中,目前处于预发布阶段,拥有稳定的核心 diffusion RL 技术栈。我们的路线图侧重于扩展模型和算法支持,并推动高效多模态 RL 训练的边界。
- 模型支持扩展: 支持随着开源 diffusion 和全模态模型的出现而出现的各种模型,涵盖图像/视频/音频生成任务以及统一理解与生成任务。
- 算法支持扩展: 集成随着提出的稳定且先进的 RL 算法,例如 DiffusionNFT。
- 完全异步 RL: 在 actor、rollout 和 reward 之间实现端到端的异步流水线,超越当前的异步奖励设置,以提高训练吞吐量和 GPU/NPU 利用率。
- 与 vLLM-Omni 的协同优化: 生成 rollout 占用了训练时间的很大一部分。我们期望通过与 vLLM-Omni 紧密集成,利用并行化、量化、批处理和优化的请求调度等先进技术,进一步加速多模态 rollout。
- 高效的全模态训练器: 除了 DiffusersFSDPTrainer,我们期望发布更多基于 Megatron-core 和 VeOmni 的高度优化的全模态和 diffusion 模型训练器引擎。
- 更广泛的硬件支持: 继续强化 Ascend NPU 路径,并通过硬件插件系统欢迎额外的硬件后端。
这只是 diffusion 和全模态 RL 后训练的开始。我们正在积极开发对更多架构和算法的支持,并邀请社区共同塑造 VeRL-Omni 的未来。
- 代码:github.com/verl-project/verl-omni
- 文档:verl-omni.readthedocs.io
- 贡献指南: 参见
CONTRIBUTING.md - 每周会议: 每周二上午 11:00(GMT+8:00)加入我们,讨论路线图和功能。在此加入
让我们一起构建全模态 RL 的未来!