vLLM x Novita AI:PegaFlow 实现生产级外部 KV 缓存
vLLM x Novita AI: PegaFlow for Production-Grade External KV Cache
与Novita AI合作,PegaFlow通过外部KV connector接口与vLLM集成,以独立Rust进程实现LLM推理的外部KV缓存服务。它将KV缓存生命周期移出vLLM worker进程,在本地实例和远程节点间池化缓存,并将固定主机内存、RDMA可访问远程内存和SSD组合成三级缓存层次结构。生产评估显示:500 GiB主机KV池由外部缓存服务持有时,vLLM启动速度提升2.15倍;八个Qwen3-8B实例共享一个主机缓存时吞吐量提升56%;使用TP8的DeepSeek-V3.2 MLA吞吐量提升72%;大前缀拉取平均远程读取吞吐量达194 GB/s。
TL;DR: 与 Novita AI 合作,PegaFlow 通过外部 KV connector 接口与 vLLM 集成,作为 LLM 推理的外部 KV 缓存服务,以独立的 Rust 进程实现。它将 KV 缓存的生命周期移出 vLLM worker 进程,在本地实例和远程节点之间池化缓存,并将固定主机内存、RDMA 可访问的远程内存和 SSD 组合成一个三级缓存层次结构。
在生产导向的评估中,该设计实现了:
- 当 500 GiB 的主机 KV 池已由外部缓存服务持有时,vLLM 启动速度提升 2.15 倍。
- 八个 Qwen3-8B 实例共享一个主机缓存而非八个独立缓存时,吞吐量提升 56%。
- 对于使用 TP8 的 DeepSeek-V3.2 MLA,通过将逻辑 KV 存储一次而非每个 TP rank 存储一次,吞吐量提升 72%。
- 在配备每节点 8 x 400 Gbps NIC 的内部 RDMA 集群中,大前缀拉取的平均远程读取吞吐量达到 194 GB/s。
核心思想很简单:KV 缓存应该是一种长期存在的服务资产,而不是绑定到单个推理进程的临时状态。
对于 vLLM 用户而言,重要的是此集成通过现有的 kv_transfer_config 路径暴露。PegaFlow 可以用作外部缓存后端,无需修改 vLLM 源代码或维护长期分支。
为什么 KV 缓存需要进程边界
KV 缓存是生产级 LLM 服务中最昂贵的运行时资产之一。它每台主机可能占用数百 GiB,需要时间分配和预热,并且其生命周期通常长于最初创建它的请求模式。
在传统的进程内设计中,该资产与推理引擎进程紧密耦合。这种耦合在引擎崩溃、滚动升级和模型切换时会变得棘手。当引擎重启时,主机 KV 池也随之消失。当服务集群从一个模型部署切换到另一个时,数百 GiB 的固定内存可能需要重新分配和预热,实例才能再次处理流量。
PegaFlow 通过将 KV 缓存运行时移动到每台机器上的独立守护进程来解决此问题。PegaFlow 服务器拥有主机 KV 池、SSD 缓存、拓扑元数据、RDMA 资源、索引状态和后台任务。vLLM worker 通过数据路径上的 CUDA IPC 和本地控制路径上的 gRPC 连接到本地 PegaFlow 进程。
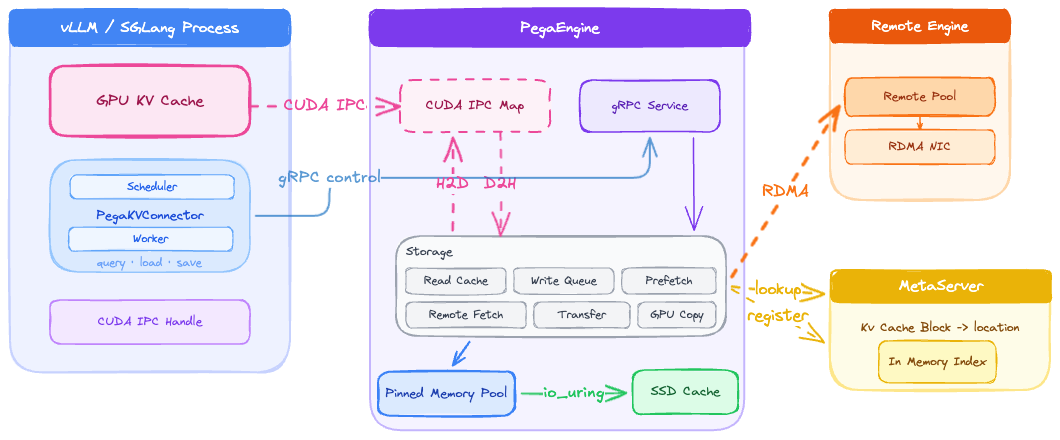
图 1:PegaFlow 作为外部 KV 缓存服务运行在 vLLM 旁边。vLLM worker 通过 CUDA IPC 和 gRPC 与本地 PegaFlow 服务器通信,而 PegaFlow 管理固定内存、SSD 缓存、RDMA 传输以及通过 MetaServer 的可选跨节点索引。
此设计围绕一个生产需求构建:一个缓存服务器应能服务于同一主机上的多个引擎和多个模型。不同的模型、tensor-parallel 配置和引擎版本可以在一个 PegaFlow 进程下共存,通过命名空间隔离,同时共享相同的内存池、SSD 容量和跨节点网络带宽。
由此产生的故障域更加清晰。vLLM 进程可以崩溃、升级或切换模型,而缓存服务保持运行。反之,缓存层的问题也不必导致推理引擎进程宕机。
通过外部缓存所有权实现更快的重启
为了隔离主机 KV 池所有权对启动路径的影响,我们测量了一个 8 x RTX 5090 的设置,运行 Qwen3-8B 并使用 TP8。实验使用了虚拟权重和 eager 模式,以消除权重加载和编译的影响,仅关注大约 500 GiB 主机 KV 池的效果。
使用嵌入式 KV 缓存设计时,500 GiB 池由 vLLM worker 拥有,vLLM 需要 71.4 秒才能达到就绪状态。
使用 PegaFlow 时,500 GiB 池由独立的 PegaFlow 服务器预先拥有。服务器就绪后,vLLM 在 33.2 秒内达到就绪状态。对于此设置,这意味着 vLLM 启动路径快了 2.15 倍,这是通过将长期存在的主机缓存分配与推理进程生命周期解耦实现的。

图 2:具有 500 GiB 主机 KV 池的 vLLM 启动时间。在此设置中,将池保留在外部 PegaFlow 服务器中,可将 vLLM 启动路径从 71.4 秒缩短至 33.2 秒。
Rust 数据路径与尾部延迟稳定性
将 KV 缓存移入外部进程的主要动机是生命周期管理、共享和 CPU 资源隔离。用 Rust 实现该进程还带来了一个重要的运维优势:延迟稳定性。
PegaFlow 的数据平面避免了 Python 解释器开销、GIL 争用和 stop-the-world 垃圾回收。这很重要,因为生产级缓存服务不仅仅在关键路径上移动字节。它还运行后台任务,例如统计信息收集、索引上传、预取、健康检查、指标报告、驱逐和 SSD 缓存管理。
在 PegaFlow 中,这些任务在同一个独立的 Rust 服务中运行,不与 vLLM 共享解释器运行时。这为系统提供了更多空间来运行控制平面和维护工作,而不会干扰数据平面路径。
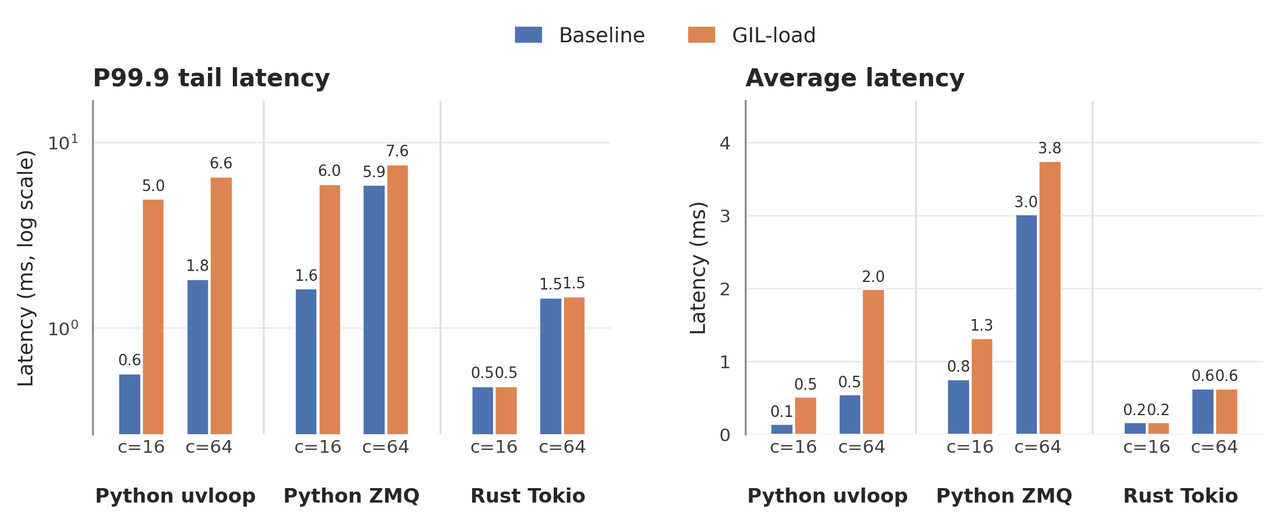
图 3:基线和 GIL 负载条件下的尾部延迟和平均延迟比较。Rust Tokio 路径受后台负载的影响远小于 Python uvloop 和 Python ZMQ 基线。
跨实例和节点的缓存池化
在生产部署中,相同的逻辑 KV 内容经常被多次复制,因为进程、模型或节点边界使得缓存彼此不可见。
这种模式出现在几种常见的部署中:
- 一台主机上的多个小模型实例。 在 8-GPU 主机上运行八个 Qwen3-8B 实例可能会将相同的系统提示词存储八次。
- 广泛的 expert-parallel 部署。 同一台机器上的多个数据并行副本维护着独立的前缀缓存,即使它们运行在同一个物理主机上。
- 使用 tensor parallelism 的 MLA。 对于 DeepSeek-V3.2 等模型,逻辑潜在 KV 可以存储一次,但进程内 TP8 部署可能会在每个 rank 上物理存储一次。
- 跨节点调度。 一个请求可能在节点 A 上有缓存命中,但如果节点 A 过载且请求被路由到节点 B,则前缀可能需要从头开始重新计算。
PegaFlow 将这些孤立的缓存片段转变为共享缓存池。
在单台主机上,所有本地实例连接到同一个 PegaFlow 服务器并共享一个 CPU KV 池。对于多实例小模型服务、WideEP 数据并行副本和 TP worker,相同的块可以在物理上存储一次,并被多个引擎重用。
跨主机,PegaFlow MetaServer 维护一个近似的全局索引。节点可以通过单边 RDMA READ 获取远程 KV 块,连接建立后远程端无需 CPU 参与。因此,远程命中可以更像本地命中一样使用,避免了昂贵的 prefill 重新计算。
结果
以下实验保持缓存预算固定,仅改变该缓存跨 vLLM 进程、tensor-parallel rank 或节点的可见性。
单节点多实例共享
我们在同一台主机上使用相同的 500 GiB 缓存预算评估了八个 Qwen3-8B 实例。
| 设置 | 缓存布局 | 吞吐量 | 平均 TTFT | 请求命中率 |
|---|---|---|---|---|
| PegaFlow | 500 GiB 共享池 | 11.97 req/s | 5.26 s | 52.35% |
| 进程内 | 8 x 62.5 GiB 独立池 | 7.68 req/s | 8.22 s | 11.77% |
重要的一点不是系统使用了更多内存。它没有。相同的 500 GiB 预算变得更有用,因为请求可以从一个共享池中获取,而不是八个独立的池。吞吐量提升了 56%,平均 TTFT 下降了 36%,请求命中率提升了 4.4 倍。
MLA 逻辑 KV 去重
我们还评估了在 500 GiB 缓存预算下使用 TP8 的 DeepSeek-V3.2 MLA。
| 设置 | 缓存布局 | 吞吐量 | 平均 TTFT | 请求命中率 |
|---|---|---|---|---|
| PegaFlow | 逻辑 KV 存储一次 | 1.81 req/s | 35.66 s | 97.23% |
| 进程内 | KV 按 TP rank 存储 | 1.05 req/s | 60.88 s | 65.18% |
对于此工作负载,避免跨 TP rank 重复存储有效地扩展了可用缓存容量。吞吐量提升了 72%,平均 TTFT 下降了 41%,请求命中率接近该 trace 的实际上限。

图 4:两个固定预算本地共享实验的总结。在这两种情况下,PegaFlow 通过使相同的 KV 预算跨隔离边界可见,提高了有效缓存容量。
跨节点 RDMA 共享
在一个配备每节点 8 x 400 Gbps RDMA NIC 的内部生产推理集群中,我们采样了数千次最近的在线远程读取。对于至少 1 GiB 的大前缀拉取,PegaFlow 在生产流量下维持了 194 GB/s 的平均有效吞吐量,P99 为 250 GB/s,峰值为 261.6 GB/s。
在此传输速率下,一个 24 GiB 的 KV 缓存段可以在大约 100 毫秒内从远程节点拉取。这可以替代原本需要消耗数秒 GPU 时间的 prefill 计算。在实践中,这就是远程命中有价值的原因:它们不仅仅是"比未命中好";它们可以快到足以成为服务路径的一部分。

图 5:内部生产集群中大型远程 KV 缓存读取的有效吞吐量。在测得的平均吞吐量下,一个 24 GiB 的远程 KV 段可以在大约 100 毫秒内获取。
三级缓存层次结构
池化使缓存容量更有用,但主机内存仍然是有限的。长重用距离的前缀可能在下次使用前被驱逐,而简单的 LRU 可能会被扫描式流量严重干扰,因为许多一次性块会通过系统。
PegaFlow 通过三级缓存层次结构解决此问题。热本地块保留在固定 DRAM 中,远程命中可以通过 RDMA 获取,而较冷的可重用块可以溢出到本地 SSD:
| 层级 | 介质 | 访问路径 | 典型角色 |
|---|---|---|---|
| L1 | 本地固定 DRAM | 本地内存 | 快速本地 KV 重用 |
| L2 | 远程 DRAM | RDMA READ | 跨节点缓存共享 |
| L3 | 本地 SSD | io_uring | 大容量溢出 |
SSD 缓存是在 io_uring 之上用 Rust 实现的。在内部测试中,单个 SSD 提供了大约 6.9 GB/s 的峰值读取吞吐量。PegaFlow 将在线稳态吞吐量保持在每磁盘约 6.5-6.6 GB/s,用大约 5% 的峰值带宽换取更稳定的尾部延迟。通过跨多个磁盘的 RAID0,总吞吐量近似线性扩展。
对于扫描密集型工作负载或缓存预算较小的主机,PegaFlow 可以启用 TinyLFU 准入策略。此策略仅在块可能被重用时才准入,从而保护缓存免受一次性流量的影响。
TinyLFU 默认是禁用的,因为最佳准入策略取决于工作负载形态。然而,在几个内部 trace 中,当缓存较小或扫描压力较高时,其性能显著优于 LRU。
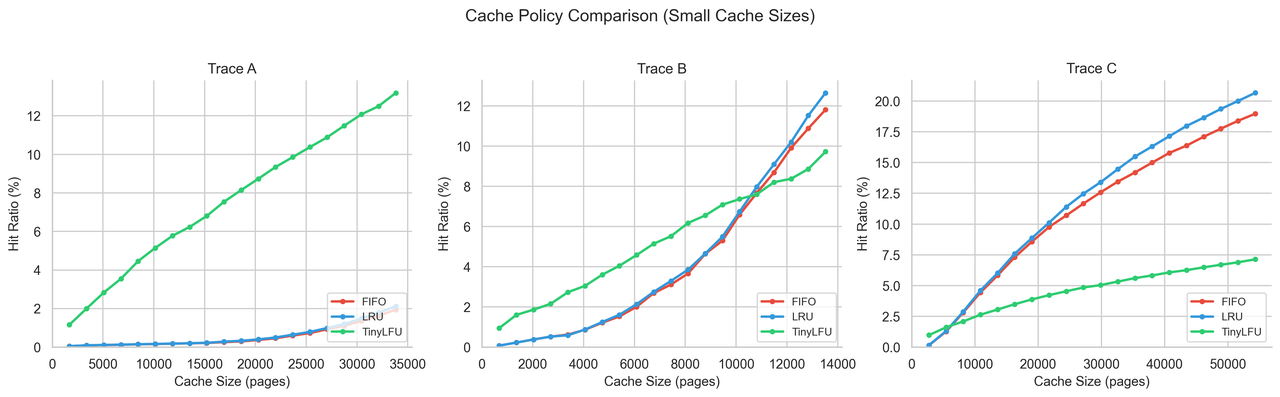
图 6:小缓存大小下的缓存策略比较。扫描密集型 trace 可能使简单的基于最近使用情况的策略失效,而像 TinyLFU 这样的准入感知策略可以保护缓存免受一次性块的冲击。
衡量与理论命中率上限的距离
仅看在线命中率可能具有误导性。对于重用率很低的工作负载,3% 的命中率可能很好,而 90% 的命中率如果工作负载的理论上限高得多,则可能仍有很大提升空间。
对于运维人员来说,有用的问题不仅仅是"命中率是多少?"而是"我们离该工作负载合理能达到的最佳命中率有多近?"
PegaFlow 使用 HyperLogLog 在线估计理论命中率上限:
r* = (N - U) / N
这里,N 是一个窗口内的总块请求数,U 是首次出现的唯一块数。HyperLogLog 使此估计成本低廉:一个 24 小时的窗口使用不到 1 MiB 的内存,误差约为 0.8%。
PegaFlow 导出滚动 HLL 窗口,默认值为 15 分钟、1 小时和 24 小时。通过将测量的命中率和理论上限放在同一个仪表板上,运维人员可以区分三种情况:
- 缓存已接近工作负载上限,因此增加容量可能帮助不大。
- 测量的命中率远低于上限,表明在容量、准入、预取或跨节点发现方面有改进空间。
- 理论上限本身就很低,表明工作负载的重用有限,瓶颈主要不在于缓存实现。
通过外部 connector 与 vLLM 集成
外部 KV 缓存系统通常需要对调度器、块管理器或 attention 内核进行侵入式更改。而 PegaFlow 则通过 vLLM 的外部 KV connector 机制进行集成。
该 connector 通过 kv_transfer_config 配置,外部包可以使用 kv_connector_module_path 动态加载。这使得 PegaFlow 可以在运行时接管关键的 KV 缓存操作,而无需修改 vLLM 源代码或维护长期分支。
从 vLLM 的角度来看,PegaFlow 不是服务引擎的替代品。它是一个通过 KV 传输接口附加的外部缓存后端,而 vLLM 继续处理调度、模型执行、批处理和兼容 OpenAI 的服务路径。
这种边界对两个项目都有利。PegaFlow 可以独立迭代其 Rust 数据平面、SSD 缓存、RDMA 路径、索引和 connector 逻辑。vLLM 可以继续改进核心服务引擎,同时为外部缓存系统暴露一个稳定的 connector 契约。
快速开始
为您的 CUDA 版本安装包:
uv pip install pegaflow-llm # CUDA 12
uv pip install pegaflow-llm-cu13 # CUDA 13
使用固定主机内存和 SSD 缓存启动单节点 PegaFlow 服务器:
pegaflow-server \
--pool-size 30gb \
--ssd-cache-path <ssd-cache-file-path> \
--ssd-cache-capacity 512gb
对于在线部署,我们建议添加 --use-hugepages。应预先预留大页。它们可以加速 CPU 固定内存分配,并通过降低注册和传输期间的地址转换开销来减轻 RDMA MTT 压力。
对于多节点部署,首先启动 MetaServer,然后在每个节点上使用 RDMA 配置启动 PegaFlow 服务器。当启用 P2P 时,每个 PegaFlow 服务器的 --addr 必须是可路由的 IP 地址,而不是 0.0.0.0 或 127.0.0.1,因为其他节点会使用它进行 gRPC 握手和块查询。
pegaflow-metaserver --addr 0.0.0.0:50056
pegaflow-server \
--addr this-node:50055 \
--pool-size 30gb \
--ssd-cache-path <ssd-cache-file-path> \
--nics mlx5_0 mlx5_1 \
--metaserver-addr http://metaserver-host:50056
无需修改 vLLM 源代码即可连接 vLLM。本文中的示例使用 vllm>=0.20.0:
vllm serve <model> \
--kv-transfer-config '{
"kv_connector": "PegaKVConnector",
"kv_role": "kv_both",
"kv_connector_module_path": "pegaflow.connector"
}'
PEGAFLOW_HOST 和 PEGAFLOW_PORT 环境变量将 connector 指向 PegaFlow 服务。默认情况下,它们分别是 http://127.0.0.1 和 50055。
公共参考基准测试
PegaFlow 仓库还包含一个在 H800 上使用 Llama-3.1-8B 的公共 KV 缓存基准测试,使用 8 个提示词、10K token prefill、1 token decode 和 4.0 req/s。在该设置中,热缓存路径将平均 TTFT 从 572.5 ms 降低到 61.5 ms,P99 TTFT 从 1113.7 ms 降低到 77.0 ms。
尝试 PegaFlow
PegaFlow 可在 GitHub 上获取:novitalabs/pegaflow。该仓库包含安装说明、服务器配置、P2P RDMA 设置、指标文档和 vLLM connector 示例。
致谢
我们感谢 Novita AI 团队构建并产品化 PegaFlow,以及 vLLM 维护者和更广泛的 vLLM 社区,感谢他们的讨论、审查和使此集成成为可能的 connector 基础设施。