EAGLE 3.1:EAGLE团队、vLLM与TorchSpec协作推进推测解码
EAGLE 3.1: Advancing Speculative Decoding Through Collaboration Between the EAGLE Team, vLLM, and TorchSpec
EAGLE 团队、vLLM 团队和 TorchSpec 团队联合发布EAGLE 3.1,一种推测解码算法。EAGLE 3.1针对EAGLE 3中因attention drift(注意力漂移)导致的不稳定性,引入FC归一化与后归一化hidden state反馈两项架构改进。在长上下文任务中,EAGLE 3.1的接受长度较EAGLE 3最高提升2倍。基于TorchSpec和vLLM,团队为Kimi K2.6训练并开源了EAGLE 3.1草稿模型(lightseekorg/kimi-k2.6-eagle3.1-mla)。在SPEED-Bench编码任务中,使用vLLM(TP=4, GB200)时,EAGLE 3.1在并发数为1时实现2.03倍单用户输出吞吐量提升,并发数为4和16时分别为1.71倍和1.66倍。该支持已集成至vLLM主分支,并将随v0.22.0版本发布。
EAGLE 系列——包括 EAGLE 1、EAGLE 2 和 EAGLE 3——已成为研究和生产系统中应用最广泛、实际部署最多的推测解码算法家族之一。
今天,EAGLE 团队、vLLM 团队 和 TorchSpec 团队 共同宣布推出 EAGLE 3.1——这是推测解码在鲁棒性、效率和可部署性方面迈出的重要一步。
EAGLE 3.1 创新
尽管推测解码在受控环境下表现良好,但在不同的聊天模板、长上下文输入或分布外系统提示下,性能往往会下降。
EAGLE 团队将这种不稳定性追溯到一个我们称之为 attention drift(注意力漂移) 的现象——随着推测深度的增加,草稿模型逐渐将注意力从 sink token 转移到自身生成的 token 上。
我们识别出两个根本问题。首先,融合输入表示变得越来越不平衡,因为更高层的 hidden state 主导了草稿模型的输入。其次,由于未归一化的残差路径,hidden state 的幅度在推测步骤中不断增长。这些效应共同导致草稿模型在更深推测深度下逐渐变得不稳定。
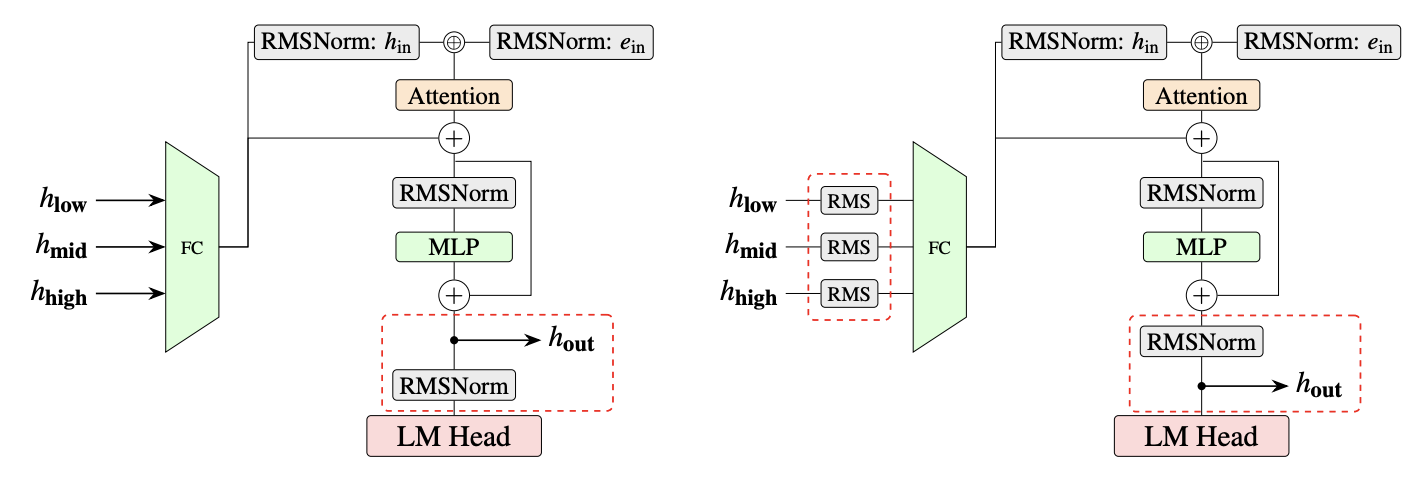
图 1:EAGLE 3 与 EAGLE 3.1 架构对比。EAGLE 3.1 在每个目标 hidden state 之后添加了 FC 归一化,并将归一化后的 hidden state 送入下一个解码步骤。
为解决这一问题,EAGLE 3.1 引入了两项关键的架构改进:
- 在每个目标 hidden state 之后、FC 层之前进行 FC 归一化
- 将归一化后的 hidden state 送入下一个解码步骤
直观上,后归一化设计使得该方法更像是在解码步骤间递归调用草稿模型,而非简单地在目标模型上附加更多层。
这些改进显著提升了跨部署场景的鲁棒性。与 EAGLE 3 相比,EAGLE 3.1 展现出:
- 更好的训练时到推理时外推能力
- 更强的长上下文鲁棒性
- 对聊天模板和系统提示变化的更高容忍度
- 在不同服务环境中更稳定的接受长度
在长上下文任务中,与 EAGLE 3 相比,EAGLE 3.1 的接受长度最高可提升 2 倍。
使用 TorchSpec 训练 EAGLE 3.1
TorchSpec 现已为 EAGLE 3.1 及未来的推测解码算法提供高效的训练支持。
通过降低训练开销和简化实验流程,TorchSpec 有助于加速下一代推测解码的研究迭代与部署。
基于 TorchSpec 和 vLLM,我们还为 Kimi K2.6 训练并开源了一个 EAGLE 3.1 草稿模型:
https://huggingface.co/lightseekorg/kimi-k2.6-eagle3.1-mla
该模型展示了如何在实际服务模型上,通过 TorchSpec 训练和 vLLM 服务支持来部署 EAGLE 3.1。
EAGLE 3.1 与 vLLM 的集成
EAGLE 3.1 以 配置驱动扩展 的形式集成到 vLLM 中,作为现有 EAGLE 3 实现的补充。
集成内容包括:
- FC 归一化支持
- 后归一化 hidden state 反馈
- 移除关于目标 hidden state 的硬编码假设
同时,与现有 EAGLE 3 检查点的向后兼容性得到完全保留。因此,EAGLE 3.1 草稿模型可以直接通过相同的推测解码代码路径接入,例如:
vllm serve nvidia/Kimi-K2.6-NVFP4 \
--trust-remote-code \
--tensor-parallel-size 4 \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2 \
--attention-backend tokenspeed_mla \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}' \
--language-model-only
这使得生产环境中 vLLM 服务的草稿模型升级变得平滑且简单。
该支持已合并到 vLLM 当前的主分支,并将通过 vLLM 的 nightly 版本以及即将发布的 v0.22.0 版本提供。
作为早期数据点,我们在 SPEED-Bench 编码数据集上,使用 vLLM(TP=4, GB200, 非分离式)对 Kimi K2.6 EAGLE 3.1 草稿模型在 Kimi-K2.6-NVFP4 上进行了基准测试。EAGLE 3.1 在并发数为 1 时实现了 2.03 倍的单用户输出吞吐量提升,并且随着并发数增加,加速效果依然显著(C=4 时为 1.71 倍,C=16 时为 1.66 倍)。
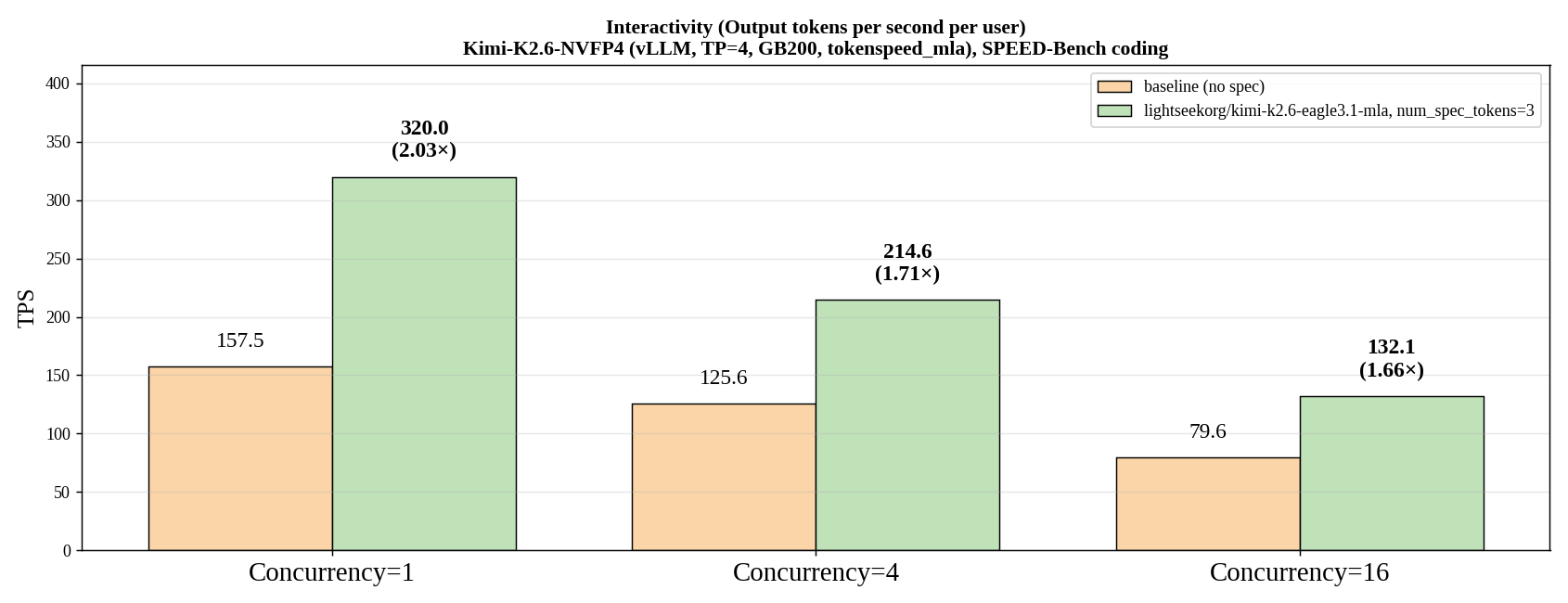
图 2:在 Kimi-K2.6-NVFP4 上使用 vLLM(TP=4, GB200)在 SPEED-Bench 编码任务中的单用户输出吞吐量(TPS)。EAGLE 3.1-MLA 与无推测基线对比。
跨生态系统的开源协作
EAGLE 团队、vLLM 团队和 TorchSpec 团队之间的这次合作,是算法研究、系统优化和训练基础设施之间开源协作的一个有力例证。
EAGLE 团队持续推动推测解码算法的进步,vLLM 帮助将这些创新大规模引入生产推理系统,而 TorchSpec 则为未来的推测解码算法提供了高效的训练和快速实验能力。
我们共同希望继续提升推测解码的整体基线水平,并在更广泛的 LLM 生态系统中推动 token 效率的进一步改进。