使用 vLLM、推测器与 LLM Compressor 加速 Laguna XS.2 推理
Accelerating Laguna XS.2 Inference with vLLM, Speculators, and LLM Compressor
Poolside 发布 Laguna XS.2,一个 33B-A3B MoE 开放权重模型,专为 agentic 编码和长周期软件任务设计。Red Hat AI 与 Poolside 合作,提供 vLLM 集成、基于 DFlash 算法的 speculator 检查点(5 层 0.6B draft 模型,单次前向传播预测 8 个 token,推理速度提升 2-3 倍),以及使用 LLM Compressor 构建的 FP8、NVFP4、INT4/INT8 量化检查点,均针对实际 agentic 应用优化了速度和效率。
随着组织越来越多地采用 AI 驱动的开发工具,对兼具准确性和运行效率的高性能 agentic 模型的需求变得至关重要。Laguna XS.2 是 Poolside 在 Laguna 系列中推出的首个开放权重模型:一个专为 agentic 编码和长周期软件任务构建的 33B-A3B MoE 模型。作为 Laguna XS.2 发布的一部分,Red Hat AI 与 Poolside 在服务和推理优化方面展开合作,包括一流的 vLLM 集成、一个 DFlash speculator 检查点,以及使用 LLM Compressor 构建的量化检查点。此次发布代表了生产级 AI 部署的一个重要里程碑,Laguna XS.2 的量化与 speculator 检查点针对实际 agentic 应用中的速度和效率进行了优化。
通过 vLLM 集成实现无缝推理
与 Poolside 合作,Laguna XS.2 在发布时便作为一流公民直接集成到 vLLM 中,从而能够通过标准 vLLM API 立即部署。
使用 DFlash 推测解码优化性能
为了进一步加速推理,Red Hat 团队使用 Speculators 库为 Laguna XS.2 训练了一个 DFlash speculator。
DFlash 算法是当前推测解码领域的最先进技术。该模型使用一个仅有 5 层、0.6B 的 draft 模型,并接收来自目标 Laguna XS.2 模型的隐藏状态输入,通过单次前向传播预测一个 token 块。随后,这些 token 由 Laguna XS.2 模型通过单次传播进行验证。这一验证步骤保证了与单独使用大模型相同的生成质量;如果 token 被接受,那么每个 token 的生成速度将远快于使用 Laguna XS.2 自回归地逐个生成 token。关键在于训练 DFlash 准确预测 Laguna XS.2 可能接受的 token。
该模型在来自 Ultrachat 200k SFT 和 Magpie-Align 的 50 万个样本上进行了训练。从每个数据集中采样 prompt,并使用 Laguna XS.2(启用思考模式)重新生成响应。随后,模型使用余弦调度器训练了 6 个 epoch,最大学习率为 6e-4,序列长度为 8192,每个序列随机采样 3072 个块位置。
结果是一个 5 层的 draft 模型,能够通过单次前向传播预测 8 个 token。当与 Laguna XS.2 一起验证时,它能够以 2-3 倍的速度提供 token,并且可证明生成质量没有损失。
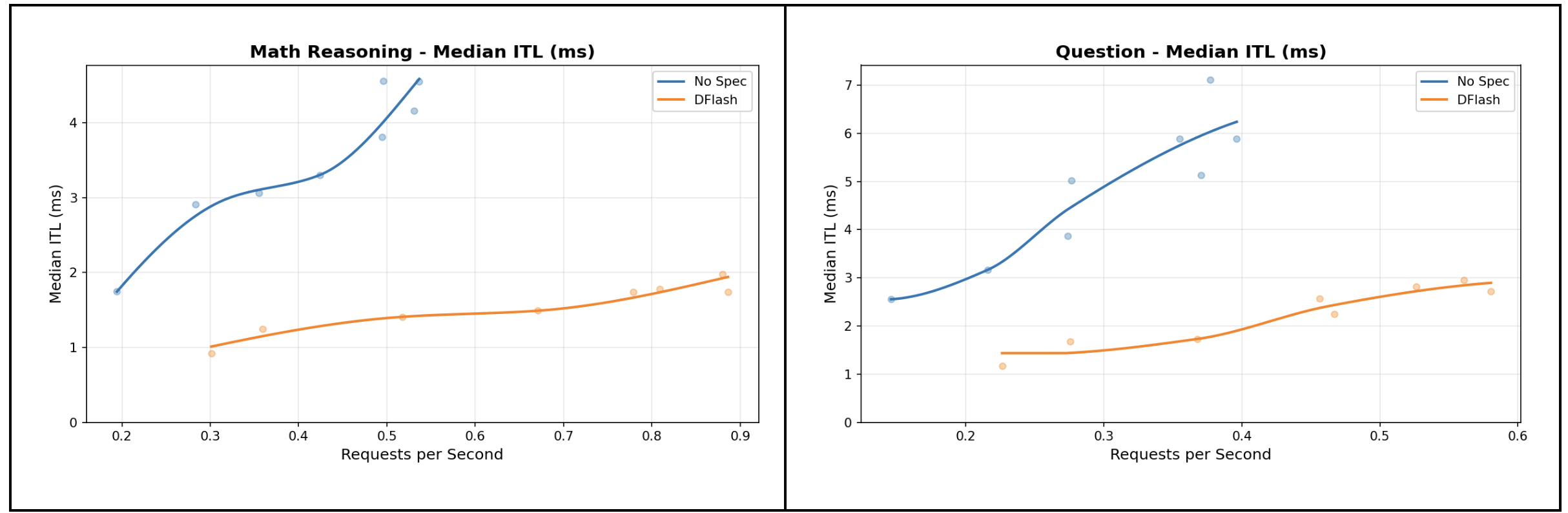 DFlash 算法代表了推测解码的下一代技术,超越了 Eagle-3 范式,提供更快的并行起草,显著减少了 token 间延迟。要亲自测试 speculator,请查看 vLLM 配方。
DFlash 算法代表了推测解码的下一代技术,超越了 Eagle-3 范式,提供更快的并行起草,显著减少了 token 间延迟。要亲自测试 speculator,请查看 vLLM 配方。
使用 LLM Compressor 的量化检查点
Poolside 团队还使用 LLM Compressor 库发布了量化的 Laguna XS.2 检查点。这些检查点包括 FP8、NVFP4、INT4/INT8 变体,采用 compressed-tensors 格式,以便在 vLLM 中实现高效部署,同时保持模型质量。
LLM Compressor 提供了一个灵活的框架,用于对 LLM 应用各种量化技术。借助这些检查点,开发者可以选择最适合其硬件、延迟和内存需求的 Laguna XS.2 变体。
后续步骤
- 在 Hugging Face Hub 上探索 Laguna XS.2 模型
- 使用 LLM Compressor 和 Speculators 优化您自己的模型