vLLM 中的原生 RL API
Native RL APIs in vLLM
vLLM 针对强化学习(RL)后训练工作负载引入两项改进:一是原生权重同步API,通过可插拔的WeightTransferEngine抽象支持NCCL和IPC后端,为RL框架提供标准化的权重传输接口;二是改进异步RL支持,新增keep模式的暂停/恢复功能,并修复了DPEP部署中的死锁问题。SkyRL和Prime-RL团队已在Qwen3-1.7B和GLM-5.1-FP8模型上验证了这些API的稳定性。
随着后训练工作负载持续扩展,我们观察到 vLLM 被广泛采用作为首选推理引擎。然而,有两个问题反复出现:
- 训练与推理之间的权重同步以临时方式实现,并在不同框架间重复。
- 异步 RL 设置在大规模下变得脆弱,尤其是在 P/D 和 DPEP 部署中。
在本文中,我们介绍 vLLM 中的两项改进:
- 原生权重同步 API,为 RL 框架提供标准接口。
- 改进的异步 RL 支持,包括新的暂停模式以及 DPEP 设置中死锁问题的修复。
vLLM 中的原生权重同步 API
背景
在在线 RL 设置中,vLLM 模型权重必须定期同步,以确保生成的 rollout 来自最新或近期版本的模型权重,从而提供更有用的反馈。
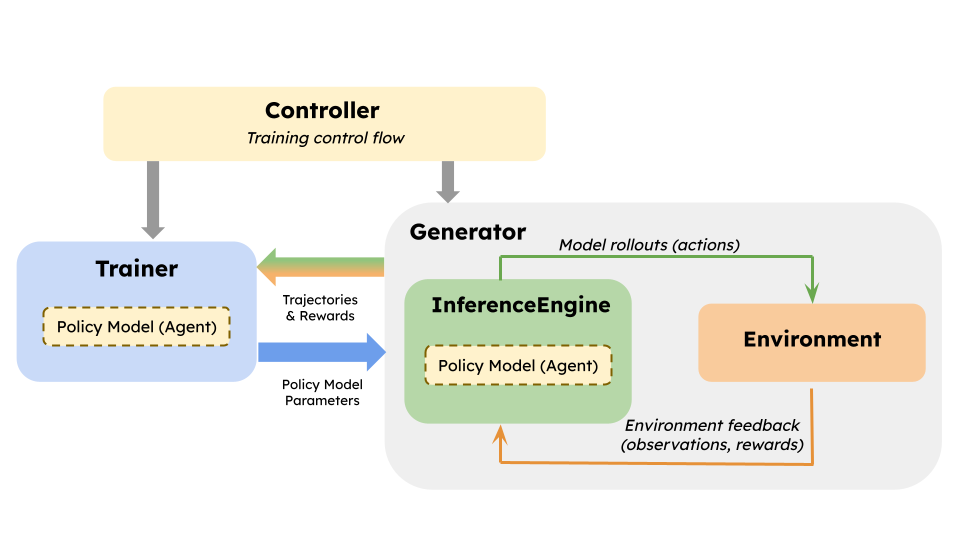
图 1:RL 系统概览。
传统上,权重加载由每个 RL 框架单独处理,通常通过扩展 vLLM worker 并添加自定义逻辑来接收和加载权重。虽然这可行,但会导致一些问题:
- 增加复杂性:框架作者必须实现和维护自定义 worker 扩展,而更好的做法是原生支持常见的传输策略。
- 重复劳动:大多数 RL 框架最终都有非常相似的实现(例如,打包张量传输、RPC 端点)。
- 版本锁定:框架通常有临时方式处理接收权重的预处理/后处理,以使 vLLM worker 能够加载它们,这可能导致版本锁定的实现。
vLLM 中的新 API
我们在 vLLM 中引入原生权重同步 API 以标准化这一过程。权重传输 API 包含四个阶段,并采用可插拔后端:
- 初始化(
init_weight_transfer_engine):在训练器和推理 worker 之间建立通信通道。在训练循环开始前调用一次。 - 开始权重更新(
start_weight_update):开始权重更新。在每个训练步骤(或步骤批次)后调用。准备 vLLM worker 以接收权重。 - 更新权重(
update_weights):从训练器更新全部或部分权重到推理引擎。可多次调用以支持分块权重传输。 - 完成权重更新(
finish_weight_update):完成当前权重更新。执行必要的后处理(例如,量化)。
相应的 API 在 API 服务器和引擎级别实现。
目前,我们支持以下后端:
- NCCL:使用 NCCL broadcast 操作在独立 GPU 上的训练和推理 worker 之间进行权重传输。
- IPC:使用 CUDA IPC 通过共享内存句柄在同一设备上进行权重传输。
两个后端都支持优化的打包实现,以最小化序列化开销。
核心传输逻辑通过可插拔的 WeightTransferEngine 抽象实现,将权重传输与 worker 实现分离,允许用户轻松引入自己的实现。核心思想是:初始化和更新权重阶段通常由 RL 框架开发者定制,并包含_传输_逻辑,而开始和完成是控制消息,涉及 vLLM 中与传输无关的预处理/后处理。
注意: HTTP 权重传输端点需要设置
VLLM_SERVER_DEV_MODE=1。
示例
例如,以下展示了在 vLLM 上通过 NCCL 进行权重传输并配合 FP8 量化的不同操作:

图 2:在 vLLM 上通过 NCCL 进行权重传输并配合 FP8 量化。
新 API 的使用方式如下:
1. 为权重传输配置引擎
from vllm import LLM
from vllm.config import WeightTransferConfig
llm = LLM(
model="my-model",
weight_transfer_config=WeightTransferConfig(backend="nccl"),
)
2. 初始化通信状态:初始化训练器和推理引擎之间的通信状态。训练器的 rank 0 进程和所有推理 worker 加入一个共享的 NCCL 进程组。
from vllm.distributed.weight_transfer.base import WeightTransferInitRequest
# 推理端初始化
llm.init_weight_transfer_engine(
WeightTransferInitRequest( # <--- 初始化参数
init_info=dict(
master_address=master_address,
master_port=master_port,
rank_offset=1, # <--- 偏移量,考虑训练器 rank 0
world_size=world_size, # <--- 训练器 + 所有推理 worker
)
)
)
# 训练端初始化
from vllm.distributed.weight_transfer.nccl_engine import (
NCCLWeightTransferEngine,
)
group = NCCLWeightTransferEngine.trainer_init(
dict(
master_address=master_address,
master_port=master_port,
world_size=world_size,
)
)
3. 从训练器发送权重:在训练器上开始权重传输。WeightTransferEngine 实现了 trainer_send_weights 方法,该方法接受一个可迭代的参数列表,并初始化全部或部分参数的传输。用户也可以实现自己的发送功能。这里,我们还可以利用打包张量广播,通过将多个小张量批处理到更大的缓冲区中,实现更高吞吐量的传输。
from vllm.distributed.weight_transfer.nccl_engine import (
NCCLTrainerSendWeightsArgs,
NCCLWeightTransferEngine,
)
trainer_args = NCCLTrainerSendWeightsArgs(
group=group,
packed=True, # 使用打包广播以提高效率
)
# 从 `AutoModelForCausalLM` 实例发送权重
NCCLWeightTransferEngine.trainer_send_weights(
iterator=model.named_parameters(),
trainer_args=trainer_args,
)
4. 在推理引擎中接收权重
from vllm.distributed.weight_transfer.base import WeightTransferUpdateRequest
# 在训练器发送权重时异步执行
llm.start_weight_update()
llm.update_weights(
WeightTransferUpdateRequest(
update_info=dict(
names=names,
dtype_names=dtype_names,
shapes=shapes,
packed=True,
)
)
)
llm.finish_weight_update()
自定义权重传输
权重传输 API 的主要目标之一是使 RL 框架能够使用 vLLM 实现自定义的权重传输策略。使用新 API,用户可以实现并注册自定义的 WeightTransferEngine:
from dataclasses import dataclass
from typing import Iterator, Callable, Any
from torch import Tensor
from vllm.distributed.weight_transfer.base import (
WeightTransferEngine,
WeightTransferInitInfo,
WeightTransferUpdateInfo,
)
# 为初始化和更新权重元数据定义自定义 dataclass
@dataclass
class MyInitInfo(WeightTransferInitInfo):
"""自定义初始化信息。"""
...
@dataclass
class MyUpdateInfo(WeightTransferUpdateInfo):
"""自定义更新信息。"""
...
# 自定义权重传输引擎
class MyWeightTransferEngine(WeightTransferEngine):
init_info_cls = MyInitInfo
update_info_cls = MyUpdateInfo
def init_transfer_engine(self, init_info: MyInitInfo):
...
def receive_weights(
self,
update_info: MyUpdateInfo,
load_weights: Callable[[list[tuple[str, Tensor]]], None],
):
...
@classmethod
def trainer_send_weights(
cls,
iterator: Iterator[tuple[str, Tensor]],
trainer_args: dict[str, Any] | Any,
):
...
# 最后,注册权重传输引擎
from vllm.distributed.weight_transfer import WeightTransferEngineFactory
WeightTransferEngineFactory.register_engine("my_weight_transfer", MyWeightTransferEngine)
注意,trainer_send_weights 方法是可选的。它编码了训练器上使用的发送逻辑,用户不必以这种方式组织其发送逻辑。
上述简单的 API 可以支持许多高级用例。作为原型,我们在此处演示了如何实现类似 Etha 风格的分片权重传输。
改进的异步 RL 暂停/恢复支持
在异步 RL 中,权重在推理请求仍在进行时更新。通常,异步 RL 中的权重同步涉及三个操作:暂停生成、传输更新后的权重,然后恢复生成。用户可以选择如何处理正在进行的请求(例如,中止所有正在运行的请求,或从先前生成的 token 恢复生成),以及保留或丢弃 KV cache。

图 3:异步 RL 系统图,灵感来自 AReaL。训练和生成重叠,训练每步使用 4 个样本。训练步骤完成后,所有引擎暂停,权重更新,KV cache 被丢弃,然后引擎恢复。恢复时重新计算 KV cache,生成照常进行。
暂停/恢复的 Keep 模式
为了在推理引擎运行时安全地更新权重,vLLM 提供了 pause_generation 和 resume_generation 方法。相同的功能在 HTTP 服务器中作为 POST /pause 和 POST /resume API 提供。之前,AsyncLLMEngine.pause_generation 支持两种模式:
- 中止所有请求
- 等待请求完成
我们新增了第三种选项:keep 模式。不同模式的对比如下表所示:
| 模式 | 说明 | 客户端影响 | 是否支持异步 RL? |
|---|---|---|---|
abort |
中止所有正在进行的请求 | 客户端必须处理重试 | 是 |
wait |
等待所有正在进行的请求完成 | 客户端无需重试 | 否,生成必须在权重更新前完成 |
keep |
暂停正在进行的请求 | 客户端无需重试 | 是 |
Keep 模式的使用方式如下:
# 暂停 - 保留正在进行的请求
await engine.pause_generation(mode="keep")
# 在此处更新权重
# 恢复
await engine.resume_generation()
在 keep 模式下:
- 正在进行的请求被暂停但不会被丢弃。
- 调度器停止,但状态被保留。
修复 DPEP 设置中的死锁
大规模异步 RL 需要在 DPEP 部署中对正在进行的权重更新进行仔细协调。在 vLLM 中,DPCoordinator 确保生成在 vLLM rank 之间得到仔细协调,以防止死锁。更具体地说,当任何 DP rank 中有活跃请求被调度时,每个 DP rank 都会执行一次前向传播。

图 4:跨 vLLM rank 的 DP 协调生成。
以前,使用 vLLM 的 DP 部署中的异步 RL 经常导致死锁,主要原因是某些引擎可能已收到暂停信号,而其他引擎仍在积极处理请求并等待所有引擎加入。发生这种情况的原因之一是暂停状态在 AsyncLLM 对象中跟踪,而 DP 协调消息在 EngineCore 进程和 DPCoordinator 之间交换。举例来说,对于 DP world size 为 2 的情况,可能出现如下死锁场景:
- API Server DP Rank 0 收到一个生成请求并将其转发给
EngineCore。API Server 向DPCoordinator发送FIRST_REQ消息以启动新一波。请求被转发给 DP Rank 0EngineCore,后者开始新的调度步骤。 - Controller 向两个引擎发出
/pause请求。暂停状态在AsyncLLM对象中设置,新请求不再转发给EngineCore。所有 DP rank 上的 API server 立即返回。 - Trainer 发出权重更新请求。同时,DP Rank 0
EngineCore已进入前向传播,并等待其他 DP rank 加入。(为简化,我们在此忽略start_weight_update和finish_weight_update请求)。 - 权重更新请求到达 DP Rank 1
EngineCore,副本进入 NCCL broadcast 集合等待其他 rank。权重更新请求在 DP Rank 0EngineCore上排队。 DPCoordinator向 DP Rank 1EngineCore发送START_DP_WAVE消息,但消息被排队。- 不同 rank 处于不同的集合中,导致死锁。
相同场景如下图所示:

图 5:vLLM 中 DPEP 部署可能出现的死锁场景。
我们通过两项更改来解决此问题:
1. 将暂停逻辑移至 EngineCore。 不再在 AsyncLLM 入口层跟踪暂停状态,而是直接在调度器中处理。这减少了暂停和生成请求之间的竞态条件。
2. 两阶段暂停/恢复。
- 阶段 1(本地暂停):每个引擎暂停调度,但通过尊重任何传入的
START_DP_WAVE请求继续执行步骤,因此它仍然可以参与所需的前向传播。 - 阶段 2(全局暂停):目前,所有 rank 每 32 步执行一次全局 all-reduce,以检查任何 DP rank 中是否有待处理请求。在同一 all-reduce 阶段,我们还检查所有引擎是否处于“本地暂停”状态。如果所有 rank 同意,它们一起停止。
这确保了:
- 没有 rank 陷入等待。
- 即使引擎收到暂停请求,
START_DP_WAVE也会被尊重。 - 所有 worker 一致地转换状态。
因此,之前的相同场景现在可以优雅地处理:
- API Server DP Rank 0 收到一个生成请求并将其转发给
EngineCore。API server 向DPCoordinator发送FIRST_REQ消息以启动新一波。请求被转发给 DP Rank 0EngineCore,后者开始新的调度步骤。 - Controller 向两个引擎发出
/pause请求。暂停请求被转发给两个 rank 的EngineCore。暂停请求在 DP Rank 0EngineCore中排队,直到步骤完成。注意,API server 此时尚未返回。 - DP Rank 0
EngineCore开始执行前向传播,worker 在 all-to-all 集合上等待。 - DP Rank 1
EngineCore收到暂停请求,进入“本地暂停”状态。 DPCoordinator向 DP Rank 1EngineCore发送START_DP_WAVE消息。- DP Rank 1
EngineCore开始执行前向传播。由于两个 DP rank 都加入,前向传播完成。 - DP Rank 0
EngineCore处理暂停请求,进入“本地暂停”状态。 - DP Rank 0 和 DP Rank 1
EngineCore参与周期性 all-reduce,意识到两个引擎都处于“本地暂停”状态,并进入“全局暂停”状态。 - API server 在
/pause调用上返回。 - Trainer 发出权重更新请求。API server 将权重更新请求转发给
EngineCore进程。(为简化,我们在此忽略start_weight_update和finish_weight_update请求)。 - 所有 vLLM worker 进入 NCCL broadcast 集合。Trainer 开始 NCCL broadcast。
- 权重更新成功完成。

图 6:使用两阶段协议在 DPEP 部署中实现无死锁的暂停/恢复。
验证
演示新的 RL API
我们在 SkyRL 中演示了新 RL API 的使用。
在 SkyRL 中,训练器通过 HTTP 与推理引擎交互。对于权重同步,SkyRL 使用原生权重同步 API,以及用于异步 RL 的原生 /pause 和 /resume API。与原生 RL API 的集成在文档中有详细说明,我们演示了在原始 DAPO 配方上对 Qwen3-1.7B 进行异步训练(示例)。

图 7:在 SkyRL 中使用原生 RL API 在 DAPO 配方上对 Qwen3-1.7B 进行异步训练。
大规模验证:在 Wide-EP 设置中实现完全异步 RL
Prime-RL 团队已针对 zai-org/GLM-5.1-FP8 的部署验证了 RL API,推理在 P/D 分离设置中运行,跨越 16 个 8xH200 节点——2 个副本,每个副本为 4P+4D,prefill 和 decode 均使用 DPEP32。所有实例还配置了 CPU KV cache offloading,每个节点容量为 1TB。使用 vllm-router 实现跨引擎的路由,该路由器提供缓存感知的粘性路由。训练器在另外 16 个 8xH200 节点上运行 BF16 模型等效版本(zai-org/GLM-5.1),在自定义数学环境中使用 IcePop 作为算法。该部署在训练过程中已证明稳定超过 100 步,评估性能持续增长,RL 曲线上升,KL 散度稳定,权重更新正常进行。

图 8:Prime-RL 对 zai-org/GLM-5.1-FP8 在 16 个 8xH200 节点上进行的完全异步 RL 验证。
结论
我们看到 vLLM RL 社区对基于新 RL API 进行构建的兴趣日益增长。vLLM RL 社区正在进行的一些工作包括集成新的 K8s 原生权重传输引擎,以及以通用方式支持分片感知、RDMA 原生权重传输。新开发在 vLLM RL 路线图中跟踪。
在文档中阅读更多关于 vLLM 中 RL 工具的信息:
在此处尝试 vLLM 上的新 API:https://github.com/vllm-project/vllm/tree/main/examples/rl。
致谢
感谢以下团体和个人使这一切成为可能:
- Prime-RL 团队(特别是 Matej Sirovatka)和 Junjie Zhang 帮助通过大规模运行验证和调试 RL API。
- NemoRL 团队提供了优化的打包张量实现。
- Robert Shaw 组织 RL 相关工作。
- Kyle Sayers 通过逐层重载使量化权重重载成为可能。