Speculators v0.5.0:支持DFlash与在线训练
Speculators v0.5.0: DFlash Support and Online Training
v0.5.0 版本为推测解码模型训练引入 DFlash 算法支持,通过块扩散(block diffusion)在单次前向传播中生成所有草稿 token,并采用非因果 attention 模式。该版本全面迁移至 vLLM 原生隐藏状态提取系统,统一在线与离线训练能力。基于 Gemma 4 31B 训练的 DFlash 推测器在推理和代码生成任务上取得较高接受率,token 间延迟优于 Eagle 3 和 FP8 量化验证器。更新了文档和教程,涵盖关键工作流与算法添加指南。
v0.5.0 版本为推测解码模型训练带来了重大的架构改进,引入了 DFlash 算法支持、完全统一的在线训练能力,并全面迁移至 vLLM 的原生隐藏状态提取系统。此版本在训练灵活性和生产就绪性方面均迈出了重要一步,适用于推测解码工作流。
主要特性包括:
- DFlash 算法支持——通过块扩散(block diffusion)实现单次前向传播的草稿 token 生成
- Gemma 4 DFlash 结果
- 基于 vLLM 原生隐藏状态提取的统一在线与离线训练
- 更新了文档和示例,概述关键工作流
DFlash 算法支持
v0.5.0 引入了对 DFlash 推测解码算法的训练支持。与自回归的 Eagle 3 模型相比,这是一种根本不同的草稿 token 生成方法。Eagle 3 通过多次前向传播自回归地生成草稿 token,而 DFlash 则采用块扩散(block diffusion)在单次前向传播中生成所有草稿 token。
DFlash 的单次前向传播特性可以显著降低推测解码的开销,尤其是在处理较长的草稿序列时。草稿模型为每个前缀生成一个长度为 B 的 token 块。这种块结构完全通过 attention mask 实现。与 Eagle 3 的另一个关键区别在于,DFlash 使用非因果 attention 模式,其中块内的 query 可以关注同一块内的所有其他 token。
在训练过程中,多个预测块会并行训练。一种直接的方法是在序列中每个可能的位置之后都启动一个预测块。然而,对于长序列,这会导致 attention mask 变得极其庞大,使得训练在内存使用和计算成本上都变得不切实际。为避免这种情况,我们不会在所有位置启动块。相反,我们从实际对训练损失有贡献的位置中随机选择一组较小的“锚点”(anchor)位置。预测块仅附加到这些锚点上。这样,无论序列长度如何,预测块的数量都保持固定,从而使训练能够扩展到更长的上下文,同时保持 attention mask 的可管理性。
训练 DFlash 推测器
训练 DFlash 模型遵循与 Eagle 3 类似的在线工作流。完整的教程可在此处找到。
与 Eagle 3 的关键区别在于训练命令中特定于推测器的参数,如下所示:
torchrun --standalone --nproc_per_node 2 scripts/train.py \
--verifier-name-or-path "Qwen/Qwen3-8B" \
--vllm-endpoint "http://localhost:8000/v1" \
--speculator-type dflash \
--draft-vocab-size 8192 \
--block-size 8 \
--max-anchors 3072 \
--num-layers 5 \
--target-layer-ids "2 18 33" \
--epochs 5 --lr 1e-4
DFlash 特定参数包括:
--block-size # 每个扩散块生成的 token 数量
--max-anchors # 训练期间推测的最大锚点数量
--speculator-type # 必须指定为 dflash
Gemma 4 DFlash 推测器
利用 DFlash 算法支持,我们训练了一个 Gemma 4 31B DFlash 推测器,并在多种任务类型上评估了其接受率。结果显示,在推理和代码生成任务上表现尤为强劲:
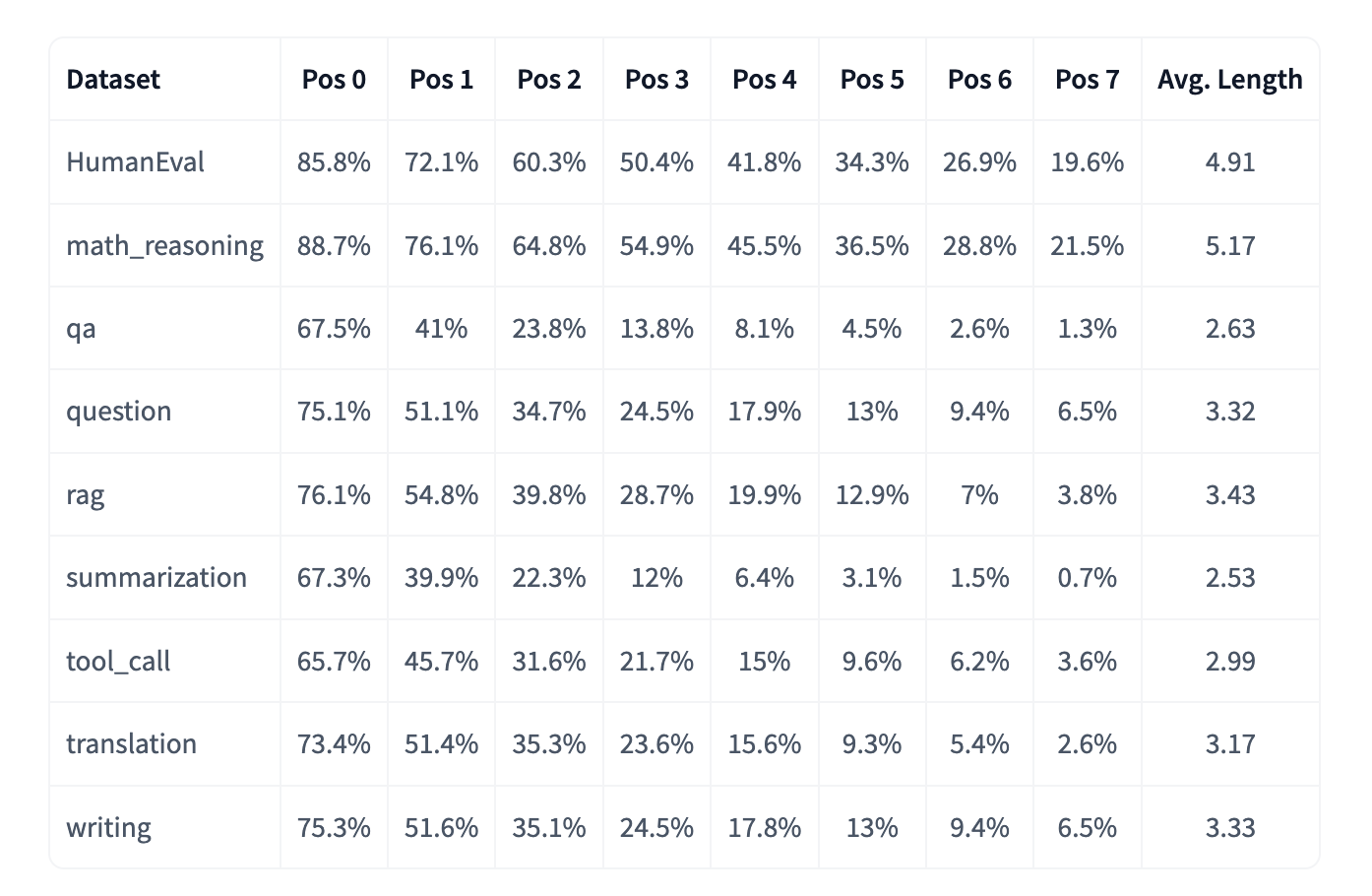
图 1:Gemma 4 DFlash 在不同任务类型上的接受率。
Gemma 4 DFlash 在 token 间延迟方面优于 Eagle 3 和独立的 FP8 量化验证器。将 DFlash 与 FP8 量化验证器结合使用可获得更大的性能提升,如下所示:
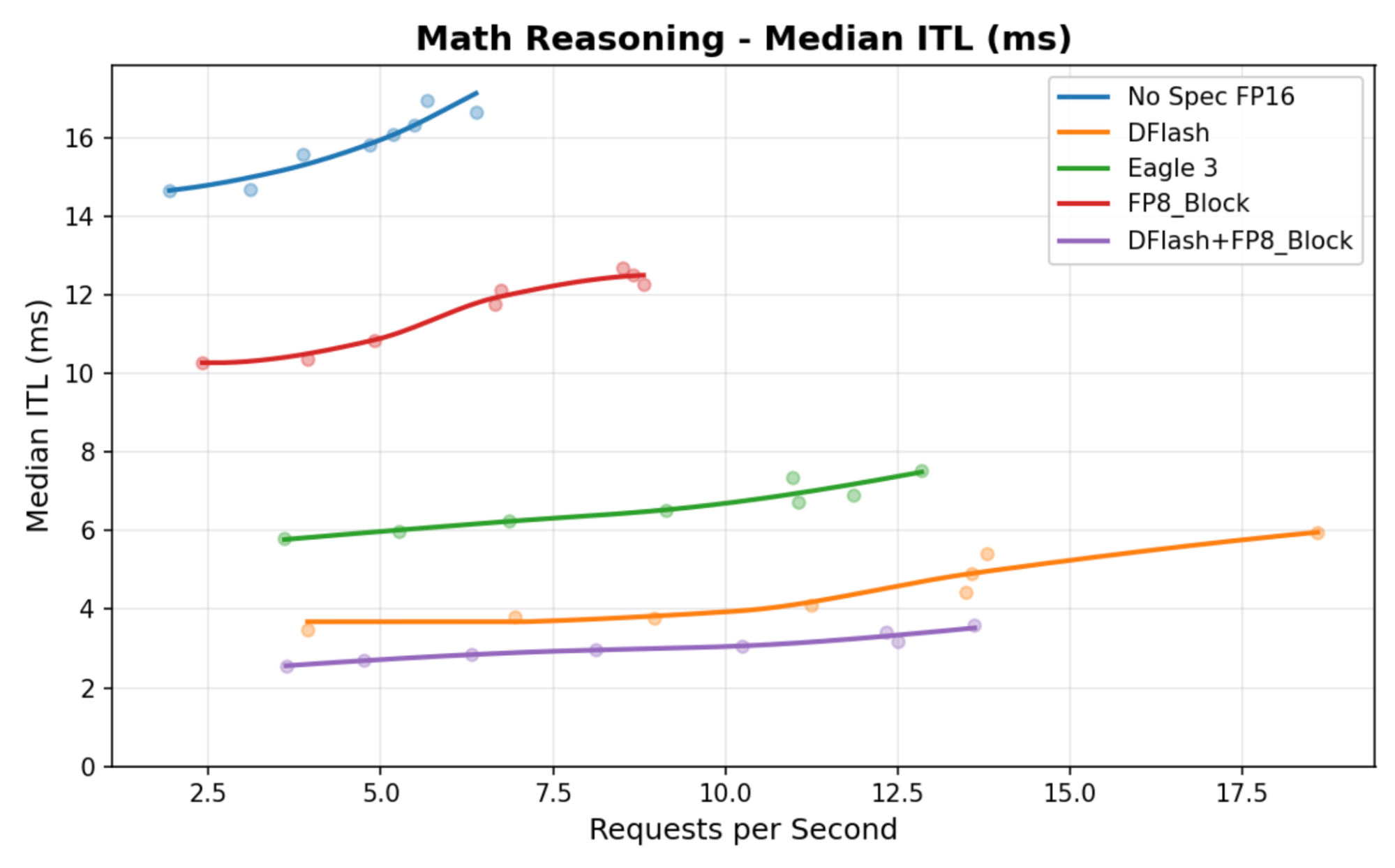
图 2:Gemma 4 DFlash token 间延迟对比。
在 vLLM 中服务 DFlash 模型
自 PR #38300 起,DFlash 模型可与 vLLM 的推测解码基础设施无缝集成,该 PR 包含在 vllm>=0.20.0 中。
与 Eagle 3 模型类似,DFlash 模型的 config.json 中包含一个 speculators_config,其中包含目标模型、推测 token、推测算法名称等详细信息。使用此配置,可以通过基本的 vllm serve 命令来服务模型,如下所示。
vllm serve -tp 2 RedHatAI/gemma-4-31B-it-speculator.dflash
统一的在线与离线训练支持
v0.5.0 通过 vLLM 的隐藏状态提取系统(在 vLLM v0.18.0 中引入)增加了对在线和离线两种训练模式的原生支持。Speculators 的先前版本使用 vLLM 的低级工具提取隐藏状态,这要求 vLLM 作为直接的 Python 依赖项。这种方法将训练流程与 vLLM 的内部 API 紧密耦合,而后者在 vLLM 版本更新时经常变化,需要手动同步上游变更。此次集成移除了先前自定义的数据生成流程,并消除了 vLLM 作为直接 Python 依赖项的需求。
现在,两种训练模式都使用相同的基于 vLLM 的提取路径:
- 在线训练:在训练过程中即时提取隐藏状态
- 离线训练:预先生成隐藏状态并缓存到磁盘,然后进行训练
通过利用 vLLM 的原生隐藏状态提取,Speculators 继承了 vLLM 的所有推理优化,包括高效的内存管理、批处理策略和硬件加速支持。现在,训练通过 vLLM 的标准 REST API 与正在运行的 vLLM 服务器通信,将训练基础设施与 vLLM 的内部实现细节解耦。这种架构转变提供了更好的版本稳定性,并使团队能够独立于 Speculators 训练框架更新 vLLM。
在线训练过程中发生的情况:
- vLLM 服务器使用基础模型(以及一些特殊配置)初始化
- 训练 prompt 被发送到 vLLM 进行推理
- 隐藏状态被提取并临时写入磁盘(或内存盘)
- 训练过程加载提取的隐藏状态并删除文件
- 推测器模型在提取的状态上进行训练
此教程提供了有关在线训练工作流的更多信息。
离线数据生成也已更新,使用与在线模式相同的隐藏状态提取系统和数据格式。已开发新的脚本,用于向正在运行的 vLLM 服务器饱和发送请求并将其写入磁盘。这两种方法耦合得非常紧密,甚至可以组合使用。例如,您可以部分离线生成隐藏状态,然后运行训练并加载现有的隐藏状态,同时生成任何缺失的部分。您也可以运行一个在线训练任务,在生成文件后不清除它们,从而允许在第一个 epoch 生成一次,然后在后续 epoch 加载这些文件。
此教程更详细地介绍了离线训练工作流。
新增全面文档
另一个值得强调的特性是更新后的文档站点。我们为 Speculators 支持的推测解码算法添加了简洁的介绍,以及训练推测器模型的详细教程指南。对于开发者,我们还引入了一份指南,涵盖如何向 Speculators 库添加新的推测解码算法,以及一份全面的 API 参考。