使用 AutoRound 量化加速 vLLM-Omni 推理
Accelerating vLLM-Omni Inference with AutoRound Quantization
Intel 的 AutoRound 训练后量化(PTQ)算法已集成到 vLLM-Omni 中,支持 W4A16(4-bit 权重 / 16-bit 激活)量化在多模态 Omni、扩散视频和多阶段图像生成管线上的部署。Qwen3-Omni-30B-A3B 的 checkpoint 大小从 66 GB 降至 25 GB(减少 62%),其 W4A16 变体在 OmniBench 上得分略优于 BF16 参考版本,文本到图像质量漂移约 1.3%。在 Intel XPU B60 上,通过 CFG 并行执行实现 1.55–1.67 倍引导生成加速。该集成在 Intel XPU 和 NVIDIA GPU 上均验证了原生执行路径。
TL;DR
我们很高兴地宣布,AutoRound——Intel 最先进的训练后量化(PTQ)算法——现已完全集成到 vLLM-Omni 中,实现了"一次量化,直接部署"的简化工作流。此次合作将 W4A16(4-bit 权重 / 16-bit 激活)量化引入多模态 Omni、扩散视频和多阶段图像生成管线。
来自我们生产级 benchmark 套件的关键实证亮点包括:
- 大幅节省 VRAM: 大型 Omni 模型的总 checkpoint 大小最多减少 62%,将 Qwen3-Omni-30B-A3B 从 66 GB 降至 25 GB。
- 精度保持: Qwen3-Omni-30B 的 W4A16 量化变体在 OmniBench 上取得了令人印象深刻的分数,略优于其 BF16 参考版本。同时,它将文本到图像的质量漂移限制在仅约 1.3%,表明 4-bit 量化可以在评估的工作负载下保持多模态质量。
- 生产部署优势: 在 Intel XPU (B60) 上解锁了高级架构优化,通过 CFG 并行执行,相比顺序 BF16 基线部署实现了 1.55–1.67 倍的引导生成加速。
- 跨后端集成: 在 Intel XPU 和 NVIDIA GPU 架构上验证了原生执行路径。
1. 引言:vLLM-Omni 与 AutoRound 的结合
vLLM-Omni 专为扩散模型、多模态 Omni 模型及相关多阶段生成栈的高性能部署而设计。这种广度使得量化变得异常有价值:目标不仅是缩小单个 Transformer,而是让多样化的运行时组合更容易在实际硬件上部署。
由 Intel 开发并在 EMNLP 2024 论文中描述的 AutoRound(通过符号梯度下降进行权重舍入),是一种基于调优的训练后量化算法。其核心思想是联合优化舍入和裁剪,为每个量化张量使用三个可学习参数:用于舍入偏移的 V,以及用于控制裁剪范围的 alpha 和 beta。在实践中,这使得 AutoRound 在低比特精度上优于简单的就近舍入基线,同时仍能生成静态 checkpoint,且推理时无额外量化开销。
这种三层协作——AutoRound 中的算法工作、vLLM-Omni 中的运行时集成,以及 HuggingFace 上不断增长的 INT4 checkpoint 目录——讲述了一个连贯的故事:AutoRound 不仅仅是一种量化技术,更是一条从研究到生产就绪的低比特 Omni 推理的端到端路径。
运行时路径有意保持简单。vLLM-Omni 读取 checkpoint 元数据,检测 quantization_config.quant_method = "auto-round",将 checkpoint 块重新映射到运行时模块,并选择匹配的计算后端。这种 checkpoint 驱动的工作流对生产环境尤其重要,因为它使部署 API 与正常模型加载保持一致。
2. 模型覆盖范围
经过验证的 AutoRound + vLLM-Omni 生态系统涵盖三种主要的多模态范式。
2.1 Omni 多模态模型
这些模型管理统一的文本、视觉和音频处理循环,由于跨模态嵌入对齐而带来独特的量化挑战。
- Qwen3-Omni-30B-A3B-Instruct (Intel/Qwen3-Omni-30B-A3B-Instruct-int4-AutoRound):大规模旗舰多模态模型。已在 vLLM-Omni 中集成并验证。
- Qwen2.5-Omni-7B (Intel/Qwen2.5-Omni-7B-int4-AutoRound):轻量级、低延迟的跨模态引擎。已在 vLLM-Omni 中集成并验证。
2.2 扩散与多阶段图像生成
- GLM-Image (Intel/GLM-Image-int4-AutoRound):多阶段文本到图像管线。已在 vLLM-Omni 中集成并验证。
- FLUX.1-dev (vllm-project-org/FLUX.1-dev-AutoRound-w4a16):高保真扩散 Transformer (DiT)。已在 vLLM-Omni 中集成并验证。
- BAGEL-7B-MoT (Intel/BAGEL-7B-MoT-int4-AutoRound):Checkpoint 可用;运行时集成正在进行中。
- Ovis-Image-7B (Intel/Ovis-Image-7B-int4-AutoRound):Checkpoint 可用;运行时集成正在进行中。
2.3 视频扩散
Wan2.2 系列代表了最先进的时空视频生成模型,其 AutoRound INT4 checkpoint 已在 vLLM-Omni 中验证:
- I2V-A14B (Intel/Wan2.2-I2V-A14B-Diffusers-int4-AutoRound)
- T2V-A14B (Intel/Wan2.2-T2V-A14B-Diffusers-int4-AutoRound)
- TI2V-5B (Intel/Wan2.2-TI2V-5B-Diffusers-int4-AutoRound)
3. 使用方法
通过将所有量化和调优操作限制在离线管线中,该集成使生产代码保持精简,并专注于高性能推理。
3.1 使用量化模型进行推理
对于 FLUX.1-dev,Python API 看起来与正常的 vLLM-Omni 加载完全相同。唯一的区别是 checkpoint 路径。
from vllm_omni import Omni
from vllm_omni.inputs.data import OmniDiffusionSamplingParams
if __name__ == '__main__':
omni = Omni(model="vllm-project-org/FLUX.1-dev-AutoRound-w4a16")
outputs = omni.generate(
"A cat sitting on a windowsill",
OmniDiffusionSamplingParams(num_inference_steps=28, guidance_scale=3.5),
)
outputs[0].images[0].save("output.png")
对于 Wan2.2 视频模型,部署仍然是标准的 vLLM-Omni 命令。服务器运行后,请求通过 BF16 变体使用的相同视频端点发送。
vllm serve Intel/Wan2.2-T2V-A14B-Diffusers-int4-AutoRound --omni --port 8091
curl -X POST "http://127.0.0.1:8091/v1/videos/sync" \
-F 'prompt=Cherry blossoms swaying gently in the breeze, cinematic motion' \
-F 'width=832' -F 'height=480' -F 'num_frames=48' \
-F 'num_inference_steps=40' -F 'guidance_scale=5.0' \
--output t2v_output.mp4
对于 Omni 模型(如 Qwen2.5-Omni),兼容 OpenAI 的聊天接口也保持不变。
vllm serve Intel/Qwen2.5-Omni-7B-int4-AutoRound --omni --port 8091
curl -s http://localhost:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Intel/Qwen2.5-Omni-7B-int4-AutoRound",
"messages": [{"role": "user", "content": "What is 2 + 3?"}],
"max_tokens": 128
}'
重要的操作细节是,vLLM-Omni 会自动从 checkpoint 中检测量化元数据。对于预量化的 AutoRound 模型,在推理期间无需添加单独的 --quantization 标志。
3.2 量化新模型
新的 checkpoint 使用 AutoRound 工具离线生成,然后由 vLLM-Omni 直接部署。在部署期间不会进行校准或量化工作。这种分离将量化实验排除在热部署路径之外,并确保生产推理专注于执行效率。
# FLUX.1-dev
auto-round \
--model black-forest-labs/FLUX.1-dev \
--scheme W4A16 \
--batch_size 1 \
--disable_opt_rtn \
--dataset coco2014 \
--iters 0
# Wan2.2-T2V-A14B
auto-round \
--model_name Wan-AI/Wan2.2-T2V-A14B-Diffusers \
--format auto_round \
--scheme W4A16 \
--iters 100 \
--nsamples 32 \
--batch_size 1 \
--num-inference-steps 3 \
--guidance-scale 5.0 \
--dataset coco2014 \
--output_dir Wan2.2-T2V-A14B-Diffusers-int4-AutoRound
# Qwen3-Omni-30B-A3B-Instruct
auto-round \
--model Qwen/Qwen3-Omni-30B-A3B-Instruct \
--bits 4 \
--group_size 128 \
--format auto_round \
--iters 200 \
--lr 5e-3 \
--output_dir tmp_qwen3_omni_w4a16 \
--trust_remote_code
生成的 checkpoint 在 config.json 中包含量化元数据:
{
"quantization_config": {
"quant_method": "auto-round",
"bits": 4,
"group_size": 128,
"sym": true,
"packing_format": "auto_round:auto_gptq"
}
}
在实践中,AutoRound 和 vLLM 的指导建议,对于许多工作负载,128 个校准样本和大约 200 次优化迭代通常足以达到稳定收敛,尽管更大或更敏感的模型可能需要更多调优。确切的校准设置取决于模型系列、任务类型和部署约束。
3.3 质量验证
对于扩散模型,vLLM-Omni 还提供了一个比较工具,用于在 BF16 参考版本和量化候选版本之间进行相同种子的回归测试。
python -m vllm_omni.quantization.tools.compare_diffusion_trajectory_similarity \
--task t2i \
--reference-model black-forest-labs/FLUX.1-dev \
--candidate-model vllm-project-org/FLUX.1-dev-AutoRound-w4a16 \
--prompt "a cup of coffee on the table" \
--height 512 --width 512 \
--num-inference-steps 20 \
--seed 142 \
--output-json /tmp/flux_similarity/result.json
4. 定量评估:准确性与质量
量化只有在保持模型核心智能的情况下才有用。我们使用自动化评估套件对 AutoRound 集成进行了广泛的多模态回归测试。
4.1 Omni 多模态评估 (OmniBench)
我们使用 evalscope 在 100 个高度复杂的多模态任务(同时包含图像和音频模态)上运行了相同的评估。W4A16 模型在 OmniBench 上的总体得分略高于 BF16 基线。
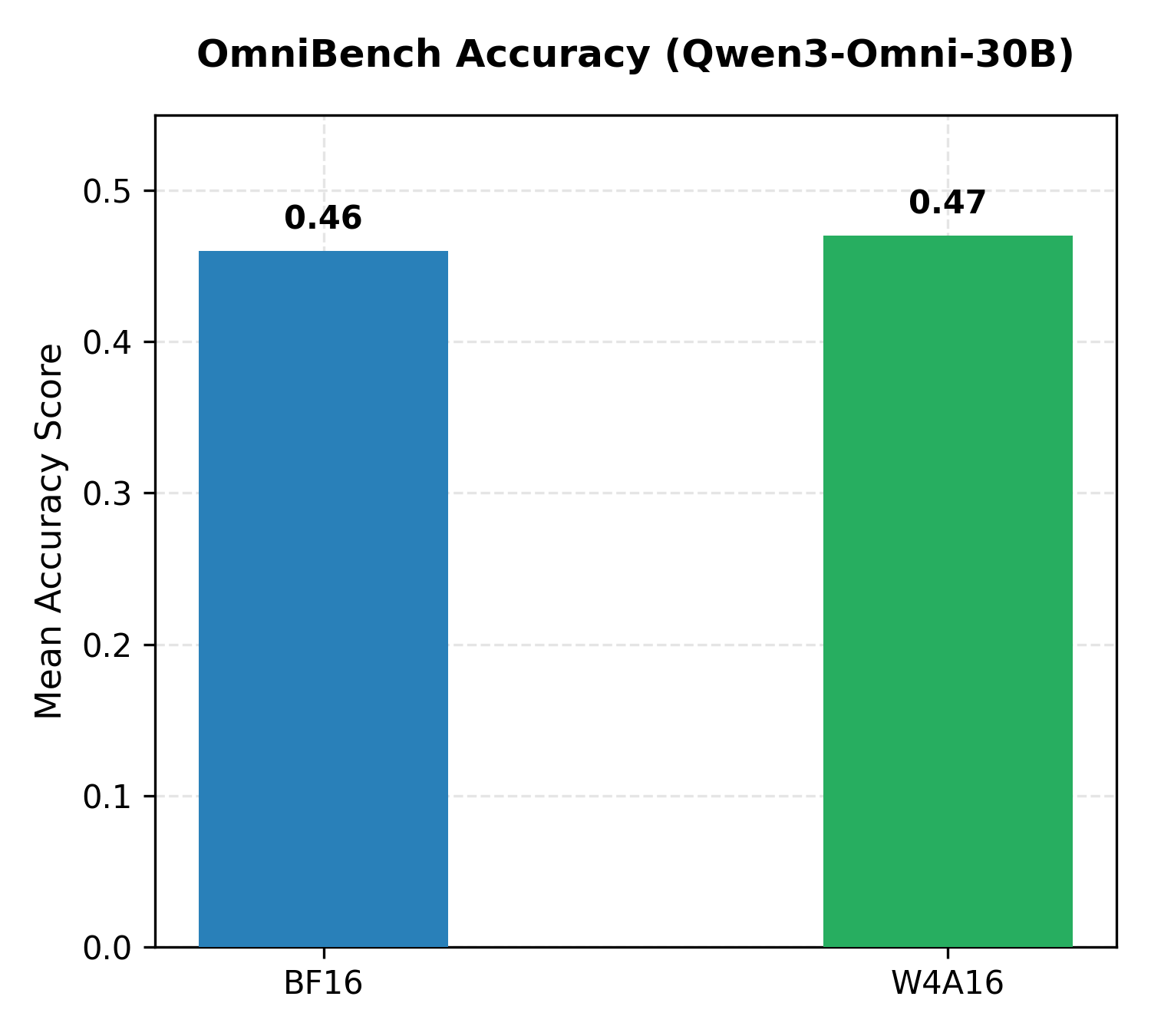
图 1:Qwen3-Omni-30B-A3B-Instruct 的 BF16 和 W4A16 AutoRound 量化变体的 OmniBench 结果对比。
4.2 多阶段扩散评估 (TIIF-Bench)
对于多阶段文本到图像系统,性能通过评估对齐、构图和保真度的 9 个结构子属性进行量化。
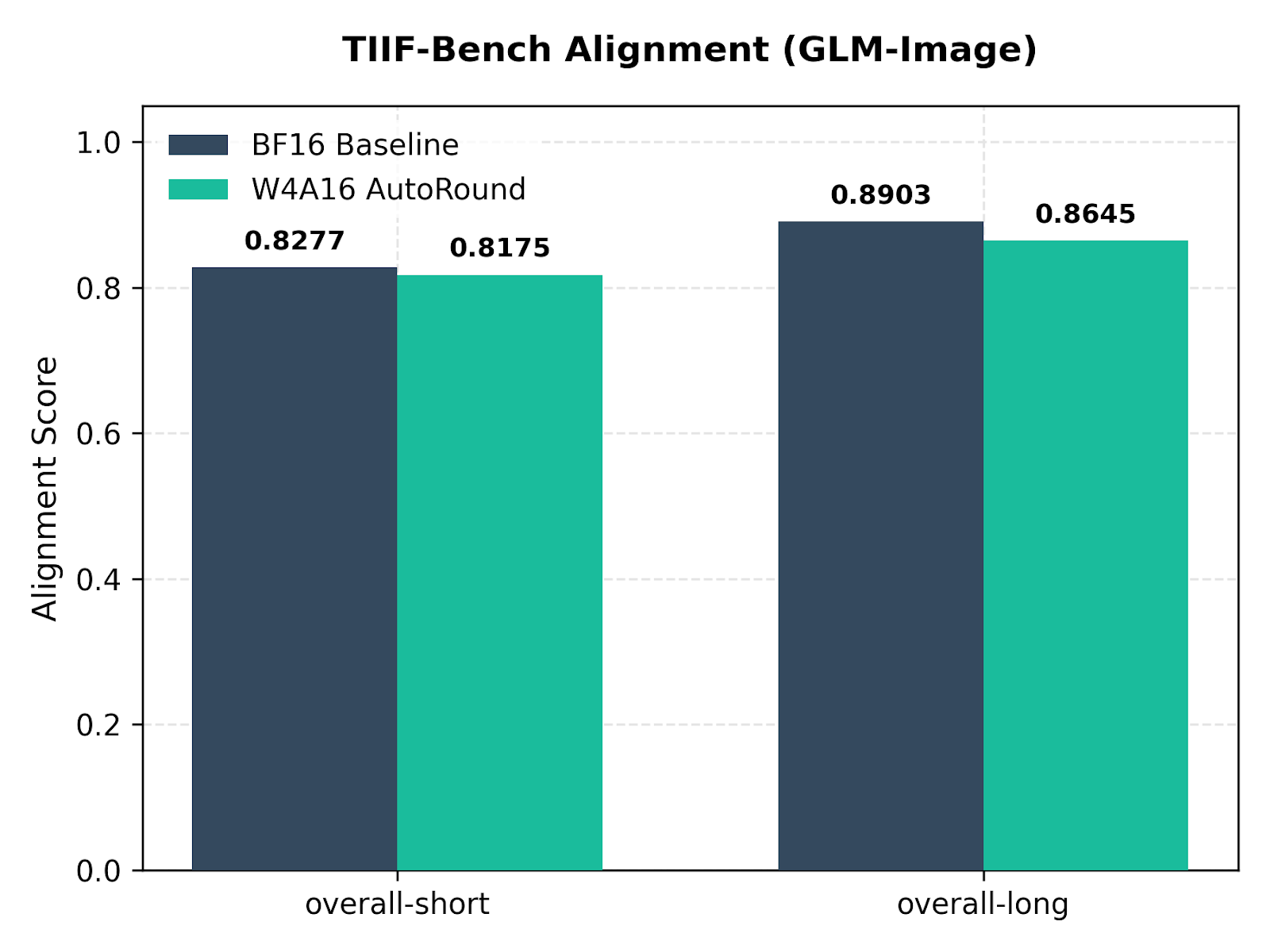
图 2:多阶段文本到图像管线的 9 个结构子属性 TIIF-Bench 评估。
所有轴上的平均精度下降约为 1.3%,在可接受的容差范围内,适合生产部署。
4.3 视频生成评估 (Wan2.2)
由于时间一致性漂移,视频管线在简单的标量量化下很脆弱。AutoRound 使用跨多个维度的客观指标进行了评估:
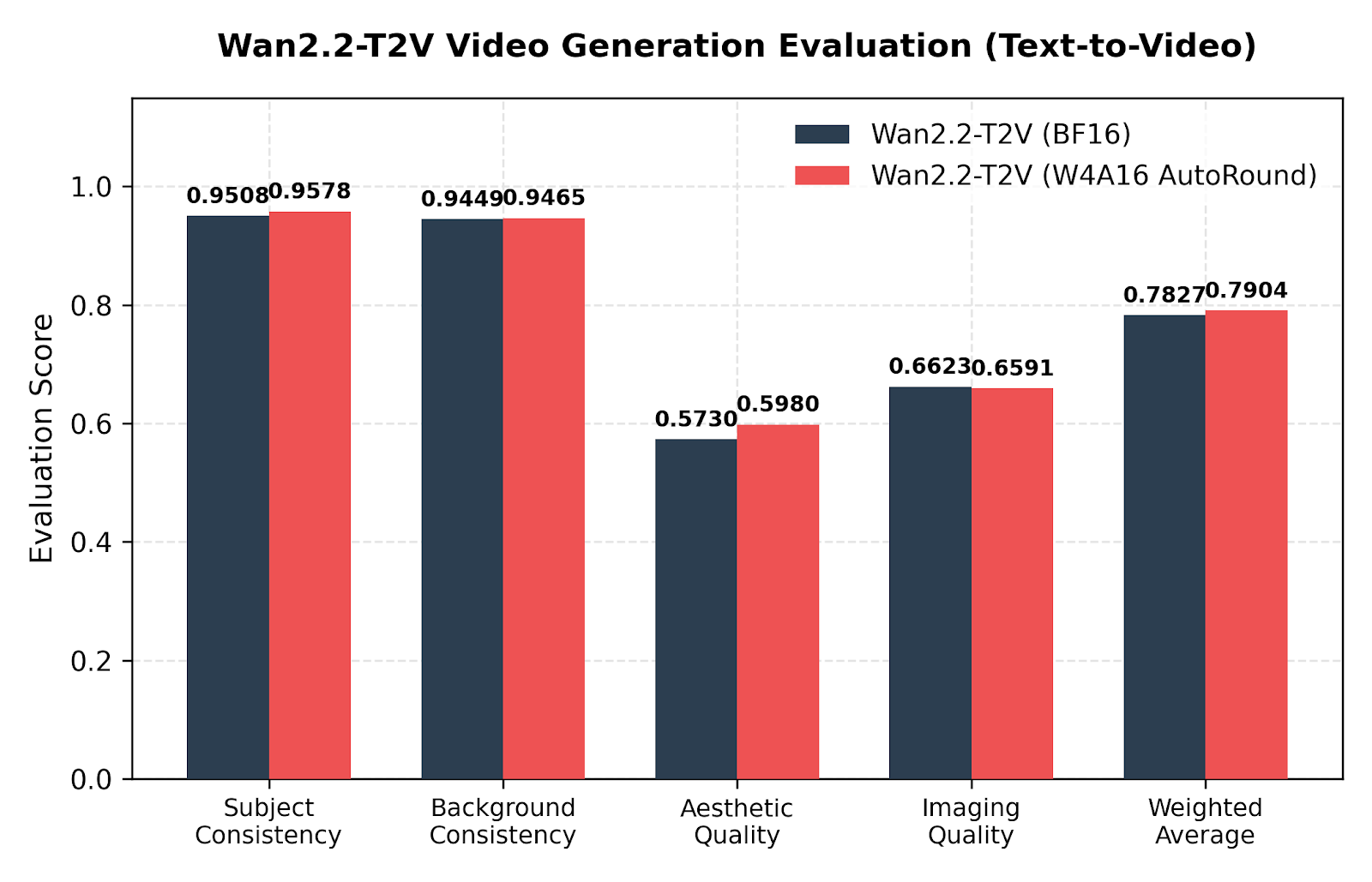
图 3:Wan2.2 T2V-A14B 在 W4A16 AutoRound 量化下的文本到视频评估。
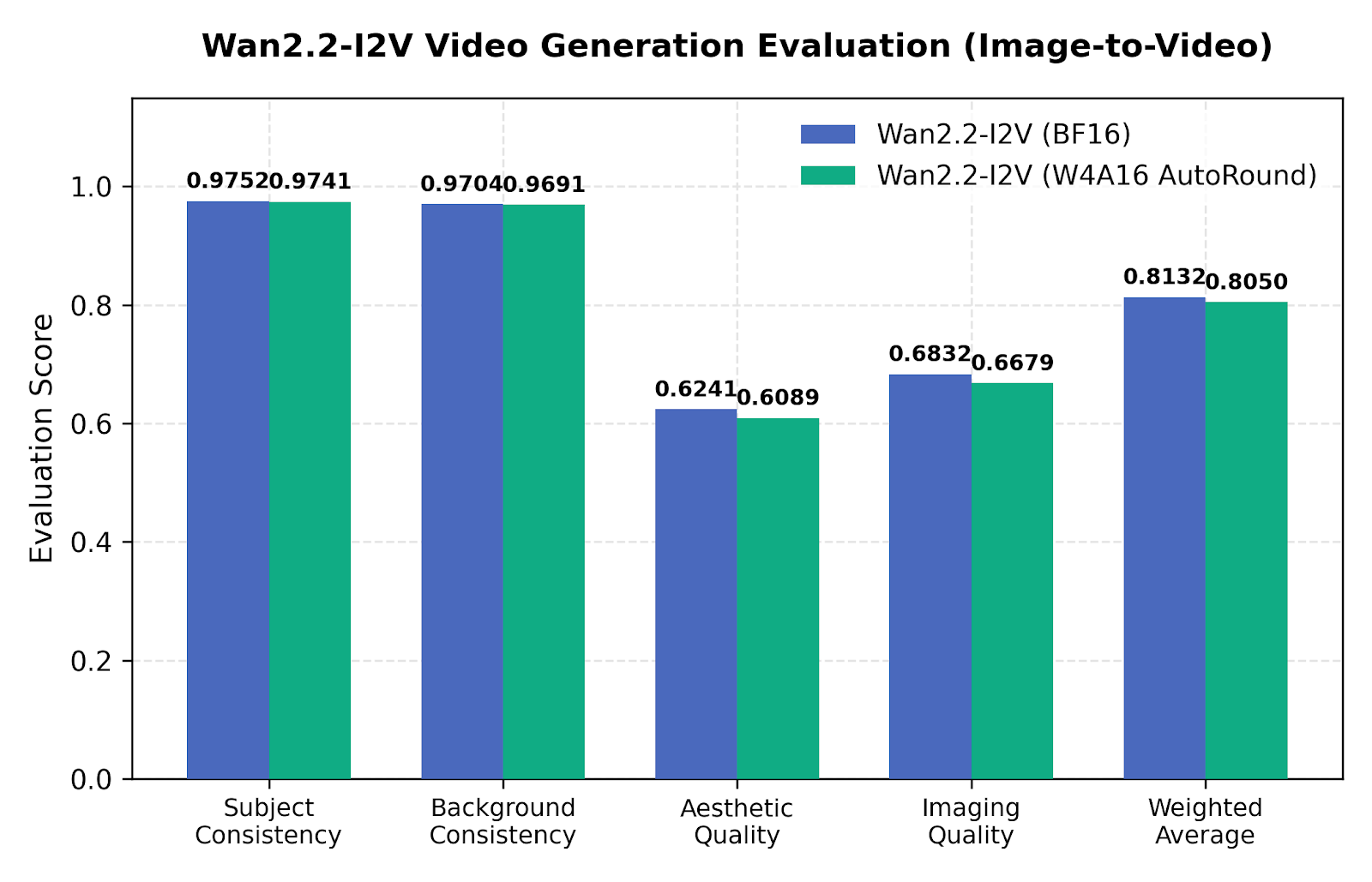
图 4:Wan2.2 I2V-A14B 在 W4A16 AutoRound 量化下的图像到视频评估。
在 W4A16 AutoRound 下,文本到视频变体 (T2V-A14B) 在结构一致性指标上实际上显示出轻微的改进。这种行为与裁剪优化可能提供正则化效果的假设一致。
5. 性能、内存占用与部署基准测试
5.1 VRAM 占用优化
W4A16 AutoRound 的首要好处是大幅减少 checkpoint 大小和执行内存占用。W4A16 将量化权重的存储从 BF16 基线缩小到原始权重占用的大约四分之一,这就是为什么首要优势是内存空间。端到端加速则取决于工作负载先前在多大程度上受限于内存容量或内存带宽。
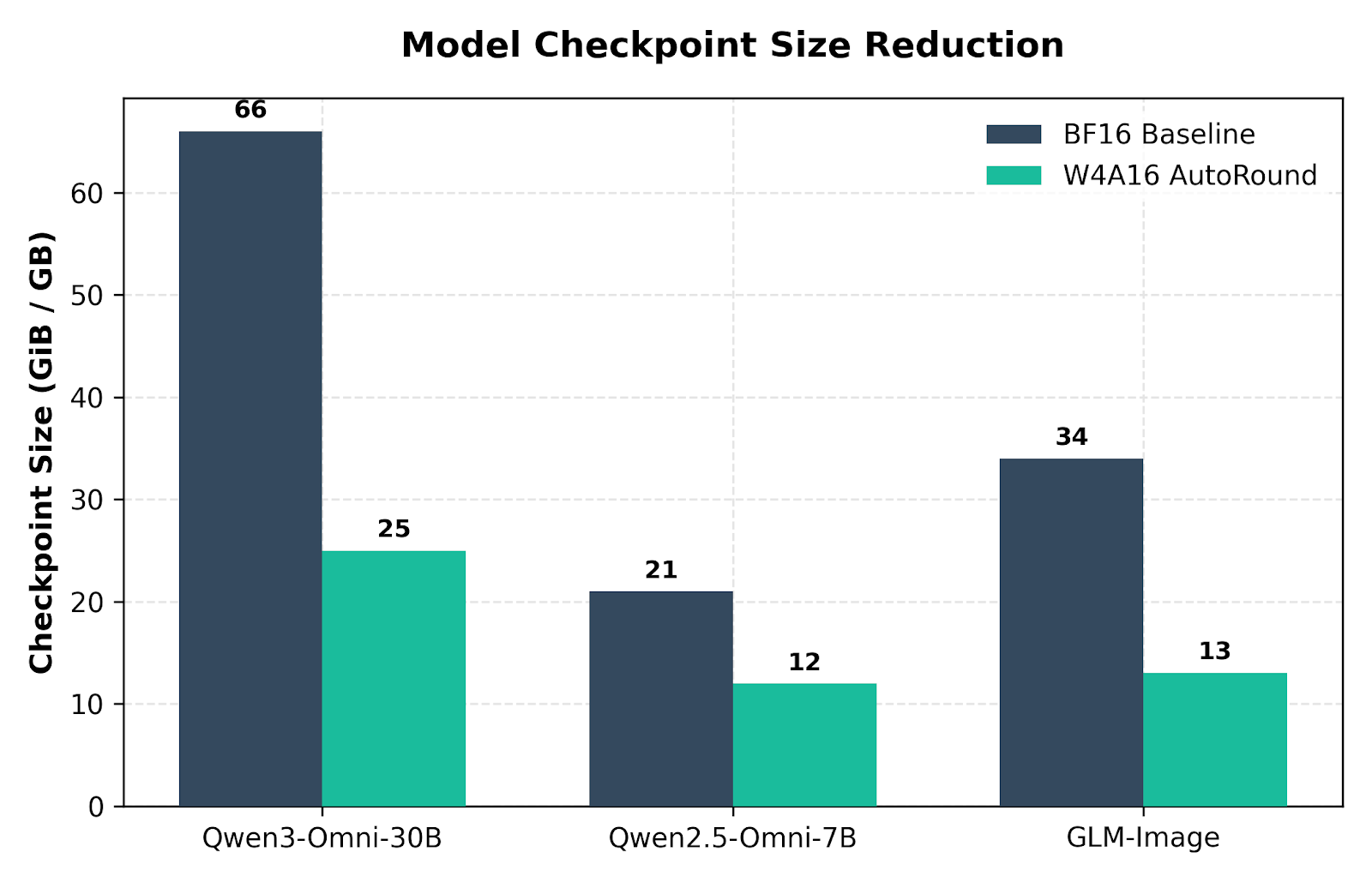
图 5:vLLM-Omni 模型系列中 BF16 和 W4A16 AutoRound 之间的 VRAM 占用对比。
有一个细微之处需要注意:并非每个管线的每个阶段都被量化。VAE 解码、辅助阶段以及多阶段系统的部分可能仍保持较高精度。这就是为什么权重压缩比通常大于端到端延迟加速比的原因。
5.2 用内存空间换取延迟降低
虽然第 5.1 节确立了 W4A16 的首要内存优势,但本案例研究展示了这种内存空间如何转化为架构优势——实现了 GPU 分配策略,从而带来超出原始计算节省所预测的实际吞吐量提升。上述所有基准测试均在 Intel XPU B60 上进行。
W4A16 将最低硬件要求从 4 个 GPU 降低到仅 1 个 GPU
一旦包含运行时激活,BF16 FLUX.1-dev 的 Transformer (23 GB) 超过了单个 B60 的 24.4 GB 容量——它需要 TP=4(全部四个 GPU)才能部署。W4A16 的 7 GB Transformer 可以轻松地放在单个 GPU 上,并留有 19% 的空间。
W4A16 + CFG 并行 = 1.55x - 1.67x 更快的引导生成
无分类器引导 (CFG) 要求每步运行两次去噪过程——一次使用提示词,一次使用负提示词。由于 BF16 占用所有 4 个 GPU 进行张量并行,这些过程必须顺序执行(2 倍延迟)。W4A16 适合 TP=2,释放了 2 个 GPU。这使得 CFG 并行成为可能——跨两个 GPU 组同时运行两个引导分支:
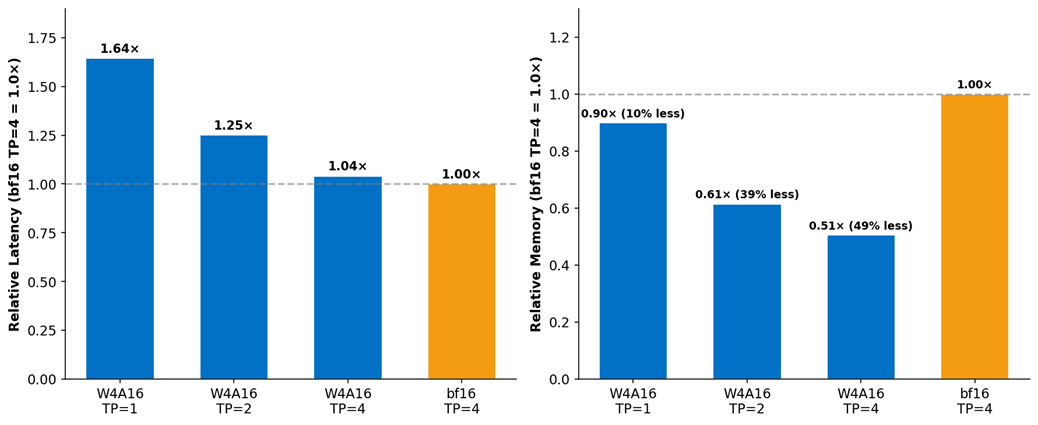
图 6:延迟和内存权衡分析:W4A16 将最低硬件要求从 4 个 GPU 降低到 1 个,从而实现了 CFG 并行执行。
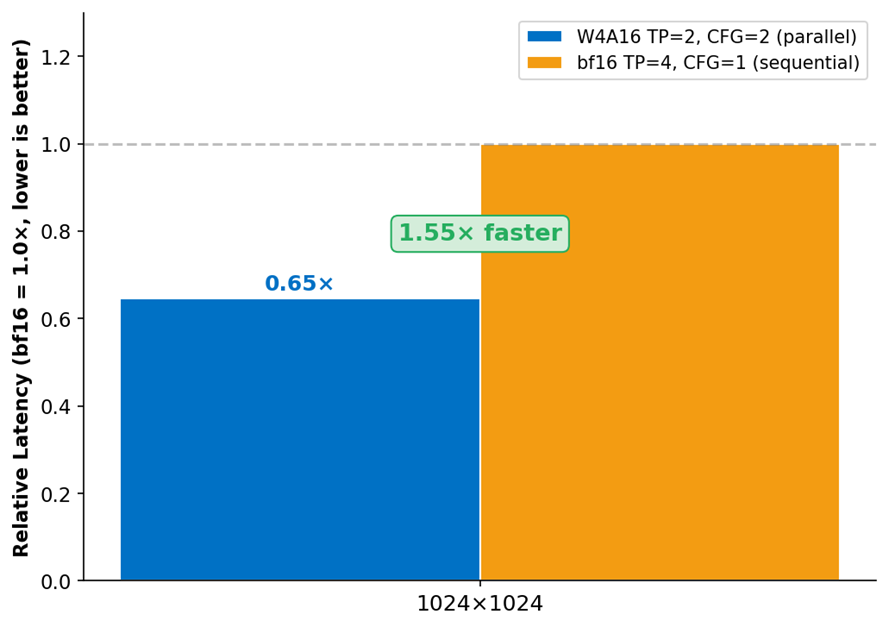
图 7:在 Intel XPU B60 上,CFG 并行执行相比顺序 BF16 部署实现了 1.55-1.67 倍的加速。
关键洞察:W4A16 在扩散工作负载中的价值超越了内存叙事。内存空间不仅允许模型适配——它还使模型能够以不同的方式运行,解锁了并行策略,从而产生比原始反量化开销所预测的更大的端到端加速。
6. 结论
AutoRound 与 vLLM-Omni 的契合度异常出色,因为该集成尊重了运营人员的实际需求:离线 checkpoint 生成、自动运行时检测、可预测的内存节省,以及在部署前验证质量的途径。结果是形成了一个实用的低比特部署工作流,现在已覆盖 vLLM-Omni 生态系统的很大一部分,从 FLUX 和 Wan 到 GLM、BAGEL、Ovis 和 Qwen Omni。
对于更广泛的社区,真正的要点是:量化不再仅仅是在 benchmark 上取胜的巧妙技巧——它已成熟为基础设施的基石。随着 AutoRound 在模型系列和硬件架构上扩大其兼容性,它为平衡多模态性能、部署成本和输出质量提供了一条有效路径。
正在进行的工作包括更广泛的格式支持,以及在模型系列和硬件目标上的持续扩展。我们正在积极扩展对额外量化格式(如 MXFP4 和 MXFP8)的支持,用于 Linear 和 MoE 模块,同时也在探索注意力层的低比特技术(例如 SageAttention)。这些改进将在不久的将来进一步扩展多模态部署的效率和灵活性。
7. 致谢
特别感谢 vLLM-Omni 团队的 Hongsheng Liu、Shunyang Li 和 WeiQing Chen,以及 Intel 的 Chendi Xue,感谢他们在将 AutoRound 集成到 vLLM-Omni 过程中提供的巨大支持。我们也深深感谢 vLLM-Omni 社区对 AutoRound 的迅速采用!