vLLM 实现快速高效 LLM 推理:DeepLearning.AI 新课程
Fast & Efficient LLM Inference with vLLM: A New Course with DeepLearning.AI
vLLM 与 Red Hat、DeepLearning.AI 合作推出实践课程“Fast & Efficient LLM Inference with vLLM”,由 Andrew Ng 参与。课程约 1.5 小时,含 9 节视频和 3 个动手实验,覆盖 LLM 推理优化、部署与基准测试全流程。内容分三阶段:使用 LLM Compressor 量化 Qwen 模型、通过 vLLM 部署并观察 continuous batching 与 prefix caching、利用 GuideLLM 模拟流量并配合 lm-eval 评估模型质量。
 我们很高兴与 Red Hat 和 Andrew Ng 的 DeepLearning.AI 共同宣布推出一门实践课程,该课程将讲解 LLM 基础知识,并完整介绍使用 vLLM 及其工具生态进行 优化、部署和基准测试 的 AI 部署生命周期。课程名为 Fast & Efficient LLM Inference with vLLM,现已上线!
我们很高兴与 Red Hat 和 Andrew Ng 的 DeepLearning.AI 共同宣布推出一门实践课程,该课程将讲解 LLM 基础知识,并完整介绍使用 vLLM 及其工具生态进行 优化、部署和基准测试 的 AI 部署生命周期。课程名为 Fast & Efficient LLM Inference with vLLM,现已上线!
"高效地部署开源 LLM,使其能够服务大量用户,同时保持低延迟和合理成本,是一项挑战。本课程将向你展示如何做到这一点。" — Andrew Ng
课程是如何形成的
今年早些时候,我们与 DeepLearning.AI 团队取得了联系,计划开设一门专注于 LLM 推理优化的课程。由于 vLLM 生态已发展壮大,不仅包含推理引擎本身,还包括模型压缩工具(LLM Compressor)和部署基准测试工具(GuideLLM),我们看到了一个机会,可以展示在大规模部署模型时,这些组件如何协同工作。
与 Andrew Ng 及其在山景城的团队合作,我们围绕许多部署所遵循的工作流程来设计课程内容:压缩模型以适应你的硬件,使用 vLLM 高效地提供服务,然后进行基准测试以了解你在速度-成本-准确率权衡中的位置。在代码示例开始之前,课程还包含了大量关于推理和内存的基础概念,这确实能帮助学习者理解为什么 continuous batching、PagedAttention 和 prefix caching 等优化技术会有所帮助。
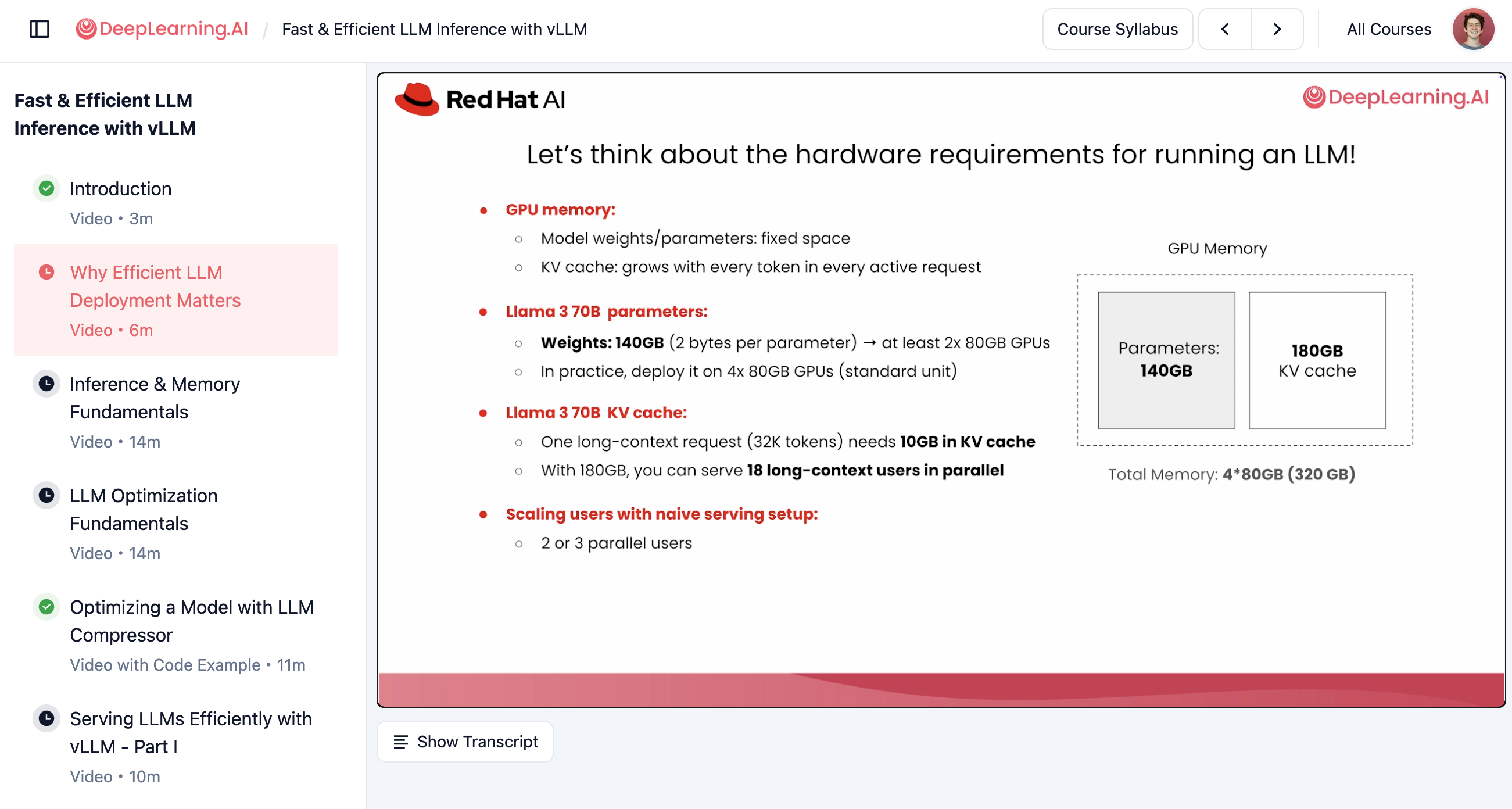 课程在进入动手实验之前,涵盖了硬件需求、内存层次结构和优化技术。
课程在进入动手实验之前,涵盖了硬件需求、内存层次结构和优化技术。
我们投入了什么
大量的精力投入在了可视化上。我们希望学习者真正理解推理背后发生了什么,以及 KV Cache 和 GPU 内存层次结构。
我们分解了推理时的 Transformer 架构,例如 token 如何流经模型,每一层执行什么计算,以及瓶颈实际在哪里。我们还可视化了 KV cache:它在 GPU 内存中的样子,它如何随着每个生成的 token 而增长,以及为什么服务多个并发用户会产生巨大的内存压力。
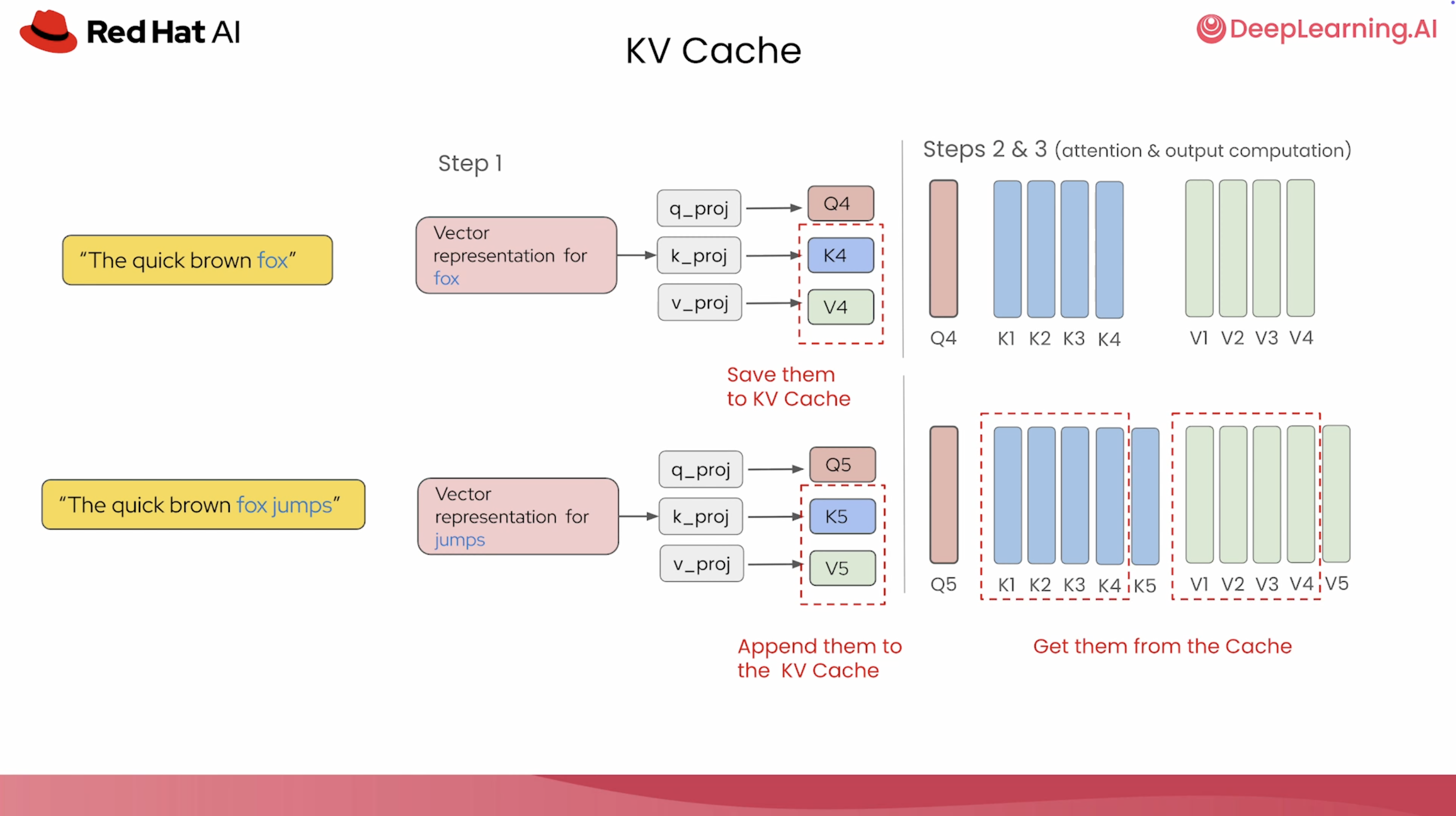 课程中可视化 KV cache 在自回归生成过程中如何增长。
课程中可视化 KV cache 在自回归生成过程中如何增长。
对于量化,我们构建了可视化解释,说明当你从模型默认发布的 FP16 权重转向 INT8 或 INT4 时会发生什么,包括其好处和权衡。
 分解仅权重量化与权重-激活量化,以及 GPU 内存层次结构。
分解仅权重量化与权重-激活量化,以及 GPU 内存层次结构。
课程内容
课程主要分为三个阶段,每个阶段在 JupyterLab 环境中都有一个动手实验,学习者可以在其中使用实际模型和正在运行的 vLLM 服务器:
压缩
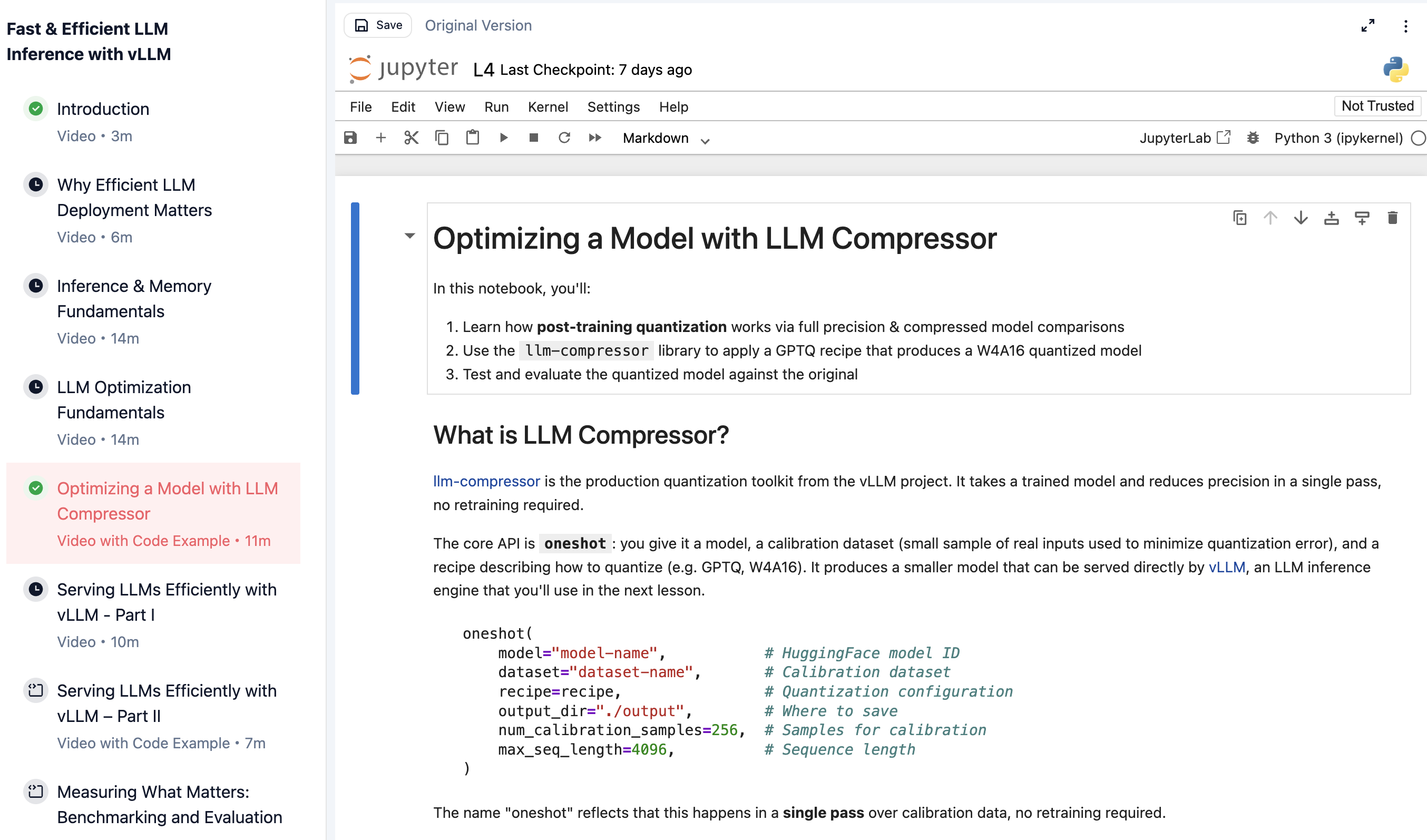
你使用一个全精度的 Qwen 模型,并通过 LLM Compressor 对其进行量化。你比较量化前后的模型大小,然后测量 perplexity 以量化准确率的权衡。这个实验能让你很好地感受量化技术,以及如何在部署 LLM 时减少 GPU 内存需求。
在课程实验中使用 LLM Compressor 量化 Qwen 模型。
服务
你学习如何使用 vLLM 部署模型,并通过 OpenAI 兼容的 API 与之交互。你通过 vLLM 的指标观察 continuous batching 等特性,看到随着并发请求的到来,内存利用率如何变化,以及当请求共享系统提示时,prefix caching 如何避免冗余计算。
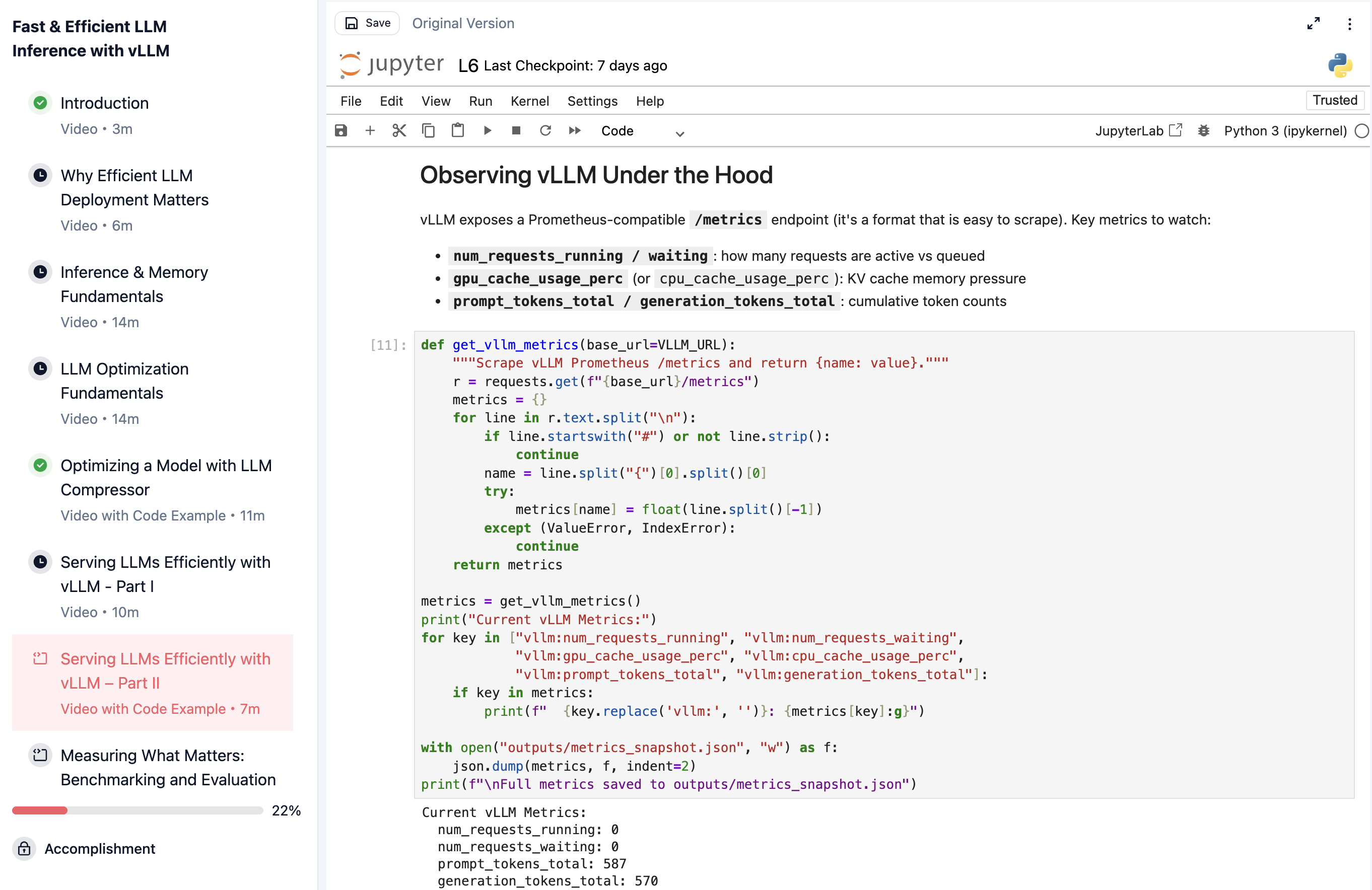 实时观察 vLLM 在并发请求到达服务器时的服务指标。
实时观察 vLLM 在并发请求到达服务器时的服务指标。
基准测试
你使用 GuideLLM 模拟真实的流量模式,测量负载下的延迟和吞吐量。然后你使用 lm-eval 评估模型质量,以确认压缩后的模型仍然满足你的准确率要求。最后,你在一个真实模型上运行了完整的负载/准确率分析,并充分理解了权衡,从而能够做出明智的部署决策。
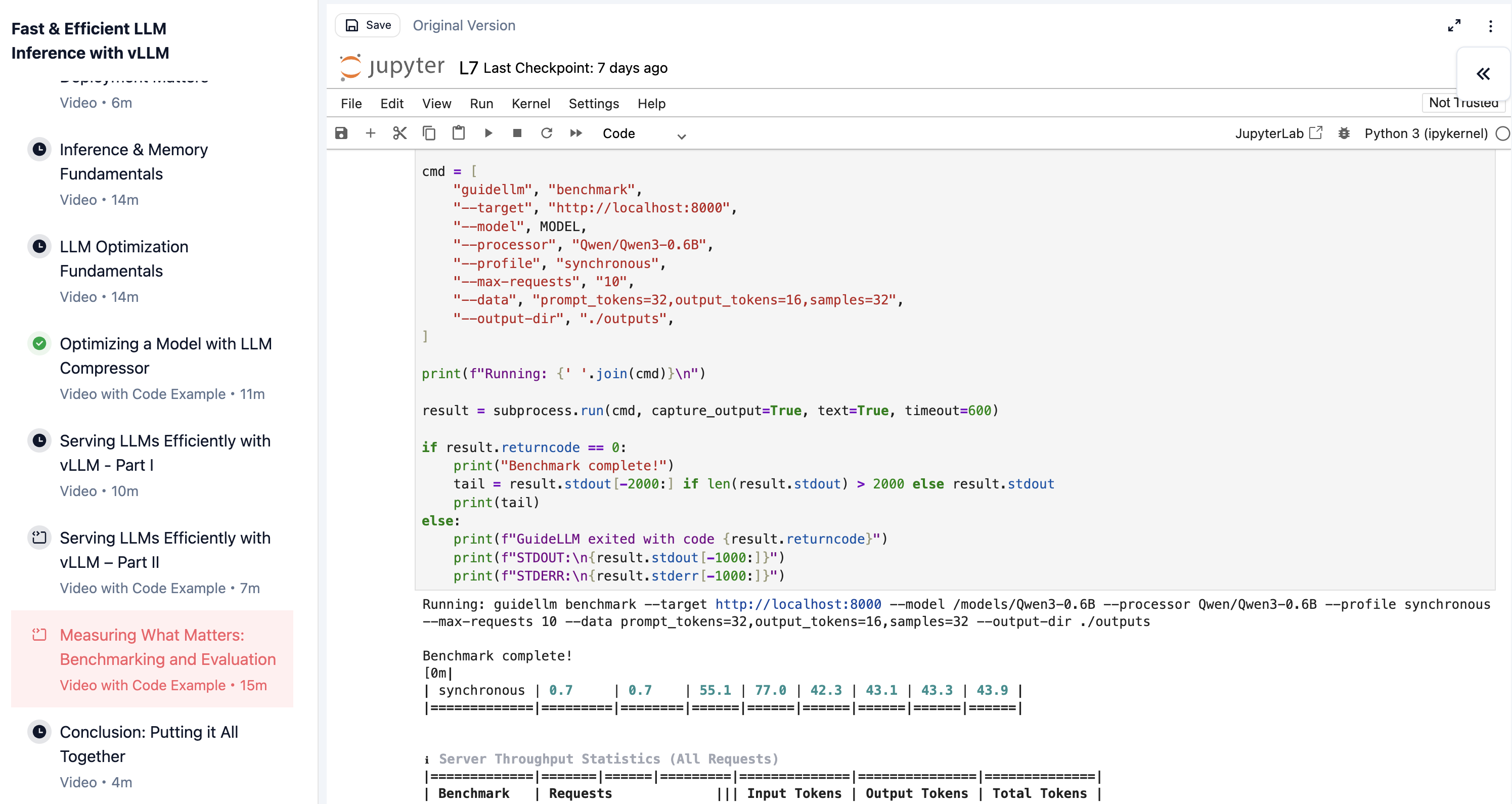 在课程实验中使用 GuideLLM 在模拟流量下对 vLLM 部署进行基准测试。
在课程实验中使用 GuideLLM 在模拟流量下对 vLLM 部署进行基准测试。
课程详情
- 课程:Fast & Efficient LLM Inference with vLLM
- 讲师:Cedric Clyburn,Red Hat 高级开发者倡导者
- 时长:约 1.5 小时,9 节视频课程,3 个动手代码实验
- 级别:中级(假设熟悉 Python 和基本的 LLM 概念)
该课程在 DeepLearning.AI 上免费提供。如果你一直在本地或大规模运行模型,并想了解表面之下发生了什么,或者你听说过 vLLM 并想动手实践,那么这门课程会很有用。你将获得部署开源模型的经验,我们希望这是一个有用的资源。
致谢
这门课程是团队合作的成果。来自 Red Hat 的:Saša Zelenović、Michael Goin 和 Sawyer Bowerman 为课程设计、技术内容和实验开发做出了贡献。来自 DeepLearning.AI 的:Hawraa Salami 帮助制定了课程大纲和制作。感谢 Andrew Ng 的合作,并在 DeepLearning.AI 的课程目录中为开源推理工具留出了空间。希望你喜欢这门课程!