vLLM 中 FP8 KV-Cache 与 Attention 量化的现状
The State of FP8 KV-Cache and Attention Quantization in vLLM
vLLM 博文由 AWS、Red Hat AI 作者撰写,测试 `--kv-cache-dtype fp8` 在 Hopper/Blackwell 上的 KV-cache 与 attention 量化,修复 FA3 accumulation 精度问题,加入 layer skipping、per-head scales 等;H100 上 Llama-3.1-8B 的 FP8 ITL slope 为 BF16 的 54%,MRCR/AIME 等评测显示多数模型接近 baseline。
vLLM 中 FP8 KV-Cache 与 Attention 量化的现状 | vLLM Blog
菜单
主题
![]() ](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
vLLM 中 FP8 KV-Cache 与 Attention 量化的现状
2026 年 4 月 22 日 21 分钟阅读
Jonas Kübler* (AWS), Eldar Kurtić* (Red Hat AI), Lucas Wilkinson (Red Hat AI), Matthew Bonanni (Red Hat AI), Michael Goin (Red Hat AI), Alexandre Marques (Red Hat AI), Kailash Budhathoki (AWS) (* 同等贡献)
#quantization#performance#kv_cache#fp8
- 引言
- 我们发现的问题
- Kernel 与 vLLM 改进
- 性能 Benchmark
- 单请求 Benchmark
- 负载下的吞吐
- 大 Head Dimension 的限制
- Blackwell (B200) GPU 上使用 FlashInfer 的性能
- 精度 Benchmark
- 推理能力评测
- 长上下文评测
- Blackwell (B200) GPU 上使用 FlashInfer 的精度
- 总结
- 什么时候应该使用 Calibration?
- 什么时候应避免使用 FP8 KV-Cache
目录
引言
长上下文 LLM serving 越来越受内存限制:对于标准 full-attention decoder,KV cache 在 128k+ 上下文中通常占据 GPU 内存的主要部分,而每个 decode 步骤都必须读取该 cache 的很大一部分。因此,只要精度能够保持,用 FP8 将 KV-cache 存储减半,就能在相同硬件成本下显著提高并发或支持更长上下文。
vLLM 的 --kv-cache-dtype fp8 flag 会量化 KV-cache,并以 FP8 运行整个 attention 计算(QK 和 ScoreV 矩阵乘法;本文全篇使用 e4m3 格式)。这个功能已在 vLLM 中存在一段时间,但它在 prefill-heavy 和 decode-heavy 工作负载的压力测试下表现如何?我们对 decoder-only 和 MoE 模型,以及 Hopper 和 Blackwell 架构进行了全面验证。我们发现并修复了 Flash Attention 3 (FA3) backend 中关键的精度和性能问题(见图 1 的示例)。在本文验证过的路径上,它在降低 decode 成本和 KV-cache 内存使用的同时,保持了接近 baseline 的精度。主要注意事项是带有小 sliding-window layer 的 hybrid-attention 模型,此时跳过这些 layer 通常更好;以及大 head dimension 模型(head_dim = 256),其 prefill 仍可能退化。此外,对于 head dimension 64 和 128,FP8 格式在 prefill 和 decoding 上都能带来加速。对于内存受限的 decoding,KV cache 的 per-token 成本在最佳情况下可降至 BF16 对应成本的 54%。对于 256 这类大 head dimension,FP8 也能降低 ITL;不过默认 prefill 性能目前仍略差于 BF16。
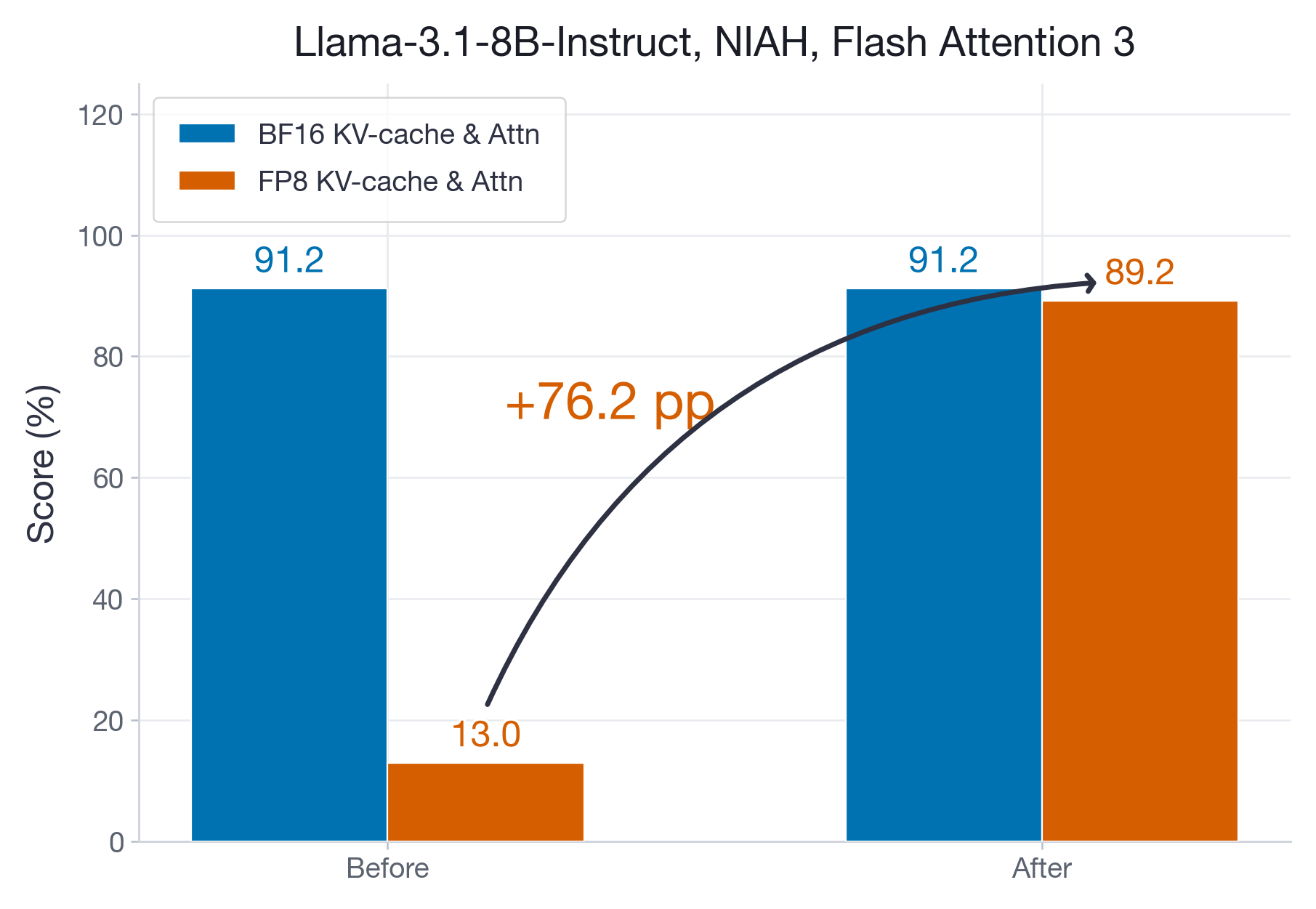
图 1:修复 FP8 Flash Attention 3 前后,在 Hopper 上 128k 的 needle-in-a-haystack 结果。Accumulation 修复将长上下文精度从严重的 FP8 退化恢复到接近 BF16 baseline,同时优化后的 FP8 路径仍保留 decode 速度优势。
目录
快速开始:
# FP8 KV-cache for all layers
vllm serve meta-llama/Llama-3.1-8B --kv-cache-dtype fp8
# FP8 KV-cache, skipping sliding-window layers (recommended for hybrid-attention models)
vllm serve gpt-oss-20b --kv-cache-dtype fp8 --kv-cache-dtype-skip-layers sliding_window
我们发现的问题
虽然 --kv-cache-dtype fp8 已在 vLLM 中存在一段时间,但我们的压力测试揭示了两类问题:
精度: 在 Hopper GPU 上,FP8 Flash Attention 3 kernel 在长上下文中存在 accumulation 精度损失。在 128k needle-in-a-haystack 任务上,FP8 精度从 91%(BF16 baseline)降至仅 13%——这一退化可追溯到 Tensor Cores 中不精确的 FP32 accumulation(见下文 two-level accumulation 修复)。
性能: 对于带 sliding-window attention layer 的模型(例如 gpt-oss-20b),FP8 ITL slope 几乎与 BF16 相同(为 BF16 slope 的 96%),这意味着尽管内存减半,用户几乎得不到 decoding 加速。break-even point 超过 700k tokens,远超多数实际上下文长度。
下一节介绍我们为解决这些问题而发布的改进。
Kernel 与 vLLM 改进
在调研过程中,我们发布了多项改进,以增强量化方案的灵活性、修复精度问题并提升性能。这里简要说明如下。
Two-level accumulation: Hopper 的 FP8 Tensor Cores 文档说明其会累加到 FP32 register,但实际中,当 contraction dimension 很大时,中间 accumulation 会损失精度——这是一个已知的硬件级问题,在 DeepSeek-V3 训练中也曾遇到(见 DeepSeek-V3 Technical Report 的图 7(b))。当 contraction dimension 达到 100K 或更高时,这种不精确 accumulation 会造成严重数值错误。具体来说,在长上下文 inference 中,Softmax(AttnScore) * V matmul 的 contraction dimension 对应上下文长度。经验上,我们发现这会导致长上下文 needle-in-a-haystack 任务的精度从 91%(BF16)退化到 13%(FP8)。为缓解这一问题,我们加入了 two-level accumulation 策略(见 SageAttention2),将部分累加结果写入一个_真正的_ FP32 register(flash-attention#104),使 FP8 精度恢复到 89%。缺点是,这种 two-level accumulation 会增加 register pressure,并导致 prefill 变慢。我们通过优化 tiling 配置部分解决了这一问题(flash-attention#125),但对于 head dimension 大于 128 的情况,prefill 性能仍落后于 BF16。
跳过 Layer: 早期 vLLM 只允许用户为所有 Attention Layer 选择单一数值格式。我们增加了 --kv-cache-dtype-skip-layers(vllm#33695)以支持 hybrid 设置。GPT-OSS 这类模型使用了一些 sliding window attention layer,其中 token 只 attend 到固定窗口大小,例如 128 tokens。在这里,FP8 的开销无法被摊销。因此,将这些 layer 保持为 BF16 实际上比量化更快,见下文的实证结果。此外,如果某些 layer 对量化特别敏感,该功能也允许跳过这些 layer。
Per-Head Scales:Flash Attention 3 kernel 允许为 attention 操作的 FP8 量化指定一个 scale 数组,其中每个 scale 对应一个 KV-head。在 vLLM 中启用该功能需要泛化对所有 group-shape 的 static quantization 支持(vllm#30833),并扩展 reshape_and_cache_flash kernel 的适用范围(vllm#30141),使其处理 scale 数组而不是单个 scalar。
Query Quantization Fusion: 我们将 query quantization 从 attention backend 移到一个简单的 torch 实现中,使 torch.compile 可以将其 fusion 到周围操作中,从而消除固定的 per-token 开销(vllm#24914)。
优化 FA3 FP8 tile size: 我们针对 head_dim = 64 和 head_dim = 128 调优了 prefill tiling 配置,以减少 two-level accumulation 引入的 register spill(flash-attention#125)。此外,我们为内存受限的 decoding 工作负载加入了专门调优的配置,显著降低了 ITL 随上下文增长的增幅,也就是 slope(flash-attention#96,flash-attention#91)。
性能 Benchmark
在长上下文 LLM serving 的 decoding 阶段,attention 可能是一项显著成本。每个生成 token 都必须 attend 到完整 KV-cache,因此 inter-token latency (ITL) 会随输入长度线性增长。将 KV-cache 从 BF16 量化到 FP8 会将每个 cached token 的内存减半,从而将每个 attention 步骤的内存流量减半,这应当直接转化为更低的 ITL slope。由于 Hopper 和 Blackwell GPU 的 FP8 FLOPs 是 BF16 的两倍,理想情况下,我们也应期望 prefill 加速。然而实践中,这些收益并不总是开箱即用就能实现,下面几节将对此展示。
单请求 Benchmark
为了清晰理解 attention 行为,我们先展示 concurrency 1 的 benchmark,随后再看 batched inference。对于 concurrency 1,Inter-Token-Latency (ITL) 与 Time-to-First-Token (TTFT) 完全分离,因此我们可以对 ITL 与 input length 拟合线性模型:
ITL = slope × input_len + intercept
并对 TTFT 拟合二次模型:
TTFT = a × input_len² + b × input_len + c
ITL slope 直接反映 per-token attention 成本——更低的 slope 意味着每增加一个 cached token 带来的延迟更少,这对长上下文工作负载至关重要。break-even point 是 FP8 ITL 低于 BF16 ITL 的上下文长度;超过这一点,FP8 在 decoding 上严格更快。二次 TTFT 模型刻画 compute-bound 的 prefill 阶段,由于输入上的 self-attention,成本会随序列长度二次增长。
所有 Hopper 实验都在单张 H100 GPU 上运行,使用 FlashAttention-3(通过 vLLM fork),它提供带 online softmax rescaling 的原生 FP8 KV-cache 支持。我们使用单 GPU、vllm bench serve、concurrency 1、128 个输出 token,并将输入长度从 256 扫描到 125k tokens。
图 2 展示了 Llama-3.1-8B 模型的结果。
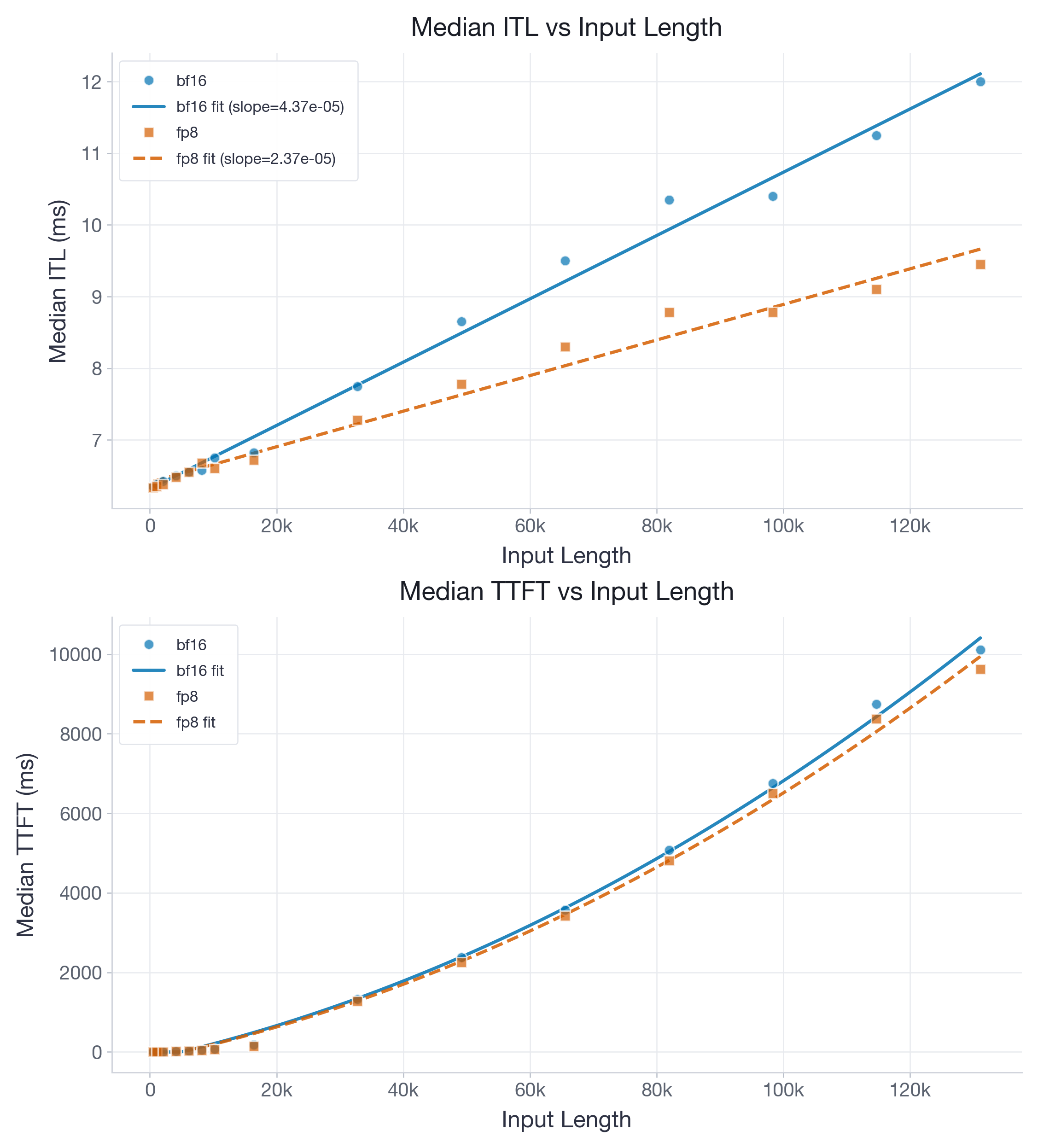
图 2:Llama-3.1-8B 的单请求 H100 benchmark。相对于 BF16,FP8 几乎将 decode ITL slope 减半,且几乎没有 intercept 惩罚,将 decode break-even point 降至约 7k tokens,同时保持相近 TTFT。
拟合得到的 ITL slope 从 4.37e-05 降至 2.37e-05 ms/token,而 intercept 仅从 6.44 变为 6.58 ms。FP8 的 slope ratio 为 BF16 的 54%,接近最优,intercept 差距仅 0.14 ms。这将 break-even point 拉低到约 7k tokens。此外,即使启用了 two-level accumulation,FP8 在长上下文下也能获得轻微 TTFT 加速。
接下来我们转向 gpt-oss-20b,这是一个 20B 参数模型,具有 hybrid attention 架构,同时包含 global layer 和 sliding-window layer(窗口大小 128)。Sliding-window layer 的 KV-cache 大小有上界,因此量化它们在长上下文中收益递减。通过 --kv-cache-dtype-skip-layers sliding_window,我们将这些 layer 保持为 BF16,只将 global attention layer 量化为 FP8。图 3 报告了该模型在 BF16 KV-cache、FP8 KV-cache,以及跳过 sliding-window layer 的 FP8 KV-cache 下的结果。
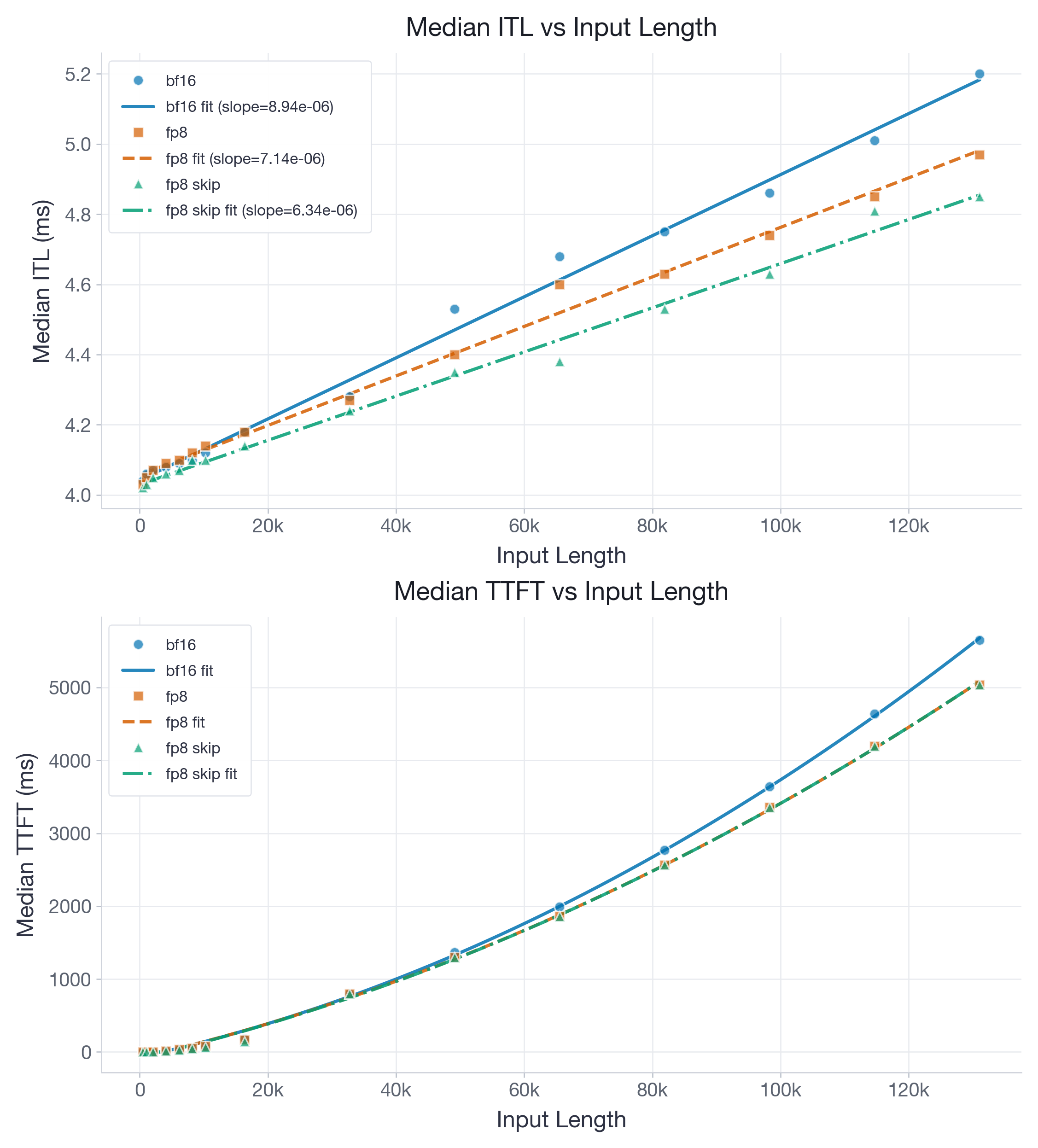
图 3:gpt-oss-20b 的单请求 H100 benchmark。跳过 sliding-window layer 是最好的 FP8 变体,因为这些 layer 的 KV-cache footprint 有上界,因此会承担量化开销,却得不到太多长上下文收益。
拟合得到的 ITL slope 从 BF16 的 8.94e-06 ms/token 降至 full FP8 的 7.14e-06,以及 FP8 skip-SW 的 6.34e-06,而 intercept 都集中在 4.03 到 4.07 ms 之间。FP8 slope 为 BF16 的 80%(full FP8)和 71%(skip-SW),这使 FP8 成为有吸引力的选项。在我们的改进之前,BF16 和 FP8 的 slope 几乎相同。
skip-sliding-window 变体明显最佳:通过将 bounded sliding-window layer 保持为 BF16(在这些 layer 中,量化增加的是常数开销,但在长上下文中没有内存节省),它以很小的 intercept 惩罚取得最低 slope。因此我们推荐使用该变体。
实践结论:对于长上下文、decode-heavy 的 serving,当 KV-cache 流量占主导时,FP8 最具吸引力;在 H100 上,对于 Llama 类模型,以及在跳过小 sliding-window layer 之后的 hybrid 模型,它已经明显有益。
下表总结了我们改进前后的单请求性能,显示 break-even point 和 ITL slope 显著降低。
表 3:两个分析模型及 KV-cache 变体的改进汇总。
| 模型 | 版本 | FP8 变体 | Break-even (tokens) | FP8 slope(占 BF16 百分比) |
|---|---|---|---|---|
| Llama-3.1-8B | before (v0.10.2) | FP8 | 24,889 | 63% |
| Llama-3.1-8B | after (v0.19.1) | FP8 | 7,010 | 54% |
| gpt-oss-20b | before (v0.10.2) | FP8 | 741,565 | 96% |
| gpt-oss-20b | after (v0.19.1) | FP8 | 22,109 | 80% |
| gpt-oss-20b | after (v0.19.1) | FP8 skip-SW | 7,659 | 71% |
负载下的吞吐
上述 sweep 隔离了 concurrency 1 下的 per-token attention 成本。为了在更真实条件下测量端到端 serving 性能,我们运行吞吐 benchmark:concurrency 8 下 150 个请求,每个请求约 20k 输入 token、约 2k 输出 token(±15% 方差)。结果见表 4 和表 5。
表 4:Llama-3.1-8B 模型在重吞吐负载下,KV-cache 为 BF16 和 FP8 格式时的性能结果。FP8 显示输出吞吐提高 14.9%,总运行时间缩短 13.0%,median ITL 降低 14.8%。
| 配置 | Median TTFT (ms) | Median ITL (ms) | 总时长 (s) | 输出 tok/s |
|---|---|---|---|---|
| BF16 | 763.6 | 15.18 | 672.6 | 450.3 |
| FP8 | 742.8 | 12.93 | 585.2 | 517.5 |
表 5:gpt-oss-20b 模型在重吞吐负载下,KV-cache 为 BF16、FP8,以及跳过 sliding window 的 FP8 时的性能结果。FP8 skip-SW 显示输出吞吐提高 4.8%,总运行时间缩短 4.6%,median ITL 降低 4.8%。
| 配置 | Median TTFT (ms) | Median ITL (ms) | 总时长 (s) | 输出 tok/s |
|---|---|---|---|---|
| BF16 | 468.9 | 8.09 | 364.2 | 831.6 |
| FP8 | 451.7 | 7.90 | 355.1 | 853.0 |
| FP8 skip-SW | 456.4 | 7.70 | 347.4 | 871.8 |
这些吞吐结果确认,单请求 ITL 改进会转化为负载下的真实 serving 收益。对于 Llama-3.1-8B,concurrency 1 下 54% 的 ITL slope 降低,转化为 concurrency 8 下 14.9% 的输出吞吐提升——FP8 不仅让每个 token 的 decode 更快,2x 内存降低也使 scheduler 能打包更多并发请求。对于 gpt-oss-20b,收益较小(4.8%),因为该模型的 sliding-window layer 限制了内存节省;skip-SW 变体通过避免对无法受益的 layer 施加开销,恢复了最多收益。
注意,这些 benchmark 使用 concurrency 8 和约 20k-token 输入,属于中等偏重负载。在更高并发或更长上下文下,FP8 的内存节省会更有影响,因为 BF16 可能会 OOM,或需要更激进的 KV-cache eviction。
大 Head Dimension 的限制
通过 flash-attention#104,我们默认启用了 two-level accumulation,以确保模型最高质量并防止用户遭遇意外精度下降。然而,对于大 head dimension,这会导致 TTFT 慢于 BF16。
为说明这一点,图 4 报告了 H100 上 gemma-4-E2B 的结果,它使用 head_dim = 256。其四分之三的 layer 也带有大小为 512 的 sliding window:
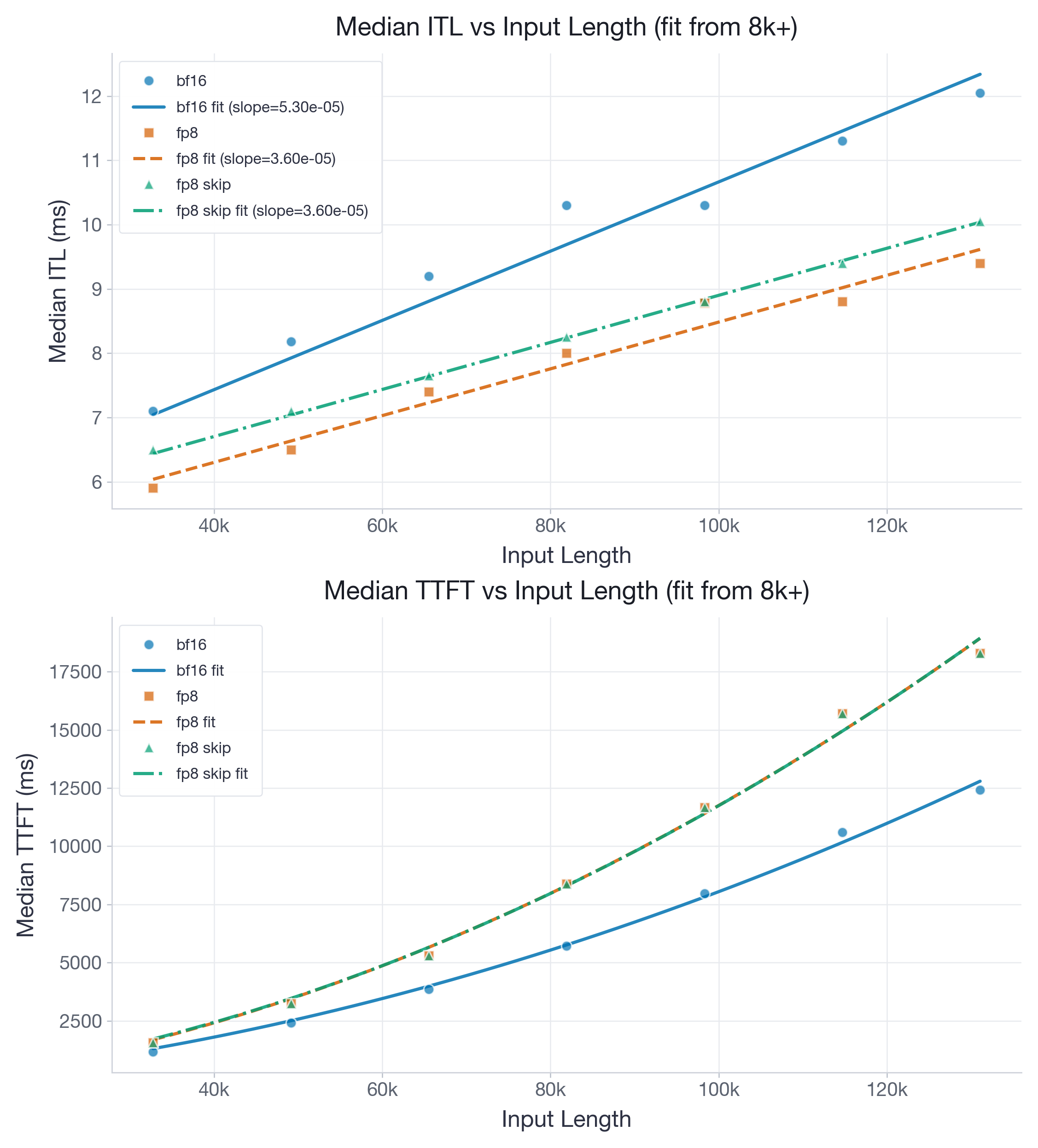
图 4:H100 上的 gemma-4-E2B(head_dim = 256)。FP8 改善 decode ITL,但 prefill 变慢,因为 two-level accumulation 增加的 register pressure 足以抵消 FP8 算术优势。
对于 gemma-4-E2B,ITL slope 从 5.30e-05 降至 3.60e-05 ms/token,而 TTFT 二次项系数从 6.93e-07 升至 1.12e-06 ms/token²。因此,在测量范围内,FP8 带来了明确的 decode 收益(slope 为 BF16 的 68%)。此外,由于 gemma-4-E2B 的 sliding window 大小(512)是 gpt-oss-20b(128)的 4 倍,每个窗口内有足够数据来摊销 FP8 开销,因此也值得量化 sliding-window layer。这会相对于跳过 sliding window layer 带来一个常数偏移。然而,FP8 的 TTFT 二次项系数约为 BF16 的 1.6x,意味着在长上下文下,由于 head_dim = 256 时 two-level accumulation 带来的 register pressure,prefill 会显著_变慢_。
目前有两种方式应对:1)用户可以禁用 two-level accumulation 以提高性能。不过在这种情况下,我们建议在相关工作负载上进行充分精度测试。2)可以让 accumulation 不是每一步都发生,而是每 N 步发生一次。一个可用实现见这个 open PR flash-attention#122,它能恢复 prefill 加速。注意,尤其是第一种选项也会为 head dimension 64 和 128 带来更大的 prefill 加速。
Blackwell (B200) GPU 上使用 FlashInfer 的性能
虽然我们的大部分性能改进面向 H100 和 Flash-Attention 3,但为完整起见,我们也提供了 B200 上使用 FlashInfer backend 的 benchmark。注意在 B200 上,accumulation 问题已经修复,因此不需要显式 two-level accumulation。图 5 和图 6 分别展示了 Llama-3.1-8B 和 gpt-oss-20b 的性能。
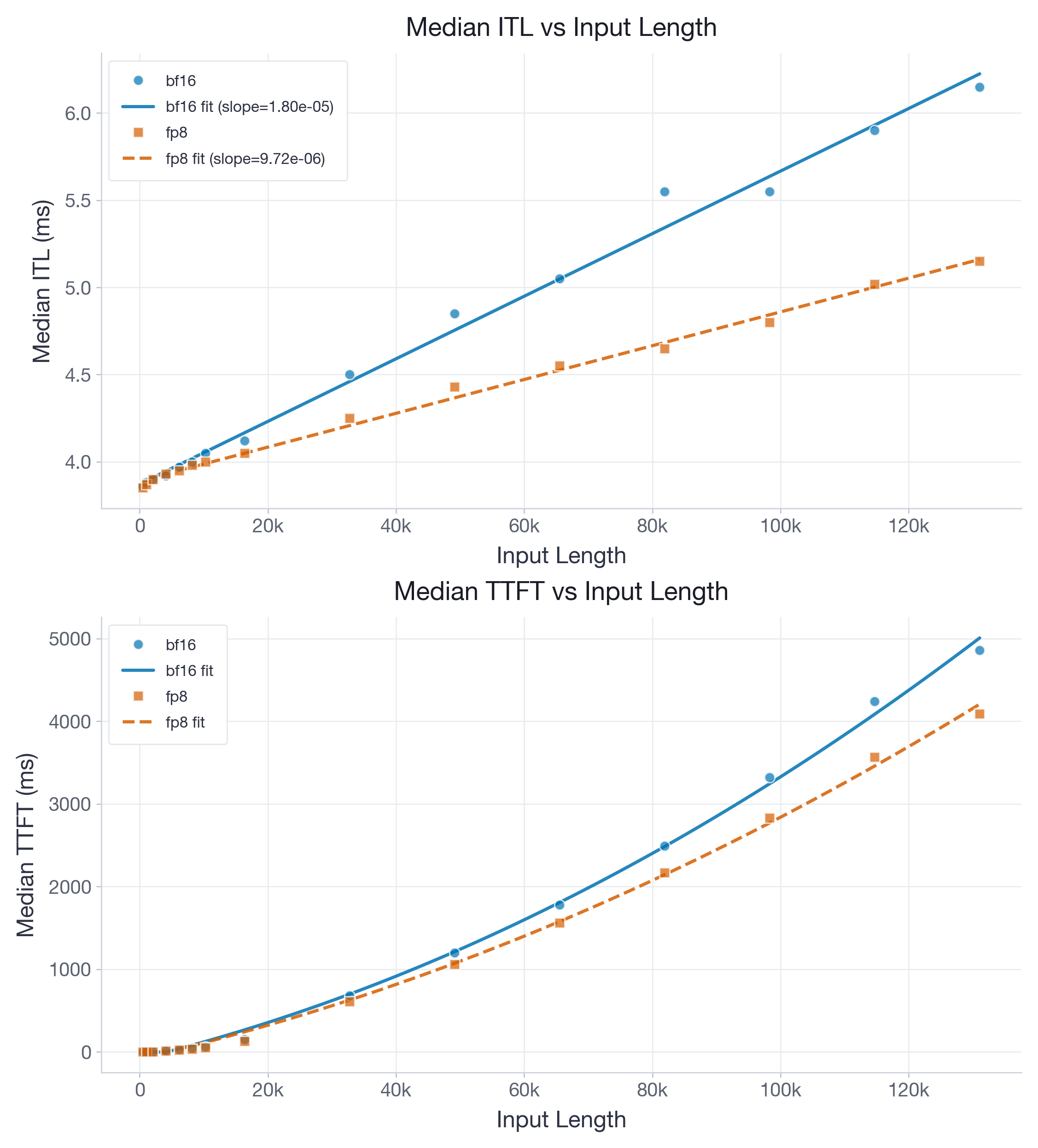
图 5:B200 上使用 FlashInfer 的 Llama-3.1-8B。FP8 再次将 decode ITL slope 降至 BF16 的约 54%,且 intercept 惩罚几乎可忽略,因此 decode 在约 4k tokens 达到 break-even。
对于 B200 上的 Llama-3.1-8B,拟合得到的 ITL slope 从 1.80e-05 降至 9.72e-06 ms/token,而 intercept 仅从 3.93 变为 3.96 ms。
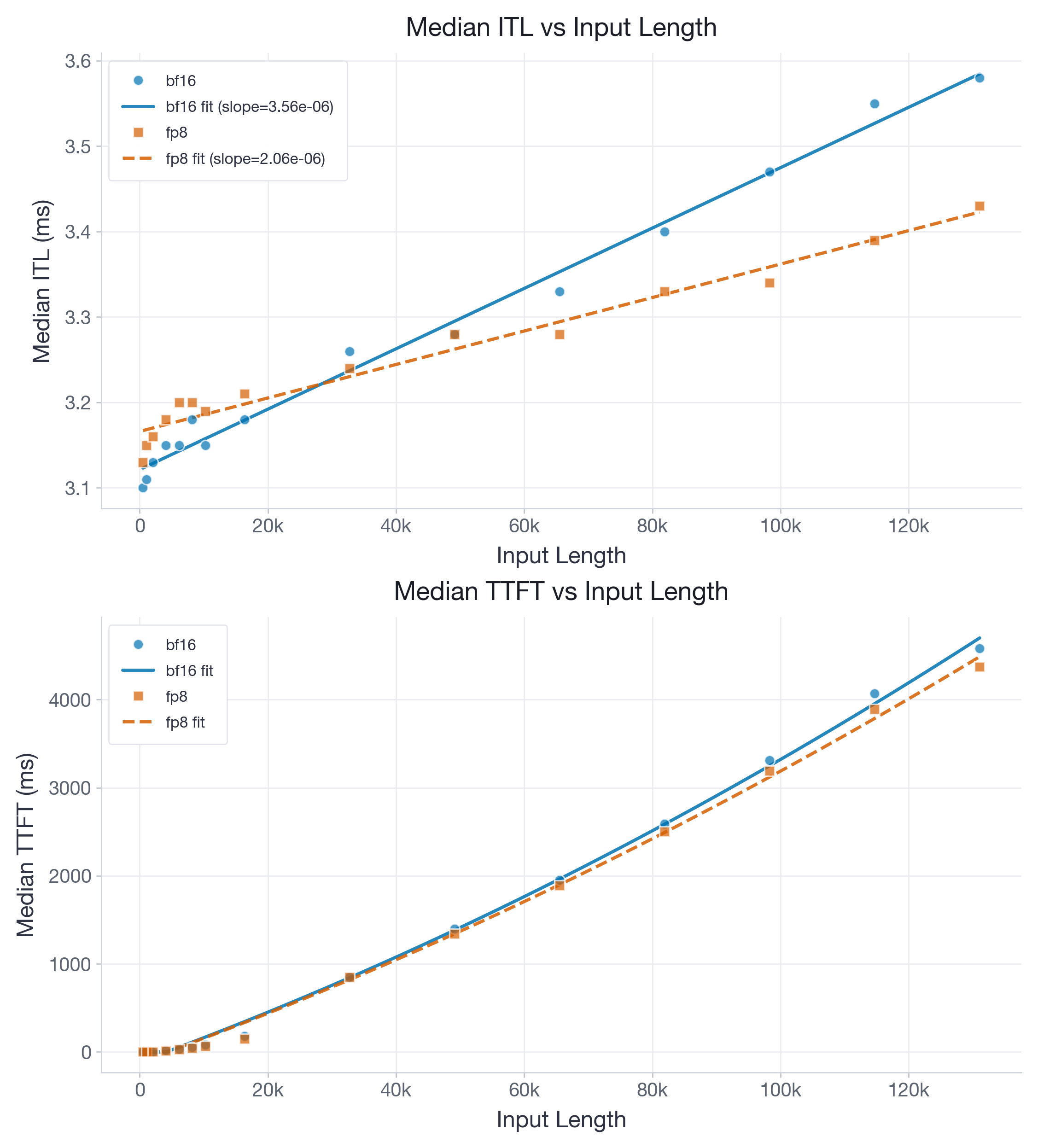
图 6:B200 上使用 FlashInfer 的 gpt-oss-20b。FP8 比在 H100 上更强地降低 decode ITL slope,但该模型仍需要更长上下文,较小 slope 才能抵消固定开销。
对于 B200 上的 gpt-oss-20b,拟合得到的 ITL slope 从 3.56e-06 降至 2.06e-06 ms/token,intercept 从 3.15 变为 3.17 ms,根据拟合结果 break-even 大约在 13k tokens。与 H100 不同,这些 B200 benchmark 只比较 BF16 与 FP8(没有 skip-SW 变体),因为在运行实验时,B200 尚不支持 layer skipping。
精度 Benchmark
我们关注以下模型:Llama-3.3-70B-Instruct、Qwen3-30B-A3B-Instruct-2507、Qwen3-30B-A3B-Thinking-2507 和 Qwen3.5-27B。
对于长上下文(prefill-heavy)评测,我们使用 openai/mrcr 任务,测试最高到 1M 的序列长度。我们报告每个 sequence-length bucket 上 5 次重复的平均 pass@1 分数,并将 Area-Under-Curve (AUC) 作为所有测试长度上的聚合指标(Context Arena)。
对于推理能力(decode-heavy)评测,我们使用 AIME25、GPQA:Diamond、MATH500 和 LiveCodeBench-v6。我们报告平均 pass@1 分数:AIME25 和 LiveCodeBench-v6 为 10 次重复,GPQA:Diamond 和 MATH500 为 5 次重复。
所有评测都采用模型创建者建议的默认 non-greedy sampling 参数,以模拟真实部署。
重要: 所有评测都使用 per-tensor uncalibrated quantization scales(即 scale = 1.0)。这是最简单的配置——没有 calibration 数据、没有 per-head 调优——代表精度的最坏情况。我们选择该设置有两个原因:1)任何 vLLM 用户都可以通过 --kv-cache-dtype fp8 轻松复现;2)它建立了一个下界——使用 calibrated scales 的结果只会更好。不过,我们也支持在目标数据上进行 quantization scales calibration,并支持更高粒度的 scales(per-attention-head,而不是 per-tensor)。有关这些功能的更多细节,请参见后续章节。
推理能力评测
图 7 比较了 Qwen3-30B-A3B-Thinking-2507 的两个版本——原始 BF16 模型和其 FP8 weight-and-activation 量化变体——在推理 benchmark 上的表现。这些 benchmark 通常是短 prefill 后接长 decode-heavy generation,常达到数万 tokens。它们测试 FP8 KV-cache 和 attention quantization 是否会在较长生成链上削弱推理能力。
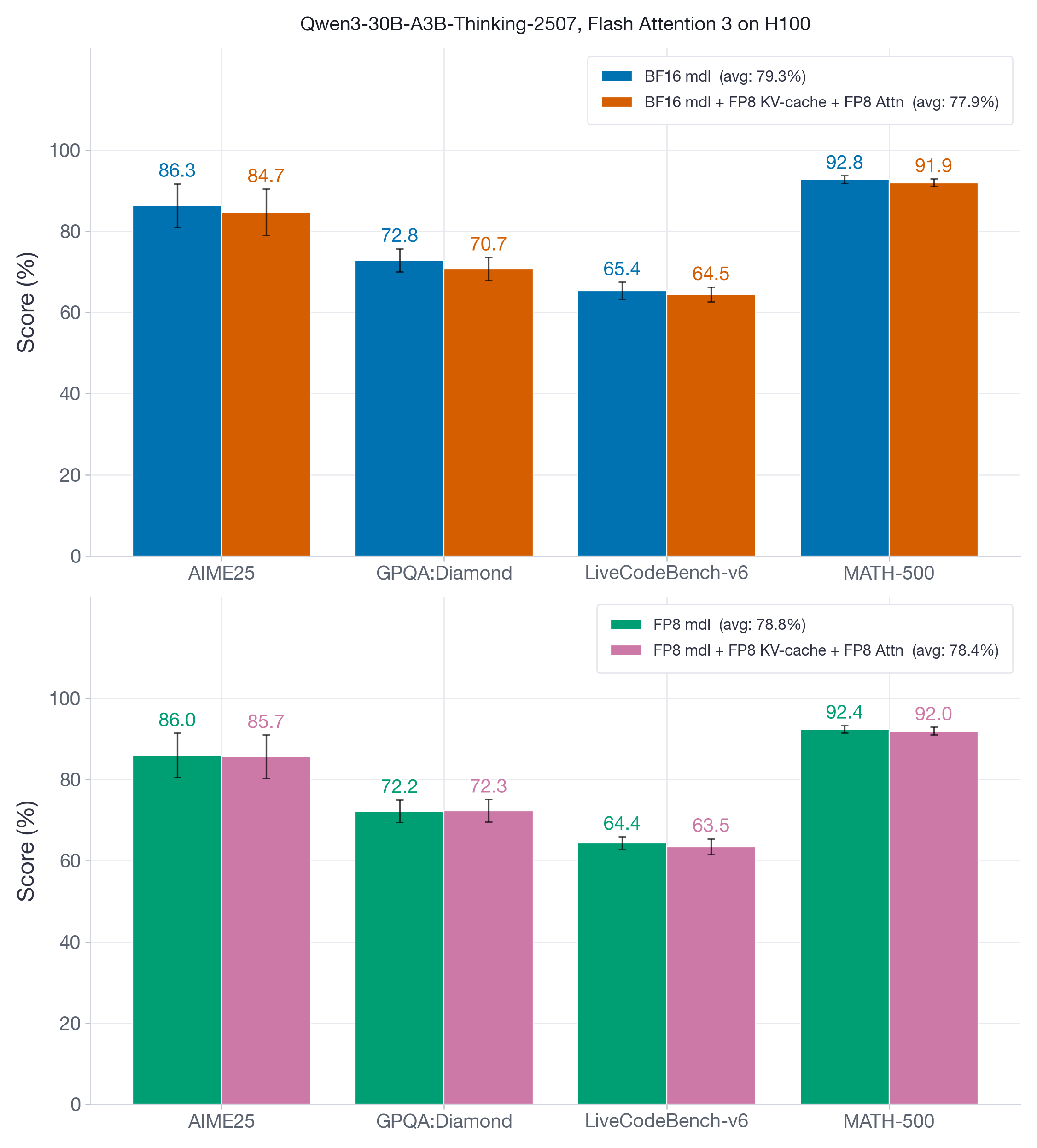
图 7:Qwen3-30B-A3B-Thinking-2507 的推理 benchmark。在 BF16-model 和 FP8-model 两种设置下,启用 FP8 KV-cache 加 FP8 attention 后,这些 decode-heavy 任务的平均精度仅变化约 1-2 分。
FP8 KV-cache 和 attention quantization 最多引入 1-2 分的精度退化,最低 recovery 为 97%(GPQA:Diamond,BF16 model)。
在图 8 中,我们对 decoder-only Qwen3.5-27B 模型报告了同一组 benchmark,同时使用 BF16 和 FP8 weight-and-activation 配置。
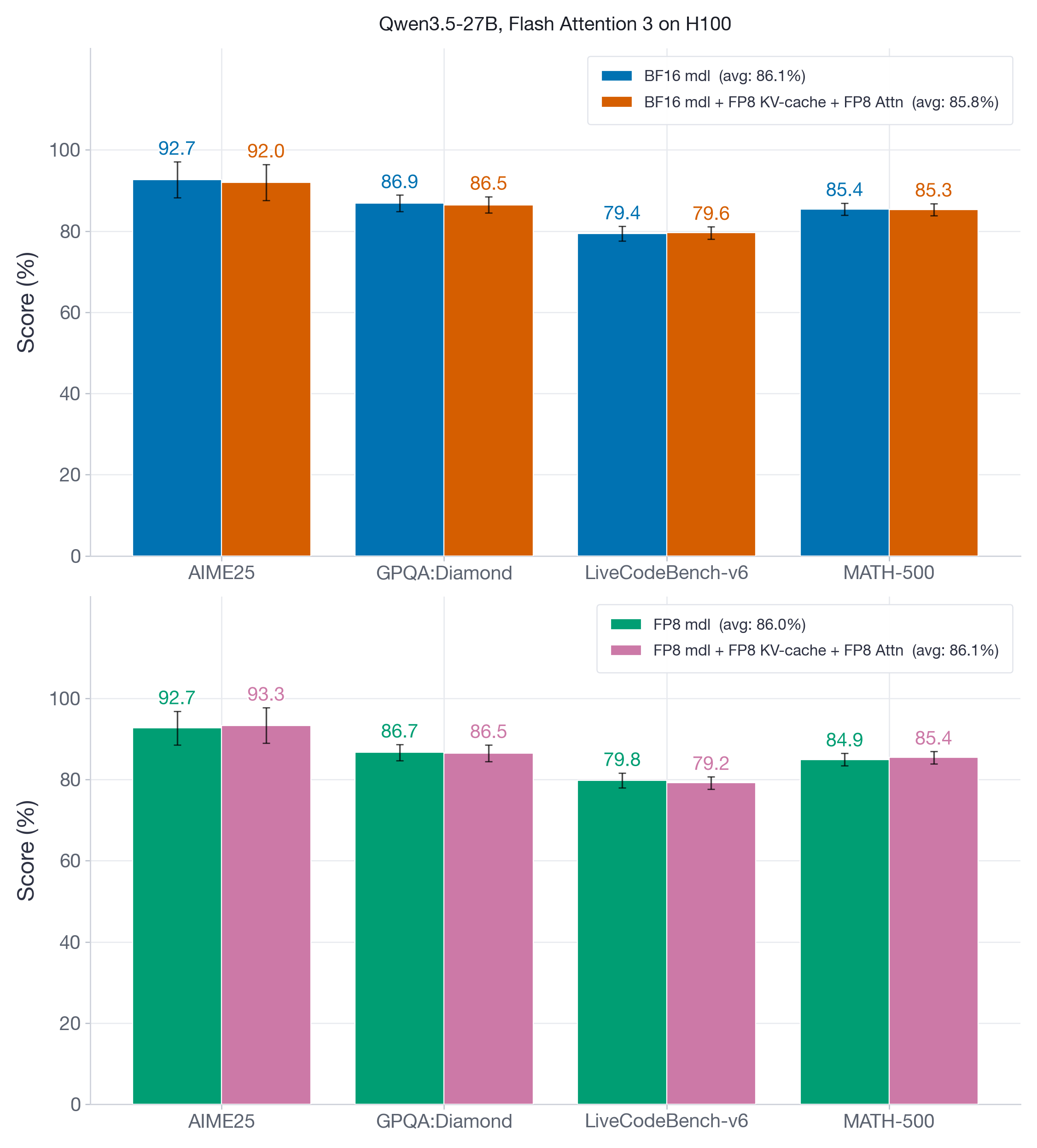
图 8:Qwen3.5-27B 的推理 benchmark。FP8 KV-cache 加 FP8 attention 在这里几乎无损,在 BF16-model 和 FP8-model 两种设置下,聚合分数差异都不到 1 分。
FP8 KV-cache 和 attention quantization 的精度影响可以忽略(最多 0.7 分),在 BF16 model 的 AIME25 上最低 recovery 为 99%。
长上下文评测
我们使用 openai/mrcr 长上下文数据集进行评测,其特点是 heavy prefill(长上下文)后接短 decoding。这用于验证即使 prompt 长达 1M tokens,FP8 KV-cache 和 attention quantization 也能维持模型能力。
图 9 描述了 Llama-3.3-70B-Instruct(未量化 BF16)及其 weight-and-activation FP8 量化变体,在从 8k 到模型最大输入长度 128k 的 sequence-length bucket 上的精度。
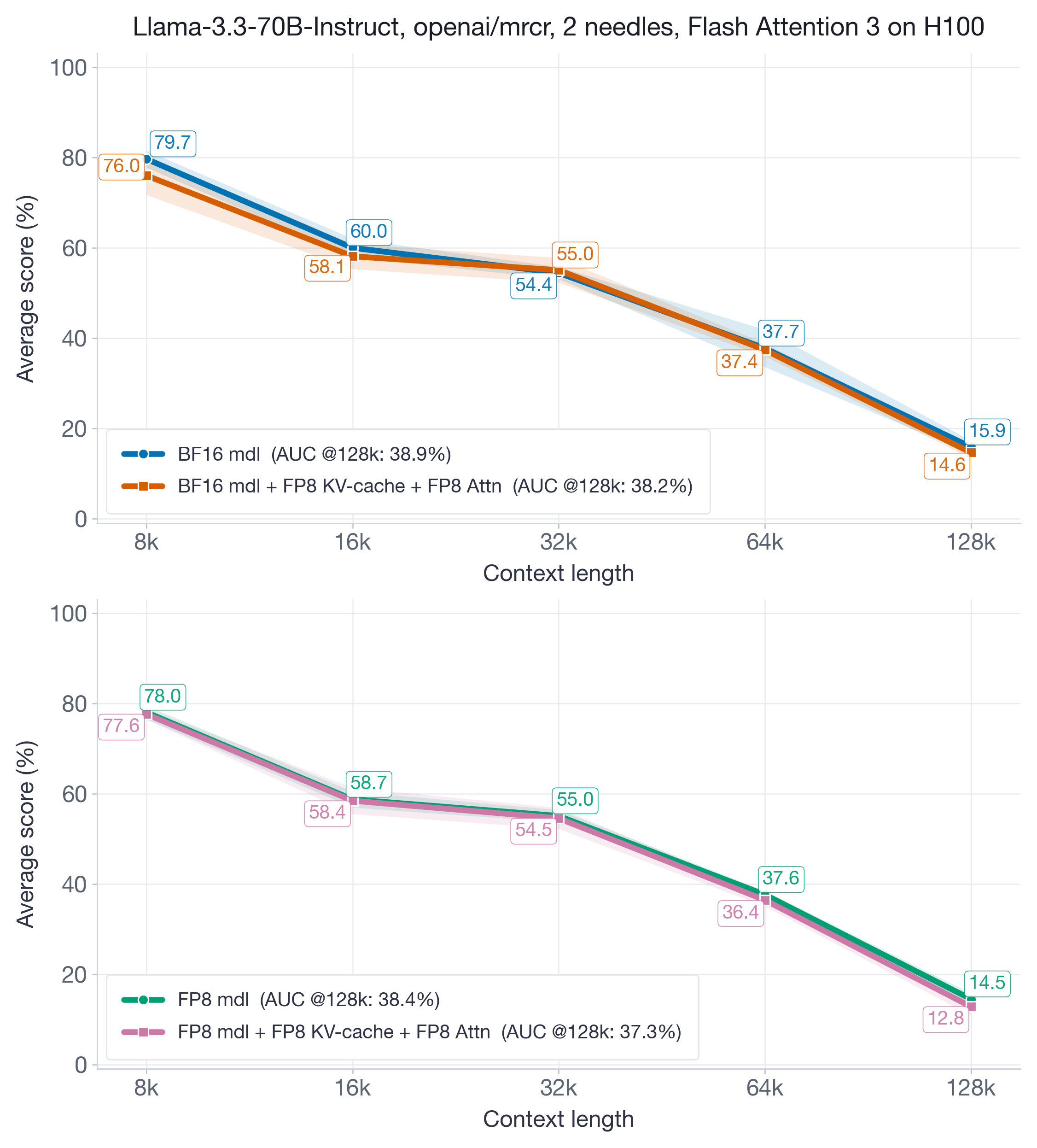
图 9:Llama-3.3-70B-Instruct 到 128k context 的 MRCR 结果。在 BF16-model 和 FP8-model 两种设置下,FP8 KV-cache 加 FP8 attention 曲线都紧贴 baseline,恢复了约 97-98% 的 baseline AUC。
FP8 KV-cache 和 attention quantization 恢复了 baseline AUC@128k 分数的 97-98%。
在图 10 中,我们关注一个 MoE 模型 Qwen3-30B-A3B-Instruct-2507。
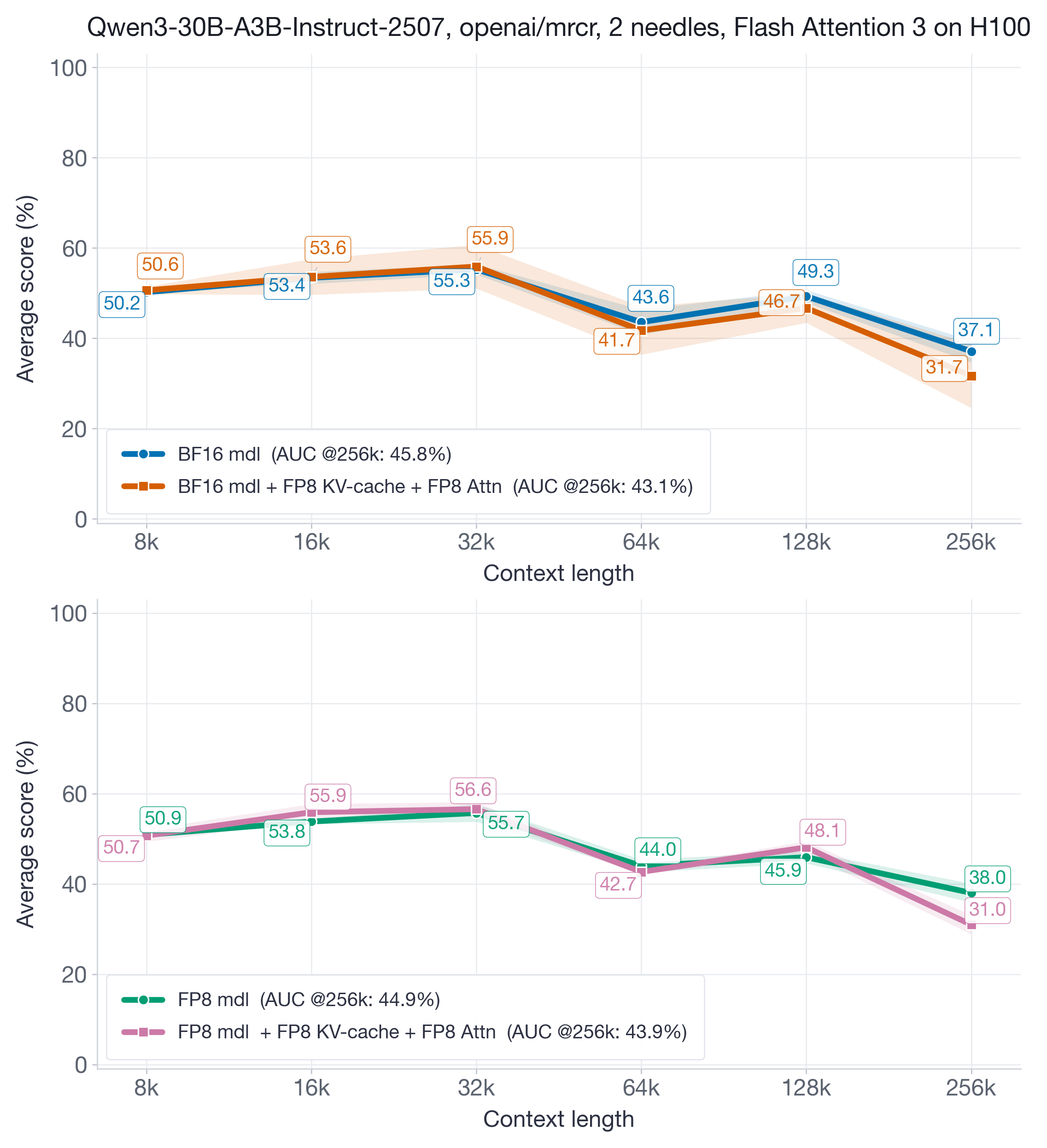
图 10:Qwen3-30B-A3B-Instruct-2507 到 256k context 的 MRCR 结果。FP8 KV-cache 加 FP8 attention 整体仍接近 baseline,但最长 bucket 的差距比 Llama 更明显;AUC recovery 在 BF16-model 设置下约为 94%,在 FP8-model 设置下约为 98%。
尽管所有 bucket 上分数方差更高(如两张图所示),整体 AUC@256k 指标仍接近 baseline,recovery 大约在 94% 到 98% 之间,具体取决于底层模型 weights 和 activations 是 BF16 还是 FP8。方差增大可归因于 baseline 模型本身行为略不稳定(例如 32k 精度 > 8k/16k 精度;128k 精度 > 64k 精度)。
最后,我们关注很新的 Qwen3.5-27B 模型,它支持最高 1M tokens 的输入序列长度,并在所有考虑的序列长度上展现出很有竞争力的精度。
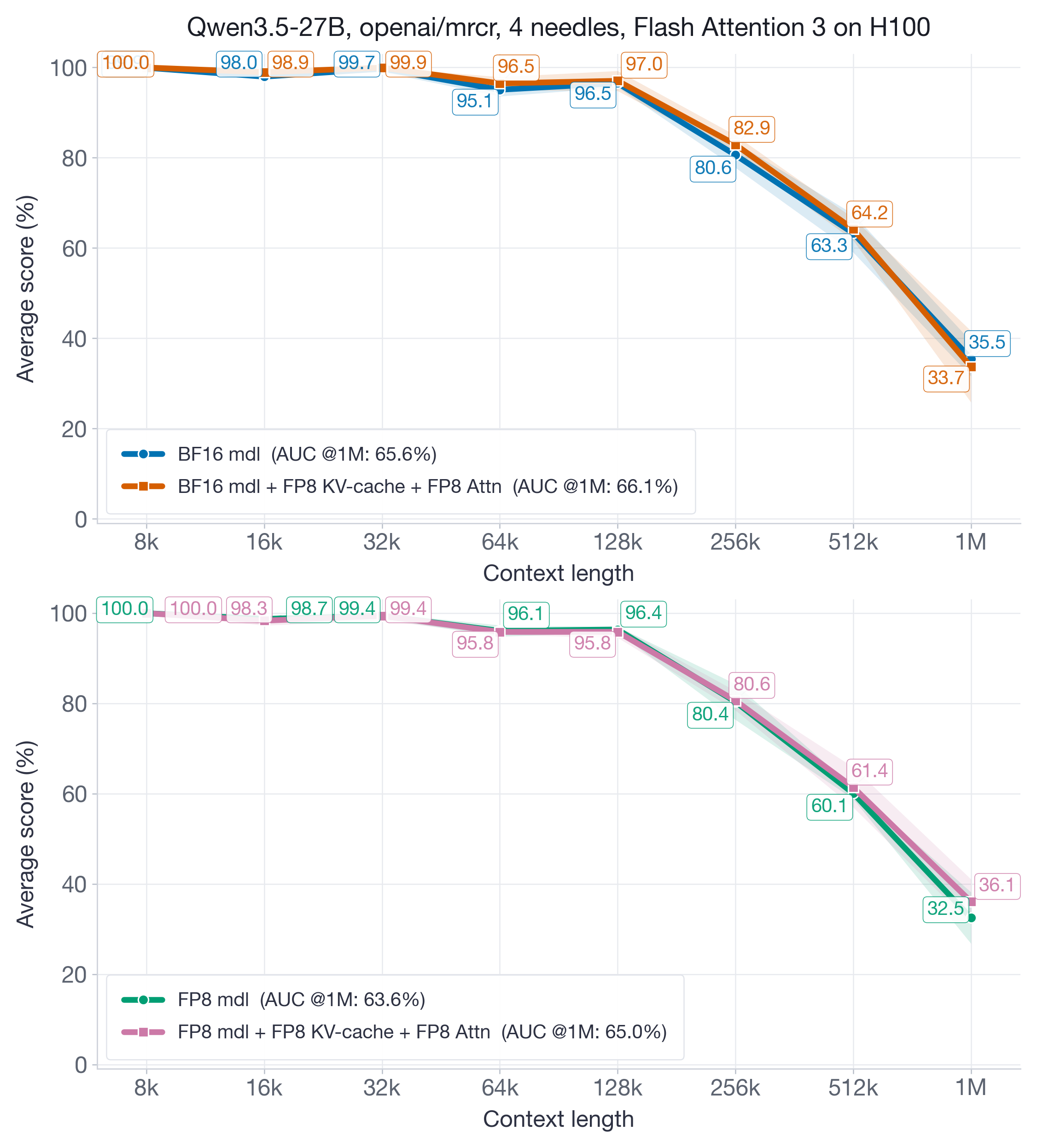
图 11:Qwen3.5-27B 到 1M context 的 MRCR 结果。在两种模型设置下,FP8 KV-cache 加 FP8 attention 都匹配 baseline 的聚合 AUC,尽管最长 context bucket 仍显示出可见方差。
图 11 显示,即使在强 baseline 模型的 1M tokens 极端场景下,FP8 KV-cache 和 attention quantization 也完全恢复了聚合 AUC@1M 指标。
Blackwell (B200) GPU 上使用 FlashInfer 的精度
我们还考察了较新的 Blackwell 架构上的 FP8 KV-cache 和 attention quantization。与 Hopper 不同,后者需要 two-stage accumulation 等干预来解决 Flash Attention kernel 的精度问题;Blackwell 使用默认 FlashInfer kernel,消除了这些精度问题。我们复现了完全相同的 Hopper 实验:Qwen3-30B-A3B-Instruct-2507(BF16/FP8)在 openai/mrcr 长上下文 benchmark 上,以及 Qwen3-30B-A3B-Thinking-2507(BF16/FP8)在推理 benchmark 上。结果见图 12 和图 13。
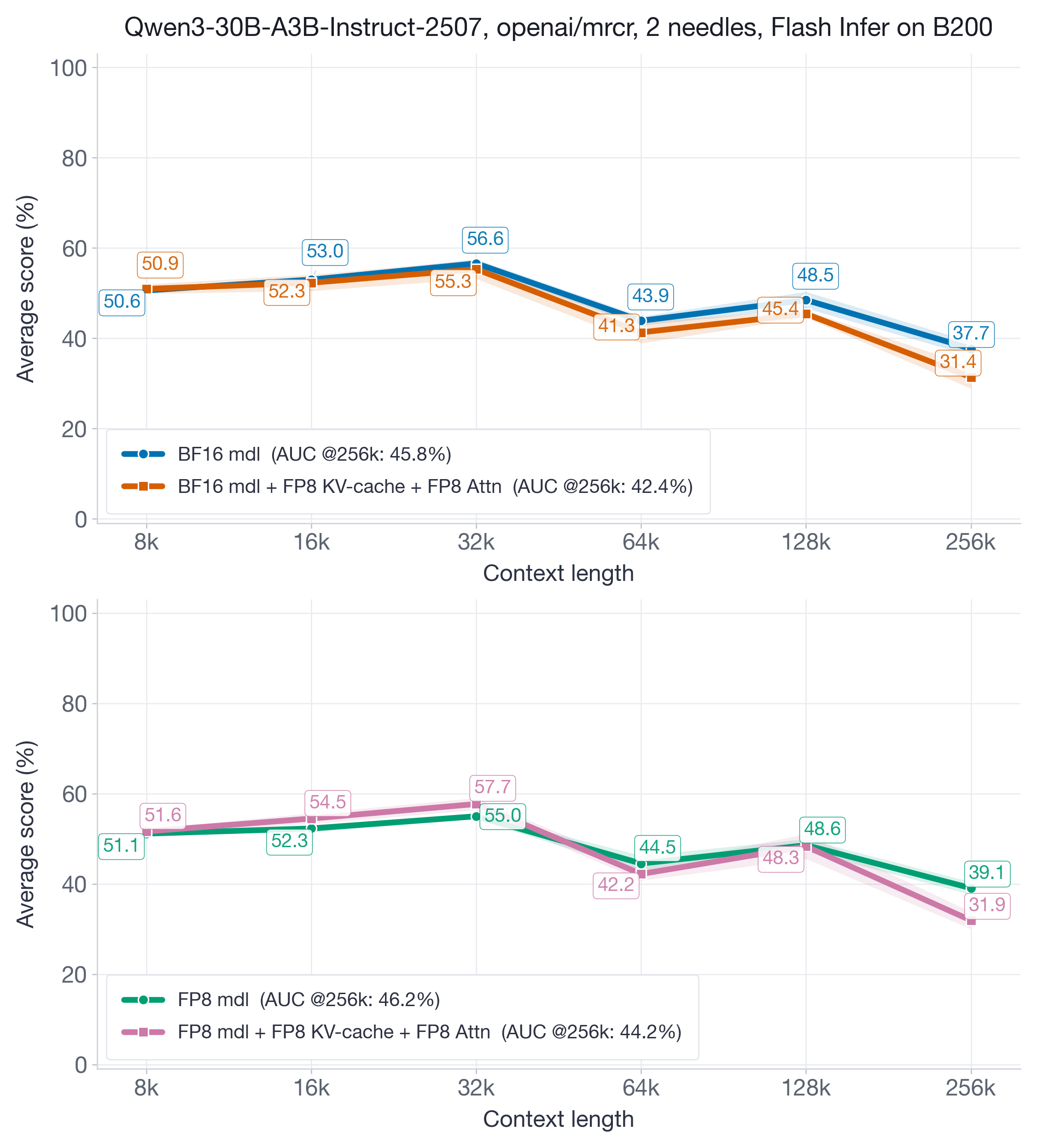
图 12:使用 FlashInfer 的 Qwen3-30B-A3B-Instruct-2507 MRCR 结果。FP8 KV-cache 加 FP8 attention 相对 baseline 仍有竞争力:AUC recovery 在 BF16-model 设置下约为 93%,在 FP8-model 设置下约为 96%。
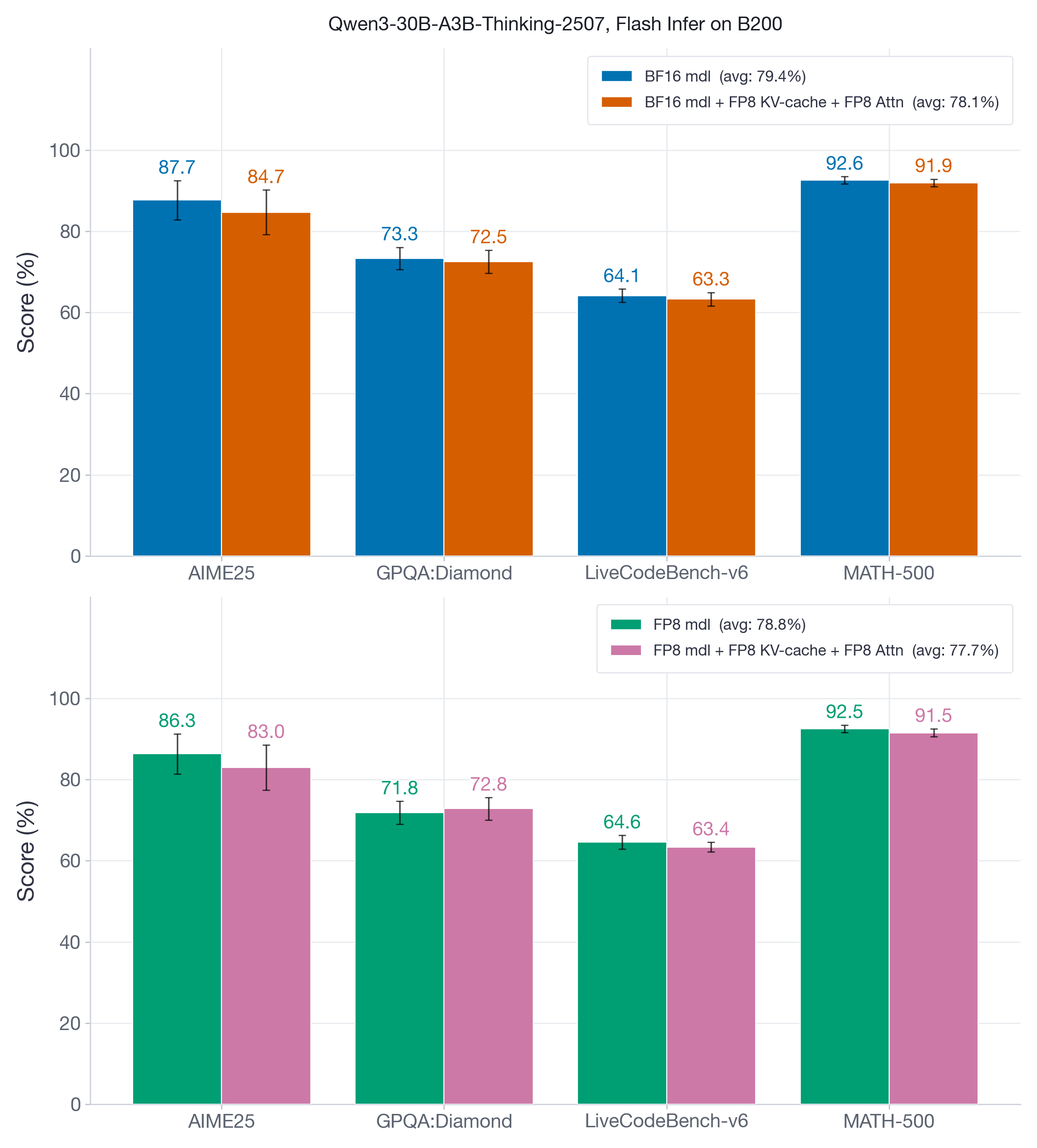
图 13:使用 FlashInfer 的 Qwen3-30B-A3B-Thinking-2507 推理 benchmark。FP8 KV-cache 加 FP8 attention 配置保持接近 baseline,在两种模型设置下平均差异约为 1 分或更少。
在带 FlashInfer backend 的 B200 GPU 上,FP8 KV-cache 加 FP8 attention 在保持精度竞争力的同时,仍保留同样的核心系统收益:更小得多的 KV cache 和更低的 decode 成本。在我们的结果中,精度匹配仍然较强,尽管并非像最佳 Hopper/FA3 案例那样始终紧密。
总结
我们的主要结论是,对于许多长上下文 vLLM 部署和硬件环境,FP8 KV-cache quantization 现在已经可以作为默认起点。如果你的工作负载是 decode-heavy 且 memory-bound,FP8 能在精度损失很小或可忽略的情况下带来有意义的延迟和容量收益。主要例外包括:head_dim = 256 上 prefill 占主导的工作负载;小 sliding-window layer 应保留为 BF16 的 hybrid 模型;以及出现持续 uncalibrated 精度损失的模型或 backend,在这些场景中 calibration 仍然重要。
虽然本文主要关注最简单的(uncalibrated scale)配置,但我们也实现了两个额外功能,以便在小众部署中获得更好的精度恢复:1)通过 vllm-project/LLM-Compressor,使用用户提供的数据集启用 scale calibration;2)支持更细粒度的 per-attention-head quantization scales。 详细示例请参阅 vLLM examples。
什么时候应该使用 Calibration?
并非所有模型都能很好地配合 uncalibrated FP8 scales。为说明这一点,我们测试了 Kimi-K2.5 模型——它使用 Flash MLA attention backend,与上述模型不同,是另一条 kernel 路径——在 H200 GPU 上使用 uncalibrated FP8 KV-cache quantization 的表现。
图 14 显示在各个 sequence-length bucket 上都有一致的下移。虽然聚合 AUC 下降幅度不大,且 standard error bands 有重叠,但这种退化是系统性的,而非随机的。实践结论:从 uncalibrated FP8 开始,因为它简单且通常足够好;但如果你在真实工作负载上观察到这种持续下移,而不是个别 noisy bucket,就应该进行 calibration。这对于使用非标准 attention backend(例如 FlashMLA)的模型尤其相关,因为其 FP8 kernel 行为可能不同于验证较充分的 FA3 和 FlashInfer 路径。
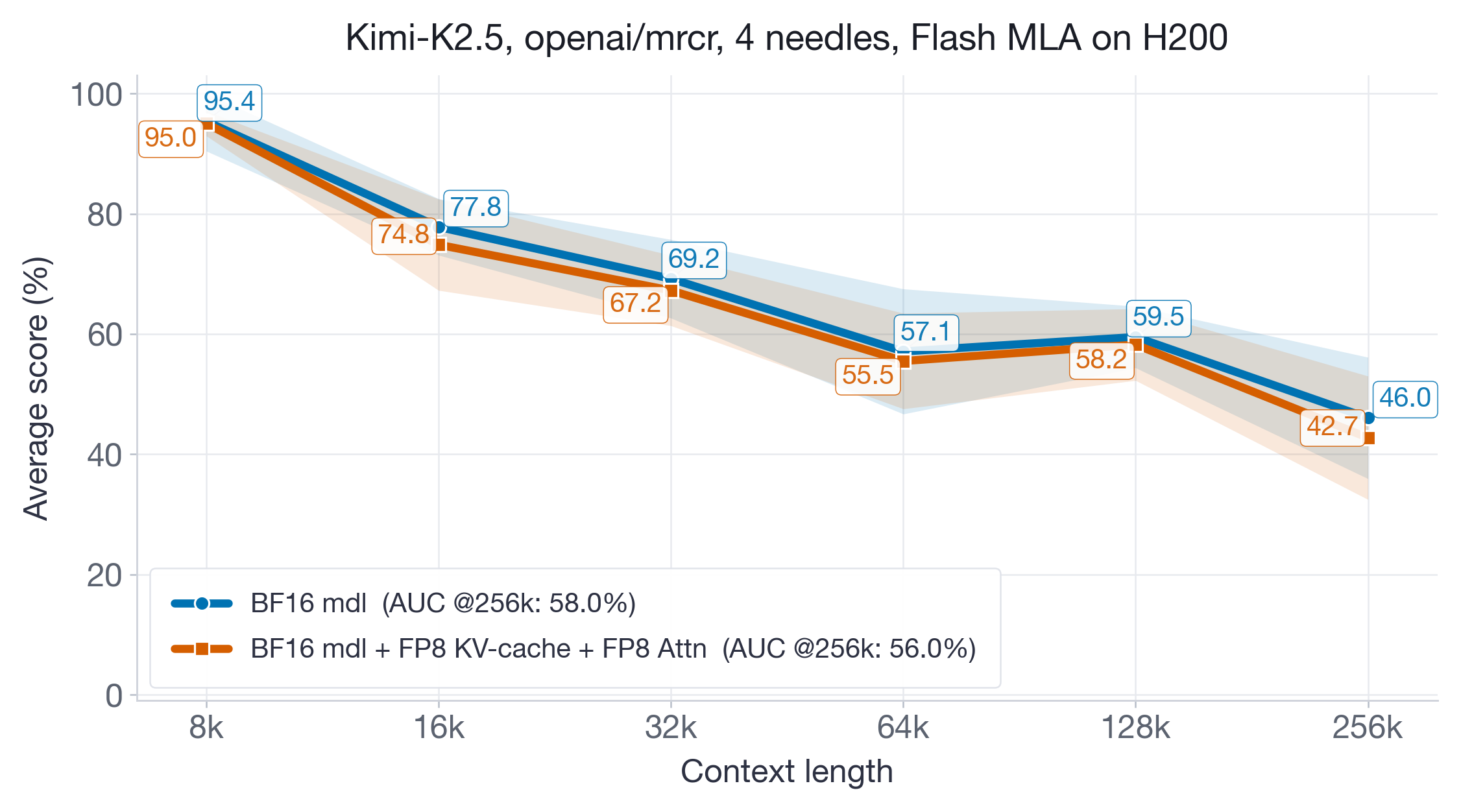
图 14:Kimi-K2.5 使用 FlashMLA 与 uncalibrated FP8 KV-cache 加 FP8 attention 的 MRCR 结果。聚合 AUC 的下降幅度不大,但在各上下文长度上都一致为负,因此这是一个值得进行 calibration 的典型例子。
什么时候应避免使用 FP8 KV-Cache
FP8 KV-cache quantization 并不总是正确选择。若符合以下情况,请考虑继续使用 BF16:
- 你的上下文较短(< ~7k tokens): FP8 有较小的常数开销(intercept gap),因此在短上下文下,BF16 的 ITL 可能略快。
- 你的模型使用
head_dim = 256且 prefill latency 很重要: two-level accumulation 开销会使长上下文下 TTFT 增加约 1.6x。禁用 two-level accumulation 可恢复速度,但需要仔细验证精度。 - 你的工作负载上 uncalibrated 精度低于 95%: 一些模型(例如带 FlashMLA 的 Kimi-K2.5)在 uncalibrated scales 下表现出一致退化,可能受益于在目标数据集上的 calibration。
- 你的模型有许多小 sliding-window attention layer: FP8 开销在这些地方可能无法很好摊销;对于 hybrid-attention 模型,优先使用
--kv-cache-dtype-skip-layers sliding_window。
上一篇:vLLM 中面向 Hybrid SSM 模型的 Disaggregated Serving下一篇:vLLM 中的 DeepSeek V4:高效长上下文 Attention
相关文章
GB300 上的 DeepSeek-V3.2:性能突破 2026 年 2 月 13 日·12 分钟阅读 DeepSeek-V3.2 (NVFP4 + TP2) 已成功且顺利地运行在 GB300(SM103 - Blackwell Ultra)上。借助 FP4 quantization,它实现了 7360 TGS(tokens / GPU /...)的单 GPU 吞吐### Model Runner V2:vLLM 更模块化、更快的核心 2026 年 3 月 24 日·8 分钟阅读 我们很高兴宣布 Model Runner V2 (MRV2),这是对 vLLM model runner 的从零重新实现。MRV2 提供了更简洁、更模块化、更高效的执行核心——且没有 API...### P-EAGLE:在 vLLM 中用 Parallel Speculative Decoding 加速 LLM inference 2026 年 3 月 13 日·12 分钟阅读 EAGLE 是大语言模型(LLM)inference 中 speculative decoding 的 SOTA 方法,但其 autoregressive drafting 会产生一个隐藏瓶颈:token 越多,你...
- 引言
- 我们发现的问题
- Kernel 与 vLLM 改进
- 性能 Benchmark
- 单请求 Benchmark
- 负载下的吞吐
- 大 Head Dimension 的限制
- Blackwell (B200) GPU 上使用 FlashInfer 的性能
- 精度 Benchmark
- 推理能力评测
- 长上下文评测
- Blackwell (B200) GPU 上使用 FlashInfer 的精度
- 总结
- 什么时候应该使用 Calibration?
- 什么时候应避免使用 FP8 KV-Cache
目录
© 2026 vLLM·保留所有权利。