vLLM 中混合 SSM 模型的分离式 Serving
Disaggregated Serving for Hybrid SSM Models in vLLM
vLLM 团队与 Red Hat 的 Nicolò Lucchesi、Zhanqiu Hu 扩展 NIXL connector,在 vLLM>=v0.20.0 支持 hybrid SSM-FA 模型分离式 P/D。方法包括双 descriptor 视图、physical/logical block 映射、DS layout 与 3-descriptor conv 传输,并在 8x H200 上测试 Nemotron-H。
vLLM 中 Hybrid SSM 模型的分离式服务 | vLLM Blog
菜单
主题
![]() ](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
vLLM 中 Hybrid SSM 模型的分离式服务
2026 年 4 月 21 日 15 分钟阅读
Nicolò Lucchesi、Zhanqiu Hu(Red Hat)以及 vLLM 团队
- 引言
- 背景:NIXL KV 传输工作流
- 挑战:FA 与 SSM State 存在根本差异
- HMA 共享 Tensor 布局
- 双 Descriptor 视图
- Physical 与 Logical Block Size
- 3-Descriptor Conv 传输
- DS Layout 方案
- 零开销:无额外 Buffer,无 Permutation
- 组合起来:Nemotron-H 示例
- 性能
- 开始使用
- 限制与未来工作
- 致谢
目录
引言
将 Mamba 风格 SSM 层与标准 full-attention(FA)层交错组合的 hybrid 架构,例如 NVIDIA Nemotron-H,正逐渐受到关注,因为它们能够把 state-space model 的线性时间效率与 attention 的表达能力结合起来。vLLM 已经通过其基于 NIXL 的 KV connector支持标准 transformer 模型的分离式 prefill/decode(P/D):prefill 实例计算 KV cache block,decode 实例通过 RDMA 拉取这些 block,从而避免重复计算。但将这一机制扩展到 hybrid 模型并不直接。FA 层与 SSM 层存储的 state 在本质上不同,layout 和 size 也不同,而 block manager 和 NIXL connector 原本是围绕单一、统一的 KV cache 格式设计的。
本文介绍我们如何扩展 NIXL connector,使其在分离模式下支持 hybrid SSM-FA 模型。核心思路包括:
- 双 descriptor 视图 — 两组 NIXL block descriptor,以不同的 offset 和 size 索引同一批物理内存区域,一组用于 FA block,另一组用于 SSM block。
- Physical/logical block 桥接 — 处理 block manager 所见的 logical block 抽象与 attention kernel 所需 physical block size 之间的不匹配。
- 3-descriptor conv 传输 — 对 Mamba conv state 进行分解,使 heterogeneous tensor-parallel 传输无需在发送端重新排列数据。
这些改动不会改变标准 transformer 模型的现有工作流。它们是纯增量扩展,只在模型包含 SSM 层时启用。该功能在 vllm>=v0.20.0 中可用。
这项工作基于 NIXL 的 HMA interface,涉及多个 PR:
- #36687 — hybrid SSM-FA 模型的双 descriptor 视图与 homogeneous-TP 支持
- #37416 — 面向 Mamba kernel 的 DS conv state layout
- #37635 — Heterogeneous-TP 3-descriptor conv state 传输
- #37310 — Mamba P/D disaggregation 的 N-1 prefill
背景:NIXL KV 传输工作流
在深入 hybrid 模型改动之前,我们先简要回顾标准 transformer 的 NIXL 分离式 P/D 是如何工作的。
该工作流有四个阶段:
- 注册内存区域 — 每个 worker 将其 KV cache tensor 注册到 NIXL,使其可通过 RDMA 访问。
- 创建 block descriptor — 对每个已注册区域,我们创建逐 block 的 descriptor,指定
(address, length, device_id)。这些 descriptor 是传输单元:我们不会移动整个区域,而是传输单个 block。 - 握手 — 当 decode(D)worker 首次需要从 prefill(P)worker 拉取数据时,双方交换 metadata:agent handle、block count、block length 等。每个 P-D 对只执行一次。
- 传输 — scheduler 告诉 D 需要从 P 拉取哪些 block。D 将
block_id -> descriptor_id映射起来,发起 RDMA READ,并轮询完成状态。
对于具有 M 个注册区域和 N 个 block 的标准模型,descriptor list 如下:
+----------------------------------+
| Region 0: desc_0 ... desc_{N-1} |
| Region 1: desc_0 ... desc_{N-1} |
| ... |
| Region M: desc_0 ... desc_{N-1} |
+----------------------------------+
区域 r 中的 block ID b 映射到 descriptor index r * N + b。
hybrid 模型的挑战在于,这种统一方案不再成立:FA 层和 SSM 层需要不同的 descriptor size 和不同的 block count。
挑战:FA 与 SSM State 存在根本差异
在标准 transformer 中,每一层的 KV cache 形状相同:[num_blocks, 2, block_size, num_kv_heads, head_dim](或其 layout 变体)。所有层共享相同的 block size、page size 和 block 数量。
Mamba 层存储的内容完全不同。它们不保存逐 token 的 K/V 对,而是维护一个折叠后的 conv state 和一个 temporal SSM state:
Conv state: (conv_dim, state_len) e.g. (3072, 3) -- bf16
SSM state: (num_heads, head_dim, state_size) e.g. (32, 64, 128) -- fp32
这些 state 中没有“token”的概念——它们是整个 sequence history 的固定大小摘要。这意味着 SSM 的 block_size 实际上是 1:每个 block 都是一个完整的 state snapshot,而不是一组逐 token 向量。请记住:这里的 block 是单个传输单元。
HMA 共享 Tensor 布局
vLLM 的 Hybrid Memory Allocator(HMA)按类型对层分组:所有 FA 层在一组,所有 SSM 层在另一组,依此类推。然后它在各组之间池化内存,使得每组中相同位置的层共享同一个物理 tensor。这很高效(block 可互换),但也意味着同一个 tensor 会同时被一个 group 视为 FA block,被另一个 group 视为 SSM block。
对于 Nemotron-H 这类模型,最终 layout 如下:
KV Cache Tensor (shared via HMA pooling)
/ \
/ \
Attention (FA) View Mamba View
| |
+-----------------------+ +-----------------------+
| Block 0 | | Block 0 |
| Key | Value | | Conv | SSM |[pad]|
| Block 1 | | Block 1 |
| Key | Value | | Conv | SSM |[pad]|
| ... | | ... |
+-----------------------+ +-----------------------+
page size 不同:FA page 由 block_size * num_kv_heads * head_dim(K/V 还要 *2)决定,而 SSM page 是 conv_state_bytes + ssm_state_bytes。HMA 会增大 FA block_size,直到它大于 Mamba 的 page size,然后对 Mamba 行进行 padding(+[pad]),使两组在字节层面的 page size 相等,从而启用共享 tensor 方案。
NIXL 面临的问题:一个包含统一 (address, length) entry 的 descriptor list 无法正确索引这两种视图。我们需要将 K/V(以及类似的 Conv/SSM)注册到独立的 descriptor 上,以便在 heterogeneous setup(即 D TP != P TP)中索引 K/V 的 head。
block b 的 FA descriptor 指向 base + b * page_size,长度为 fa_block_len。同一个 block b 的 Mamba descriptor 指向相同的 base + b * page_size,但长度为 conv_size 或 ssm_size。两者不同。
双 Descriptor 视图
我们的方案是在同一块物理内存上注册两组独立的 descriptor list,将它们拼接起来,并由单个 NIXL transfer handle 指向:
+------------------------------------------------------+
| FA descriptors (M regions x N_phys blocks) |
| |
| Region 0 |
| FA_desc_K[0], FA_desc_K[1], ... FA_desc_K[N-1] |
| FA_desc_V[0], FA_desc_V[1], ... FA_desc_V[N-1] |
| Region 1 |
| ... |
| Region M |
| ... |
| | ^
| --------------------------------------------------- | | num_descs
| | v
| Mamba descriptors (M regions x N_log blocks) |
| |
| Region 0 |
| Mamba_desc_x[0] ... Mamba_desc_x[N-1] |
| Mamba_desc_B[0] ... Mamba_desc_B[N-1] |
| Mamba_desc_C[0] ... Mamba_desc_C[N-1] |
| Mamba_desc_SSM[0] ... Mamba_desc_SSM[N-1] |
| Region 1 |
| ... |
| Region M |
| ... |
+------------------------------------------------------+
注:这里我们使用
N_phys/_log分别表示 physical block 和 logical block。你可以先假设N_phys=N_log=N,两者不相等的情况见下一节。
注:上面的 Mamba 部分已经体现了 conv-state 分解为 x、B、C 子投影的形式,详见下文 3-Descriptor Conv 传输。对于 homogeneous TP,它们会简化为两个子区域(Conv、SSM)。
FA descriptor 占据前 num_descs = M * N_phys 个 slot。Mamba descriptor 紧随其后。Block ID 映射变为:
if is_fa_group:
desc_id = region_id * N_phys + block_id
else: # mamba group
desc_id = mamba_region_id * N_log + block_id + num_descs
Physical 与 Logical Block Size
第二个复杂点来自 attention kernel 的要求。FlashInfer 等 backend 需要特定的 physical block size(例如 16 个 token),它可能不同于用户设置或 HMA 计算出的 logical block size。
对于标准模型,这通过一个简单的 ratio 处理:
physical_blocks = logical_blocks * ratio
ratio = logical_block_size / kernel_block_size
对于 hybrid 模型,这个 ratio 只适用于 FA 层。SSM 层没有可拆分的“token”维度,因此始终直接使用 logical_blocks。这意味着 descriptor list 中 FA 部分和 Mamba 部分使用不同的 block count:
FA section: M regions * N_phys blocks (N_phys = N_logical * ratio)
Mamba section: M regions * N_logical blocks
这通过 _physical_blocks_per_logical 字段跟踪,该字段按 engine 计算(因为当 P 和 D 的 TP size 不同时,它们的 ratio 可能不同)。_get_block_descs_ids 中的 block-ID-to-descriptor-ID 映射会根据当前解析的是 FA group 还是 Mamba group,使用对应的 stride。
3-Descriptor Conv 传输
对于 homogeneous TP(P 和 D 使用相同的 --tensor-parallel-size),传输 SSM state 很直接:每个 D rank 从匹配的 P rank 读取对应的 conv + SSM block。
Heterogeneous TP 会让事情更复杂。以 P_TP=1, D_TP=4 为例:四个 D worker 都必须从单个 P worker 读取各自的 conv 和 SSM state shard。SSM temporal state 沿 heads 维度分片,而这是第一个轴,因此切片很简单。但 conv state 的结构如下:
Conv state = [x | B | C] where x, B, C are sub-projections
^ ^ ^
| | |
intermediate_size / TP groups_ss / TP groups_ss / TP
在标准 SD layout (state_len, dim) 中,这些子投影在内存中是交错的。一个只想读取自己那部分 x 的 D worker 需要收集非连续字节——这对于 zero-copy RDMA 并不现实。
DS Layout 方案
我们要求 conv state 使用 DS layout(dim, state_len)(通过 VLLM_SSM_CONV_STATE_LAYOUT=DS 设置)。在这种 layout 中,每个子投影的数据在内存中都是连续的:
DS layout within one page:
|--- x (x_bytes) ---|--- B (b_bytes) ---|--- C (b_bytes) ---|--- SSM ---|
现在,每个 D rank 可以通过三次独立且连续的 RDMA read 读取自己的 x、B 和 C slice——因此称为“3-descriptor transfer”(我们仍然只发起一次 NIXL READ)。
对于 heterogeneous TP,remote_conv_offsets 方法会计算每个 D rank 的 slice 在 P page 中的位置,并考虑 TP ratio。这使每个 Mamba layer 拥有 4 个 descriptor region(x、B、C、SSM),而不是 homogeneous 情况下的 2 个 region(Conv、SSM)。代价是 descriptor list 更大,但 RDMA 传输本身仍然是高效的连续 read。
任何一侧 GPU 都不会分配额外的内存 staging buffer。任何一侧也都不需要数据 reshuffling。
注:在常规 colocated setup 中使用 DS layout 时,我们没有观察到明显的 kernel 性能退化。未来版本中,我们可能会将标准 layout 始终更新为 DS。
零开销:无额外 Buffer,无 Permutation
一个更简单的替代方案是把完整 conv state 传输到每个 D rank,然后在本地 permute/slice 成正确形状。但对于 Mamba,我们有意避免这种做法:
- 无 staging buffer — 在 D 端进行 permute 需要在每个 D worker 上分配一个大小等于 P 完整 conv state 的临时 buffer。对于 Nemotron-H 这类模型,每个 block 的 conv state 已经不小(bf16 下为
3 * 3072 * 2 bytes)。再乘以数千个 block 和所有 Mamba layer,这部分开销会累积,并占用本可用于 KV cache 的空间。 - 无传输后 reshuffling — 借助 DS layout,每个 D rank 只读取自己需要的字节,并直接写入 KV cache 中的最终目的位置。无需在传输后运行 kernel 来重新排列数据。传输完成后,state 可立即使用。
- 只传输自己拥有的部分 — 每个 D rank 只传输 conv state 中自己的
1/TP份额,而不是完整 state。对于D_TP=4,与“全部传输,然后本地切片”的方案相比,每个 rank 的数据量减少 4 倍。 - 跳过 HMA padding — 前面提到,HMA 会对 SSM page 进行 padding,使其与 FA page size 匹配。Mamba descriptor 的 size 是实际的
conv_bytes + ssm_bytes,而不是 padded page size。这意味着我们不会通过网络传输 padding 字节——只传输真实 state。对于 padding 很大的模型(例如 FA page size 远大于原始 SSM state 的情况),这可以显著减少每个 block 的传输量。
下图验证了 Nemotron Super 120B 在 TP=4(FA block_size=4224,由 HMA 设置)下的零开销传输优化。对于每种 KV cache dtype(bf16 和 fp8),我们将 Naive baseline(为 Mamba block 传输完整 HMA-padded page)与 Optimal 方法(只传输实际 conv + SSM 字节,跳过所有 HMA padding 和/或辅助 buffer)进行比较。我们首先验证,从传输指标看,我们的方法与 Optimal 一致。
对于 fp8,FA page size 较小(每个 element 1 字节,而不是 2 字节),因此在该配置下 padding 可以忽略。随后我们展示 bf16 setup 下的节省效果,我们的方法每个 request 消除了约 50 MB 的不必要传输。
由于 Mamba state 是每个 request 固定大小的摘要,随着 ISL 增加,传输大小会随 FA block 数量扩展。
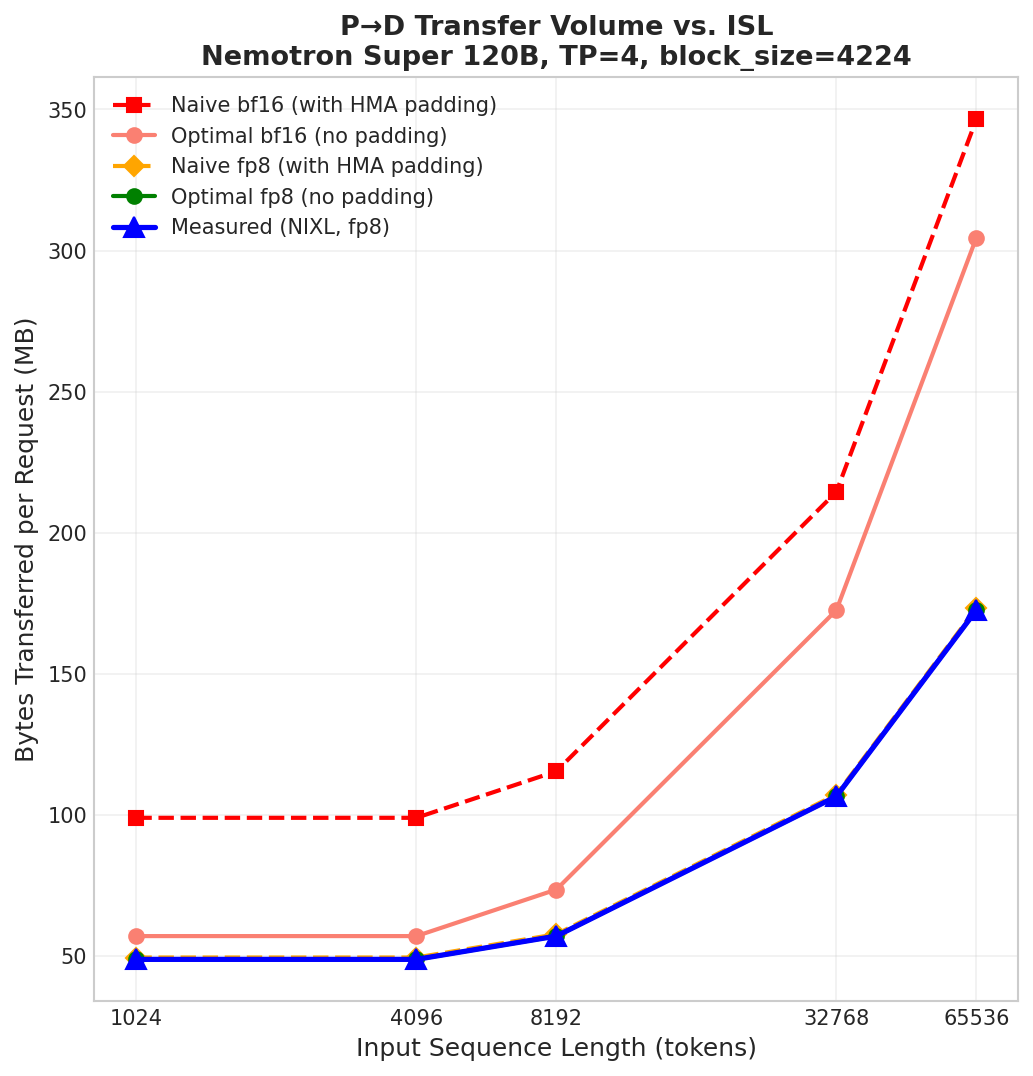
图 1:Nemotron Super 120B(TP=4,FA block_size=4224)中 P→D 传输量随 input sequence length 的变化。Naive 和 Optimal baseline 根据模型的 page size 和 block count 解析计算得到。Measured 线报告分离式 P/D 服务期间实际传输的字节数(由 NIXL 报告)。我们的方法(Optimal)消除了 HMA padding 开销,这反映在实测传输量中。
组合起来:Nemotron-H 示例
下面通过一个具体示例说明:以 TP=2 的分离式 P/D 服务运行 nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8。
模型结构:共 52 层,在 Mamba 与 FA 之间交替。HMA 将它们分为 5 个 group(4 个 Mamba,1 个 FA)。经过内存池化后,得到 6 个共享 KV cache tensor。
KV cache layout:
FA layers: [num_blocks, 2, block_size=400, 4, 128] # K/V with HMA-inflated block_size
SSM layers: [num_blocks, 3, 3072] (conv) + [num_blocks, 48, 64, 128] (ssm)
HMA 会对 block size 进行 padding,使两种视图在字节层面具有相同的 page size。kernel(FlashInfer/FlashAttention)可能进一步细分 FA block,从而产生 physical/logical ratio。
Descriptor 注册:
- 将 6 个共享 tensor 注册为 NIXL memory region(与 dense model 相同)。
- 为全部 6 个 region x
N_physblock 创建 FA descriptor,并分别索引 K 和 V。 - 追加 Mamba descriptor:6 个 region x
N_logicalblock,每个 block 带 4 个子区域(x、B、C、SSM),用于 3-descriptor transfer。
传输流程:
- P 完成 prefill。scheduler 按 group 分配 block ID:
[[fa_block_ids], [mamba_block_ids_g0], [mamba_block_ids_g1], ...]。 - D 接收 block ID,并将其映射到 descriptor index:FA block 使用标准的
region * N + block_id公式;Mamba block 加上num_descsoffset,并使用N_logicalstride。 - D 使用 FA 与 Mamba descriptor 发起单个
make_prepped_xferREAD,然后轮询完成状态。 - 完成后,D 通知 P,使其可以释放 block。
从 D 的视角看,整个传输是一个单一 async 操作。没有中间 buffer,也没有数据 reshuffling。
性能
我们在通过 NVLink 连接的 8x H200 GPU 上,对分离式 P/D 与 colocated serving 进行 benchmark。模型是 nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-FP8,这是一个较新的 120B LatentMoE hybrid 架构,交错包含 Mamba2 层和 full-attention 层。
- Colocated baseline:单实例,TP=8,使用全部 8 个 GPU。
- 分离式 P/D:1 个 prefill 实例(TP=4,4 个 GPU)+ 1 个 decode 实例(TP=4,4 个 GPU),总 GPU 数相同。
我们将 concurrency 从 8 到 256 个并发用户进行 sweep,并绘制每 GPU output throughput 与每用户 output token rate(Interactivity)之间的关系。workload 使用 ShareGPT 作为测试数据集。
所有 run 都使用很高的 warmup 值,以确保 KV cache 被“打散”,从而避免 request block 恰好连续分配时带来的初始性能 boost。这能更准确地反映常规长时间运行情况。也可以通过检查 metrics 中报告的 descriptor 数量保持恒定来验证这一点(覆盖完整数据集 sweep)。
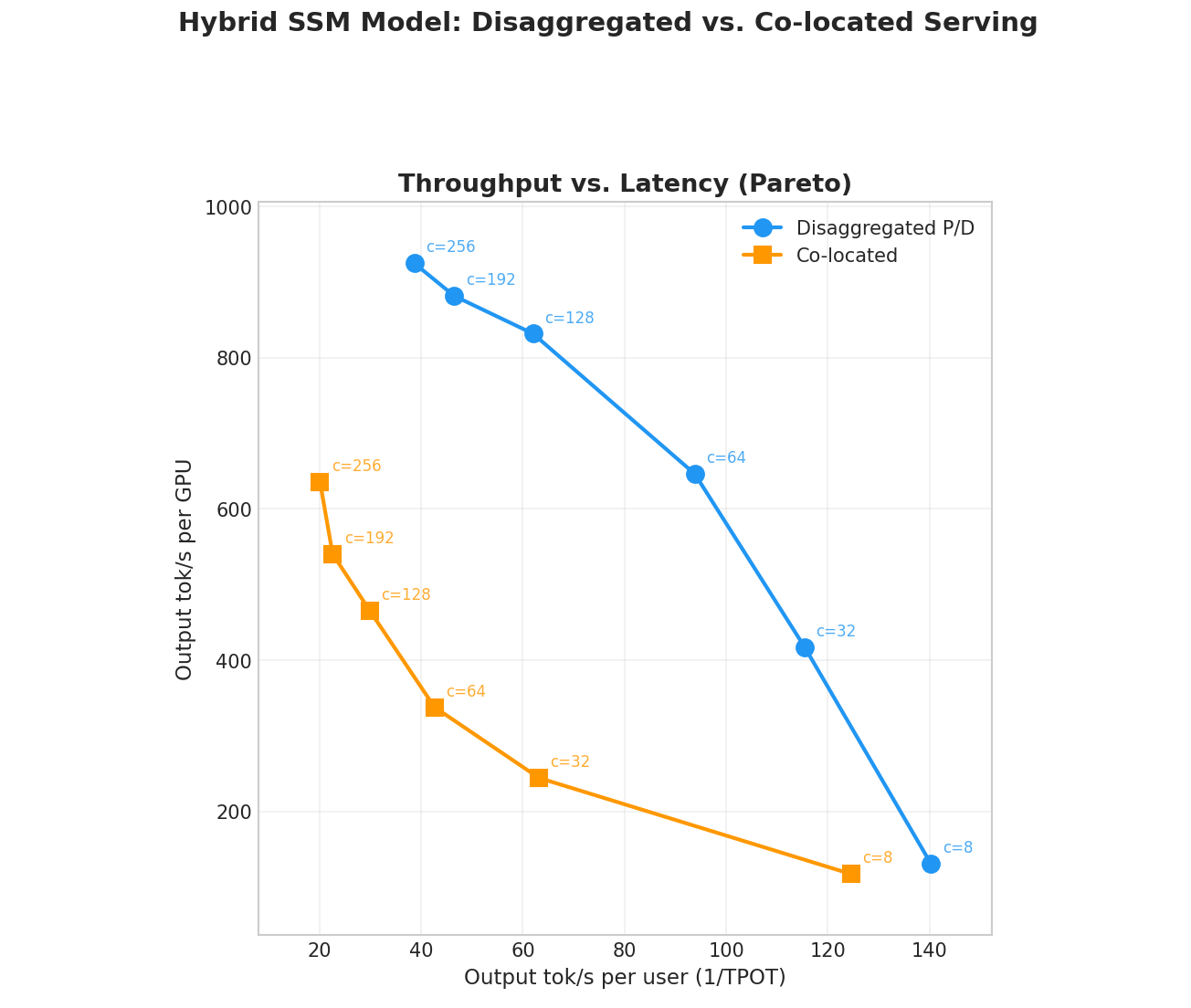
图 2:hybrid SSM 模型的分离式 P/D 与 colocated serving 对比。不同 concurrency level 下的 throughput-vs-latency Pareto 曲线。Prefix-caching 已禁用。
结果显示了与标准 transformer 模型分离式服务中观察到的相同模式:在更高 batch size 下,分离式 P/D 在 Pareto 意义上优于 colocated baseline。通过将 decode 与 prefill 干扰隔离开,decode 实例可以维持更大的 batch 而不发生 stall,从而在高 concurrency 下获得显著更高的每 GPU output tok/s。
开始使用
要使用分离式 P/D 运行 hybrid SSM 模型:
# Prefill instance
VLLM_SSM_CONV_STATE_LAYOUT=DS vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.85 \
--trust-remote-code \
--max-model-len 8192 \
--block-size 128 \
--no-disable-hybrid-kv-cache-manager \
--kv-transfer-config '{"kv_connector":"NixlConnector","kv_role":"kv_both"}'
注:通过
VLLM_SSM_CONV_STATE_LAYOUT=DS设置 DS conv state layout 是 heterogeneous TP 所必需的,但其他情况下并非必需。
限制与未来工作
- Mamba1 模型:3-descriptor conv transfer 目前仅支持 Mamba2。Mamba1 的 SSM temporal 形状
(intermediate_size // tp, state_size)无法重建intermediate_size,而这是 conv 分解所必需的。类似地,GDN 支持(Qwen3.5+)已列入分离式服务 roadmap - Speculative decoding:SSM state transfer 与 speculative decoding 之间的交互尚未经过充分验证。
- HMA 下的 mixed block size:启用 HMA 时,P 与 D 之间不同的 block size(
block_size_ratio > 1)尚不受支持。
致谢
Thomas Parnell(IBM Research)、Roi Koren(NVIDIA)
上一篇 vLLM Korea Meetup 2026 总结下一篇 vLLM 中 FP8 KV-Cache 与 Attention Quantization 的现状
相关文章
更进一步的推理:为什么你的单节点 vLLM Setup 需要 Prefill-Decode Disaggregation Apr 7, 2026·22 分钟阅读 TL;DR:Prefill 和 decode 会争用同一批 GPU,导致负载下 ITL 飙升。我们展示了如何使用 AMD 的 MORI-IO connector,在单个 8-GPU MI300X 节点上将二者分离——实现 2.5x...### 使用 vLLM 运行高效的 Multimodal Agentic AI:NVIDIA Nemotron 3 Nano Omni Apr 28, 2026·7 分钟阅读 我们很高兴在 vLLM 中支持新发布的 NVIDIA Nemotron 3 Nano Omni 模型。### vLLM 中的 DeepSeek V4:高效 Long-context Attention Apr 24, 2026·17 分钟阅读 从第一性原理出发,解析 DeepSeek V4 的 long-context attention,以及我们如何在 vLLM 中实现它。
- 引言
- 背景:NIXL KV 传输工作流
- 挑战:FA 与 SSM State 存在根本差异
- HMA 共享 Tensor 布局
- 双 Descriptor 视图
- Physical 与 Logical Block Size
- 3-Descriptor Conv 传输
- DS Layout 方案
- 零开销:无额外 Buffer,无 Permutation
- 组合起来:Nemotron-H 示例
- 性能
- 开始使用
- 限制与未来工作
- 致谢
目录
© 2026 vLLM·保留所有权利。