用 vLLM 运行基于 NVIDIA Nemotron 3 Nano Omni 的高效多模态 agentic AI
Run Highly Efficient Multimodal Agentic AI with NVIDIA Nemotron 3 Nano Omni Using vLLM
vLLM 博客介绍对 NVIDIA Nemotron 3 Nano Omni 的支持。该开放多模态模型采用 MoE 与 Hybrid Transformer-Mamba,30B 总参数、3B 激活参数、256K 上下文,支持文本、图像、视频、音频输入和文本输出,可通过 vLLM 0.20.0 以 BF16、FP8、NVFP4 部署,并提供 OpenAI-compatible API 示例。
使用 vLLM 运行高效的 NVIDIA Nemotron 3 Nano Omni 多模态 Agentic AI | vLLM Blog
菜单
主题
![]() ](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
](https://vllm.ai/)[文档](https://docs.vllm.ai/)[博客](https://vllm.ai/blog)[活动](https://vllm.ai/events)[联系](https://vllm.ai/contact)[社区](https://vllm.ai/#community)搜索⌘J[](https://github.com/vllm-project/vllm "GitHub")
使用 vLLM 运行高效的 NVIDIA Nemotron 3 Nano Omni 多模态 Agentic AI
2026 年 4 月 28 日 7 分钟阅读
NVIDIA Nemotron Team
- TL;DR:关于 Nemotron 3 Nano Omni
- 使用 vLLM 运行优化的多模态推理
- 安装 vLLM
- 服务模型
- 面向多模态 Agentic 应用的最高效率与领先精度
- 多文档与视频效率
- 多模态精度
- 开始使用
- 致谢
目录
我们很高兴在 vLLM 上支持新发布的 NVIDIA Nemotron 3 Nano Omni 模型。
Nemotron 3 Nano Omni 是 Nemotron 3 开放模型家族的一部分,是一个高效率、开放的多模态模型,具备领先精度,旨在驱动能够在单一循环中跨视觉、音频和语言进行感知与推理的 sub-agent。
企业 agent 工作流天然是多模态的。Agent 必须理解屏幕、文档、音频、视频和文本,而且往往需要在同一次推理过程中完成。然而,当今大多数 agentic 系统是把视觉、语音和语言的独立模型拼接在一起,这会增加推理跳数,使编排更复杂,并在整个 pipeline 中割裂上下文。
Nemotron 3 Nano Omni 解决了这种割裂带来的两大挑战:
- 模型割裂: 按顺序运行独立的视觉、音频和语言模型,会因重复的推理过程而增加延迟,放大成本和故障模式,并在不同 modality 之间割裂上下文。Nemotron 3 Nano Omni 将其整合为单一的多模态推理循环——一个模型即可同时理解屏幕、文档、音频和视频,从而简化 agent 工作流设计,并显著降低编排开销。
- 效率: 持续感知工作负载——屏幕监控、文档理解、视频分析——需要在规模化场景下持续运行。Nemotron 3 Nano 的 hybrid MoE 架构在每次 forward pass 中仅激活 30B 参数中的 3B,提供高吞吐,并通过 temporal-aware perception 和高效视频采样降低视频推理的计算量,使始终在线的 agent 能够在不产生过高成本的情况下运行。
使用该模型,AI 系统在保持相同交互性的情况下,可比其他开放 omni 模型实现高 9x 的吞吐,从而在不牺牲响应性的前提下降低成本并提升可扩展性。
TL;DR:关于 Nemotron 3 Nano Omni
架构: Mixture of Experts (MoE) 与 Hybrid Transformer-Mamba Architecture
模型大小: 总参数 30B,激活参数 3B
上下文长度: 256K
统一的视觉和音频 encoder 消除了独立感知模型的需求——一个模型即可替代割裂的多模态 stack。3D convolution 层 (Conv3D) 支持高效处理视频中的时空数据。
Modalities:
- 输入:文本、图像、视频、音频
- 输出:文本
效率: 在相同交互性下,实现比其他开放 omni 模型高 9x 的吞吐。Efficient Video Sampling (EVS) 可在相同计算预算下处理更长视频,通过 temporal-aware perception 为视频推理带来更低计算量。支持 FP8 和 NVFP4 quantization,便于灵活部署。
精度: 与最佳开放替代模型相比,多模态智能提升 20%。
Post-training: 通过 NVIDIA NeMo RL 和 NeMo Gym,在文本、图像、音频和视频环境中进行多环境 reinforcement learning,提升指令遵循能力,并更好收敛到正确的多模态答案。
支持的 GPU: NVIDIA B200、H100、H200、A100、L40S、DGX Spark 和 RTX 6000
开始使用:
- 从 Hugging Face 下载模型权重——BF16、FP8、NVFP4
- 使用 cookbook 通过 vLLM 运行推理,也可通过 Brev launchable 运行
- 阅读 technical report 了解更多细节
使用 vLLM 运行优化的多模态推理
Nemotron 3 Nano Omni 支持 BF16、FP8 和 NVFP4 精度,可实现加速推理,并在同一 GPU 上服务更多请求。按照以下说明开始使用。
安装 vLLM
pip install vllm[audio]==0.20.0
服务模型
你可以通过 OpenAI-compatible API 服务 Nemotron 3 Nano Omni。根据你的设置需要,配置 attention backend 和任何必需的环境变量。有关 FP8 和 NVFP4 的详细说明,请参考 cookbooks。
python3 -m vllm.entrypoints.openai.api_server \
--model "nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16" \
--served-model-name nemotron \
--trust-remote-code \
--dtype auto \
--host 0.0.0.0 \
--port 5000 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--media-io-kwargs '{"video":{"num_frames":512,"fps":1}}' \
--video-pruning-rate 0.5 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3
服务器启动并运行后,你可以使用下面的代码片段发送多模态 prompts。
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about GPUs."}
],
temperature=1,
max_tokens=1024,
)
print("Reasoning:", resp.choices[0].message.reasoning,
"\nContent:", resp.choices[0].message.content)
如需更简便地使用 vLLM 进行设置,请参考我们的入门 cookbook,地址在这里,或使用 NVIDIA Brev Launchable。
面向多模态 Agentic 应用的最高效率与领先精度
Nemotron 3 Nano Omni 针对硬件高效推理进行了优化,并可直接集成到 vLLM 等现代 inference stack 中。它支持 FP8 和 NVFP4 quantization、NVIDIA 优化的 kernels,以及高效视频采样,可在不同部署环境中提供准确、低延迟且可预测的推理。
通过将这些优化与基于 3D convolution 的时空处理结合,Nemotron 3 Nano Omni 能以更低计算成本维持高质量的多模态感知,从工作站到 cloud-scale 系统都能提供稳定的精度与响应性。
图 1 中的性能是在固定交互性阈值下评估的:保持每用户 token 速率恒定,同时衡量系统在不降低多文档和视频用例实时用户体验的前提下,能够维持多少总吞吐。这种方法强调在真实部署约束下既不牺牲响应性也不牺牲质量的效率,而不仅仅是峰值并发。
多文档与视频效率
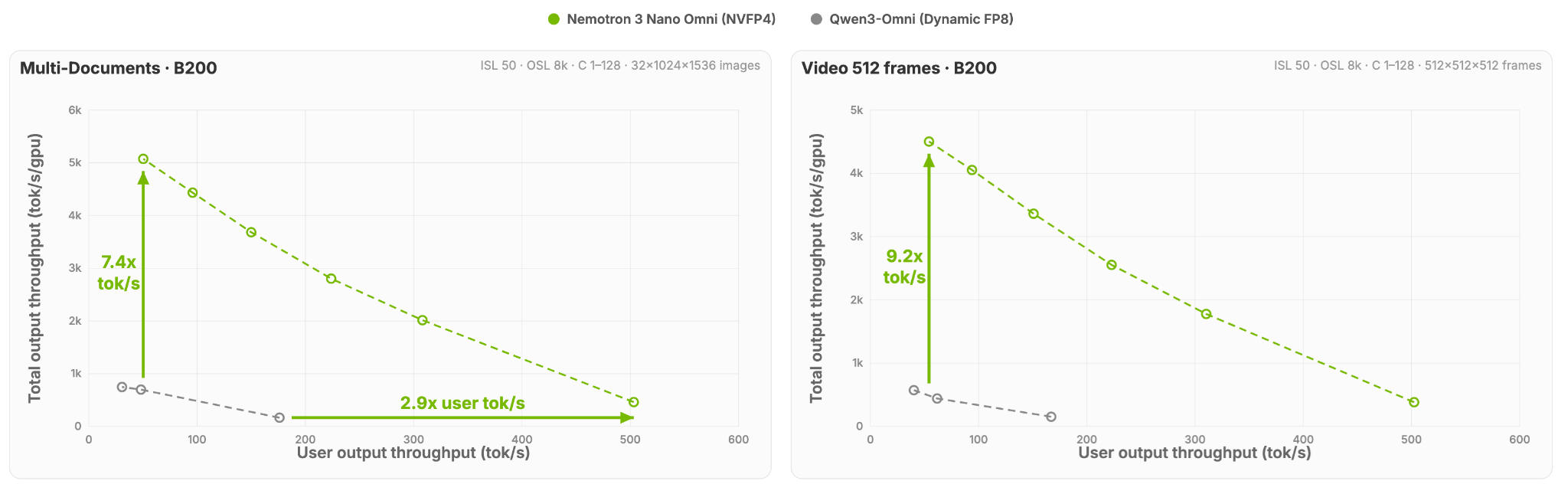
Pareto 曲线展示多文档和视频用例中更高效的系统容量,显示 Nemotron 3 Nano Omni 相比另一个开放 omni 模型分别实现 7.4x 和 9.2x 的更高吞吐。
图 1:在固定每用户交互性阈值(tokens/sec/user)下,各模型可维持的系统总吞吐;显示 Nemotron 3 Nano Omni 相比另一个开放 omni 模型,在多文档和视频用例中分别实现 7.4x 和 9.2x 的更高吞吐。
多模态精度
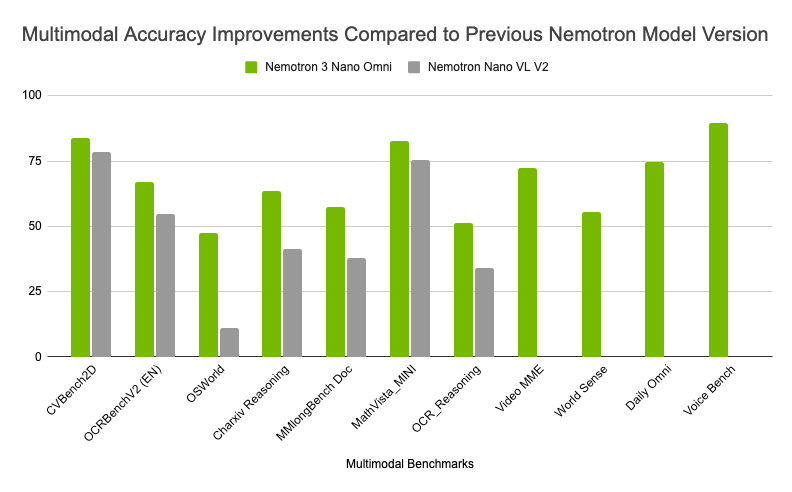
一张图表展示新 Nemotron 3 Nano Omni 模型相对于上一版本 Nemotron Nano VL V2,在多个行业领先 benchmark 上的精度提升,突出其在复杂文档智能、视频和音频推理方面的高性能。
图 2:与上一代 NVIDIA Nemotron Nano VL V2 模型相比,在行业领先 benchmark 上多模态推理精度得到提升,突出其在复杂文档智能、视频和音频推理方面的强劲表现。
如图 2 所示,Nemotron 3 Nano Omni 的模型持续改进,与上一代 NVIDIA Nemotron Nano VL V2 相比,在视觉、视频、OCR 和音频 benchmarks 上提供了更高的多模态精度。这些精度提升与领先效率相结合,使其在六个多模态 leaderboard 上取得领先位置。

一张图片展示 Nemotron 3 Nano Omni 在六个行业领先的多模态效率与精度 leaderboard 中获胜,包括 MMlongbench‑Doc、OCRBenchV2、WorldSense、DailyOmni、VoiceBench 和 MediaPerf。
图 3:Nemotron 3 Nano 在六个多模态效率与精度 leaderboard 中位居榜首。
该模型在 MMlongbench‑Doc 和 OCRBenchV2 等文档智能 benchmarks 上提供 best‑in‑class 性能,同时在 WorldSense、DailyOmni 和 VoiceBench 等视频和音频理解 benchmarks 中也处于领先地位。在 MediaPerf benchmark 上,Nemotron 3 Nano Omni 在所有任务中实现最高吞吐,并在视频级标签任务中取得最低推理成本。
在 agent 系统中,Nemotron 3 Nano Omni 充当多模态感知与上下文 sub-agent,为 agent 提供跨屏幕、文档、音频流和视频的“眼睛”和“耳朵”,同时将结构化理解输入到下游的编排与执行 agent。其轻量架构使其能够与系统中的其他模型高效协同运行,而无需在独立感知 pipeline 中重复计算。它处理 agent 需要看到和听到的一切。
这使 Nemotron 3 Nano Omni 成为驱动 computer use agents、文档智能工作流以及音视频理解 pipeline 的有力选择——同时不需要维护割裂多模态 stack 所带来的开销。
开始使用
NVIDIA Nemotron 3 Nano Omni 是一个高效率的开放多模态模型,能够驱动 sub-agent 更快完成跨视觉、音频和语言的任务。凭借开放权重、数据集和 recipes,你可以获得完整透明度,并具备在自有基础设施上 fine-tune 和部署的灵活性,覆盖从工作站到云端的场景。
准备好大规模运行多模态 AI agents 了吗?
- 从 Hugging Face 下载模型权重——BF16、FP8、NVFP4
- 使用 cookbook 通过 vLLM 运行推理,也可通过 Brev launchable 运行
- 阅读 Nemotron 3 Nano Omni technical report
订阅 NVIDIA news 并在 LinkedIn、X、YouTube 以及 Discord 上的 Nemotron 频道关注 NVIDIA AI,以获取 NVIDIA Nemotron 的最新动态。
致谢
感谢所有为将 Nemotron 3 Nano Omni 引入 vLLM 做出贡献的人。
- NVIDIA: Nirmal Kumar Juluru, Anusha Pant
- vLLM team and community: Roger Wang, Michael Goin, Thomas Parnell, Kevin Luu, Robert Shaw, Tyler Michael Smith
上一篇:vLLM 中的 DeepSeek V4:高效长上下文 Attention
相关文章
vLLM 中的 DeepSeek V4:高效长上下文 Attention 2026 年 4 月 24 日·17 分钟阅读 从第一性原理出发,讲解 DeepSeek V4 的长上下文 attention,以及我们如何在 vLLM 中实现它。### 在 vLLM 上发布 Gemma 4:逐字节来看,能力最强的开放模型 2026 年 4 月 2 日·3 分钟阅读 随着 Gemma 4 首次亮相,vLLM 立即支持 Google 最先进的开放模型系列,覆盖多种硬件 backend,并首次在 Google TPU 上实现 Day 0 支持,...### 使用 vLLM 运行高效且准确的 NVIDIA Nemotron 3 Super Multi-Agent AI 2026 年 3 月 11 日·5 分钟阅读 我们很高兴在 vLLM 上支持新发布的 NVIDIA Nemotron 3 Super 模型。
- TL;DR:关于 Nemotron 3 Nano Omni
- 使用 vLLM 运行优化的多模态推理
- 安装 vLLM
- 服务模型
- 面向多模态 Agentic 应用的最高效率与领先精度
- 多文档与视频效率
- 多模态精度
- 开始使用
- 致谢
目录
© 2026 vLLM·保留所有权利。