TurboQuant 首次全面研究:精度与性能
A First Comprehensive Study of TurboQuant: Accuracy and Performance
一项针对TurboQuant KV-cache量化方法的全面研究,覆盖四个模型(30B至200B+参数,含仅解码器和MoE架构)及五个基准(长上下文检索和推理)。FP8(`--kv-cache-dtype fp8`)提供2倍KV-cache容量,精度损失可忽略,吞吐量匹配BF16。TurboQuant变体(k8v4、4bit-nc、k3v4-nc、3bit-nc)将容量扩展至2.4-3.7倍,但吞吐量降低40-52%,延迟增加10-68%。激进的k3v4-nc和3bit-nc在AIME25等任务上精度下降达20个点。
引言
TurboQuant 是一种 KV-cache 量化方法,因其声称通过对模型 KV-cache 进行极低比特宽度量化可大幅节省 GPU 内存,近期在社区中获得了广泛关注。与 FP8 KV-cache 量化(使用硬件原生 FP8 Tensor Core 操作同时量化 KV-cache 存储和注意力计算本身)不同,TurboQuant 仅将 KV-cache 存储压缩至 3-4 比特,并在注意力计算前将其反量化回 BF16。这一架构差异对精度和性能均有显著影响。
然而,大多数已报告的结果基于在短上下文基准上评估的小模型,这些基准并未对 KV-cache 量化进行压力测试。为了向社区提供更具可操作性的数据,我们进行了一项全面研究,涵盖四个模型(包括仅解码器和 MoE 架构),参数规模从 30B 到 200B+,以及五个基准,包括重 prefill 的长上下文检索和重 decode 的推理工作负载。
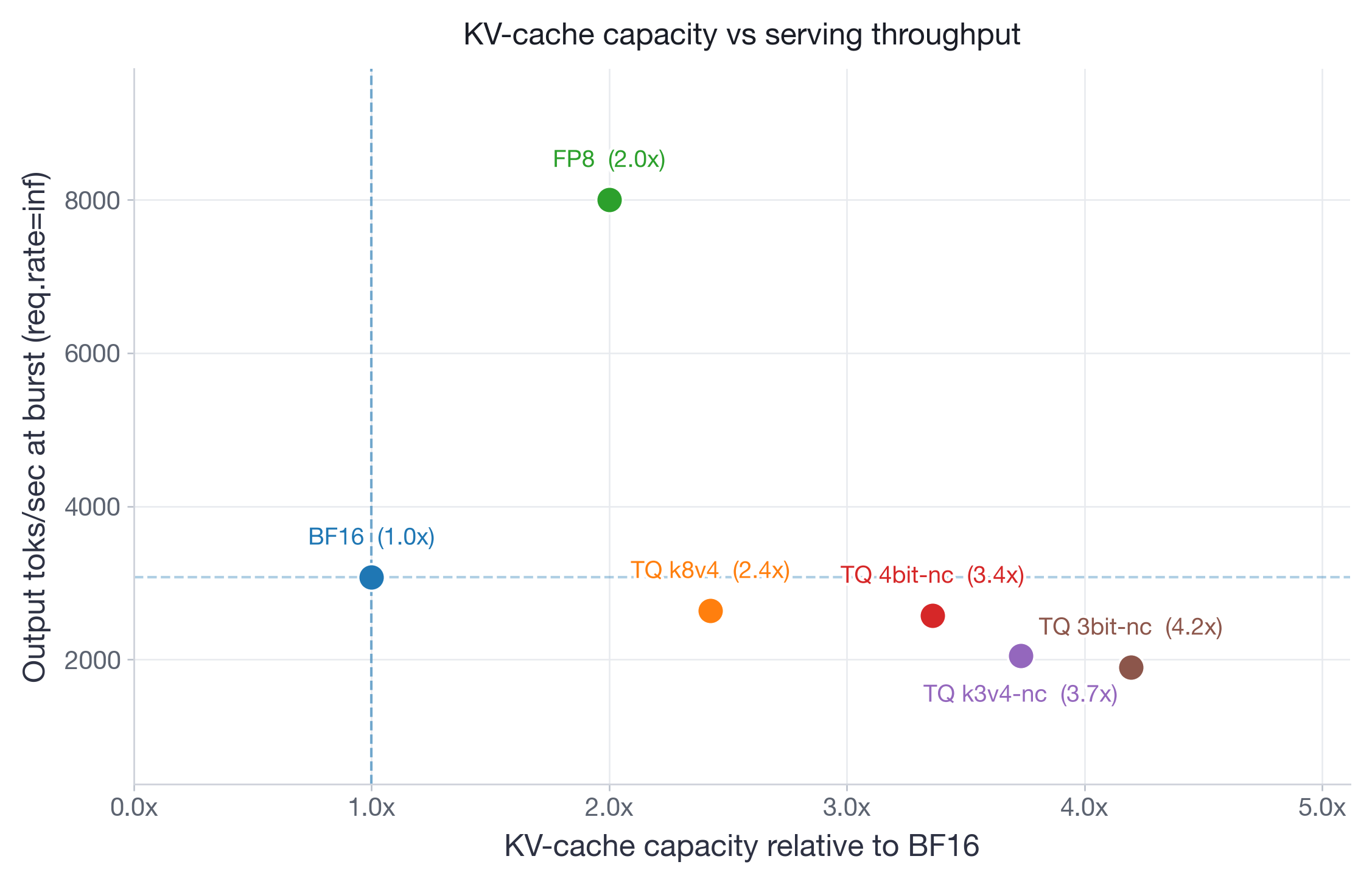
图 1:Llama-3.3-70B-Instruct 在 4xH100 上的帕累托前沿。FP8 占据主导地位,突发吞吐量比 BF16 高 2.6 倍,KV-cache 容量为 2 倍。所有 TurboQuant 变体均以吞吐量换取额外内存节省。
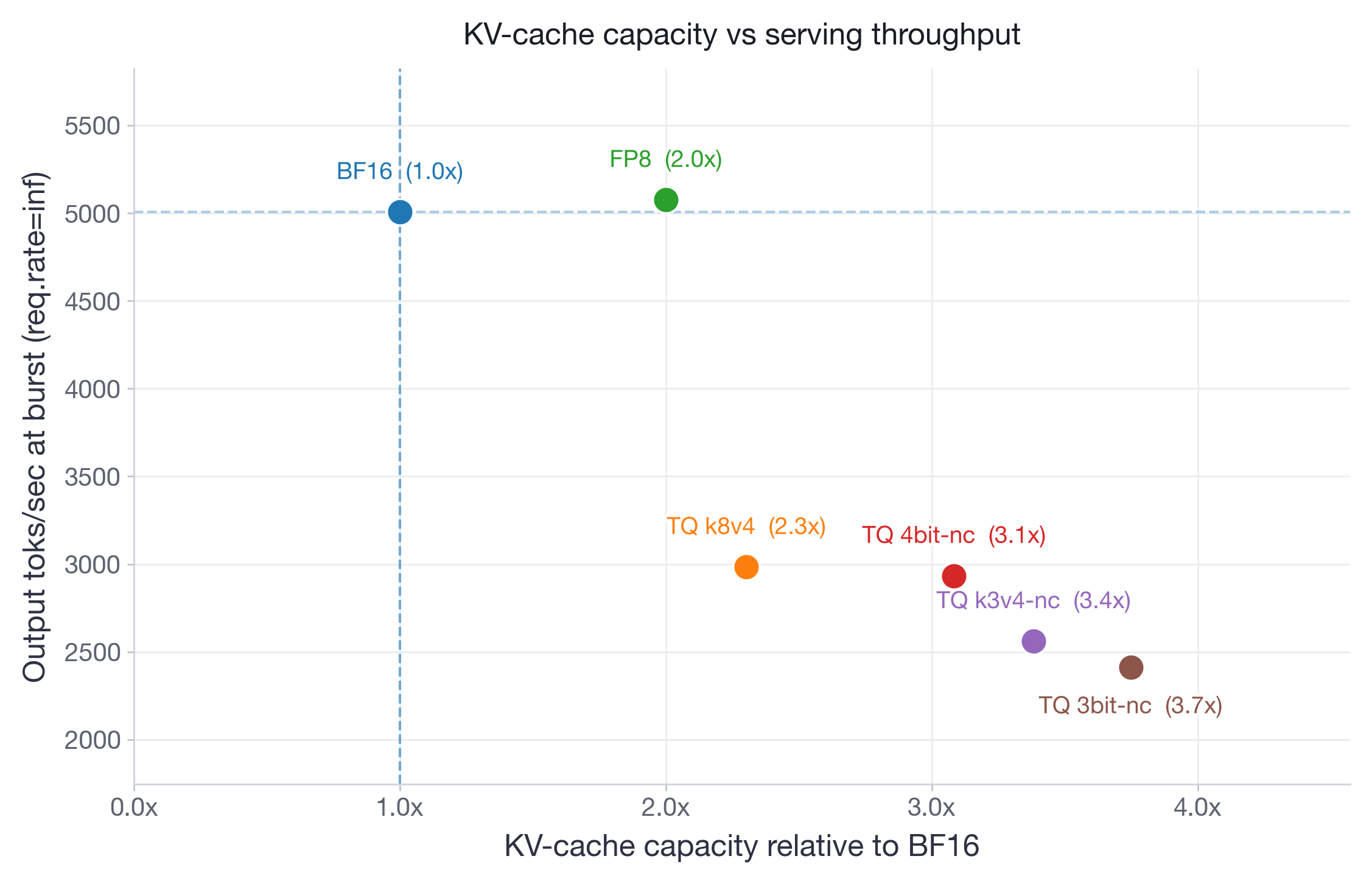
图 2:Qwen3-30B-A3B-Instruct-2507 在 2xH100 上的帕累托前沿。FP8 在 2 倍容量下匹配 BF16 吞吐量。TurboQuant 变体将容量扩展至 2.3-3.7 倍,但吞吐量降低 40-52%。
TL;DR
- 通过
--kv-cache-dtype fp8使用的 FP8 仍然是 KV-cache 量化的最佳默认选择:它提供 2 倍 KV-cache 容量,精度损失可忽略不计,同时在大多数性能指标上与 BF16 持平,并在内存受限的服务场景中显著提升性能。 - TurboQuant
k8v4相比 FP8 没有显著优势:它仅提供适度的 KV-cache 节省(2.4 倍 vs 2 倍),不值得对吞吐量和延迟指标造成持续的负面影响。 - TurboQuant
4bit-nc可能是最实用的 TurboQuant 变体:它在 KV-cache 内存压力下有所帮助,但以额外的容量换取适度的精度、延迟和吞吐量成本。在内存为主要限制的边缘部署中,它可能仍然可行。 - TurboQuant
k3v4-nc和3bit-nc显示出明显的精度下降,尤其是在推理和超长上下文任务上,同时显著降低延迟和吞吐量。这使得它们不适合生产部署。
目录
快速开始:
# 所有层的 FP8 KV-cache
vllm serve MiniMaxAI/MiniMax-M2.7 --kv-cache-dtype fp8
# TurboQuant KV-cache,跳过第一层和最后两层
vllm serve MiniMaxAI/MiniMax-M2.7 --kv-cache-dtype turboquant_4bit_nc
实验设置
量化方案: 我们对四种 TurboQuant 变体(--kv-cache-dtype turboquant_{k8v4, 4bit_nc, k3v4_nc, 3bit_nc})与未量化的 BF16 和 FP8 KV-cache 基线进行基准测试。turboquant_k8v4 使用 8 位键和 4 位值;turboquant_4bit_nc 使用 4 位键和值并带有范数校正;turboquant_k3v4_nc 使用 3 位键和 4 位值并带有范数校正;turboquant_3bit_nc 使用 3 位键和值并带有范数校正。FP8 基线(--kv-cache-dtype fp8)以 FP8 精度存储查询、键和值,并同时量化注意力计算本身——这是与仅压缩存储的 TurboQuant 的关键区别。有关每个 TurboQuant 变体的更多详细信息,请参阅论文和 vLLM 文档。有关 FP8 KV-cache 量化的更多详细信息,请参阅 FP8 KV-cache 博客文章。
基准测试: 我们在五个旨在对 KV-cache 量化进行压力测试的基准上进行评估,涵盖重 prefill 和重 decode 的工作负载。对于长上下文检索(重 prefill),我们使用 openai/mrcr——一个具有挑战性的多轮上下文检索任务,测试序列长度直至每个模型的最大支持长度。对于推理(重 decode),我们使用 AIME25、GPQA:Diamond、MATH500 和 LiveCodeBench-v6。所有评估均采用模型创建者建议的默认非贪婪采样参数,以模拟真实部署。
模型: 我们专注于四个模型,涵盖小规模和大规模,以及仅解码器和 MoE 架构:Llama-3.3-70B-Instruct、Qwen3-30B-A3B-Instruct-2507、Qwen3-30B-A3B-Thinking-2507 和 MiniMax-M2.7。在撰写本文时,TurboQuant 仅支持具有标准注意力机制(例如 GQA)的模型——尚不支持具有滑动窗口或混合注意力的模型。
精度结果
长上下文检索
对于长上下文评估,我们使用 openai/mrcr 任务,测试序列长度直至每个模型的最大支持长度。我们报告每个序列长度桶在 5 次重复中的平均 pass@1 分数,以及所有测试长度的曲线下面积(AUC)作为聚合指标(Context Arena)。
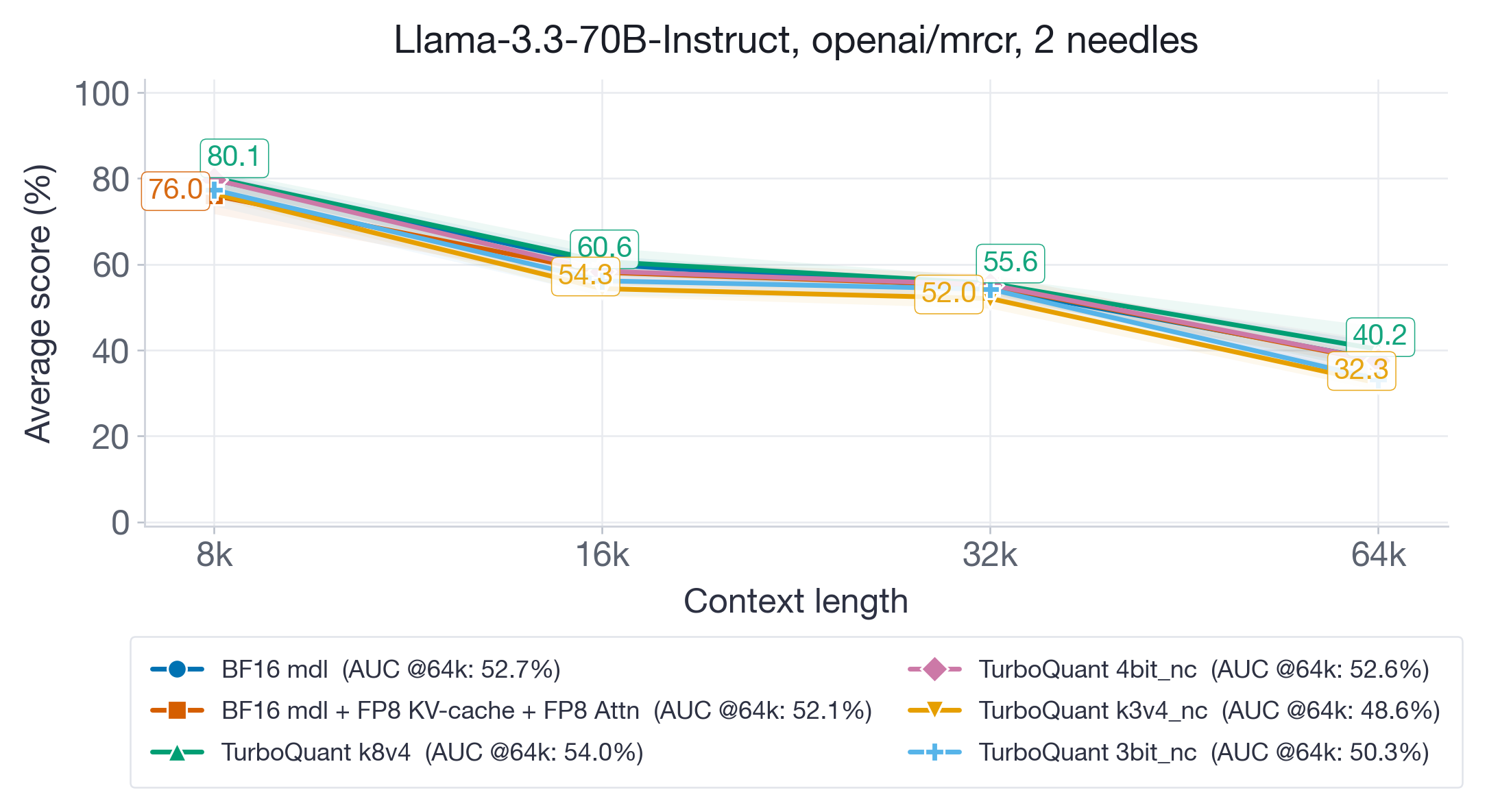
图 3:Llama-3.3-70B-Instruct 在高达 64k 上下文下的长上下文检索结果。在 128k(模型的最大支持上下文长度)时,BF16 基线崩溃至 <10%。
在 Llama-3.3-70B-Instruct(图 3)上,较高比特的 TurboQuant 变体(k8v4 和 4bit-nc)很好地保留了长上下文检索能力,并保持了有竞争力的 AUC(约 52%)。然而,TQ k3v4-nc(48.6%)和 3bit-nc(50.3%)在所有序列长度上显示出明显且持续的退化,在 64k 上下文处差距扩大,精度下降高达 8 个点。
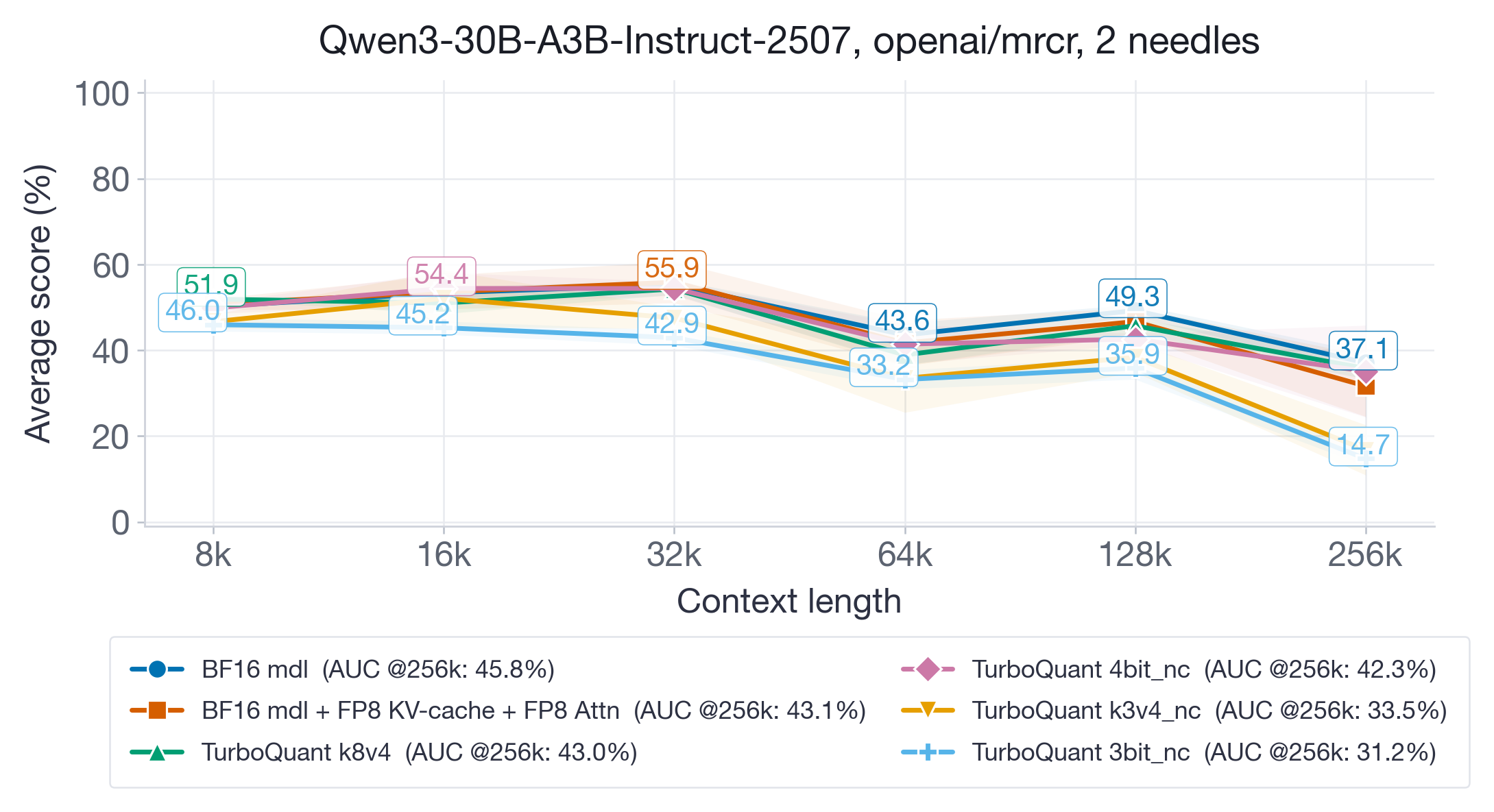
图 4:Qwen3-30B-A3B-Instruct-2507 在高达 256k 上下文下的长上下文检索结果。
在支持长达 256k 上下文的 Qwen3-30B-A3B-Instruct-2507(图 4)上,差异更为明显。BF16(45.8%)、FP8(43.1%)和 TQ k8v4(43.0%)彼此在标准差范围内。TQ 4bit-nc(42.3%)也具有竞争力。但激进的变体显著退化:TQ k3v4-nc 降至 33.5% AUC,TQ 3bit-nc 降至 31.2%——相对于 BF16 相对退化约 30%。退化集中在最长的上下文长度(128k-256k),表明低比特 KV-cache 量化误差随序列长度累积。
要点: TQ k8v4 和 4bit-nc 对于长上下文检索是安全的。TQ k3v4-nc 和 3bit-nc 显示出明显的精度退化,尤其是在非常长的上下文中。FP8 匹配较高比特的 TQ 变体,同时提供更好的推理性能(稍后展示)。
推理
对于重 decode 的推理基准,我们使用 AIME25、GPQA:Diamond、MATH500 和 LiveCodeBench-v6。我们报告平均 pass@1 分数:AIME25 和 LiveCodeBench-v6 在 10 次重复上,GPQA:Diamond 和 MATH500 在 5 次重复上。
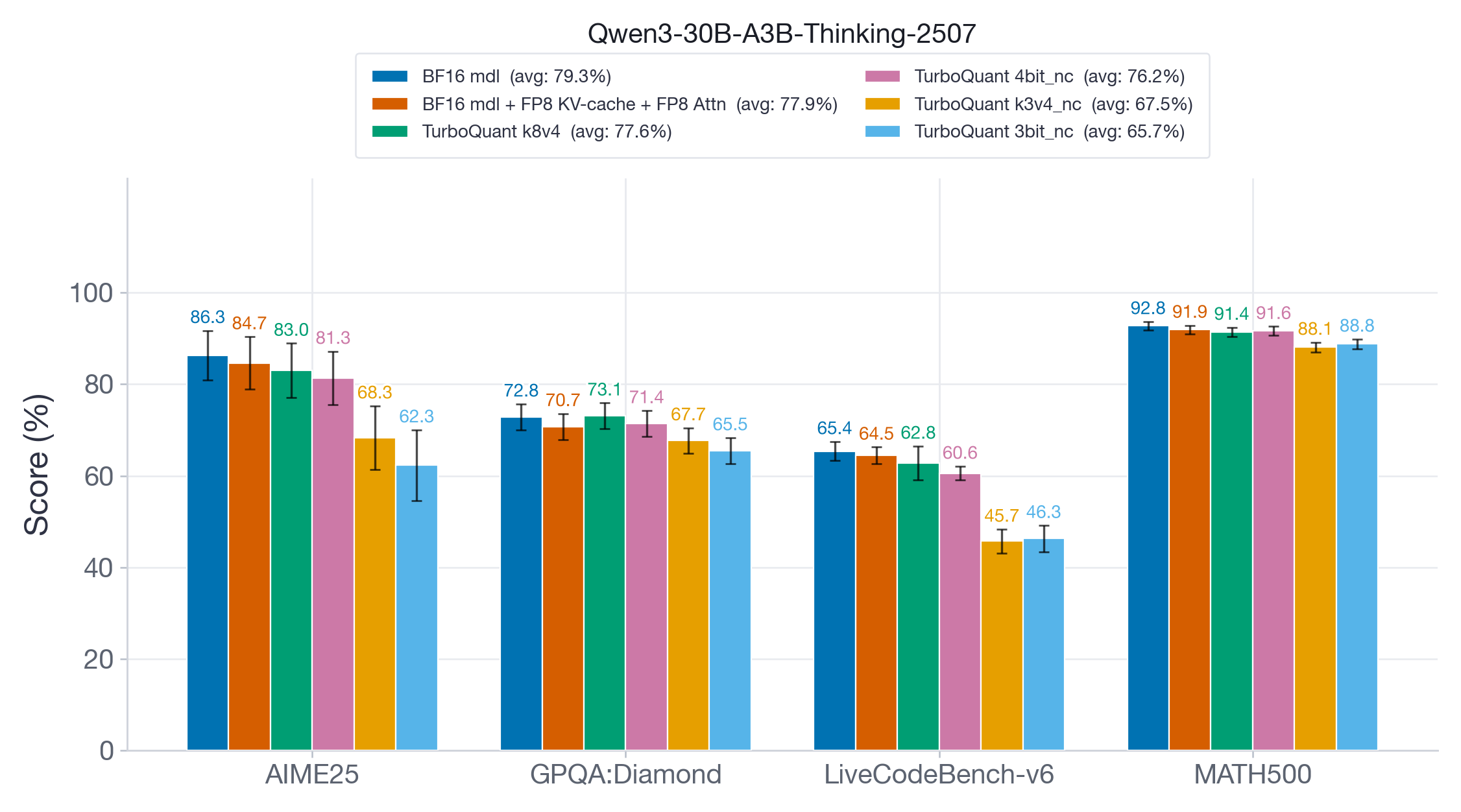
图 5:Qwen3-30B-A3B-Thinking-2507 的推理结果。激进的 TQ 变体(k3v4-nc、3bit-nc)在 AIME25 和 LiveCodeBench-v6 上显示出非常大的下降。
在 Qwen3-30B-A3B-Thinking-2507(图 5)上,我们看到了清晰的精度层级。FP8 和 TQ k8v4 接近 BF16 基线,平均精度恢复率 >98%。TQ 4bit-nc 显示出稍大的下降,恢复率为 96%,而 TQ k3v4-nc 和 3bit-nc 显示出约 20 个点的剧烈精度下降。即使在相对简单的 MATH500 基准上,精度下降也约为 4 个点,表明激进的 TurboQuant 变体不适合长生成推理任务。
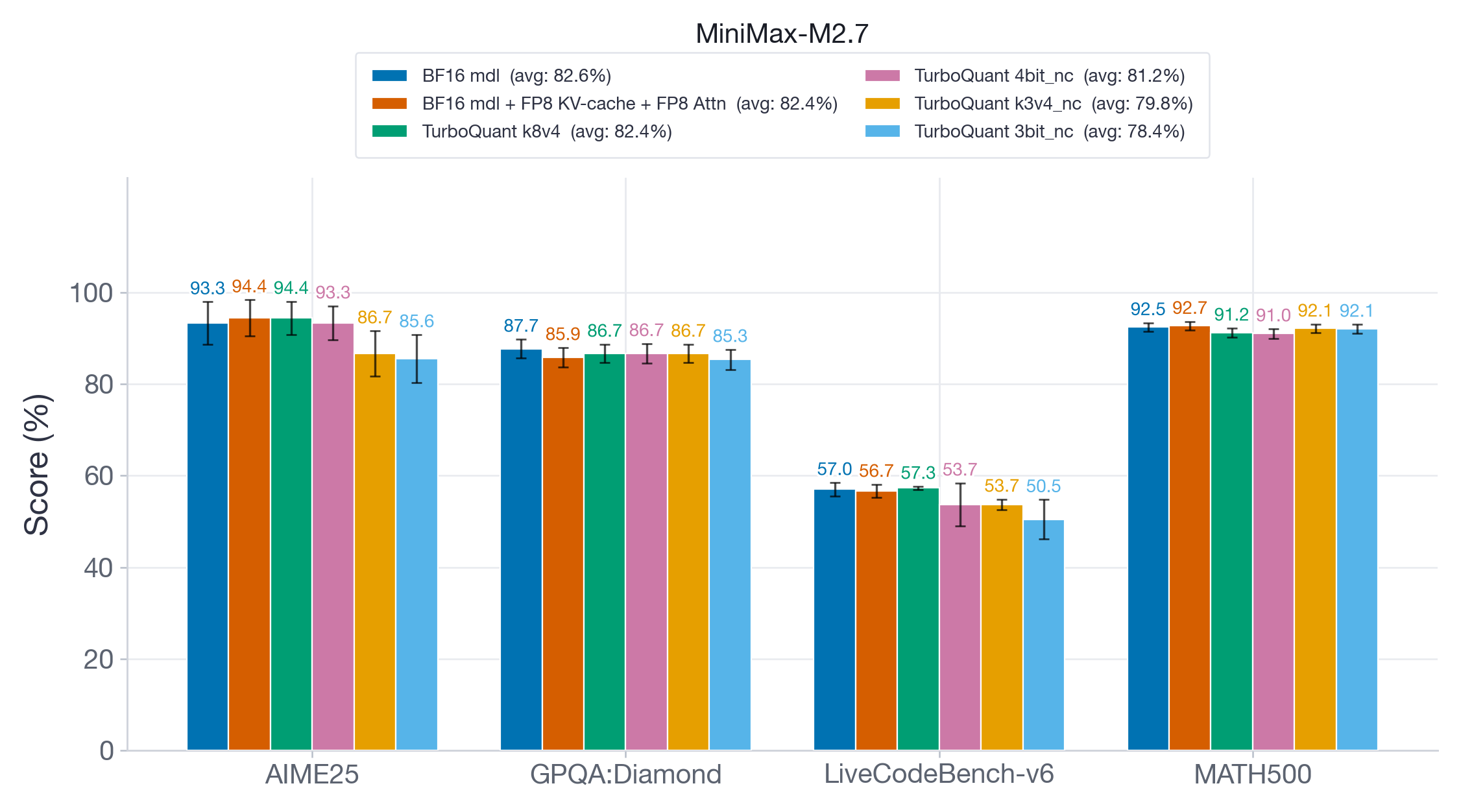
图 6:MiniMax-M2.7 的推理结果。尽管较大的模型往往对量化更鲁棒,但激进的 TurboQuant 变体仍然显示出显著的精度退化,特别是在 AIME25 和 LiveCodeBench-v6 上。
在 MiniMax-M2.7(图 6)上,一个更大的 200B+ 参数模型,我们观察到类似的模式。FP8 和 TQ k8v4 保持 >99% 的精度恢复,而 TQ 4bit-nc 显示出适度的下降。与较小的 Qwen 模型一样,激进的 TQ 变体(k3v4-nc、3bit-nc)显示出显著的精度退化,尤其是在 AIME25 和 LiveCodeBench-v6 上,精度下降高达约 8 个点。
要点: 激进的 TurboQuant 变体(k3v4-nc、3bit-nc)显示出显著的精度退化,尤其是在困难的数学和编码任务(如 AIME25 和 LiveCodeBench-v6)上。TQ 4bit-nc 显示出适度的精度下降,而 TQ k8v4 的表现与未量化的 BF16 基线相当。FP8 也与未量化基线匹配;然而,它提供了比任何 TurboQuant 变体都显著更好的推理性能(稍后展示)。
性能结果
对于性能基准测试,我们专注于 Qwen3-30B-A3B-Instruct-2507(2xH100)和 Llama-3.3-70B-Instruct(4xH100)。我们在各种请求速率下测量延迟、离线吞吐量和在线服务指标(TPOT 和 TTFT)。我们使用 vLLM 版本 0.20.2(提交 6ec9bbec3)部署模型。
延迟
我们使用 vllm bench latency 测量延迟,使用固定的合成请求,输入长度为 1024,输出长度为 256,扫描批大小 1、8、32 和 64。每个配置使用 10 次预热迭代,然后进行 30 次测量迭代。结果显示为相对于 BF16 的减速比(越低越好)。
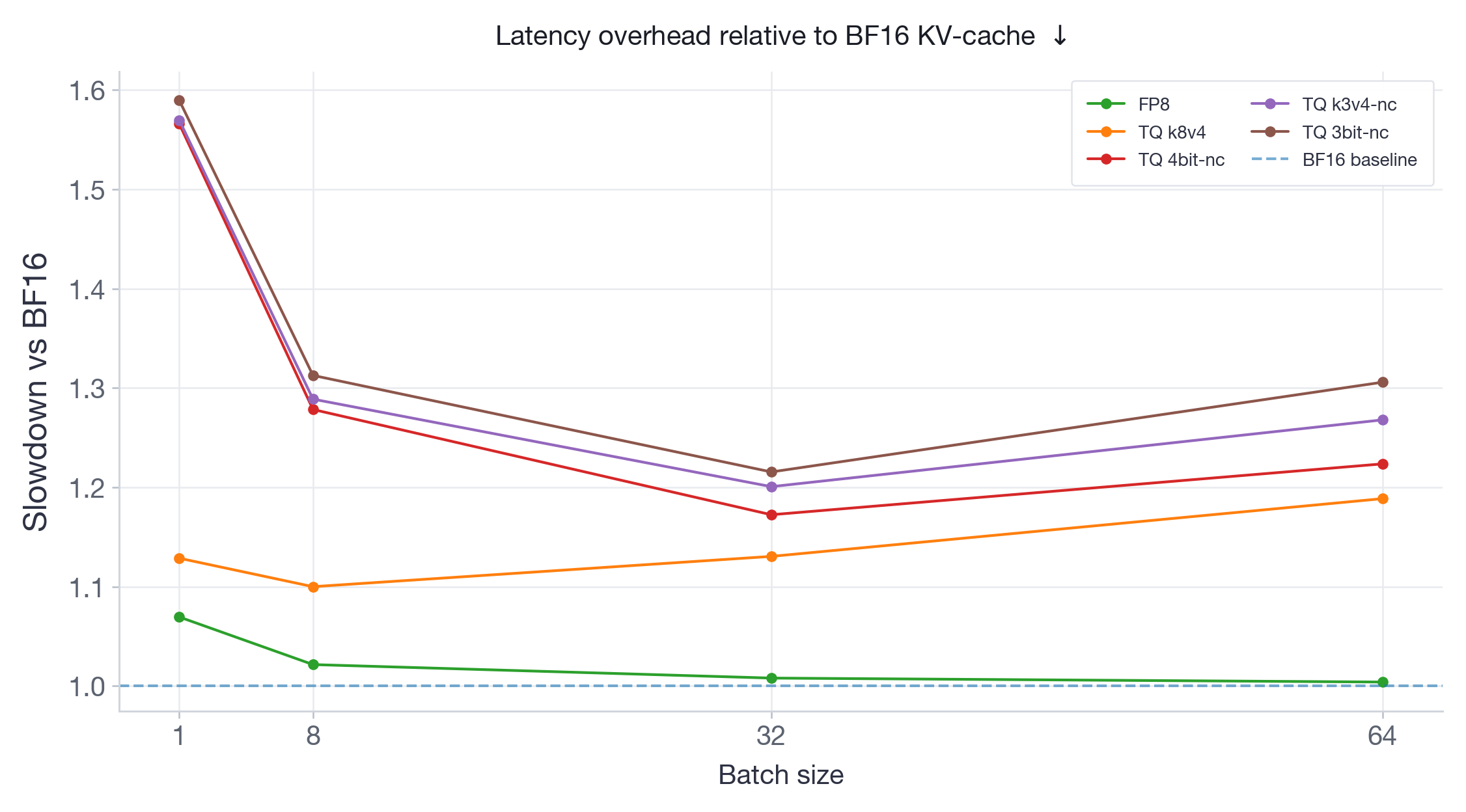
图 7:Qwen3-30B-A3B-Instruct-2507 相对于 BF16 的延迟开销。FP8 的开销可忽略不计,并随批处理消失;TurboQuant(TQ)根据变体和批大小增加高达 60% 的减速。
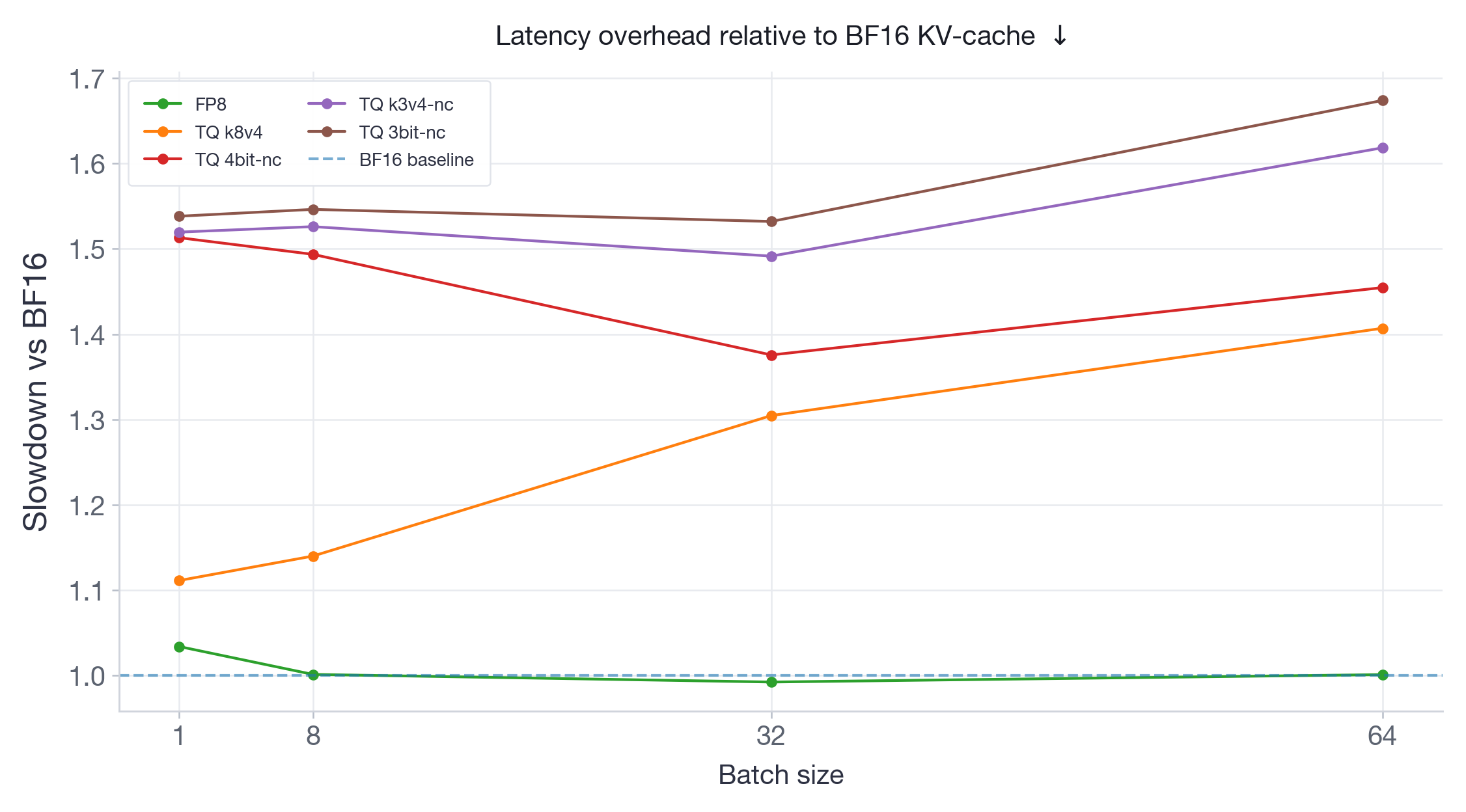
图 8:Llama-3.3-70B-Instruct 相对于 BF16 的延迟开销。FP8 的开销可忽略不计,而 TQ 开销范围从 10% 到 68%。
FP8 在两个模型和所有批大小上始终表现出可忽略不计或零延迟开销——这是预期的,因为 FP8 使用硬件原生 FP8 Tensor Core 操作量化注意力计算本身,避免了反量化开销。所有 TurboQuant 变体都增加了可测量的延迟:在 Qwen3-30B(图 7)上,开销范围约为 10% 到 60%;在 Llama-3.3-70B(图 8)上,开销总体更高,范围约为 10% 到 68%。值得注意的是,对于较大的 Llama-70B 模型,TQ 开销倾向于随批大小增加——这与我们对此用例的期望相反。这是因为 TurboQuant 必须在计算注意力之前将 KV-cache 从低比特存储反量化回 BF16,并且此反量化成本随访问的 KV-cache 量而增长。
吞吐量
我们使用 vllm bench throughput 测量离线吞吐量,使用 200 个提示,涵盖三个输入/输出长度对:256/256、1024/512 和 4096/256。结果显示为 BF16 吞吐量的百分比(越高越好)。
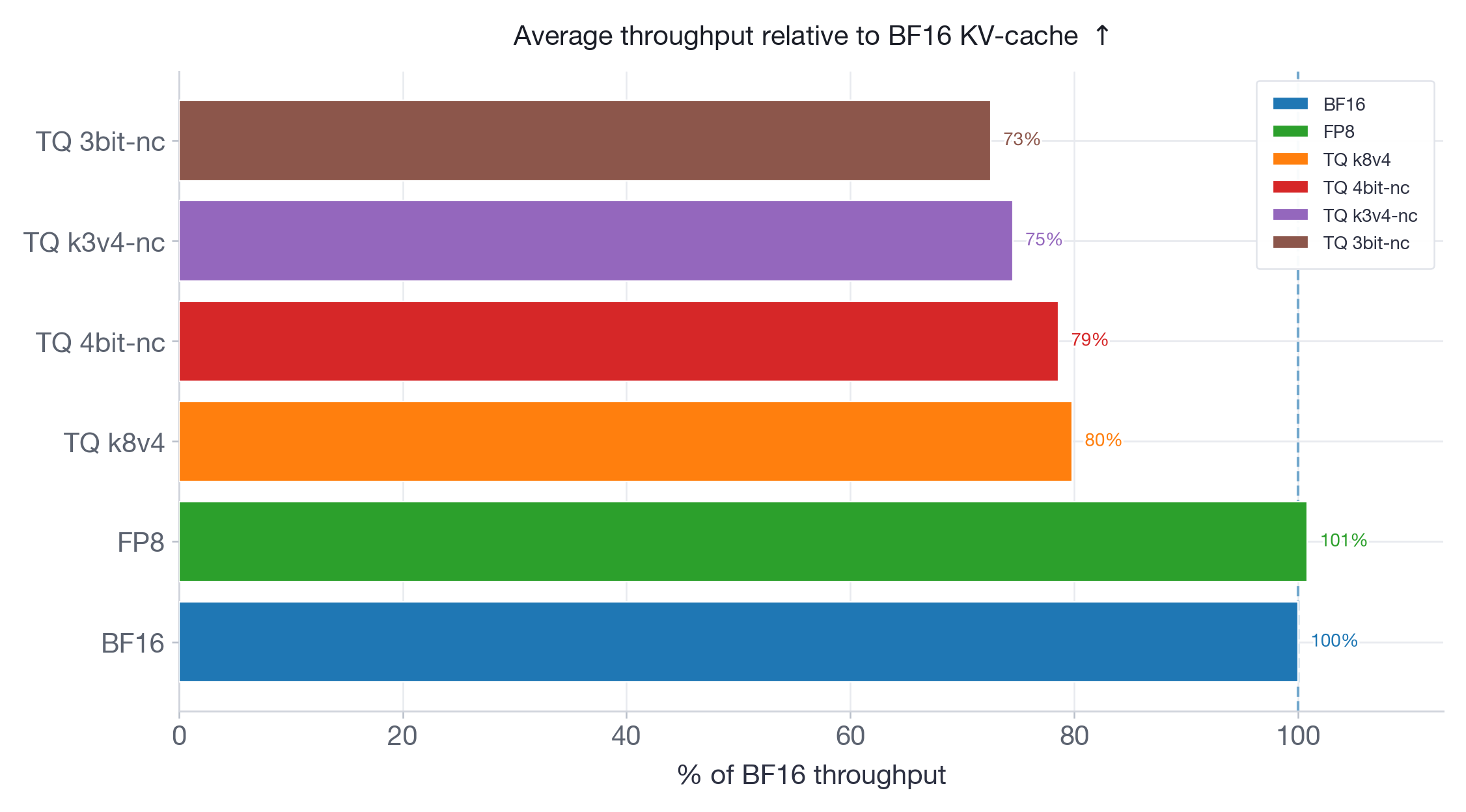
图 9:Qwen3-30B-A3B-Instruct-2507 相对于 BF16 的平均吞吐量。FP8 保持 BF16 吞吐量,而所有 TurboQuant 变体都降低了吞吐量,表明较低的 KV-cache 存储成本并不直接转化为更快的服务。
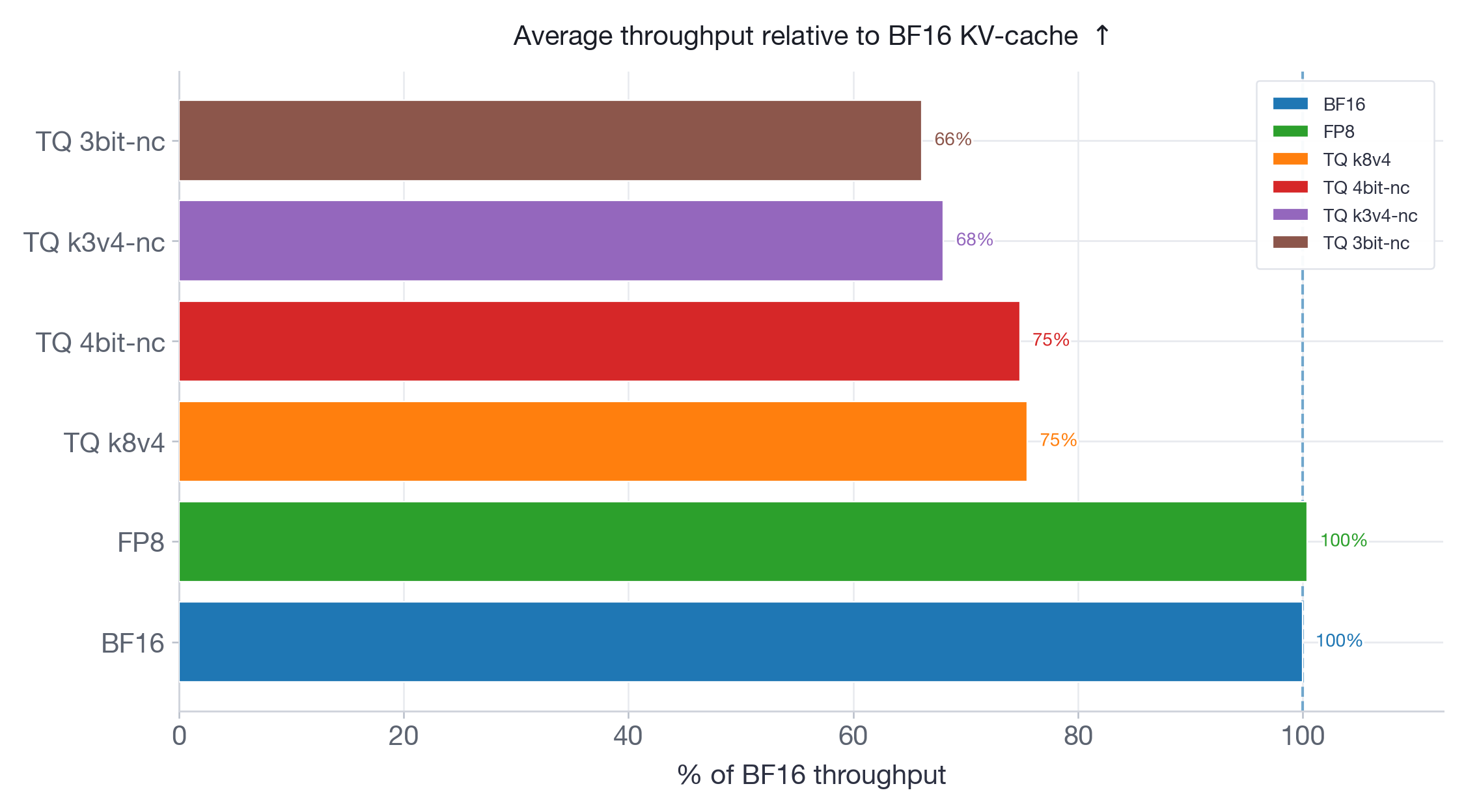
图 10:Llama-3.3-70B-Instruct 相对于 BF16 的平均吞吐量。FP8 保持 BF16 吞吐量,而所有 TurboQuant 变体都降低了吞吐量,表明较低的 KV-cache 存储成本并不直接转化为更快的服务。
吞吐量结果强化了延迟发现。FP8 在两个模型上匹配 BF16 吞吐量。所有 TurboQuant 变体都严格低于 BF16:在 Qwen3-30B(图 9)上,范围从 80%(k8v4)到 73%(3bit-nc);在 Llama-70B(图 10)上,从 75%(k8v4 和 4bit-nc)到 66%(3bit-nc)。更激进的量化始终导致更低的吞吐量——反量化开销随打包格式的复杂性而增长。
服务速度
我们使用 vllm bench serve 测量服务性能,使用输入长度为 1024、输出长度为 512 的合成请求,300 个测量提示和 5 个预热请求。我们测试请求速率 2、8 和 inf(尽可能快地发送请求)。我们报告 TPOT(每个输出令牌的时间——衡量解码速度)和 P99 TTFT(首个令牌的时间——衡量请求开始生成的速度)。
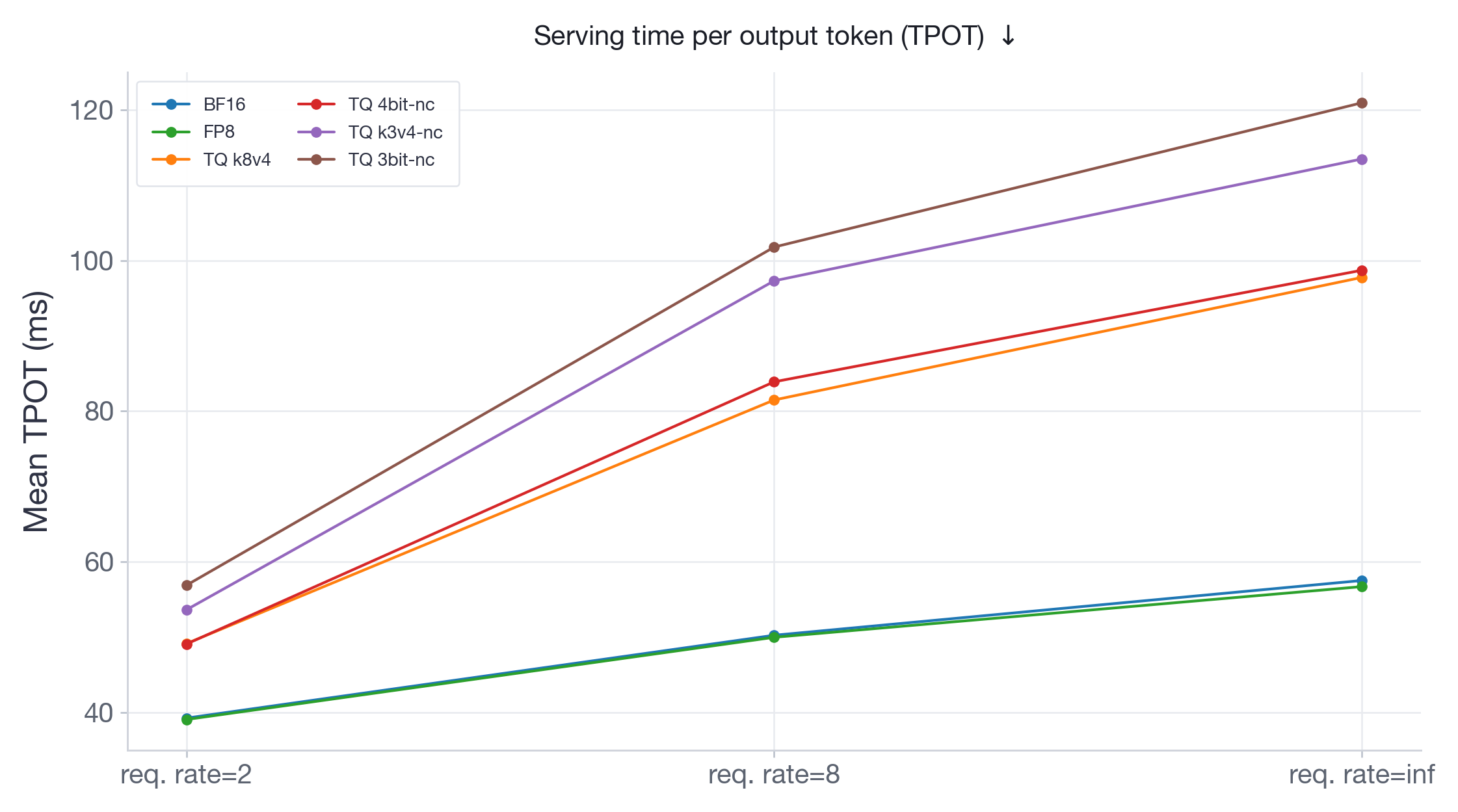
图 11:Qwen3-30B-A3B-Instruct-2507 的每个输出令牌的服务时间(TPOT)。
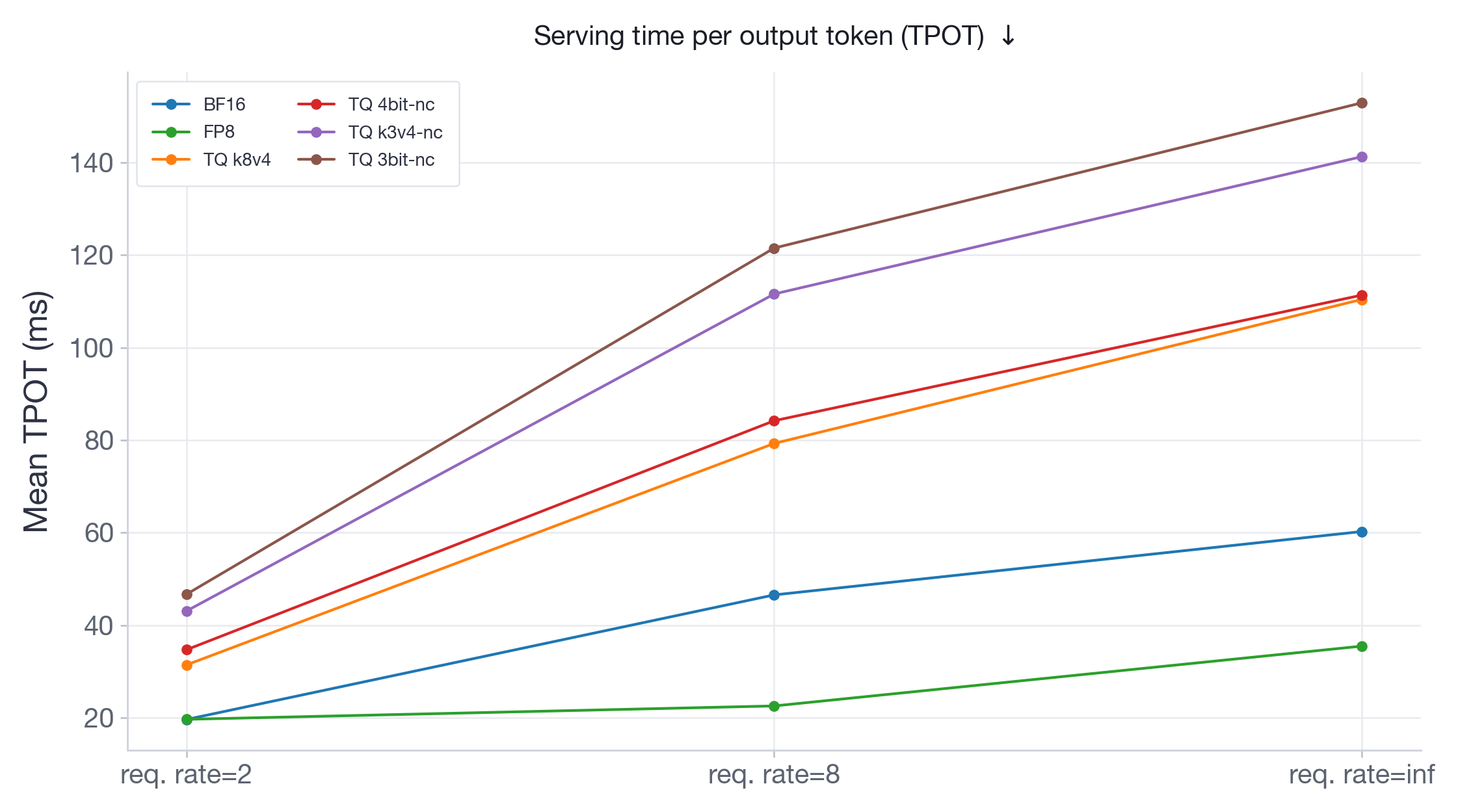
图 12:Llama-3.3-70B-Instruct 的每个输出令牌的服务时间(TPOT)。
TPOT 结果(图 11-12)反映了延迟和吞吐量发现:FP8 在所有请求速率下要么跟踪要么优于 BF16,而 TQ 变体增加了大量的每令牌开销,且随负载增长。在 Llama-70B 的突发负载下,FP8 几乎比 BF16 快 2 倍,而 TQ 变体慢 1.5 到 2.5 倍。
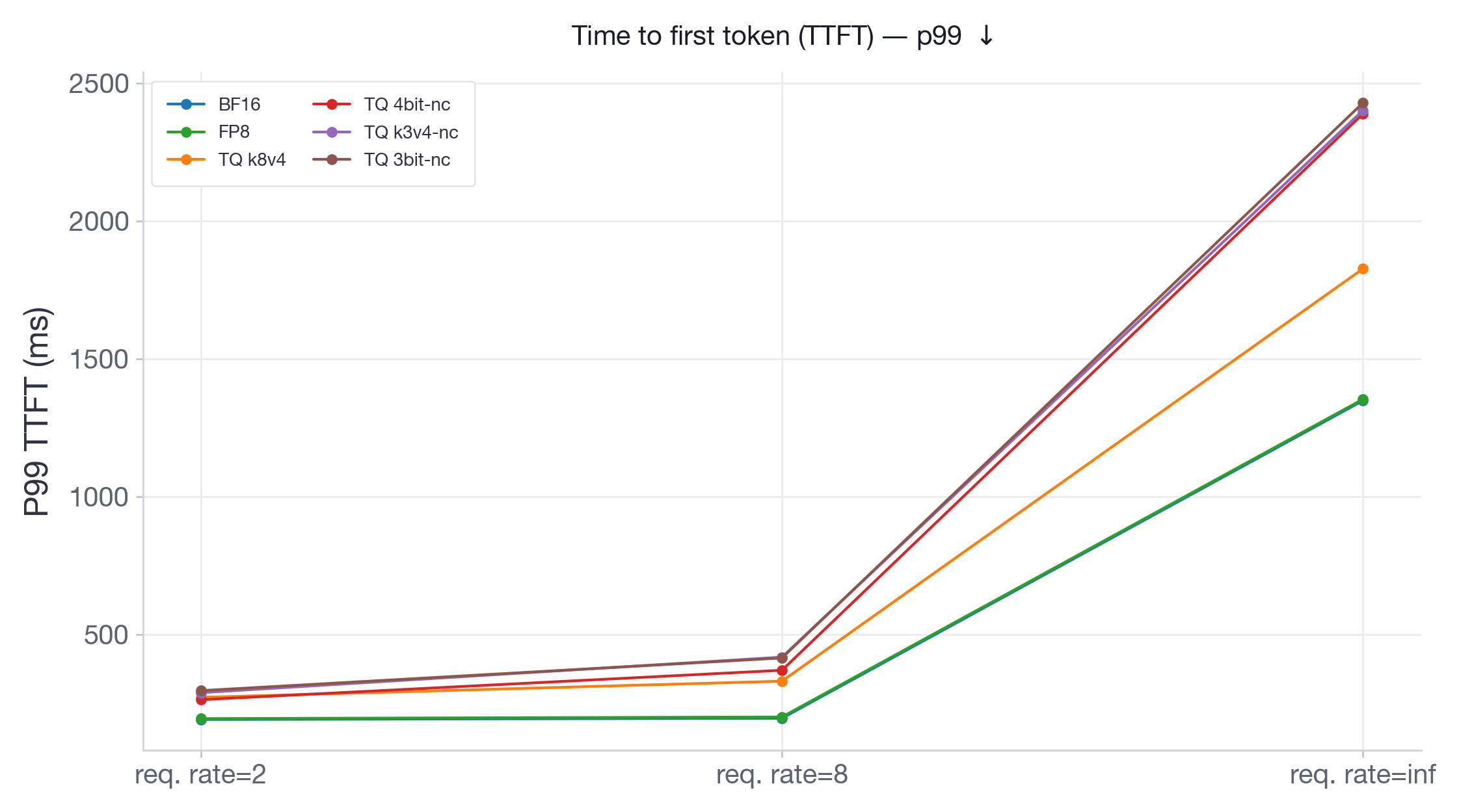
图 13:Qwen3-30B-A3B-Instruct-2507 的 P99 TTFT。
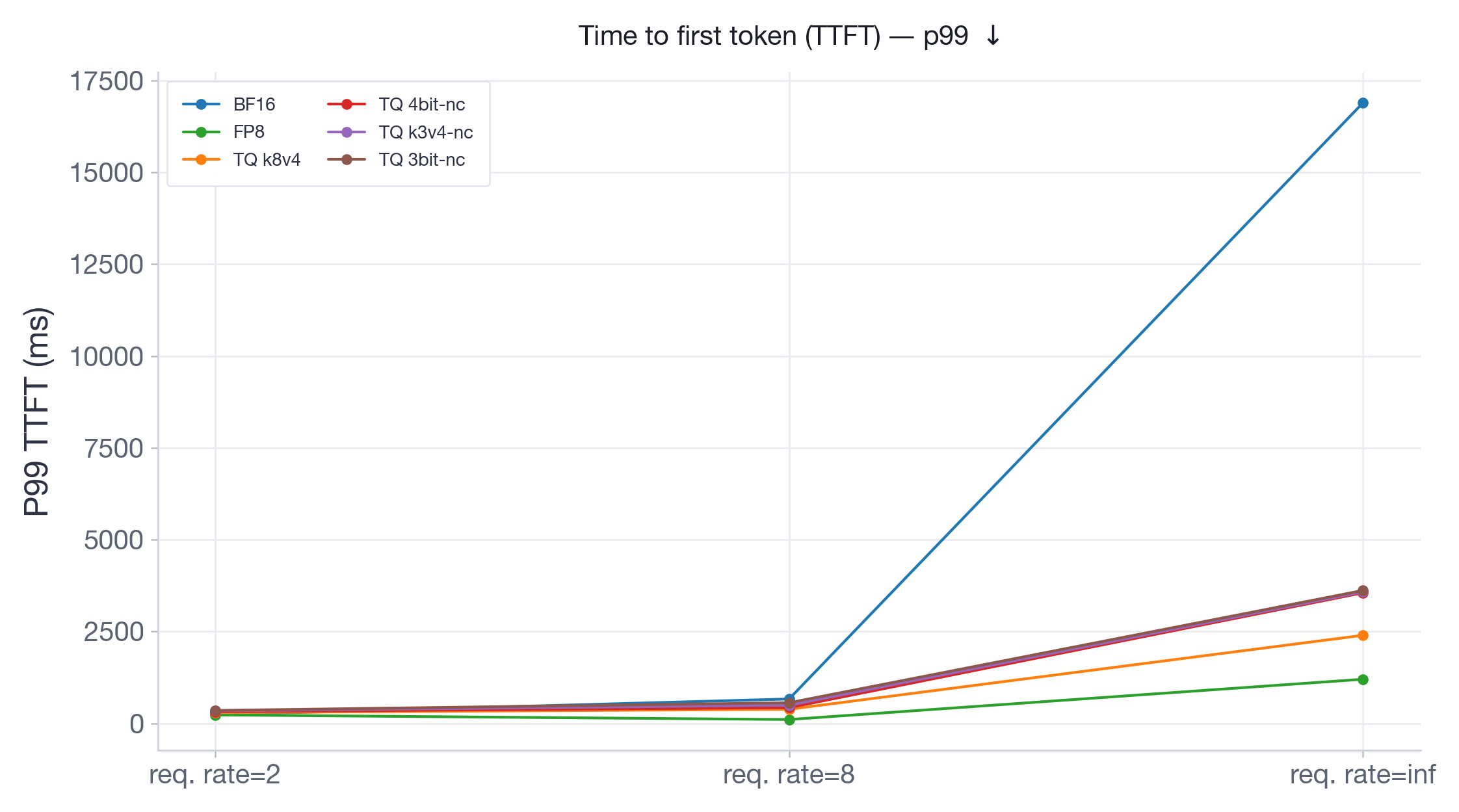
图 14:Llama-3.3-70B-Instruct 的 P99 TTFT。在突发负载下,由于内存饱和,BF16 TTFT 激增至约 17 秒;TurboQuant 变体保持在 3.5 秒以下,FP8 保持在 1.5 秒以下。
在 Qwen3-30B(图 13)上,它在 2xH100 上有更多的内存余量,FP8 在所有请求速率下与 BF16 表现相同。TurboQuant 变体始终较慢,在突发负载下减速高达 2 倍。在 Llama-3.3-70B(图 14)上,运行在 4xH100 上,KV-cache 空间有限,BF16 在突发负载下的 TTFT 激增至约 17 秒,因为系统耗尽了 KV-cache 内存,必须将传入请求排队。所有 TurboQuant 变体保持在 3.5 秒以下——5 倍的改进——因为它们的压缩 KV-cache 允许在不排队的情况下处理更多并发请求。同时,FP8 实现了最低的 TTFT,约为 1.3 秒,并始终优于所有 TurboQuant 变体。
要点: TurboQuant 通过降低吞吐量和增加每令牌延迟,始终表现不如 BF16 和 FP8。然而,在内存受限的服务场景中,KV-cache 压缩防止了内存饱和,并在突发负载下相对于 BF16 显著降低了 TTFT。这是 TurboQuant 价值主张的核心:它以每令牌速度换取服务原本会被排队的请求的能力。另一方面,FP8 提供了两全其美的效果:它匹配或优于 BF16 吞吐量,同时提供可忽略不计的延迟开销,并在突发负载下显著更好的 TTFT。
关键发现与建议
基于跨精度和性能基准的全面评估,我们得出以下实用建议:
FP8(--kv-cache-dtype fp8)仍然是 KV-cache 量化的最佳默认选择。 FP8 提供 2 倍 KV-cache 容量,无吞吐量成本,精度损失可忽略不计,有时甚至通过量化注意力提升性能。对于绝大多数工作负载,它是最安全、最可预测的选择,如 FP8 KV-cache 博客文章中所述。
TurboQuant k8v4 相比 FP8 没有显著优势。 此 TQ 变体仅提供适度的 KV-cache 节省(2.4 倍 vs 2 倍),不值得对吞吐量和延迟指标造成持续的负面影响。
TurboQuant 4bit-nc 提供了引人注目的内存换吞吐量权衡。 此变体提供高达 3.4 倍的 KV-cache 容量,在大多数基准上精度下降适度(1-4 个点)。对于内存受限的部署尤其有价值,其中突发负载下的 TTFT 改进超过了所有其他指标的负面影响。在部署前,请彻底验证目标工作负载的精度。
避免在没有彻底验证的情况下使用 TurboQuant k3v4-nc 和 3bit-nc。 这些激进的变体可能导致剧烈的精度下降,在困难的数学和编码基准上高达 20 个点。除了精度问题,由于复杂的反量化步骤导致的持续性能退化,使它们不适合生产部署。
当 GPU 内存不是瓶颈时,坚持使用 BF16。 如果您的工作负载使用短上下文、低并发运行,或者您的硬件有充足的内存,BF16 提供了最佳的精度-性能权衡,且没有量化伪影的风险。