vLLM 登顶 Artificial Analysis 排行榜
vLLM Tops the Artificial Analysis Leaderboard
DigitalOcean 发布推理基准测试,vLLM 开源引擎在NVIDIA Blackwell Ultra芯片上部署DeepSeek V3.2、MiniMax-M2.5和Qwen 3.5 397B模型。DeepSeek V3.2实现每用户最佳输出吞吐量230 TPS,Qwen 3.5 397B在Artificial Analysis全部12家提供商中排名第一,10,000 token prompt下TTFT低于1秒。优化包括DSv3.2注意力路径kernel融合(每层kernel从33降至10)、MiniMax-M2.5自定义EAGLE3 draft模型(基于TorchSpec训练)及Qwen 3.5线性注意力融合,均已在vLLM主线中或正在添加。
 vLLM 如何构建了 DeepSeek V3.2、MiniMax-M2.5 和 Qwen 3.5 397B 的领先部署。
vLLM 如何构建了 DeepSeek V3.2、MiniMax-M2.5 和 Qwen 3.5 397B 的领先部署。
上周,DigitalOcean 发布了推理基准测试,涵盖三个前沿开放权重模型。在 DeepSeek V3.2 上,该部署实现了每用户最佳输出吞吐量 230 TPS——比大多数推理提供商对同一模型报告的数值高出 4 倍以上。在 Qwen 3.5 397B 版本上,它在 Artificial Analysis 测量的全部 12 家提供商中排名第一,在 10,000 token 的 prompt 上 TTFT 低于 1 秒。
值得注意的部分是:底层的引擎是开源的。它就是 vLLM。
在生产 AI 中,一个常见的假设是,最佳的推理性能需要专有堆栈。然而,在这个案例中,一个运行在相同 NVIDIA Blackwell Ultra 芯片上的社区构建推理引擎却排名第一。
这些结果背后的优化并未锁定在私有分支中。针对 DeepSeek V3.2 的算子融合、针对 MiniMax-M2.5 的自定义 EAGLE3 draft 模型,以及一套针对 Qwen 3.5 线性注意力路径调优的融合;每一项改动都已存在于 vLLM 主线中,或正在被添加。
这篇文章将介绍这个部署是如何构建的。
vLLM 如何实现高速
这项工作分布在三个模型上,每个模型都有其自身的瓶颈和相应的解决方案。
- DeepSeek V3.2:激进的 kernel 融合,以在低 batch size 下减少开销(也适用于 DeepSeek V4)。
- MiniMax-M2.5:针对性的 kernel 融合,搭配一个自定义的 EAGLE3 draft 模型——该模型基于开源 TorchSpec 和 vLLM 训练,尽管模型本身是自定义的。相同的 draft 也适用于 M2.7;两者的架构相同。
- Qwen 3.5 397B:针对模型注意力和归一化路径的针对性融合。
以下各节将依次介绍每个模型。
DeepSeek V3.2:低 Batch Size 下的 Kernel 融合
在低 batch size 下,DeepSeek V3.2 的瓶颈在于 GPU kernel 启动开销,而非计算。每个 transformer 层会发起数十个独立的 kernel——像归一化、旋转位置编码(rotary embedding)和量化这样的小操作,GPU 本身执行只需微秒级,但每个操作都带有固定的启动成本,占据了总时间的主导地位。
解决方案是在注意力路径上进行算子融合。之前作为独立 kernel 启动的操作——Q 和 KV 归一化、Q 和 KV 的旋转位置编码、索引器的 layer norm 和旋转位置编码、FP8 量化以及 KV cache 写入——被合并为一对融合 kernel,覆盖了注意力和 MoE 之外的所有内容。每层 kernel 数量从约 33 个降至约 10 个的目标。
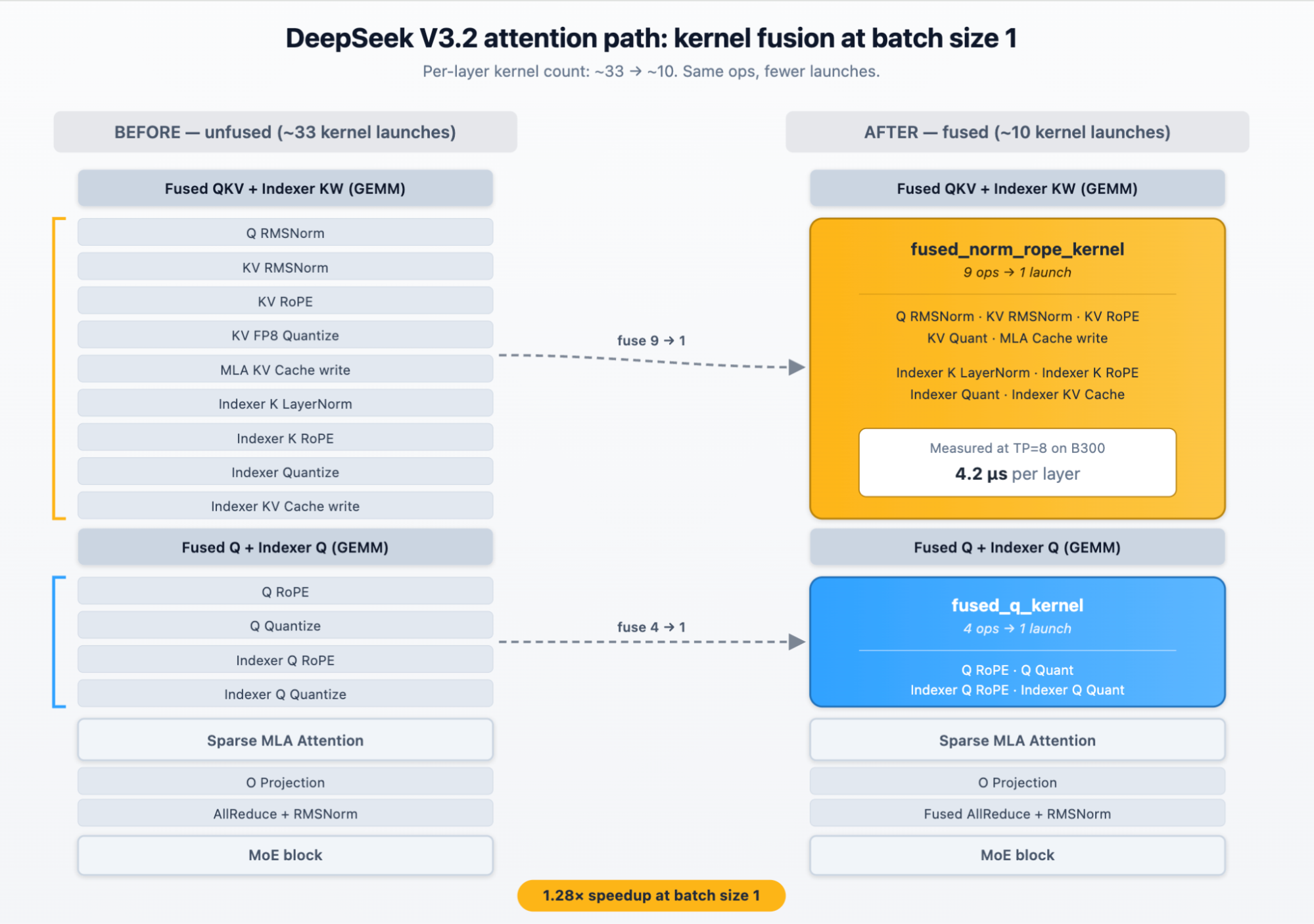
图 1:DSv3.2 注意力路径融合将每层约 33 次 kernel 启动缩减至约 10 次,在 batch size 为 1 时实现了 1.28 倍的加速。
仅融合一项就在 batch size 为 1 时实现了 1.28 倍的加速(在 4× GB200 上,无 MTP,从 85.8 tok/s 提升至 109.3 tok/s)。在单个 8× B300 节点上,并发度为 1 时:
- 无 MTP(TP=8):125 tok/s
- 使用 MTP=1(TP=8):234 tok/s(约 90% draft 接受率)
- 使用 prefill/decode 分离(TP=4 + TP=4 + MTP=3):262 tok/s
除了融合之外,两个 DSv3.2 特有的 kernel 填补了剩余差距。一个新的 router GEMM kernel——专门针对 DSv3 在小 decode batch size 下的 MoE 路由维度进行了优化——取代了通用的 matmul,在 batch 1 时额外带来了 6% 的加速(#34302)。
对于稀疏注意力索引器,一个新的 TopK kernel 会根据序列长度为每行选择正确的算法,将所有情况适配到单个 CUDA graph 中。这为 128K 上下文 decode 带来了高达 17% 的每 token 延迟改善(#37421)。
同样的工作现在构成了 vLLM 对 DeepSeek V4 的支持 的基础,该支持复用了本工作中的 Q RoPE + 量化以及 QK norm 融合。结果如下所示。
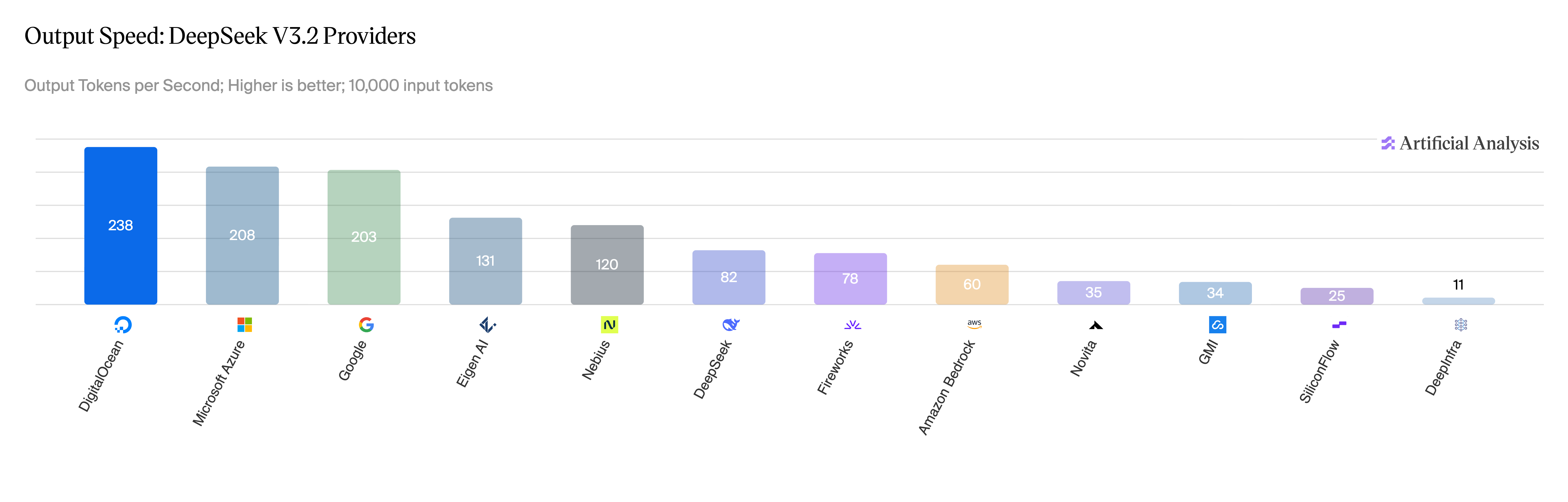
图 2:DeepSeek V3.2 非推理模式,各提供商的输出速度。
来源:Artificial Analysis,2026 年 5 月。
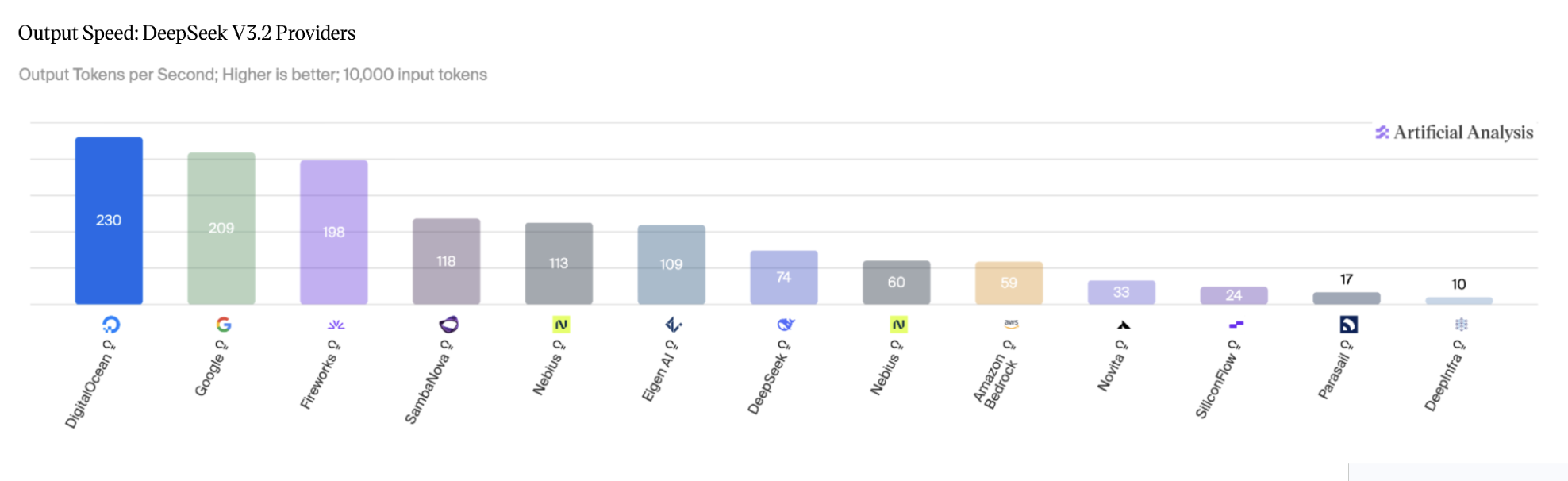
图 3:DeepSeek V3.2 推理模式,各提供商的输出速度。
来源:Artificial Analysis,2026 年 5 月。
MiniMax-M2.5:EAGLE3 与更多 Kernel 融合
Inferact 团队使用 TorchSpec 为 MiniMax-M2.5 训练了一个自定义的 EAGLE3 draft 模型。TorchSpec 是一个 torch 原生的在线推测解码框架,可同时运行 FSDP draft 训练和基于 vLLM 的目标推理。该 draft 并非从通用的监督数据集中学习,而是消耗 MiniMax-M2.5 重新生成的响应上的实时 vLLM 生成的隐藏状态,从而训练其匹配基础模型的精确 token 分布。
vLLM 的 MRV2 路径中的推测解码基础设施改进使这成为可能:一个 draft 模型元数据修复,提高了后续 draft 位置的接受率(#38311),以及支持 draft prefill 的 CUDA graph(#37588)。
除了 draft 模型之外,MiniMax M2.5 还获得了针对性的 kernel 融合工作。添加了一个自定义的 QK-norm 融合(fuse_minimax_qk_norm)来处理模型非标准的注意力归一化,其中 Q 和 K 的方差在应用每通道缩放之前,会在 tensor-parallel rank 之间进行缩减(#37045)。
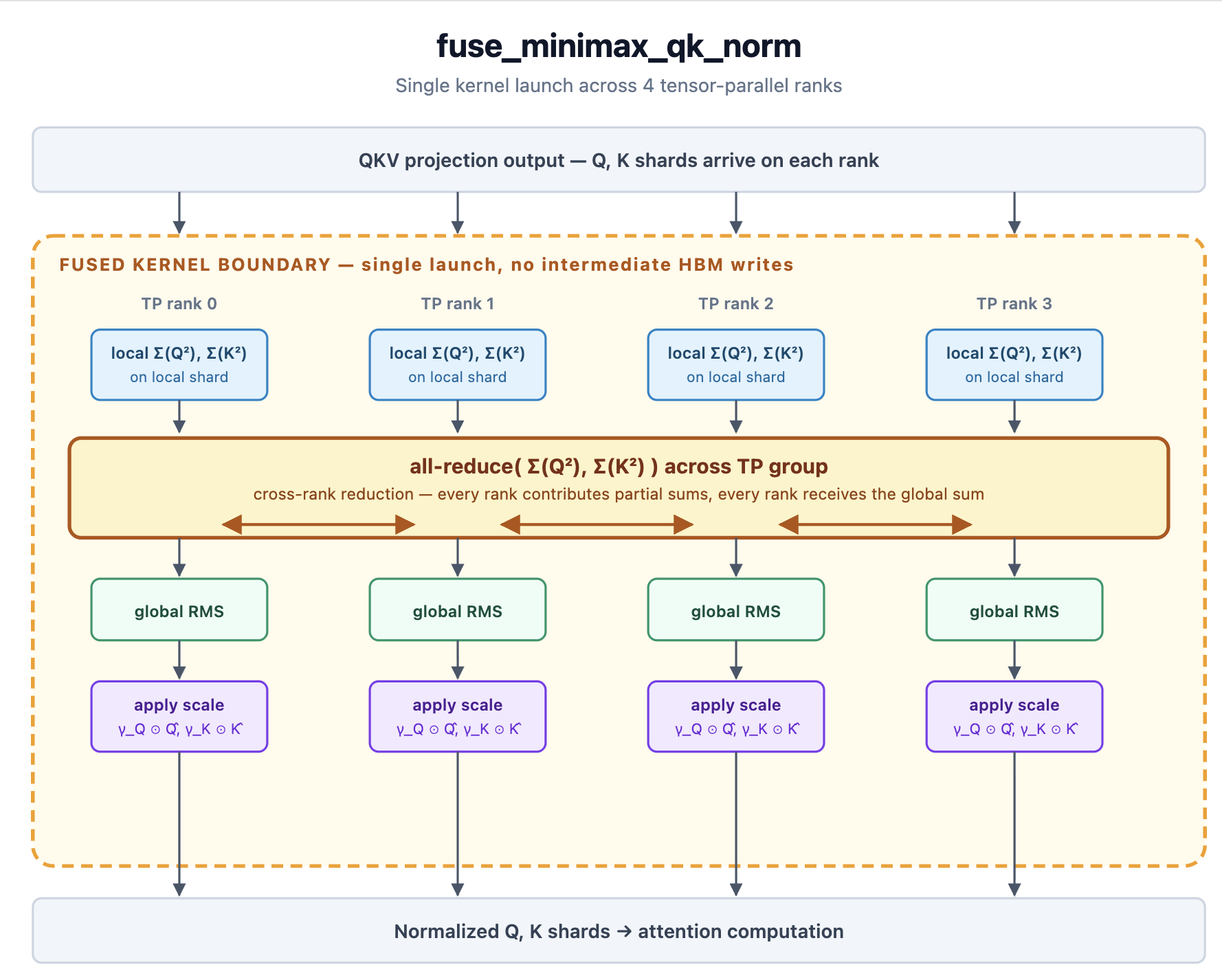
图 4:跨四个 tensor-parallel rank 的 fuse_minimax_qk_norm 剖析。
通过此融合以及标准的 fuse_norm_quant、fuse_act_quant 和 fuse_gemm_comms 通道,上限实验达到了:
- 并发度 1 时 326 tok/s(TP=4,EAGLE3 + 3 个推测 token,合成 100% 接受率)。
这代表了在拥有完美 draft 模型时服务堆栈的上限,将融合工作的贡献与 draft 模型质量分离开来。
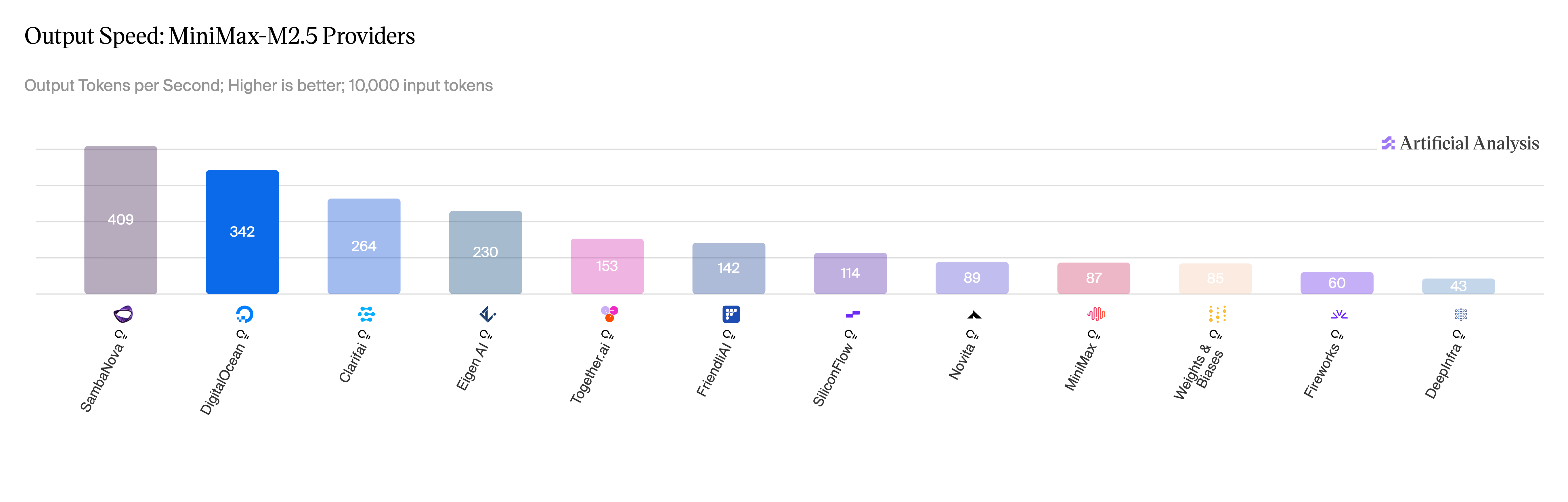
图 5:MiniMax-M2.5,各提供商的输出速度。
来源:Artificial Analysis,2026 年 5 月。
Qwen 3.5 397B:线性注意力与融合缺口
Qwen 3.5 在其注意力模块中使用了带有非标准归一化的线性注意力。这两种架构选择都与 vLLM 的标准融合基础设施产生了尴尬的交互:投影后的卷积路径是线性注意力模型独有的,并且归一化变体与 vLLM 现有 allreduce_rms 融合所寻找的模式不匹配。
代价在 profiler 中显现出来。由于错过了 allreduce_rms 融合,大约一半的 decode 时间花费在未融合的跨设备 reduce 上——这正是融合应该消除的那种开销。模型运行正常,数值正确,但引擎执行的内存往返次数超出了必要。
四项工作填补了这一缺口:
- 修复现有的
allreduce_rms融合通道,使其能够识别 Qwen 的归一化变体——在 batch > 1 时,TPOT 提升约 5%。 - 对 qk-norm + rope 路径进行 kernel 级优化。
- 针对 Qwen 线性注意力架构特有的后卷积路径进行 kernel 融合(#37813)。
- 双流执行,重叠独立计算分支。
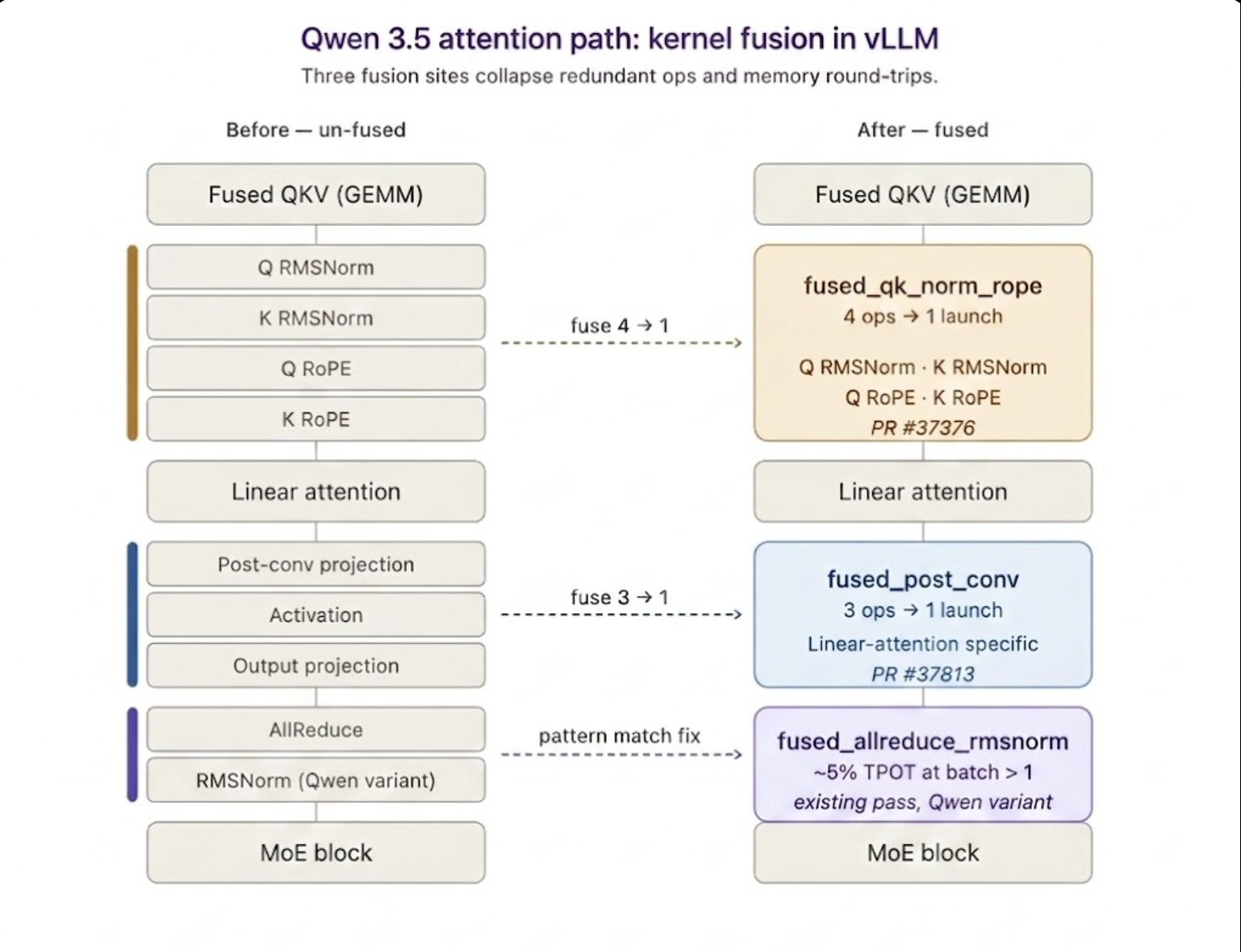
图 6:vLLM 中的 Qwen 3.5 397B kernel 融合工作。
结合 TP=8 和 expert parallelism,生产部署达到了:
- 并发度 1 时 163 tok/s(TEP=8,后卷积融合)
- 并发度 256 时 7.33 req/s,高于 6.69 req/s 的基线(+10%)
这项工作已合并到 vLLM 主线中。
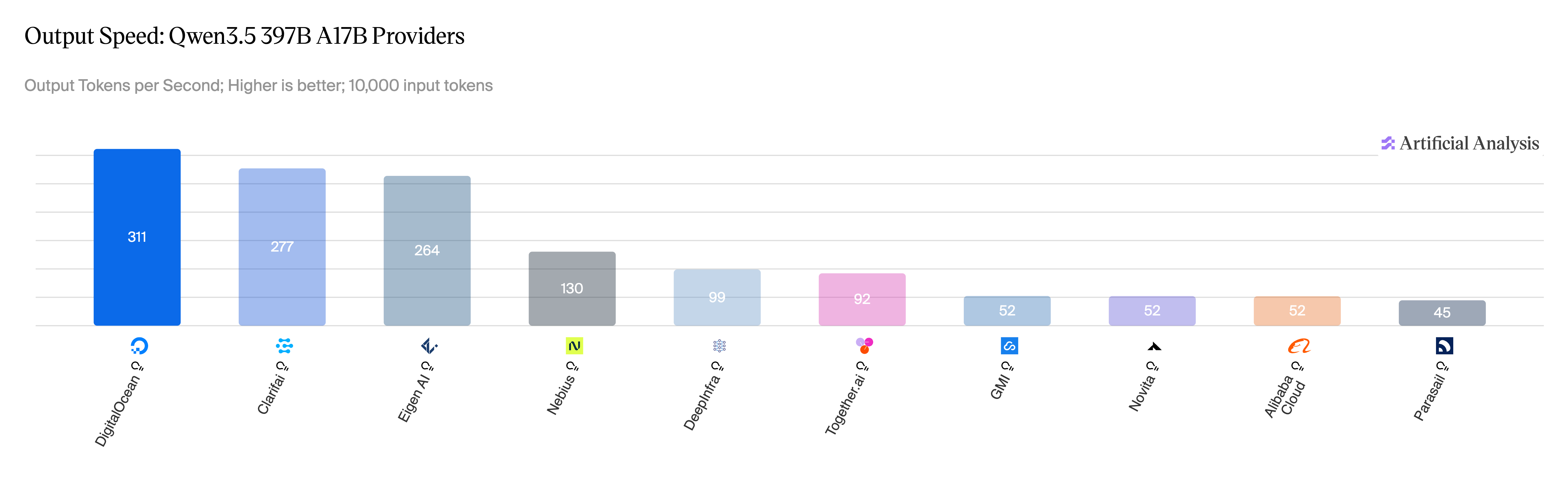
图 7:Qwen 3.5 397B,各提供商的输出速度。
来源:Artificial Analysis,2026 年 5 月。
这对 vLLM 意味着什么
这些结果背后的优化——DSv3.2 注意力路径融合、MiniMax EAGLE3 draft 模型训练方案以及 Qwen 3.5 融合——要么已经上游合并到 vLLM 主线中,要么正在上游合并的路上。在当前 vLLM 上运行这些模型的团队将获得相同的加速效果。
开源成为默认选择
从历史上看,最快的推理堆栈一直是专有的——由超大规模云厂商、模型实验室和芯片供应商为其自身基础设施构建和调优。开源替代方案虽然广泛可用,但在生产性能上往往落后。
这种情况在推理层已不复存在。vLLM 现在在其支持的模型上位居 Artificial Analysis 排行榜榜首。在这些基准测试中,世界上最快的推理是开源的。现代 AI 底层的基础设施正在追随这一趋势。
致谢
感谢 Inferact、DigitalOcean、NVIDIA、Red Hat 以及 vLLM 开源社区对这项计划的贡献。